
-
测试工程师你应该掌握什么
2009-03-09 10:56:42
人是测试工作中最有价值也是最重要的资源,没有一个合格的、积极的测试小组,测试就不可能实现。然而,在软件开发产业中有一种非常普遍习惯,那就是让那些经验最少的新手、没有效率的开发者或不适合干其他工作的人去做测试工作。这绝对是一种目光短浅的行为,对一个系统进行有效的测试所需要的技能绝对不比进行软件开发需要的少,事实上,测试者将获得极其广泛的经验,他们将遇到许多开发者不可能遇到的问题。
①、沟通能力
一名理想的测试者必须能够同测试涉及到的所有人进行沟通,具有与技术(开发者)和非技术人员(客户,管理人员)的交流能力。既要可以和用户谈得来,又能同开发人员说得上话,不幸的是这两类人没有共同语言。和用户谈话的重点必须放在系统可以正确地处理什么和不可以处理什么上。而和开发者谈相同的信息时,就必须将这些活重新组织以另一种方式表达出来,测试小组的成员必须能够同等地同用户和开发者沟通。
②、移情能力
和系统开发有关的所有人员都处在一种既关心又担心的状态之中。用户担心将来使用一个不符合自己要求的系统,开发者则担心由于系统要求不正确而使他不得不重新开发整个系统,管理部门则担心这个系统突然崩溃而使它的声誉受损。测试者必须和每一类人打交道,因此需要测试小组的成员对他们每个人都具有足够的理解和同情,具备了这种能力可以将测试人员与相关人员之间的冲突和对抗减少到最低程度。
③、技术能力
就总体言,开发人员对那些不懂技术的人持一种轻视的态度。一旦测试小组的某个成员作出了一个错误的断定,那么他们的可信度就会立刻被传扬了出去。一个测试者必须既明白被测软件系统的概念又要会使用工程中的那些工具。要做到这一点需要有几年以上的编程经验,前期的开发经验可以帮助对软件开发过程有较深入的理解,从开发人员的角度正确的评价测试者,简化自动测试工具编程的学习曲线。
④、自信心
开发者指责测试者出了错是常有的事,测试者必须对自己的观点有足够的自信心。如果容许别人对自己指东指西,就不能完成什么更多的事情了。
⑤、外交能力
当你告诉某人他出了错时,就必须使用一些外交方法。机智老练和外交手法有助于维护与开发人员的协作关系,测试者在告诉开发者他的软件有错误时,也同样需要一定的外交手腕。如果采取的方法过于强硬,对测试者来说,在以后和开发部门的合作方面就相当于“赢了战争却输了战役”。
⑥、幽默感
在遇到狡辩的情况下,一个幽默的批评将是很有帮助的。
⑦、很强的记忆力
一个理想的测试者应该有能力将以前曾经遇到过的类似的错误从记忆深处挖掘出来,这一能力在测试过程中的价值是无法衡量的。因为许多新出现的问题和我们已经发现的问题相差无几。
⑧、耐心
一些质量保证工作需要难以置信的耐心。有时你需要花费惊人的时间去分离、识别和分派一个错误。这个工作是那些坐不住的人无法完成的。
⑨、怀疑精神
可以预料,开发者会尽他们最大的努力将所有的错误解释过去。测式者必须听每个人的说明,但他必须保持怀疑直到他自己看过以后。
⑩、自我督促
干测试工作很容易使你变得懒散。只有那些具有自我督促能力的人才能够使自己每天正常地工作。
11、洞察力
一个好的测试工程师具有“测试是为了破坏”的观点,捕获用户观点的能力,强烈的质量追求,对细节的关注能力。应用的高风险区的判断能力以便将有限的测试针对重点环节。 -
用Cobertura测量测试覆盖率
2009-02-26 17:59:52
尽管测试先行编程(test-first programming)和单元测试已不能算是新概念,但测试驱动的开发仍然是过去 10 年中最重要的编程创新。最好的一些编程人员在过去半个世纪中一直在使用这些技术,不过,只是在最近几年,这些技术才被广泛地视为在时间及成本预算内开发健壮的无缺陷软件的关键所在。但是,测试驱动的开发不能超过测试所能达到的程度。测试改进了代码质量,但这也只是针对实际测试到的那部分代码而言的。您需要有一个工具告诉您程序的哪些部分没有测试到,这样就可以针对这些部分编写测试代码并找出更多 bug。
Mark Doliner 的 Cobertura (cobertura 在西班牙语是覆盖的意思)是完成这项任务的一个免费 GPL 工具。Cobertura 通过用额外的语句记录在执行测试包时,哪些行被测试到、哪些行没有被测试到,通过这种方式来度量字节码,以便对测试进行监视。然后它生成一个 HTML 或者 XML 格式的报告,指出代码中的哪些包、哪些类、哪些方法和哪些行没有测试到。可以针对这些特定的区域编写更多的测试代码,以发现所有隐藏的 bug。
我们首先查看生成的 Cobertura 输出。图 1 显示了对 Jaxen 测试包运行 Cobertura 生成的报告。从该报告中,可以看到从很好(在
org.jaxen.expr.iter包中几乎是 100%)到极差(在org.jaxen.dom.html中完全没有覆盖)的覆盖率结果。
图 1. Jaxen 的包级别覆盖率统计数据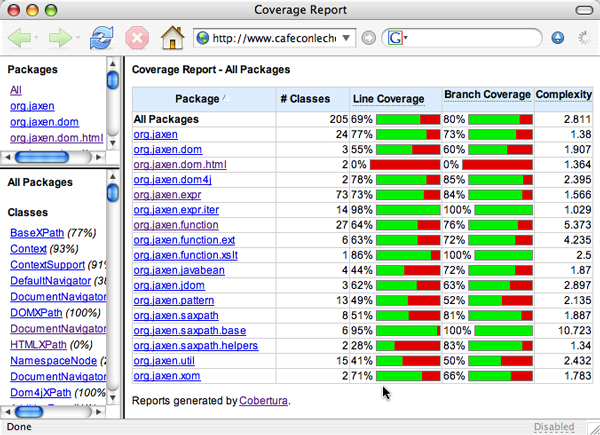
Cobertura 通过被测试的行数和被测试的分支数来计算覆盖率。第一次测试时,两种测试方法之间的差别并不是很重要。Cobertura 还为类计算平均 McCabe 复杂度。
可以深入挖掘 HTML 报告,了解特定包或者类的覆盖率。图 2 显示了
org.jaxen.function包的覆盖率统计。在这个包中,覆盖率的范围从SumFunction类的 100% 到IdFunction类的仅为 5%。
图 2. org.jaxen.function 包中的代码覆盖率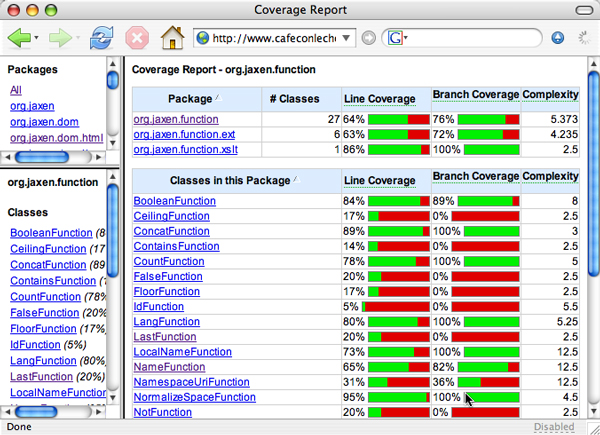
进一步深入到单独的类中,具体查看哪一行代码没有测试到。图 3 显示了
NameFunction类中的部分覆盖率。最左边一栏显示行号。后一栏显示了执行测试时这一行被执行的次数。可以看出,第 112 行被执行了 100 次,第 114 行被执行了 28 次。用红色突出显示的那些行则根本没有测试到。这个报告表明,虽然从总体上说该方法被测试到了,但实际上还有许多分支没有测试到。
图 3. NameFunction 类中的代码覆盖率

Cobertura 是 jcoverage 的分支。GPL 版本的 jcoverage 已经有一年没有更新过了,并且有一些长期存在的 bug,Cobertura 修复了这些 bug。原来的那些 jcoverage 开发人员不再继续开发开放源码,他们转向开发 jcoverage 的商业版和 jcoverage+,jcoverage+ 是一个从同一代码基础中发展出来的封闭源代码产品。开放源码的奇妙之处在于:一个产品不会因为原开发人员决定让他们的工作获得相应的报酬而消亡。
利用 Cobertura 报告,可以找出代码中未测试的部分并针对它们编写测试。例如,图 3 显示 Jaxen 需要进行一些测试,运用
name()函数对文字节点、注释节点、处理指令节点、属性节点和名称空间节点进行测试。如果有许多未覆盖的代码,像 Cobertura 在这里报告的那样,那么添加所有缺少的测试将会非常耗时,但也是值得的。不一定要一次完成它。您可以从被测试的最少的代码开始,比如那些所有没有覆盖的包。在测试所有的包之后,就可以对每一个显示为没有覆盖的类编写一些测试代码。对所有类进行专门测试后,还要为所有未覆盖的方法编写测试代码。在测试所有方法之后,就可以开始分析对未测试的语句进行测试的必要性。
是否有一些可以测试但不应测试的内容?这取决于您问的是谁。在 JUnit FAQ 中,J. B. Rainsberger 写到“一般的看法是:如果 自身 不会出问题,那么它会因为太简单而不会出问题。第一个例子是
getX()方法。假定getX()方法只提供某一实例变量的值。在这种情况下,除非编译器或者解释器出了问题,否则getX()是不会出问题的。因此,不用测试getX(),测试它不会带来任何好处。对于setX()方法来说也是如此,不过,如果setX()方法确实要进行任何参数验证,或者说确实有副作用,那么还是有必要对其进行测试。”理论上,对未覆盖的代码编写测试代码不一定就会发现 bug。但在实践中,我从来没有碰到没有发现 bug 的情况。未测试的代码充满了 bug。所做的测试越少,在代码中隐藏的、未发现的 bug 就会越多。
我不同意。我已经记不清在“简单得不会出问题”的代码中发现的 bug 的数量了。确实,一些 getter 和 setter 很简单,不可能出问题。但是我从来就没有办法区分哪些方法是真的简单得不会出错,哪些方法只是看上去如此。编写覆盖像 setter 和 getter 这样简单方法的测试代码并不难。为此所花的少量时间会因为在这些方法中发现未曾预料到的 bug 而得到补偿。
一般来说,开始测量后,达到 90% 的测试覆盖率是很容易的。将覆盖率提高到 95% 或者更高就需要动一下脑筋。例如,可能需要装载不同版本的支持库,以测试没有在所有版本的库中出现的 bug。或者需要重新构建代码,以便测试通常执行不到的部分代码。可以对类进行扩展,让它们的受保护方法变为公共方法,这样就可以对这些方法进行测试。这些技巧看起来像是多此一举,但是它们曾帮助我在一半的时间内发现更多的未发现的 bug。
并不总是可以得到完美的、100% 的代码覆盖率。有时您会发现,不管对代码如何改造,仍然有一些行、方法、甚至是整个类是测试不到的。下面是您可能会遇到的挑战的一些例子:
- 只在特定平台上执行的代码。例如,在一个设计良好的 GUI 应用程序中,添加一个 Exit 菜单项的代码可以在 Windows PC 上运行,但它不能在 Mac 机上运行。
- 捕获不会发生的异常的
catch语句,比如在从ByteArrayInputStream进行读取操作时抛出的IOException。
- 非公共类中的一些方法,它们永远也不会被实际调用,只是为了满足某个接口契约而必须实现。
- 处理虚拟机 bug 的代码块,比如说,不能识别 UTF-8 编码。
考虑到上面这些以及类似的情况,我认为一些极限程序员自动删除所有未测试代码的做法是不切实际的,并且可能具有一定的讽刺性。不能总是获得绝对完美的测试覆盖率并不意味着就不会有更好的覆盖率。
然而,比执行不到的语句和方法更常见的是残留代码,它不再有任何作用,并且从代码基中去掉这些代码也不会产生任何影响。有时可以通过使用反射来访问私有成员这样的怪招来测试未测试的代码。还可以为未测试的、包保护(package-protected)的代码来编写测试代码,将测试类放到将要测试的类所在那个包中。但最好不要这样做。所有不能通过发布的(公共的和受保护的)接口访问的代码都应删除。执行不到的代码不应当成为代码基的一部分。代码基越小,它就越容易被理解和维护。
不要漏掉测量单元测试包和类本身。我不止一次注意到,某些个测试方法或者类没有被测试包真正运行。通常这表明名称规范中存在问题(比如将一个方法命名为
tesSomeReallyComplexCondition,而不是将其命名为testSomeReallyComplexCondition),或者忘记将一个类添加到主suite()方法中。在其他情况下,未预期的条件导致跳过了测试方法中的代码。不管是什么情况,都是虽然已经编写了测试代码,但没有真正运行它。JUnit 不会告诉您它没有像您所想的那样运行所有测试,但是 Cobertura 会告诉您。找出了未运行的测试后,改正它一般很容易。
在了解了测量代码覆盖率的好处后,让我们再来讨论一下如何用 Cobertura 测量代码覆盖率的具体细节。Cobertura 被设计成为在 Ant 中运行。现在还没有这方面的 IDE 插件可用,不过一两年内也许就会有了。
首先需要在 build.xml 文件中添加一个任务定义。以下这个顶级
taskdef元素将 cobertura.jar 文件限定在当前工作目录中:<taskdef classpath="cobertura.jar" resource="tasks.properties" />
然后,需要一个
cobertura-instrument任务,该任务将在已经编译好的类文件中添加日志代码。todir属性指定将测量类放到什么地方。fileset子元素指定测量哪些 .class 文件:<target name="instrument"> <cobertura-instrument todir="target/instrumented-classes"> <fileset dir="target/classes"> <include name="**/*.class"/> </fileset> </cobertura-instrument> </target>
用通常运行测试包的同一种类型的 Ant 任务运行测试。惟一的区别在于:被测量的类必须在原始类出现在类路径中之前出现在类路径中,而且需要将 Cobertura JAR 文件添加到类路径中:
<target name="cover-test" depends="instrument"> <mkdir dir="${testreportdir}" /> <junit dir="./" failureproperty="test.failure" printSummary="yes" fork="true" haltonerror="true"> <!-- Normally you can create this task by copying your existing JUnit target, changing its name, and adding these next two lines. You may need to change the locations to point to wherever you've put the cobertura.jar file and the instrumented classes. --> <classpath location="cobertura.jar"/> <classpath location="target/instrumented-classes"/> <classpath> <fileset dir="${libdir}"> <include name="*.jar" /> </fileset> <pathelement path="${testclassesdir}" /> <pathelement path="${classesdir}" /> </classpath> <batchtest todir="${testreportdir}"> <fileset dir="src/java/test"> <include name="**/*Test.java" /> <include name="org/jaxen/javabean/*Test.java" /> </fileset> </batchtest> </junit> </target>>
Jaxen 项目使用 JUnit 作为其测试框架,但是 Cobertura 是不受框架影响的。它在 TestNG、Artima SuiteRunner、HTTPUni 或者在您自己在地下室开发的系统中一样工作得很好。
最后,
cobertura-report任务生成本文开始部分看到的那个 HTML 文件:<target name="coverage-report" depends="cover-test"> <cobertura-report srcdir="src/java/main" destdir="cobertura"/> </target>
srcdir属性指定原始的 .java 源代码在什么地方。destdir属性指定 Cobertura 放置输出 HTML 的那个目录的名称。在自己的 Ant 编译文件中加入了类似的任务后,就可以通过键入以下命令来生成一个覆盖报告:
% ant instrument % ant cover-test % ant coverage-report
当然,如果您愿意的话,还可以改变目标任务的名称,或者将这三项任务合并为一个目标任务。
Cobertura 是敏捷程序员工具箱中新增的一个重要工具。通过生成代码覆盖率的具体数值,Cobertura 将单元测试从一种艺术转变为一门科学。它可以寻找测试覆盖中的空隙,直接找到 bug。测量代码覆盖率使您可以获得寻找并修复 bug 所需的信息,从而开发出对每个人来说都更健壮的软件。
- 只在特定平台上执行的代码。例如,在一个设计良好的 GUI 应用程序中,添加一个 Exit 菜单项的代码可以在 Windows PC 上运行,但它不能在 Mac 机上运行。
-
精妙Sql语句
2009-02-26 17:54:20
-
Web的系统测试方法
2009-02-26 15:36:15
随着Internet和Intranet/Extranet的快速增长,Web已经对商业、工业、银行、财政、教育、政府和娱乐及我们的工作和生活产生了深远的影响。许多传统的信息和数据库系统正在被移植到互联网上,电子商务迅速增长,早已超过了国界。范围广泛的、复杂的分布式应用正在Web环境中出现。Web的流行和无所不在,是因为它能提供支持所有类型内容连接的信息发布,容易为最终用户存取。
Yogesh Deshpande和Steve Hansen在1998年就提出了Web工程的概念。Web工程作为一门新兴的学科,提倡使用一个过程和系统的方法来开发高质量的基于Web的系统。它"使用合理的、科学的工程和管理原则,用严密的和系统的方法来开发、发布和维护基于Web的系统"。目前,对于web工程的研究主要是在国外开展的,国内还刚刚起步。
在基于Web的系统开发中,如果缺乏严格的过程,我们在开发、发布、实施和维护Web的过程中,可能就会碰到一些严重的问题,失败的可能性很大。而且,随着基于Web的系统变得越来越复杂,一个项目的失败将可能导致很多问题。当这种情况发生时,我们对Web和Internet的信心可能会无法挽救地动摇,从而引起Web危机。并且,Web危机可能会比软件开发人员所面对的软件危机更加严重、更加广泛。
在Web工程过程中,基于Web系统的测试、确认和验收是一项重要而富有挑战性的工作。基于Web的系统测试与传统的软件测试不同,它不但需要检查和验证是否按照设计的要求运行,而且还要测试系统在不同用户的浏览器端的显示是否合适。重要的是,还要从最终用户的角度进行安全性和可用性测试。然而,Internet和Web媒体的不可预见性使测试基于Web的系统变得困难。因此,我们必须为测试和评估复杂的基于Web的系统研究新的方法和技术。
一般软件的发布周期以月或以年计算,而Web应用的发布周期以天计算甚至以小时计算。Web测试人员必须处理更短的发布周期,测试人员和测试管理人员面临着从测试传统的C/S结构和框架环境到测试快速改变的Web应用系统的转变。
一、功能测试
1、链接测试
链接是Web应用系统的一个主要特征,它是在页面之间切换和指导用户去一些不知道地址的页面的主要手段。链接测试可分为三个方面。首先,测试所有链接是否按指示的那样确实链接到了该链接的页面;其次,测试所链接的页面是否存在;最后,保证Web应用系统上没有孤立的页面,所谓孤立页面是指没有链接指向该页面,只有知道正确的URL地址才能访问。
链接测试可以自动进行,现在已经有许多工具可以采用。链接测试必须在集成测试阶段完成,也就是说,在整个Web应用系统的所有页面开发完成之后进行链接测试。
2、表单测试
当用户给Web应用系统管理员提交信息时,就需要使用表单操作,例如用户注册、登陆、信息提交等。在这种情况下,我们必须测试提交操作的完整性,以校验提交给服务器的信息的正确性。例如:用户填写的出生日期与职业是否恰当,填写的所属省份与所在城市是否匹配等。如果使用了默认值,还要检验默认值的正确性。如果表单只能接受指定的某些值,则也要进行测试。例如:只能接受某些字符,测试时可以跳过这些字符,看系统是否会报错。
3、Cookies测试
Cookies通常用来存储用户信息和用户在某应用系统的操作,当一个用户使用Cookies访问了某一个应用系统时,Web服务器将发送关于用户的信息,把该信息以Cookies的形式存储在客户端计算机上,这可用来创建动态和自定义页面或者存储登陆等信息。
如果Web应用系统使用了Cookies,就必须检查Cookies是否能正常工作。测试的内容可包括Cookies是否起作用,是否按预定的时间进行保存,刷新对Cookies有什么影响等。
4、设计语言测试
Web设计语言版本的差异可以引起客户端或服务器端严重的问题,例如使用哪种版本的HTML等。当在分布式环境中开发时,开发人员都不在一起,这个问题就显得尤为重要。除了HTML的版本问题外,不同的脚本语言,例如Java、JavaScript、 ActiveX、VBScript或Perl等也要进行验证。
5、数据库测试
在Web应用技术中,数据库起着重要的作用,数据库为Web应用系统的管理、运行、查询和实现用户对数据存储的请求等提供空间。在Web应用中,最常用的数据库类型是关系型数据库,可以使用SQL对信息进行处理。
在使用了数据库的Web应用系统中,一般情况下,可能发生两种错误,分别是数据一致性错误和输出错误。数据一致性错误主要是由于用户提交的表单信息不正确而造成的,而输出错误主要是由于网络速度或程序设计问题等引起的,针对这两种情况,可分别进行测试。
二、性能测试
1、连接速度测试
用户连接到Web应用系统的速度根据上网方式的变化而变化,他们或许是电话拨号,或是宽带上网。当下载一个程序时,用户可以等较长的时间,但如果仅仅访问一个页面就不会这样。如果Web系统响应时间太长(例如超过5秒钟),用户就会因没有耐心等待而离开。
另外,有些页面有超时的限制,如果响应速度太慢,用户可能还没来得及浏览内容,就需要重新登陆了。而且,连接速度太慢,还可能引起数据丢失,使用户得不到真实的页面。
2、负载测试
负载测试是为了测量Web系统在某一负载级别上的性能,以保证Web系统在需求范围内能正常工作。负载级别可以是某个时刻同时访问Web系统的用户数量,也可以是在线数据处理的数量。例如:Web应用系统能允许多少个用户同时在线?如果超过了这个数量,会出现什么现象?Web应用系统能否处理大量用户对同一个页面的请求?
3、压力测试
负载测试应该安排在Web系统发布以后,在实际的网络环境中进行测试。因为一个企业内部员工,特别是项目组人员总是有限的,而一个Web系统能同时处理的请求数量将远远超出这个限度,所以,只有放在Internet上,接受负载测试,其结果才是正确可信的。
进行压力测试是指实际破坏一个Web应用系统,测试系统的反映。压力测试是测试系统的限制和故障恢复能力,也就是测试Web应用系统会不会崩溃,在什么情况下会崩溃。黑客常常提供错误的数据负载,直到Web应用系统崩溃,接着当系统重新启动时获得存取权。
压力测试的区域包括表单、登陆和其他信息传输页面等。
三、可用性测试
1、导航测试
导航描述了用户在一个页面内操作的方式,在不同的用户接口控制之间,例如按钮、对话框、列表和窗口等;或在不同的连接页面之间。通过考虑下列问题,可以决定一个Web应用系统是否易于导航:导航是否直观?Web系统的主要部分是否可通过主页存取?Web系统是否需要站点地图、搜索引擎或其他的导航帮助?
在一个页面上放太多的信息往往起到与预期相反的效果。Web应用系统的用户趋向于目的驱动,很快地扫描一个Web应用系统,看是否有满足自己需要的信息,如果没有,就会很快地离开。很少有用户愿意花时间去熟悉Web应用系统的结构,因此,Web应用系统导航帮助要尽可能地准确。
导航的另一个重要方面是Web应用系统的页面结构、导航、菜单、连接的风格是否一致。确保用户凭直觉就知道Web应用系统里面是否还有内容,内容在什么地方。
Web应用系统的层次一旦决定,就要着手测试用户导航功能,让最终用户参与这种测试,效果将更加明显。
2、图形测试
在Web应用系统中,适当的图片和动画既能起到广告宣传的作用,又能起到美化页面的功能。一个Web应用系统的图形可以包括图片、动画、边框、颜色、字体、背景、按钮等。图形测试的内容有:
(1)要确保图形有明确的用途,图片或动画不要胡乱地堆在一起,以免浪费传输时间。Web应用系统的图片尺寸要尽量地小,并且要能清楚地说明某件事情,一般都链接到某个具体的页面。
(2)验证所有页面字体的风格是否一致。
(3)背景颜色应该与字体颜色和前景颜色相搭配。
(4)图片的大小和质量也是一个很重要的因素,一般采用JPG或GIF压缩。
3、内容测试
内容测试用来检验Web应用系统提供信息的正确性、准确性和相关性。
信息的正确性是指信息是可靠的还是误传的。例如,在商品价格列表中,错误的价格可能引起财政问题甚至导致法律纠纷;信息的准确性是指是否有语法或拼写错误。这种测试通常使用一些文字处理软件来进行,例如使用Microsoft Word的"拼音与语法检查"功能;信息的相关性是指是否在当前页面可以找到与当前浏览信息相关的信息列表或入口,也就是一般Web站点中的所谓"相关文章列表"。
4、整体界面测试
整体界面是指整个Web应用系统的页面结构设计,是给用户的一个整体感。例如:当用户浏览Web应用系统时是否感到舒适,是否凭直觉就知道要找的信息在什么地方?整个Web应用系统的设计风格是否一致?
对整体界面的测试过程,其实是一个对最终用户进行调查的过程。一般Web应用系统采取在主页上做一个调查问卷的形式,来得到最终用户的反馈信息。
对所有的可用性测试来说,都需要有外部人员(与Web应用系统开发没有联系或联系很少的人员)的参与,最好是最终用户的参与。
四、客户端兼容性测试
1、平台测试
市场上有很多不同的操作系统类型,最常见的有Windows、Unix、Macintosh、Linux等。Web应用系统的最终用户究竟使用哪一种操作系统,取决于用户系统的配置。这样,就可能会发生兼容性问题,同一个应用可能在某些操作系统下能正常运行,但在另外的操作系统下可能会运行失败。
因此,在Web系统发布之前,需要在各种操作系统下对Web系统进行兼容性测试。
2、浏览器测试
浏览器是Web客户端最核心的构件,来自不同厂商的浏览器对Java,、JavaScript、 ActiveX、 plug-ins或不同的HTML规格有不同的支持。例如,ActiveX是Microsoft的产品,是为Internet Explorer而设计的,JavaScript是Netscape的产品,Java是Sun的产品等等。另外,框架和层次结构风格在不同的浏览器中也有不同的显示,甚至根本不显示。不同的浏览器对安全性和Java的设置也不一样。
测试浏览器兼容性的一个方法是创建一个兼容性矩阵。在这个矩阵中,测试不同厂商、不同版本的浏览器对某些构件和设置的适应性。
五、安全性测试
Web应用系统的安全性测试区域主要有:
(1)现在的Web应用系统基本采用先注册,后登陆的方式。因此,必须测试有效和无效的用户名和密码,要注意到是否大小写敏感,可以试多少次的限制,是否可以不登陆而直接浏览某个页面等。
(2)Web应用系统是否有超时的限制,也就是说,用户登陆后在一定时间内(例如15分钟)没有点击任何页面,是否需要重新登陆才能正常使用。
(3)为了保证Web应用系统的安全性,日志文件是至关重要的。需要测试相关信息是否写进了日志文件、是否可追踪(4)当使用了安全套接字时,还要测试加密是否正确,检查信息的完整性。
(5)服务器端的脚本常常构成安全漏洞,这些漏洞又常常被黑客利用。所以,还要测试没有经过授权,就不能在服务器端放置和编辑脚本的问题。
六、总结
本文从功能、性能、可用性、客户端兼容性、安全性等方面讨论了基于Web的系统测试方法。
基于Web的系统测试与传统的软件测试既有相同之处,也有不同的地方,对软件测试提出了新的挑战。基于Web的系统测试不但需要检查和验证是否按照设计的要求运行,而且还要评价系统在不同用户的浏览器端的显示是否合适。重要的是,还要从最终用户的角度进行安全性和可用性测试。
-
LoadRunner下DLL的调用
2009-02-26 15:30:21
动态链接库的编写
在Visual C++6.0开发环境下,打开FileNewProject选项,可以选择Win32 Dynamic-Link Library建立一个空的DLL工程。
1. Win32 Dynamic-Link Library方式创建Non-MFC DLL动态链接库每一个DLL必须有一个入口点,这就象我们用C编写的应用程序一样,必须有一个WINMAIN函数一样。在Non-MFC DLL中DllMain是一个缺省的入口函数,你不需要编写自己的DLL入口函数,用这个缺省的入口函数就能使动态链接库被调用时得到正确的初始化。如果应用程序的DLL需要分配额外的内存或资源时,或者说需要对每个进程或线程初始化和清除操作时,需要在相应的DLL工程的.CPP文件中对DllMain ()函数按照下面的格式书写。
BOOL APIENTRY DllMain(HANDLE hModule,DWORD ul_reason_for_call,LPVOID lpReserved)
{
switch( ul_reason_for_call )
{
case DLL_PROCESS_ATTACH:
break;
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
case DLL_PROCESS_DETACH:
break;
default:
break;
}
return TRUE;
}
参数中,hMoudle是动态库被调用时所传递来的一个指向自己的句柄(实际上,它是指向_DGROUP段的一个选择符); ul_reason_for_call是一个说明动态库被调原因的标志,当进程或线程装入或卸载动态链接库的时候,操作系统调用入口函数,并说明动态链接库被调用的原因,它所有的可能值为:DLL_PROCESS_ATTACH: 进程被调用、DLL_THREAD_ATTACH: 线程被调用、DLL_PROCESS_DETACH: 进程被停止、DLL_THREAD_DETACH: 线程被停止;lpReserved为保留参数。到此为止,DLL的入口函数已经写了,剩下部分的实现也不难,你可以在DLL工程中加入你所想要输出的函数或变量了。
我们已经知道DLL是包含若干个函数的库文件,应用程序使用DLL中的函数之前,应该先导出这些函数,以便供给应用程序使用。要导出这些函数有两种方法,一是在定义函数时使用导出关键字_declspec(dllexport),另外一种方法是在创建DLL文件时使用模块定义文件.Def。需要读者注意的是在使用第一种方法的时候,不能使用DEF文件。下面通过两个例子来说明如何使用这两种方法创建DLL文件。
1)使用导出函数关键字_declspec(dllexport)创建MyDll.dll,该动态链接库中有两个函数,分别用来实现得到两个数的最大和最小数。在MyDll.h和MyDLL.cpp文件中分别输入如下原代码:
//MyDLL.h
extern "C" _declspec(dllexport) int desinit(int mode);
extern "C" _declspec(dllexport) void desdone(void);
extern "C" _declspec(dllexport) void des_setkey(char *subkey, char *key);
extern "C" _declspec(dllexport) void endes(char *block, char *subkey);
extern "C" _declspec(dllexport) void dedes(char *block, char *subkey);
//MyDll.cpp
#include"MyDll.h"
//这里我用了比较大小的函数代替了我要实现的函数
int desinit(int a, int b)
{
if(a>=b)return a;
else
return b;
}
int desdone(int a, int b)
{
if(a>=b)return b;
else
return a;
}
该动态链接库编译成功后,打开MyDll工程中的debug目录,可以看到MyDll.dll、MyDll.lib两个文件。LIB文件中包含DLL文件名和DLL文件中的函数名等,该LIB文件只是对应该DLL文件的"映像文件",与DLL文件中,LIB文件的长度要小的多,在进行隐式链接DLL时要用到它。读者可能已经注意到在MyDll.h中有关键字"extern C",它可以使其他编程语言访问你编写的DLL中的函数。
LoadRunner调用动态链接库
上面完成动态链接库开发后,下面就介绍动态链接库如何被LoadRunner进行调用,其实也是很简单的。在LoadRunner中的DLL调用有局部调用与全局调用,下面介绍局部调用。
首先把你编译的DLL放在角本路径下面,这里是MyDll.dll,MyDll.lib.然后在Action中使用
lr_load_dll("MYDll.dll"),此函数可以把DLL加载进来,让你调用DLL里面的函数,而DLL中的运算是编译级的,所以效率极高,代码样例如下:
#include "lrs.h"
Action()
{
//
int nRet = 6;
char srckey[129];
memset(srckey, 'a', 128);
lr_message(lr_eval_string(srckey));
lr_load_dll("MyDLL.dll");
nRet = desinit(5,8);
lr_message("比较的结果为%d",nRet);
return 0;
}
运行结果
比较的结果为8
全局的动态链接库的调用则需要修改mdrv.dat,路径在LoadRunner的安装目录下面(LoadRunner/dat directory);在里面修改如例:
[WinSock]
ExtPriorityType=protocol
WINNT_EXT_LIBS=wsrun32.dll
WIN95_EXT_LIBS=wsrun32.dll
LINUX_EXT_LIBS=liblrs.so
SOLARIS_EXT_LIBS=liblrs.so
HPUX_EXT_LIBS=liblrs.sl
AIX_EXT_LIBS=liblrs.so
LibCfgFunc=winsock_exten_conf
UtilityExt=lrun_api
ExtMessageQueue=0
ExtCmdLineOverwrite=-WinInet No
ExtCmdLineConc=-UsingWinInet No
WINNT_DLLS=user_dll1.dll, user_dll2.dll, ...
//最后一行是加载你需要的DLL
这样你就可以在LR中随意的调用程序员写的API函数,进行一些复杂的数据加密,准备的一些操作进行复杂的测试.同时如果你觉的有大量高复杂的运算也可以放在DLL中进行封装,以提高效率。 -
修改系统配置:让XP不再越用越慢
2009-02-26 14:54:19
-
sql
2008-08-19 11:13:40
1、用户
查看当前用户的缺省表空间
SQL>select username,default_tablespace from user_users;查看当前用户的角色
SQL>select * from user_role_privs;查看当前用户的系统权限和表级权限
SQL>select * from user_sys_privs;
SQL>select * from user_tab_privs;显示当前会话所具有的权限
SQL>select * from session_privs;显示指定用户所具有的系统权限
SQL>select * from dba_sys_privs where grantee='GAME';显示特权用户
select * from v$pwfile_users;显示用户信息(所属表空间)
select default_tablespace,temporary_tablespace
from dba_users where username='GAME';显示用户的PROFILE
select profile from dba_users where username='GAME';
2、表查看用户下所有的表
SQL>select * from user_tables;查看名称包含log字符的表
SQL>select object_name,object_id from user_objects
where instr(object_name,'LOG')>0;查看某表的创建时间
SQL>select object_name,created from user_objects where object_name=upper('&table_name');查看某表的大小
SQL>select sum(bytes)/(1024*1024) as "size(M)" from user_segments
where segment_name=upper('&table_name');查看放在ORACLE的内存区里的表
SQL>select table_name,cache from user_tables where instr(cache,'Y')>0;3、索引
查看索引个数和类别
SQL>select index_name,index_type,table_name from user_indexes order by table_name;查看索引被索引的字段
SQL>select * from user_ind_columns where index_name=upper('&index_name');查看索引的大小
SQL>select sum(bytes)/(1024*1024) as "size(M)" from user_segments
where segment_name=upper('&index_name');4、序列号
查看序列号,last_number是当前值
SQL>select * from user_sequences;5、视图
查看视图的名称
SQL>select view_name from user_views;查看创建视图的select语句
SQL>set view_name,text_length from user_views;
SQL>set long 2000; 说明:可以根据视图的text_length值设定set long 的大小
SQL>select text from user_views where view_name=upper('&view_name');6、同义词
查看同义词的名称
SQL>select * from user_synonyms;7、约束条件
查看某表的约束条件
SQL>select constraint_name, constraint_type,search_condition, r_constraint_name
from user_constraints where table_name = upper('&table_name');SQL>select c.constraint_name,c.constraint_type,cc.column_name
from user_constraints c,user_cons_columns cc
where c.owner = upper('&table_owner') and c.table_name = upper('&table_name')
and c.owner = cc.owner and c.constraint_name = cc.constraint_name
order by cc.position;8、存储函数和过程
查看函数和过程的状态
SQL>select object_name,status from user_objects where object_type='FUNCTION';
SQL>select object_name,status from user_objects where object_type='PROCEDURE';查看函数和过程的源代码
SQL>select text from all_source where ōwner=user and name=upper('&plsql_name'); -
JUnit测试程式
2008-06-30 17:23:56

junit测试程式编写规范
一、 程式命名规范
1.测试类的命名
测试类的命名规则是:被测试类的类名+test
比如有一个类叫irgsrhdelegate,那么他的测试类的命名就是irgsrhdelegatetest
2.测试用例的命名
测试用例的命名规则是:test+用例方法名称
比如要测试的方法叫updatedata,那么测试用例的命名就是testupdatedata
(说明:“用例方法”就是指被测试的类中所包含的方法,而“测试用例”就是指测试类中所包含的方法)
比如irgsrhdelegate中有一个方法叫做findbyirgfindparam,那么在irgsrhdelegatetest中对应的测试用例名称就是testfindbyirgfindparam。
3.其他命名规范
本规范未说明的其他命名规范请参照《java语言编码规范》(eno-w063-java coding rule.doc)。
二、 测试程式的包名定义规范
为了保持测试程式的单独和稳定性,请按照下面的方式组织测试程式:
假如被测试类的包名是com.wistrons.util,那么测试类的包名就是test.com.wistrons.util。也就是说在被测试类的包名前加上“test.”,这就是测试类的包名。
三、 测试数据的准备方案
准备测试数据时有三种方案能够选择。
1.在程式中直接写入测试数据
在要输入的数据项不多的情况下能够采用这种方式
2.使用junitpack包中的inputdatautil工具类
(要使用这个工具,请在测试程式中加上import junitpack.inputdatautil)
这种方法需要把测试数据写在一个xml文档中,xml的格式如下所示:
<?xml version="1.0" encoding="utf-8"?>
<inputs>
<input>
<irgcd>h0001</irgcd>
<irgname></irgname>
<irgkname></irgkname>
</input>
<input>
…
</input>
…
</inputs>
在这个xml文档中的根节点为inputs,根节点下能够有多个input节点。每个input节点代表一个case中需要的任何数据。
使用这个工具类的操作步骤如下:
1) 获取xml的存放路径。
请把写好的xml存放在测试类所在的目录中,然后能够按如下方式取得xml的存放路径:
string xml = irgsrhdelegatetest.class.getresource(".").tostring() +"test.xml";
2) 创建inputdatautil的实例。
inputdatautil inpututil = new inputdatautil();
3) 在inputdatautil实例中配置接受数据的类名,inputdatautil将此类和xml进行数据绑定。
inpututil.setclassname("jp.co.liondor.common.fz25irgsrh. seekirgsrhopt");
4) 调用inputdatautil.parse()方法,从xml中采集数据
java.util.vector vector = (java.util.vector) inpututil.parse(xml);
5) 从vector中取出被绑定类的实例
for (int i = 0; i < vector.size(); i++) {
seekirgsrhopt ōpt = (seekirgsrhopt) vector.get(i);
…
}
现在对inputdatautil的工作原理进行说明。inputdatautil会根据input节点下的子节点名来配置被绑定的类中对应的set方法,然后把xml中的数据配置到被绑定类中。比如上例xml中,input节点下有三个子节点:irgcd、irgname、irgkname。那么在调用inputdatautil.parse()方法时,inputdatautil就会分别调用seekirgsrhopt类的setirgcd()、setirgname()、setirgkname()方法,把数据配置到seekirgsrhopt的实例类中,并返回包含这些实例类的vector对象。
3.使用digester
(要使用这个工具,请在测试程式中加上import org.apache.commons.digester.digester)
digester是apache提供的一个工具类,上面的inputdatautil也是从digester类继承的。当使用inputdatautil暂时无法解决的时候,能够直接使用digester。
使用digester的步骤如下:
1) 获取xml的存放路径。
获取方式和使用inputdatautil相同。
2) 创建digester的实例。
digester dig = new digester();
3) 设定和inputs节点绑定的类为vector
dig.addobjectcreate("inputs", "java.util.vector");
4) 设定和input节点绑定的类
dig.addobjectcreate("inputs/input",
" jp.co.liondor.common.fz25irgsrh. seekirgsrhopt ");
5) 根据input节点下的子节点,依次设定相应的set方法
dig.addcallmethod("inputs/input/ irgcd ", "setirgcd ", 1);
dig.addcallparam("inputs/input/ irgcd ", 0);
6) 设定向vector中加入数据的方法
dig.addsetnext("inputs/input", "add");
7) 调用digester.parse()方法,从xml中采集数据
java.util.vector vector = (java.util.vector) dig.parse(xml);
8) 从vector中取出被绑定类的实例
for (int i = 0; i < vector.size(); i++) {
seekirgsrhopt ōpt = (seekirgsrhopt) vector.get(i);
…
}
digester的用法很灵活,能够组织很复杂的数据。
关于digester的周详用法请参考http://jakarta.apache.org/commons/digester/。
四、 对ui测试的原则
对ui做单元测试必须做到不能牵涉到业务逻辑操作(比如数据库操作、和server的交互)。否则就是ui的设计不合理。对ui的单元测试应该很单纯,就只是测试界面的动作是否符合设计需要。
五、 测试数据的覆盖率
测试时所准备的测试数据要覆盖程式中任何可能出现的case。
六、 测试记录
记录测试的过程和结果,请使用log4j工具。
七、 测试粒度
选择测试粒度的原则:
1) 被测试类中任何public、protected方法都要测到。
2) 对于简单的set和get方法没有必要做测试。 -
spring
2008-06-26 17:12:50
1. 前言
此文档讲述的内容适合于对 Spring MVC 和数据持久层 ORM 概念有一定基础的开发者,着重于讲述基于 Spring 框架基础之上进行 Java 开发的其中一种技术解决方案,而不是讲述相关技术的原理,想要了解技术原理内容请参考相关文档资料。
现在,网络上流传的Spring+Struts+Hibernate用得非常火,几乎成为很多对技术痴迷的人的技术架构标准,可是在我看来,也许是因为项目都不算大,人力也不够多,这个技术架构太复杂了。从Spring本身来讲,从MVC到数据操作,都可以不需要其他附加组件即可实现,并且结构清晰,使用简单,功能还更加强大,本文讲述的重点就是单独使用Spring来建立一个简易的开发框架。
首先说,为什么选择Spring呢?大概在2003年的时候,Struts已经开始流行了,但是在学习Struts的时候感觉这个技术框架比原始的JSP+JavaBean的方式复杂了很多,后来2004年做新项目时在论坛上看到推荐Spring,下载一试,上手非常的容易,结构也很清晰,支持的功能也非常多,所以决定用它了(其实那时候对于依赖注入和AOP代理还不甚了解,也很少用到接口)。
在2001-2003年的时候都是自己封装了JavaBean做为公共模块来访问数据库的,后来ORM兴起了,先是看了Hibernate的,3.0版还没用出,还不支持存储过程,因为那时候也做Delphi相关开发,用惯了SQL语句,始终觉得HQL这样的东东增加了开发的复杂度和不可控制性,原生的复杂SQL语句无法使用,不喜欢。后来看到了iBATIS,经过试用,正是我所需要的,SQL语句配置简单,基本不会破坏SQL语句的结构,这样将SQL语句Copy到外部数据库工具中进行调试也非常的方便,加上SQL语句可以使用很多的特定数据库的函数,执行效率和简洁性也非常好,修改了SQL又不需要重新编译程序。
有网友说Hibernate支持多个数据库移值啊,我认为这个就不仅仅是SQL语句的问题了,还有很多其他方面的因素,大多数项目都可以不用考虑。又有网友说Hibernate对于数据库结构修改的影响比较小,这种情况影响的也不仅仅是几句代码的问题,涉及到界面表现、业务流程等很多重要方面,相对说来修改代码倒是小Case了。
说完了上面的 ORM 组件,再说说 JDBC , Spring 的 JdbcTemplate 将我们常用的 JDBC 流程封装起来,使用非常简单,一般执行的 SQL 就是一句话,构造 SQL 随着业务的复杂而复杂,并且也支持 PrepareStatement 的执行模式避免 SQL 注入漏洞发生,同样具备完整的数据操作功能如查询、更新、存储过程、异常捕捉等等,经过几年的使用比较,我认为轻型的项目使用 JdbcTemplate 是非常不错的选择。
由于能力所限,其中细节如有欠缺之处,请多多批评指正。2. 参考资料
² Spring 官方网站: http://www.springframework.org/ ;
² Spring 2.0 中文参考手册: http://spring.jactiongroup.net/ ;
² Apache Jakarta 官方网站: http://jakarta.apache.org/ ;
² JSTL 官方网站: http://java.sun.com/products/jsp/jstl/ ;
² Intellij IDEA 官方网站: http://www.jetbrains.com/ ;
MVC 层在 Spring 的 AbstractController 类基础上进行了继承和重构,使整个框架仅使用单一的公共控制器,数据操作采用 Spring JdbcTemplate ,在逻辑层中直接集成了 Spring Jdbc 能力,可直接操作数据,表现层 Jstl ,除此之外,未定义任何的表单对象、数据库表映射对象和其他 ORM 的配置文件,在保留对关键功能的集成度的基础上技术入门度极低,重点关注业务功能和优化 SQL 语句 。
请求处理流传如图所示:
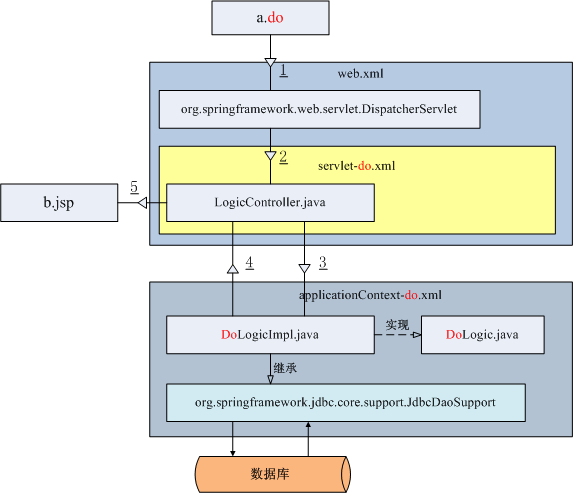
1) 用户访问 http://www.fyyk.com/a.do ;
2) Web 应用服务器(如 tomcat )解析扩展名为 *.do 的请求,通过 Spring 分发器 org.springframework.web.servlet.DispatcherServlet 读取 servlet-do.xml 中的配置,将请求转发给公共控制器类 LogicController.java ;
3) 公共控制器类 LogicController.java 根据 servlet-do.xml 文件中的配置信息调用 DoLogicImpl.java 类中相对应名称的方法;
4) DoLogicImpl.java 类中的方法在处理完成业务逻辑后,将数据内容 ModelAndView 返回给公共控制器类 LogicController.java ;
5) 公共控制器类 LogicController.java 处理 ModelAndView 信息,执行 b.jsp 将结果数据显示出来;
servlet-xxx.xml 文件中,封装后的 Controller 特点如下:
控制器类配置在1) 继承 AbstractController 类,便于调用应用环境的 Web 特性;
2) 只用控制器做请求的转发,业务实现全部在逻辑层;
3) 采用反映射机制( reflect ),运行期调用逻辑类中的方法,而请求 URI 、逻辑类和方法名之间的对应关系只需要在 servlet-xxx.xml 中配置,这样,控制器实现就只有唯一的一个类文件;
applicationContext-xxx.xml 文件配置 Bean 定义中,主要实现两项功能:一是处理业务逻辑,二是操作数据库;
逻辑层类在逻辑层类首先需要定义一个接口类,统一以 xxxLogic.java 命名,实现类命名为 xxxLogicImpl.java ,并继承 JdbcDaoSupport 类,这样逻辑类便具有了数据库访问能力。
逻辑类的方法如果被公共控制器类 LogicController.java 的反映射机制直接调用,则其接口类需要继承空的公共接口类 BasicLogic ,定义方法时参数和返回值是固定的,如果是被其他逻辑类调用则不需要。
public ModelAndView initLogin(HttpServletRequest request, HttpServletResponse response, ServletContext servletContext);
控制器层直接将请求的 request 、 response 和 servletContext 全部传递过来交由逻辑层自由控制,对于 request 中的表单数据,未采用 SimpleFormController 的模式定义表单对象,建议手工获取,从代码量本身来将并不复杂,反而更加灵活。在业务处理完成后,必须构造一个 ModelAndView 对象,作为方法返回值回传给控制器。
范例代码如下:
public class AdminLogicImpl extends JdbcDaoSupport implements AdminLogic
{
public ModelAndView insertUser(HttpServletRequest request, HttpServletResponse response,
ServletContext servletContext) throws DataAccessException
{
String userId = request.getParameter("userId");
String userName = request.getParameter("userName");
int age = Integer.parseInt(request.getParameter("age"));
double weight = Double.parseDouble(request.getParameter("weight"));
String sqlStr = "insert into testuser (userId,username,age,weight,updatetime) values (?,?,?,?,?)";
Object[] ōbject = new Object[]{userId, userName, age, weight, new Date()};
getJdbcTemplate().update(sqlStr, object);
Map<String, Object> model = new HashMap<String, Object>();
model.put("msg", " 插入用户成功! ");
model.put("url", "pageForm.user");
String view = "admin/message.jsp";
return new ModelAndView(view, model);
}
}
表现层采用 Jstl taglib 1.2 ,在 *.jsp 页面中加入 taglib 引用即可使用 Jstl 标签的大部分功能了,标签的具体使用方法请参考相关文档。
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<%@ taglib uri="http://java.sun.com/jsp/jstl/fmt" prefix="fmt" %>
<%@ taglib uri="http://java.sun.com/jsp/jstl/functions" prefix="fn" %>
4. 开发准备
4.1. 开发工具
Ø Java 编辑器 Intellij IDEA 6.0.5 、 Eclipse WTP 3.2 ;
Ø JDK5.0 Update 11 ;
Ø Web 服务器 Tomcat 5.5.20 ;
Ø 数据库 Oracle10g ;
4.2. 支撑库文件
spring.jar
spring
jstl.jar
standard.jar
Jstl 1.2
commons-io-
commons-fileupload-1.2.jar
文件上传组件
commons-logging-1.1.jar
log4j-
日志组件
mail.jar
activation.jar
邮件组件
quartz-
时序调度组件
aspectjweaver.jar
AOP 组件
commons-lang-2.3.jar
Apache 公共包
commons-codec-1.3.jar
commons-collections-3.2.jar
commons-httpclient-
Httpclient 组件
4.3. 系统目录结构
Java连接各种数据库的实例
2008-06-12 15:11:01
1、Oracle8/8i/9i数据库(thin模式)
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
String url="jdbc:oracle:thin:@localhost:1521:orcl";
//orcl为数据库的SID
String user="test\";
String password="test";
Connection conn= DriverManager.getConnection(url,user,password);2、DB2数据库
Class.forName("com.ibm.db2.jdbc.app.DB2Driver ").newInstance();
String url="jdbc:db2://localhost:5000/sample";
//sample为你的数据库名
String user="admin";
String password="";
Connection conn= DriverManager.getConnection(url,user,password);3、Sql Server7.0/2000数据库
Class.forName("com.microsoft.jdbc.sqlserver.SQLServerDriver").newInstance();
String url="jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=mydb";
//mydb为数据库
String user="sa";
String password="";
Connection conn= DriverManager.getConnection(url,user,password);4、Sybase数据库
Class.forName("com.sybase.jdbc.SybDriver").newInstance();
String url =" jdbc:sybase:Tds:localhost:5007/myDB";
//myDB为你的数据库名
Properties sysProps = System.getProperties();
SysProps.put("user","userid");
SysProps.put("password","user_password");
Connection conn= DriverManager.getConnection(url, SysProps);5、Informix数据库
Class.forName("com.informix.jdbc.IfxDriver").newInstance();
String url =
"jdbc:informix-sqli://123.45.67.89:1533/myDB:INFORMIXSERVER=myserver;
user=testuser;password=testpassword";
//myDB为数据库名
Connection conn= DriverManager.getConnection(url);6、MySQL数据库
Class.forName("org.gjt.mm.mysql.Driver").newInstance();
String url ="jdbc:mysql://localhost/myDB?user=soft&password=soft1234&useUnicode=true&characterEncoding=8859_1"
//myDB为数据库名
Connection conn= DriverManager.getConnection(url);7、PostgreSQL数据库
Class.forName("org.postgresql.Driver").newInstance();
String url ="jdbc:postgresql://localhost/myDB"
//myDB为数据库名
String user="myuser";
String password="mypassword";
Connection conn= DriverManager.getConnection(url,user,password);JSP/JSF WEB应用
2008-06-12 15:10:01
Java在最近几年逐渐升温,随着Java SE 5和Java SE 6的推出,Java的未来更显得无比辉煌。但以Java为基础的JSP在Java SE 5推出之前却一直抬不起头来,这最重要的原因就是JSP虽然功能十分强大,但最大的优点也是它的最大缺点,功能强大就意味着复杂,尤其是设计前端界面的可视化工具不多,也不够强大。因此,设计JSP页面就变得十分复杂和繁琐...Java在最近几年逐渐升温,随着Java SE 5和Java SE 6的推出,Java的未来更显得无比辉煌。但以Java为基础的JSP在Java SE 5推出之前却一直抬不起头来,这最重要的原因就是JSP虽然功能十分强大,但最大的优点也是它的最大缺点,功能强大就意味着复杂,尤其是设计前端界面的可视化工具不多,也不够强大。因此,设计JSP页面就变得十分复杂和繁琐。不过,在Java SE 5推出的同时,Sun为了简化JSP的开发难度,推出了新的JavaServer Faces(简称JSF)规范。从而使JSP走上了康庄大道。
一、什么是JSF
JSF和JSP是一对新的搭档。JSP是用于后台的逻辑处理的技术,而JSF恰恰相反,是使开发人员能够快速的开发基于 Java 的 Web 应用程序的技术,是一种表现层技术。目前,JSF1.2已经正式作为一个标准加入了Java EE 5中。
作为一种高度组件化的技术,开发人员可以在一些开发工具的支持下,实现拖拉式编辑操作,用户只需要简单的将 JSF 组件拖到页面上,就可以很容易的进行 Web 开发了。这是其作为一种组件化的技术所具有的最大好处,我们能用的组件不光是一些比较简单的输入框之类,还有更多复杂的组件可以使用的,比如 DataTable 这样的表格组件, Tree 这样的树形组件等等。
作为一种标准的技术,JSF还得到了相当多工具提供商的支持。同时我们也会有很多很好的免费开发工具可以使用,前不久 Sun Java Studio Creator 2 和 Oracle JDeveloper 10g 作为免费的支持 JSF 的开发工具发布,给 JSF 带来了不小的生气。另外我们也有一些很优秀的商业开发工具可共选择,BEA Workshop (原 M7 NitroX),Exadel,MyEclipse 这样的基于 Eclipse 的插件开发工具,为现在广大的 Eclipse 用户带来了不小的便利,IBM 的 Rational Application Developer 和 Borland 的 JBuilder 也是很不错的支持 JSF 可视化开发的商业开发工具。
JSF和传统的Web技术有着本质上的差别,在传统的Web技术需要用户自己对浏览器请求进行捕捉,保存客户端状态,并且手工控制着页面的转向,等等。而JSF的出现,无疑给我们带来了巨大的便利,JSF 提供了事件驱动的页面导航模型,该模型使应用程序开发人员能够设计应用程序的页面流。与 Struts 的方式向类似的是,所有的页面流信息都定义在 JSF 配置 XML 文件 (faces-config.xml) 中,而非硬编码在应用程序中。这很大程度简化了开发人员开发难度,简化了应用程序的开发。
同时JSF也是一种遵循模型-视图-控制器 (MVC) 模式的框架。实现了视图代码(View)与应用逻辑(Model)的完全分离,使得使用 JSF 技术的应用程序能够很好的实现页面与代码的分离。所有对 JSF 页面的请求都会通过一个前端控制器 (FacesServlet) 处理,系统自动处理用户的请求,并将结果返回给用户。这和传统的 MVC 框架并没有太大的区别。
在JSF中不仅使用了 POJO 技术,而且还使用了类似 Spring 的控制反转(IoC) (或称为依赖注入-DI) 技术,在 JSF 的 Backing Bean 中,我们可以把视图所需要的数据和操作放进一个 Backing Bean 中。同时得益于 JSF 使用的 DI 技术,我们可以在配置文件中初始化 Managed Bean,同时我们也可以通过这样的技术很方便的和使用类似技术的 Spring 进行整合。struts
2008-06-12 15:06:29
Struts 运行环境
1.1 Struts 1.0 和1.1版本
当前主要有两个版本,struts 1.0 release 和 struts 1.1 beta 3。Struts 1.0 和1.1差别很大,主要有两点:
- Struts 1.1 中引用了很多 apache其他项目的类包,如:xml 解析、日志、验证等,因此struts1.1 的包结构与1.0 完全不同。在struts 1.1环境下,一个webapp 要成功运行,除了struts.jar 外,还需要引用12个包。
- Struts 1.1 增加了很多新功能,例如,支持sub-applications, 动态FormBean,异常处理,验证,支持Tile templating等。
尽管struts 1.0 是正式发布版,但是结构已经老化,功能也已经固化。所以我们的Framework不选用struts 1.0, 而选用 struts 1.1。
1.2支持struts的应用服务器
根据apache官方网站的说法,struts几乎支持所有的servlet containers, 下面是几种主要的servlet containers
Servlet Container
版本
iPlanet Application Server
6.0sp2 or higher, 6.5
Tomcat
3.2.x, 4.0 or higher
Weblogic
6.0 or higher
Websphere
3.5 or higher
Orion
1.0 or higher
Resin
1.2 or higher
JRun
3.0 or higher
1.3配置说明
我们公司目前项目中使用较多的应用服务器是iPlanet Application Server, Tomcat。Struts 1.1 在这两个应用服务器下已经配置通过。
Tomcat 与struts结合的很好,只需要将xxx.war 放到 webapp 目录下,启动Tomcat 即可,不需要其他额外的配置。
iPlanet 配置复杂一些,主要原因是xml parser 版本不一致,和struts 相关类不能加载。具体的配置说明请见《如何在 iAS 6.x 中配置Struts 1.1 beta x》。
在其他的应用服务器上,还没有尝试struts, 今后根据项目需要会作进一步的研究。
struts框架
2.1 struts 体系结构
struts framework是MVC 模式的体现,下面分别从模型、视图、控制来看看struts的体系结构(Architecture)。下图显示了struts framework的体系结构响应客户请求时,各个部分工作的原理。

Struts体系结构
2.1.1 从视图角度(View)
主要由JSP建立,struts自身包含了一组可扩展的自定义标签库(TagLib),可以简化创建用户界面的过程。目前包括:Bean Tags,HTML Tags,Logic Tags,Nested Tags,Template Tags。
2.1.2从模型角度(Model)
模型主要是表示一个系统的状态(有时候,改变系统状态的业务逻辑操作也也划分到模型中)。在Struts中,系统的状态主要有ActiomForm Bean体现,一般情况下,这些状态是非持久性的。如果需要将这些状态转化为持久性数据存储,Struts本身也提供了Utitle包,可以方便的与数据库操作。
2.1.3 从控制器角度(Controller)
在Struts framework中, Controller主要是ActionServlet,但是对于业务逻辑的操作则主要由Action、ActionMapping、ActionForward这几个组件协调完成。其中,Action扮演了真正的业务逻辑的实现者,而ActionMapping和ActionForward则指定了不同业务逻辑或流程的运行方向。
2.2 struts 的组件
框架中所使用的组件:
ActionServlet
控制器
ActionClass
包含事务逻辑
ActionForm
显示模块数据
ActionMapping
帮助控制器将请求映射到操作
ActionForward
用来指示操作转移的对象
ActionError
用来存储和回收错误
Struts标记库
可以减轻开发显示层次的工作
2.3 struts 配置文件
Struts-config.xml集中了所有页面的导航定义。对于WEB项目,通过配置文件可迅速把握其脉络,这不管是对于前期的开发,还是后期的维护或升级都是方便的。掌握Struts-config.xml是掌握Struts的关键所在。
在struts的早先版本中,只有一个struts配置文件struts-config.xml。但是,对大型项目来说,使用和修改这个配置文件,会成为瓶颈。在struts1.1中,支持sub-Application ,可以定义多个配置文件协同工作。
通过struts配置文件struts-config.xml 将struts各个组件联系在一起。在struts-config.xml 中可以定义下面内容:
- 全局转发
- ActionMapping类
- ActionForm bean
- JDBC数据源
2.3.1 配置全局转发
全局转发用来在JSP页之间创建逻辑名称映射。全局转发的例子:
<global-forwards>
<forwardname="logoff"path="/logoff.do"/>
<forwardname="logon"path="/logon.jsp"/>
<forwardname="registration"path="/registration.jsp"/>
<forwardname="success"path="/mainMenu.jsp"/>
</global-forwards>
属性
描述
Name
全局转发的名字
Path
与目标URL的相对路径
2.3.2 配置ActionMapping
ActionMapping对象帮助进行框架内部的流程控制,它们可将请求URI映射到Action类,并且将Action类与ActionForm bean相关联。ActionServlet在内部使用这些映射,并将控制转移到特定Action类的实例。所有Action类使用perform()或者execute()方法实现特定应用程序代码,返回一个ActionForward对象,其中包括响应转发的目标页面名称。例如:
<action-mappings>
<actionpath="/logon"
type="org.apache.struts.webapp.example.LogonAction"
name="logonForm"
scope="session"
input="logon">
</action>
<forward name="failure" path="/error.jsp"/>
<forward name="success" path="/index.jsp"/>
</ action-mappings>
属性
描述
Path
Action类的相对路径
Name
与本操作关联的Action bean的名称
Type
连接到本映射的Action类的全称(可有包名)
Scope
ActionForm bean的作用域(请求或会话)
Prefix
用来匹配请求参数与bean属性的前缀
Suffix
用来匹配请求参数与bean属性的后缀
attribute
作用域名称。
className
ActionMapping对象的类的完全限定名默认的类是org.apache.struts.action.ActionMapping
input
输入表单的路径,指向bean发生输入错误必须返回的控制
unknown
设为true,操作将被作为所有没有定义的ActionMapping的URI的默认操作
validate
设置为true,则在调用Action对象上的perform()方法前,ActionServlet将调用ActionForm bean的validate()方法来进行输入检查
通过<forward>元素,可以定义资源的逻辑名称,该资源是Action类的响应要转发的目标。
属性
描述
Id
ID
ClassName
ActionForward类的完全限定名,默认是org.apache.struts.action.ActionForward
Name
操作类访问ActionForward时所用的逻辑名
Path
响应转发的目标资源的路径
redirect
若设置为true,则ActionServlet使用sendRedirect()方法来转发资源
2.3.3 配置ActionForm Bean
ActionServlet使用ActionForm来保存请求的参数,这些bean的属性名称与HTTP请求参数中的名称相对应,控制器将请求参数传递到ActionForm bean的实例,然后将这个实例传送到Action类。例子:
<form
beans >
<form
bean name="bookForm" type="BookForm"/>
</form
beans>
属性
描述
Id
ID
className
ActionForm bean的完全限定名,默认值是org.apache.struts.action.ActionFormBean
Name
表单bean在相关作用域的名称,这个属性用来将bean与ActionMapping进行关联
Type
类的完全限定名
2.3.4 配置JDBC数据源
例子:
<data-sources>
<data-source>
<set-property property="autoCommit"
value="false"/>
<set-property property="descrīption"
value="Example Data Source Configuration"/>
<set-property property="driverClass"
value="org.postgresql.Driver"/>
<set-property property="maxCount"
value="4"/>
<set-property property="minCount"
value="2"/>
<set-property property="password"
value="mypassword"/>
<set-property property="url"
value="jdbc:postgresql://localhost/mydatabase"/>
<set-property property="user"
value="myusername"/>
</data-source>
</data-sources>
属性
描述
descrīption
数据源的描述
autoCommit
数据源创建的连接所使用的默认自动更新数据库模式
driverClass
数据源所使用的类,用来显示JDBC驱动程序接口
loginTimeout
数据库登陆时间的限制,以秒为单位
maxCount
最多能建立的连接数目
minCount
要创建的最少连接数目
password
数据库访问的密码
readOnly
创建只读的连接
User
访问数据库的用户名
url
JDBC的URL
通过指定关键字名称,Action类可以访问数据源,比如:
javax.sql.DataSource ds = servlet.findDataSource(“conPool”);
javax.sql.Connection con = ds.getConnection();
struts标记库
struts 标记库包含4种类型的标记,分别是:
- struts-bean taglib:在访问bean和bean属性时使用的tag,也包含一些消息显示的tag。
- struts-html taglib:用来生成动态HTML用户界面和窗体的tag。
- struts-logic taglib :用来管理根据条件生成输出文本,和其它一些用来控制的信息。
- struts-template taglib:用来定义模板机制。
Struts提供了功能强大的Taglib,充分使用这些Tag,能最大限度的发挥Struts的作用。
由于标记库功能强大,所以掌握它需要花费一定的时间。目前我们可以先从 struts-html taglib 学起,主要精力还是要先放在理解掌握struts导航功能上。
文档《struts 标记库》可以帮助学习掌握struts taglib.
可视化设计工具和代码生成器Camino
Camino 是基于 struts framework的可视化建模工具。使用camino 可以实现快速设计和开发,主要特点有:
- 支持struts 1.0 和 struts 1.1
- 通过storyboard , 可视化定义页面导航流程,配置struts-config.xml 文件。
- Jsp converter wizard 功能可以将普通jsp 转换成带struts-html taglib 的jsp
- Code Generator wizard 功能可以自动生成 Action 和 FormBean 类的框架。
- Camin 3.0 还提供了验证器和Preview Jsp 的功能。
目前Camino的版本有2.05 和 3.0, 可以下载试用版。Camino 自带了帮助文档,可以方便学习Camino。
Struts example
Struts 1.1 beta 3 的包中包含了几个example, 可以帮助学习struts。
Web应用程序
描述
Struts-blank.war
一个简单的web应用程序
Struts-documentation.war
包含struts站点上所有struts文档
Struts-example.war
Struts很多特性的示范
Struts-exercisetaglib.war
主要用于对自定义标签库进行增加而使用的测试页,但也可以示范如何使用struts标记
Struts-template.war
包含struts模板标记的介绍和范例
Struts-upload.war
一个简单的例子,示范如何使用struts框架上传文件
在Tomcat 4.1.18运行环境下,只需要将 xxx.war 文件放到webapps 目录下,启动Tomcat 即可。
建议从struts-example 开始学习,熟读struts-config.xml, jsp, 和 java 源码。
6、统一的IDE工具: eclipse
Eclipse 是由IBM支持的开发源码的IDE, 目前的最新版本是2.1。与Netbeans, JBuilder相比,由以下特点:
- 界面设计精细,布局合理,秉承了IBM的风格。
- 功能齐全,具备了Netbeans, JBuilder(Enterprice fetature 除外)大部分功能,还有一些特有的功能,如:代码历史记录比较、替换,代码重构,自动生成get,set方法, 小组协作方式的版本控制和权限控制。
- 速度快,执行一个代码格式化(14,000行)的操作,要比Netbeans快百倍以上。
- 功能强大的plug-in,可以与Ant, JUnit, Tomcat集成。将来我们也可以编写自己的插件,有增强功能的潜力。
目前,每个项目使用的开发工具都不同,有JBuilder, Netbeans等。从长远考虑应该采用开发源码的IDE, 不存在盗版问题。现在开发源码的IDE有Netbeans, Eclipse两大阵营,分别由Sun 和 IBM支持。综合上面的Eclipse特性,我推荐统一使用Eclipse。
7、参考资料
- 网站:
struts 官方网站:http://jakarta.apache.org/struts
struts resource : http://jakarta.apache.org/struts/resources/index.html
Camino 网站:http://www.scioworks.com/index.html
其他网站:http://husted.com/struts/
http://struts.application-servers.com/main.html
http://www.synthis.com/products/architectures/struts/index.jsp
- 文章:
《struts框架详细介绍》 - ppt 文档,描述了struts 框架
《struts-intro》- ppt 文档,其中的struts 导航流程图非常好。
《Using Struts》 - ppt 文档,概述了struts 框架和组成
《如何在 iAS 6.x 中配置Struts 1.1 beta x》- 讲述在iPlanet 6.x 如何配置 struts 1.1
《Struts标记库》 - 详细介绍了struts taglib的使用
《struts turorial》 - 一个网上购书的示例,详细讲解了struts使用步骤新手入门:写Java程序的三十个基本规则
2008-06-12 15:04:53
(1) 类名首字母应该大写。字段、方法以及对象(句柄)的首字母应小写。对于所有标识符,其中包含的所有单词都应紧靠在一起,而且大写中间单词的首字母。例如:ThisIsAClassName
thisIsMethodOrFieldName
若在定义中出现了常数初始化字符,则大写static final基本类型标识符中的所有字母。这样便可标志出它们属于编译期的常数。
Java包(Package)属于一种特殊情况:它们全都是小写字母,即便中间的单词亦是如此。对于域名扩展名称,如com,org,net或者edu等,全部都应小写(这也是Java 1.1和Java 1.2的区别之一)。
(2) 为了常规用途而创建一个类时,请采取“经典形式”,并包含对下述元素的定义:
equals()
hashCode()
toString()
clone()(implement Cloneable)
implement Serializable
(3) 对于自己创建的每一个类,都考虑置入一个main(),其中包含了用于测试那个类的代码。为使用一个项目中的类,我们没必要删除测试代码。若进行了任何形式的改动,可方便地返回测试。这些代码也可作为如何使用类的一个示例使用。
(4) 应将方法设计成简要的、功能性单元,用它描述和实现一个不连续的类接口部分。理想情况下,方法应简明扼要。若长度很大,可考虑通过某种方式将其分割成较短的几个方法。这样做也便于类内代码的重复使用(有些时候,方法必须非常大,但它们仍应只做同样的一件事情)。 (5) 设计一个类时,请设身处地为客户程序员考虑一下(类的使用方法应该是非常明确的)。然后,再设身处地为管理代码的人考虑一下(预计有可能进行哪些形式的修改,想想用什么方法可把它们变得更简单)。
(6) 使类尽可能短小精悍,而且只解决一个特定的问题。下面是对类设计的一些建议:
■一个复杂的开关语句:考虑采用“多形”机制
■数量众多的方法涉及到类型差别极大的操作:考虑用几个类来分别实现
■许多成员变量在特征上有很大的差别:考虑使用几个类 。
(7) 让一切东西都尽可能地“私有”——private。可使库的某一部分“公共化”(一个方法、类或者一个字段等等),就永远不能把它拿出。若强行拿出,就可能破坏其他人现有的代码,使他们不得不重新编写和设计。若只公布自己必须公布的,就可放心大胆地改变其他任何东西。在多线程环境中,隐私是特别重要的一个因素——只有private字段才能在非同步使用的情况下受到保护。
(8) 谨惕“巨大对象综合症”。对一些习惯于顺序编程思维、且初涉OOP领域的新手,往往喜欢先写一个顺序执行的程序,再把它嵌入一个或两个巨大的对象里。根据编程原理,对象表达的应该是应用程序的概念,而非应用程序本身。
(9) 若不得已进行一些不太雅观的编程,至少应该把那些代码置于一个类的内部。
(10) 任何时候只要发现类与类之间结合得非常紧密,就需要考虑是否采用内部类,从而改善编码及维护工作(参见第14章14.1.2小节的“用内部类改进代码”)。
(11) 尽可能细致地加上注释,并用javadoc注释文档语法生成自己的程序文档。
(12) 避免使用“魔术数字”,这些数字很难与代码很好地配合。如以后需要修改它,无疑会成为一场噩梦,因为根本不知道“100”到底是指“数组大小”还是“其他全然不同的东西”。所以,我们应创建一个常数,并为其使用具有说服力的描述性名称,并在整个程序中都采用常数标识符。这样可使程序更易理解以及更易维护。
(13) 涉及构建器和异常的时候,通常希望重新丢弃在构建器中捕获的任何异常——如果它造成了那个对象的创建失败。这样一来,调用者就不会以为那个对象已正确地创建,从而盲目地继续。
(14) 当客户程序员用完对象以后,若你的类要求进行任何清除工作,可考虑将清除代码置于一个良好定义的方法里,采用类似于cleanup()这样的名字,明确表明自己的用途。除此以外,可在类内放置一个boolean(布尔)标记,指出对象是否已被清除。在类的finalize()方法里,请确定对象已被清除,并已丢弃了从RuntimeException继承的一个类(如果还没有的话),从而指出一个编程错误。在采取象这样的方案之前,请确定finalize ()能够在自己的系统中工作(可能需要调用System.runFinalizersonExit(true),从而确保这一行为)。
(15) 在一个特定的作用域内,若一个对象必须清除(非由垃圾收集机制处理),请采用下述方法:初始化对象;若成功,则立即进入一个含有finally从句的try块,开始清除工作。
(16) 若在初始化过程中需要覆盖(取消)finalize(),请记住调用super.finalize()(若Object属于我们的直接超类,则无此必要)。在对finalize()进行覆盖的过程中,对super.finalize()的调用应属于最后一个行动,而不应是第一个行动,这样可确保在需要基础类组件的时候它们依然有效。
(17) 创建大小固定的对象集合时,请将它们传输至一个数组(若准备从一个方法里返回这个集合,更应如此操作)。这样一来,我们就可享受到数组在编译期进行类型检查的好处。此外,为使用它们,数组的接收者也许并不需要将对象“造型”到数组里。
(18) 尽量使用interfaces,不要使用abstract类。若已知某样东西准备成为一个基础类,那么第一个选择应是将其变成一个interface(接口)。只有在不得不使用方法定义或者成员变量的时候,才需要将其变成一个abstract(抽象)类。接口主要描述了客户希望做什么事情,而一个类则致力于(或允许)具体的实施细节。
(19) 在构建器内部,只进行那些将对象设为正确状态所需的工作。尽可能地避免调用其他方法,因为那些方法可能被其他人覆盖或取消,从而在构建过程中产生不可预知的结果(参见第7章的详细说明)。
(20) 对象不应只是简单地容纳一些数据;它们的行为也应得到良好的定义。
(21) 在现成类的基础上创建新类时,请首先选择“新建”或“创作”。只有自己的设计要求必须继承时,才应考虑这方面的问题。若在本来允许新建的场合使用了继承,则整个设计会变得没有必要地复杂。
(22) 用继承及方法覆盖来表示行为间的差异,而用字段表示状态间的区别。一个非常极端的例子是通过对不同类的继承来表示颜色,这是绝对应该避免的:应直接使用一个“颜色”字段。
(23) 为避免编程时遇到麻烦,请保证在自己类路径指到的任何地方,每个名字都仅对应一个类。否则,编译器可能先找到同名的另一个类,并报告出错消息。若怀疑自己碰到了类路径问题,请试试在类路径的每一个起点,搜索一下同名的.class文件。
(24) 在Java 1.1 AWT中使用事件“适配器”时,特别容易碰到一个陷阱。若覆盖了某个适配器方法,同时拼写方法没有特别讲究,最后的结果就是新添加一个方法,而不是覆盖现成方法。然而,由于这样做是完全合法的,所以不会从编译器或运行期系统获得任何出错提示——只不过代码的工作就变得不正常了。
(25) 用合理的设计方案消除“伪功能”。也就是说,假若只需要创建类的一个对象,就不要提前限制自己使用应用程序,并加上一条“只生成其中一个”注释。请考虑将其封装成一个“独生子”的形式。若在主程序里有大量散乱的代码,用于创建自己的对象,请考虑采纳一种创造性的方案,将些代码封装起来。
(26) 警惕“分析瘫痪”。请记住,无论如何都要提前了解整个项目的状况,再去考察其中的细节。由于把握了全局,可快速认识自己未知的一些因素,防止在考察细节的时候陷入“死逻辑”中。
(27) 警惕“过早优化”。首先让它运行起来,再考虑变得更快——但只有在自己必须这样做、而且经证实在某部分代码中的确存在一个性能瓶颈的时候,才应进行优化。除非用专门的工具分析瓶颈,否则很有可能是在浪费自己的时间。性能提升的隐含代价是自己的代码变得难于理解,而且难于维护。
(28) 请记住,阅读代码的时间比写代码的时间多得多。思路清晰的设计可获得易于理解的程序,但注释、细致的解释以及一些示例往往具有不可估量的价值。无论对你自己,还是对后来的人,它们都是相当重要的。如对此仍有怀疑,那么请试想自己试图从联机Java文档里找出有用信息时碰到的挫折,这样或许能将你说服。
(29) 如认为自己已进行了良好的分析、设计或者实施,那么请稍微更换一下思维角度。试试邀请一些外来人士——并不一定是专家,但可以是来自本公司其他部门的人。请他们用完全新鲜的眼光考察你的工作,看看是否能找出你一度熟视无睹的问题。采取这种方式,往往能在最适合修改的阶段找出一些关键性的问题,避免产品发行后再解决问题而造成的金钱及精力方面的损失。
(30) 良好的设计能带来最大的回报。简言之,对于一个特定的问题,通常会花较长的时间才能找到一种最恰当的解决方案。但一旦找到了正确的方法,以后的工作就轻松多了,再也不用经历数小时、数天或者数月的痛苦挣扎。我们的努力工作会带来最大的回报(甚至无可估量)。而且由于自己倾注了大量心血,最终获得一个出色的设计方案,成功的快感也是令人心动的。坚持抵制草草完工的诱惑——那样做往往得不偿失。
提高Java代码可重用性的三个措施
2008-06-12 14:57:01
本文介绍了三种修改现有代码提高其可重用性的方法,它们分别是:改写类的实例方法,把参数类型改成接口,选择最简单的参数接口类型。措施一:改写类的实例方法
通过类继承实现代码重用不是精确的代码重用技术,因此它并不是最理想的代码重用机制。换句话说,如果不继承整个类的所有方法和数据成员,我们无法重用该类里面的单个方法。继承总是带来一些多余的方法和数据成员,它们总是使得重用类里面某个方法的代码复杂化。另外,派生类对父类的依赖关系也使得代码进一步复杂化:对父类的改动可能影响子类;修改父类或者子类中的任意一个类时,我们很难记得哪一个方法被子类覆盖、哪一个方法没有被子类覆盖;最后,子类中的覆盖方法是否要调用父类中的对应方法有时并不显而易见。
任何方法,只要它执行的是某个单一概念的任务,就其本身而言,它就应该是首选的可重用代码。为了重用这种代码,我们必须回归到面向过程的编程模式,把类的实例方法移出成为全局性的过程。为了提高这种过程的可重用性,过程代码应该象静态工具方法一样编写:它只能使用自己的输入参数,只能调用其他全局性的过程,不能使用任何非局部的变量。这种对外部依赖关系的限制简化了过程的应用,使得过程能够方便地用于任何地方。当然,由于这种组织方式总是使得代码具有更清晰的结构,即使是不考虑重用性的代码也同样能够从中获益。
在Java中,方法不能脱离类而单独存在。为此,我们可以把相关的过程组织成为独立的类,并把这些过程定义为公用静态方法。
例如,对于下面这个类:
class Polygon {
.
.
public int getPerimeter() {...}
public boolean isConvex() {...}
public boolean containsPoint(Point p) {...}
.
.
}
我们可以把它改写成:
class Polygon {
.
.
public int getPerimeter() {return pPolygon.computePerimeter(this);}
public boolean isConvex() {return pPolygon.isConvex(this);}
public boolean containsPoint(Point p) {return pPolygon.containsPoint(this, p);}
.
}
其中,pPolygon是:
class pPolygon {
static public int computePerimeter(Polygon polygon) {...}
static public boolean isConvex(Polygon polygon) {...}
static public boolean
containsPoint(Polygon polygon, Point p) {...}
}
从类的名字pPolygon可以看出,该类所封装的过程主要与Polygon类型的对象有关。名字前面的p表示该类的唯一目的是组织公用静态过程。在Java中,类的名字以小写字母开头是一种非标准的做法,但象pPloygon这样的类事实上并不提供普通Java类的功能。也就是说,它并不代表着一类对象,它只是Java语言组织代码的一种机制。
在上面这个例子中,改动代码的最终效果是使得应用Polygon功能的客户代码不必再从Polygon继承。Polygon类的功能现在已经由pPolygon类以过程为单位提供。客户代码只使用自己需要的代码,无需关心Polygon类中自己不需要的功能。但它并不意味着在这种新式过程化编程中类的作用有所削弱。恰恰相反,在组织和封装对象数据成员的过程中,类起到了不可或缺的作用,而且正如本文接下来所介绍的,类通过多重接口实现多态性的能力本身也带来了卓越的代码重用支持。然而,由于用实例方法封装代码功能并不是首选的代码重用手段,所以通过类继承达到代码重用和多态性支持也不是最理想的。
措施二:把参数类型改成接口
正如Allen Holub在《Build User Interfaces for Object-Oriented Systems》中所指出的,在面向对象编程中,代码重用真正的要点在于通过接口参数类型利用多态性,而不是通过类继承:
“……我们通过对接口而不是对类编程达到代码重用的目的。如果某个方法的所有参数都是对一些已知接口的引用,那么这个方法就能够操作这样一些对象:当我们编写方法的代码时,这些对象的类甚至还不存在。从技术上说,可重用的是方法,而不是传递给方法的对象。”
在“措施一”得到的结果上应用Holub的看法,当某块代码能够编写为独立的全局过程时,只要把它所有类形式的参数改为接口形式,我们就可以进一步提高它的可重用能力。经过这个改动之后,过程的参数可以是实现了该接口的所有类的对象,而不仅仅是原来的类所创建的对象。由此,过程将能够对可能存在的大量的对象类型进行操作。
例如,假设有这样一个全局静态方法:
static public boolean contains(Rectangle rect, int x, int y) {...}
这个方法用于检查指定的点是否包含在矩形里面。在这个例子中,rect参数的类型可以从Rectangle类改变为接口类型,如下所示:
static public boolean contains(Rectangular rect, int x, int y) {...}
而Rectangular接口的定义是:
public interface Rectangular {Rectangle getBounds();}
现在,所有可以描述为矩形的类(即,实现了Rectangular接口的类)所创建的对象都可以作为提供给pRectangular.contains()的rect参数。通过放宽参数类型的限制,我们使方法具有更好的可重用性。
不过,对于上面这个例子,Rectangular接口的getBounds方法返回Rectangle,你可能会怀疑这么做是否真正值得。换言之,如果我们知道传入过程的对象会在被调用时返回一个Rectangle,为什么不直接传入Rectangle取代接口类型呢?之所以不这么做,最重要的原因与集合有关。让我们假设有这样一个方法:
static public boolean areAnyOverlapping(Collection rects) {...}
该方法用于检查给定集合中的任意矩形对象是否重叠。在这个方法的内部,当我们用循环依次访问集合中的各个对象时,如果我们不能把对象cast成为Rectangular之类的接口类型,又如何能够访问对象的矩形区域呢?唯一的选择是把对象cast成为它特有的类形式(我们知道它有一个方法可以返回矩形),它意味着方法必须事先知道它所操作的对象类型,从而使得方法的重用只限于那几种对象类型。而这正是前面这个措施力图先行避免的问题!
措施三:选择最简单的参数接口类型
在实施第二个措施时,应该选用哪一种接口类型来取代给定的类形式?答案是哪一个接口完全满足过程对参数的需求,同时又具有最少的多余代码和数据。描述参数对象要求的接口越简单,其他类实现该接口的机会就越大——由此,其对象能够作为参数使用的类也越多。从下面这个例子可以很容易地看出这一点:
static public boolean areOverlapping(Window window1, Window window2) {...}
这个方法用于检查两个窗口(假定是矩形窗口)是否重叠。如果这个方法只要求从参数获得两个窗口的矩形坐标,此时相应地简化这两个参数是一种更好的选择:
static public boolean areOverlapping(Rectangular rect1, Rectangular rect2) {...}
上面的代码假定Window类型实现了Rectangular接口。经过改动之后,对于任何矩形对象我们都可以重用该方法的功能。
有些时候可能会出现描述参数需求的接口拥有太多方法的情况。此时,我们应该在全局名称空间中定义一个新的公共接口供其他面临同一问题的代码重用。
当我们需要象使用C语言中的函数指针一样使用参数时,创建唯一的接口描述参数需求是最好的选择。例如,假设有下面这个过程:
static public void sort(List list, SortComparison comp) {...}
该方法运用参数中提供的比较对象comp,通过比较给定列表list中的对象排序list列表。sort对comp对象的唯一要求是要调用一个方法进行比较。因此,SortComparison应该是只带有一个方法的接口:
public interface SortComparison {
boolean comesBefore(Object a, Object b);
}
SortComparison接口的唯一目的在于为sort提供一个它所需功能的钩子,因此SortComparison接口不能在其他地方重用。
总而言之,本文三个措施适合于改造现有的、按照面向对象惯例编写的代码。这三个措施与面向对象编程技术结合就得到了一种可在以后编写代码时使用的新式代码编写技术,它能够简化方法的复杂性和依赖关系,同时提高方法的可重用能力和内部凝聚力。
当然,这里的三个措施不能用于那些天生就不适合重用的代码。不适合重用的代码通常出现在应用的表现层。例如,创建程序用户界面的代码,以及联结到输入事件的控制代码,都属于那种在程序和程序之间千差万别的代码,这种代码几乎不可能重用。
三步改善Java码质量
2008-06-12 14:52:39
本文讨论了如何以递进的方式使用Apache Ant来改善我们的代码质量。并按着三步走的原则给出了具体的实现步骤。一、充分利用单元测试、代码覆盖
单元测试、代码覆盖是最容易被接受和实现的方式。事实上,大多数开发人员都知道单元测试对他们很重要。在我们开始讨论这些东西之前,先看一下Google研究院主管Peter Norvig的一段话:“如果你认为你们不需要对自己的代码进行单元测试,那么就写在纸上写一所有的原因,并且仔细研究这张纸,然后扔了它,继续测试自己的程序吧”。看来Google也是非常推崇进行单元测试的。那么谁又来测试那么测试者呢?也就是说,我们怎么能验证对程序做了足够的测试呢?这是一个非常有价值的问题,因为那些未通过测试的程序才是我们更应该关注的地方。这个问题的一个解决方案就是使用代码覆盖工具,这种工具将告诉我们我们到底测试了多少代码(也就是被测试代码的百分比),然后使用一般的综合处理来合并覆盖核对结果。如果覆盖核对失败,那么我们建立应用程序的过程也就失败了。
对了本文所讨论的递增代码策略选择了代码覆盖工具Cobertura,这是由于它非常容易使用,而且拥有良好的定义格式,以及四个Ant任务接口。这些任务之一就是cobertura-check,当代码不能完成我们要求的覆盖率时,它就会失败。如下面的代码显示如果覆盖率未达到80%,Ant在建立工程时就会失败: <target name="coverage_check">
<cobertura-check totallinerate="80"/>
</target name="coverage_check">
<target name="coverage_check">
<cobertura-check totallinerate="80"/>
</target name="coverage_check">除了使用硬编码来指定这个覆盖率外,我们还可能以使用一个更容易建立的结果作为当前核对的覆盖率。我们可以通过使用两个核心Ant任务连接一对Cobertura任务来完成这个任务。并不不用担心各种覆盖率的具体的值。我们的目标是完成可测量的代码改善,而不是设置一个绝对的代码覆盖率。
在建立用于测试和运行我们的代码的targets后,我们可以将用于核对我们的建立脚本的增量覆盖率。第一步是使用一个cobertura报吿任务建立一个XML格式的覆盖报表。代码如下:<cobertura-report format="xml"/>
下面是由一个cobertura报表任务产生的
coverage.xml
<?xml version="1.0"?> <!DOCTYPE coverage SYSTEM "http://cobertura.sourceforge.net/xml/coverage-02.dtd"> <coverage line-rate="0.43612334801762115" branch-rate="0.48344370860927155" version="1.8" timestamp="1181043899853"> <sources> <source>./src/java</source> </sources> <packages> ... </packages> </coverage>现在要确保将这个文件保存在某个硬盘上,因为我们在后面会需要这个文件。
二、从报表中取出覆盖率一开始,我们可以试着使用Ant的XmlProperty任务来直接获得这个覆盖率,并给一个Ant属性。但是这个方法有以下两个问题:1. 在coverage.xml中的覆盖率是一个小数,但当核对任务时需要一个整数百分比。2. 在实际的项目中,coverage.xml的文件尺寸非常大,如果在Java中尝试使用XmlProperty任务时可能会出现Java OutOfMemoryError错误。而我们只想从coverage.xml文件中获得以下的内容:<xslt in="coverage.xml" ōut="build/coverage.properties" style="src/xsl/coverage.xsl" />上面的简单的XSL模板需要产生一个只包含我们需要的值的属性文件,内容如下:<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method="text" omit-xml-declaration="yes"/> <xsl:template match="coverage"> total.line-rate= <xsl:value-of select="floor(@line-rate*100)"/> </xsl:template> </xsl:stylesheet>要注意的是方法floor(@line-rate*100),可以将小数覆盖率转换为整型覆盖率。最终结果是一个只包含下面一行的coverage.properties文件:total.line-rate=44现在我们可以使用Ant的属性任务来从coverage.properties读取这个Ant属性所需要的覆盖率:<property file="build/coverage.properties" />最后,我们可以将最初的"80"使用新的Ant属性替换,代码如下:<cobertura-check totallinerate="${total.line-rate}"/>三、将内容放到一起最后的build.xml文件看上去的形似如下:<target name="coverage_check" depends="check_against_previous_rate"> <antcall target="coverage_report"/> </target> <target name="coverage_report"> <cobertura-report format="xml" destdir="." /> </target> <target name="check_against_previous_rate" depends="coverage_xml_to_properties"> <property file="build/coverage.properties" /> <cobertura-check totallinerate="${coverage.line-rate}" /> </target> <target name="coverage_xml_to_properties"> <xslt in="coverage.xml" out="build/coverage.properties" style="src/xsl/coverage.xsl" /> </target>
要注意一个新的覆盖报告仅仅当覆盖核对被通过后才能被产生,也就是说,每次提高覆盖率后,都会比上一次建立的代码质量有所提高。四、改善跟踪率的其他方法还有一些递增地改善代码质量的方法是通过将覆盖率记录到文件中来跟踪代码改善率。我们可以通过Ant的echo任务建立如下的代码:<target name="time"> <tstamp> <format property="date.time" pattern="yyyy-MM-dd HH:mm"/> </tstamp> </target> <target name="log" depends="time"> <echo file="${history.txt}" append="true"> ${date.time};total.line-rate;${total.line-rate} </echo> </target>
五、结果可测量、改善可视化
经过对一个工程的测试,在这个工作使用本文所提供的策略后的一周内定,这个工程的代码质量改善了超过30%。而更另人兴奋的是以前开发人员都不需要对代码进行测试,而现在它们会为通过测试而使他们的代码质量的提高感到骄傲。当然,我们不需要只停留在本文所介绍的方法和理论上。我们也可以将增量改善策略用在其他的代码规则中。因为大多数的代码核对工具都可以产生基于XML格式的输出,我们可以使用XSL模板来过滤出与之相关的代码规则,并将这些规则作为当前的代码核对工具的输入。Java基础知识:谈谈简单Hibernate入门
2008-06-12 14:49:10
Hibernate简介
Hibernate寓意:Let Java objects hibernate in the relational database.
Hibernate 是Java应用和关系数据库之间的桥梁,负责Java对象和关系数据库之间的映射的ORM中间件。Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得Java开发人员可以随心所欲的使用对象编程思维来操纵数据库。简单的说就是:
1.封装了通过JDBC访问数据库操作。
2.向上层应用提供访问面向对象数据访问的API。
创建Hibernate配置文件
通过一个例子practice 演示如何运用Hibernate来访问关系数据库。
Practice 工程的功能:
通过Hibernate保存客户(customer)信息。
其Hibernate应用结构图如下:
―――――――――――――――――――――――――――
Practice 应用
Customer Class ; action Class;Business Class
――――――――――――――――――――――――――――
――――――――――――――――――――――――――――
Hibernate xml
对象-关系映射文件 Hibernate ApI
Hibernate 配置文件
――――――――――――――――――――――――――――
――――――――――――――――――――――――――――
关系数据库(Mysql)
CUSTOMERS 表
――――――――――――――――――――――――――――
创建持久化类
Hibernate 从Hibernate配置文件中读取和数据库连接相关的信息。
配置文件有两种形式:
一种是XML格式的文件:hibernate.cfg.xml
一种是Java属性文件:hibernate.properties
这个实例中我们将使用hibernate.cfg.xml。
"http://hibernate.sourceforge.net/hibernate-configuration-2.0.dtd">
true
false
net.sf.hibernate.dialect.MySQLDialect
org.gjt.mm.mysql.Driver
jdbc:mysql://localhost:3306/netstore
root
123456
true
gb2312
插入位置在src目录下:
创建O/R对象-关系映射文件
创建持久化的类Customer.java
package entity;import java.io.Serializable;
public class Customers implements Serializable {
private Integer id;
private String name;
private int age;
public Customers() {
}
public int getAge() {
return age; }
public void setAge(int age) {
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}}
Get/set 方法的命名必须符合JavaBean的规范,否则Hibernate会报出异常,具体请参照相关资料。关于Serializable接口:
Hibernate 并不要求持久化类必须实现java.io.Serializable接口,但是对于采用分布式结构的Java应用,当Java对象在不同的进程节点之间传输时,这个对象必须实现这个接口;如果希望对HttpSession中存放的Java对象进行持久化,那么这个Java对象必须实现Serializable接口。
关于不带参数的构造方法:
public Customers() { }
Hibernate要求持久化类必须提供一个不带参数的默认的构造方法,原因请参考相关资料。
创建Mysql数据库
数据库名称:netstroe
Customer表DDL定义如下:CREATE TABLE `customers` ( `Id` bigint(20) NOT NULL default '0', `name` varchar(15) default NULL, `age` int(11) default NULL, PRIMARY KEY (`Id`)) TYPE=MyISAM;
创建对象-关系映射文件
创建对象-关系映射文件:Customers.hbm.xml
代码如下:
"-//Hibernate/Hibernate Mapping DTD 2.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd" >
name="entity.Customers"
table="customers">
name="id"
type="java.lang.Integer"
column="id"
>
name="name"
type="java.lang.String"
column="name"
length="15"
/>
name="age"
type="int"
column="age"
length="11"
/>
引入Hibernate所需的jar包
Hibernate2.jar、hibernate-tools.jar
通过Hibernate API 访问MYSQL数据库
创建业务逻辑类:useHibernate.java
代码如下:
package business;
import entity.Customers;
import net.sf.hibernate.Session;
import net.sf.hibernate.SessionFactory;
import net.sf.hibernate.Transaction;
import net.sf.hibernate.cfg.Configuration;
public class useHibernate {
public static SessionFactory sessionFactory;
/** 初始化Hibernate,创建SessionFactory实例 */
public void saveCustomers(Customers customers) throws Exception {
Configuration config = null;
config = new Configuration().configure();
// 创建一个SessionFactory 实例
sessionFactory = config.buildSessionFactory();
Session session = sessionFactory.openSession();
Transaction tx = null;
try {
/* 开始一个事务 */
tx = session.beginTransaction();
session.save(customers);
/* 提交事务 */
tx.commit();
} catch (Exception e) {
// TODO Auto-generated catch block
if (tx != null)
tx.rollback();
throw e;
} finally {
session.close();
}
}}
测试Hibernate配置是否成功
创建Junit测试:testhibernate.java
有关Junit请参考相关资料:
package test;
import business.useHibernate;
import entity.Customers;import junit.framework.TestCase;
Customers customers = new Customers();
customers.setId(new Integer(330121));
customers.setAge(24);
customers.setName("huhpreal");
useHibernate usehibernate = new useHibernate();
try {
usehibernate.saveCustomers(customers);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}}
查看后台打印信息:
(cfg.Environment 403 ) Hibernate 2.0.3
(cfg.Environment 432 ) hibernate.properties not found
(cfg.Environment 452 ) using CGLIB reflection optimizer
(cfg.Environment 462 ) JVM proxy support: true
(cfg.Configuration 703 ) Configuration resource: /hibernate.cfg.xml
(cfg.Configuration 270 ) Mapping resource: hbm/Customers.hbm.xml
(cfg.Binder 178 ) Mapping class: entity.Customers -> customers
(cfg.Configuration 885 ) Configured SessionFactory: null
(cfg.Configuration 492 ) processing one-to-many association mappings
(cfg.Configuration 503 ) processing foreign key constraints
(impl.SessionFactoryImpl 132 ) building session factory
(dialect.Dialect 83 ) Using dialect: net.sf.hibernate.dialect.MySQLDialect
(connection.DriverManagerConnectionProvider 41 ) Hibernate connection pool size: 20
(connection.DriverManagerConnectionProvider 70 ) using driver: org.gjt.mm.mysql.Driver at URL: jdbc:mysql://localhost:3306/netstore
(connection.DriverManagerConnectionProvider 71 ) connection properties: {useUnicode=true, user=root, password=123456, characterEncoding=gb2312}
(impl.SessionFactoryImpl 162 ) Use outer join fetching: false
(impl.SessionFactoryImpl 185 ) Use scrollable result sets: true
(impl.SessionFactoryImpl 186 ) JDBC 2 max batch size: 15
(impl.SessionFactoryImpl 194 ) echoing all SQL to stdout
(impl.SessionFactoryObjectFactory 82 ) no JDNI name configured
(impl.SessionFactoryImpl 269 ) Query language substitutions: {}
Hibernate 配置使用成功
查看数据库:
插入成功!LR_函数_Action
2008-04-11 18:18:28
web_url
语法:
Int Web_url(const char *name, const char * url, <Lists of Attributes>, [EXTRARES,<Lists of Resource Attributes>,LAST)
返回值
成功时返回LR_PASS (0),失败时返回 LR_FAIL (1)。
参数:
Name:VuGen中树形视图中显示的名称,在自动事务处理中也可以用做事务的名称。
url:页面url地址。
EXTRARES:分隔符,标记下一个参数是资源属性的列表了。
LAST:属性列表结束的标记符。
说明
Web_url根据函数中的URL属性加载对应的URL,不需要上下文。
只有VuGen处于URL-based或者HTML-based(此时A scrīpt containing explicit URLs only选项被选中时)的录制模式时,web_url才会被录制到。
可以使用web_url 模拟从FTP服务器上下载文件。web_url 函数会使FTP服务器执行文件被真实下载时的操作。除非手工指定了"FtpAscii=1",下载会以二进制模式完成。
在录制选项中,Toos—Recording Option下,Recording选项中,有一个Advanced HTML选项,可以设置是否录制非HTML资源,只有选择了“Record within the current scrīpt step”时,List of Resource Attributes才会被录制到。非HTML资源的例子是gif和jpg图象文件。
通过修改HTTP头可以传递给服务器一些附加的请求信息。使用HTTP头允许请求中包含其他的内容类型(Content_type),象压缩文件一样。还可以只请求特定状态下的web页面。
所有的Web Vusers ,HTTP模式下的WAP Vusers或者回放模式下的Wireless Session Protocol(WSP),都支持web_url函数。
web_image
语法:
Int web_image (const char *StepName, <List of Attributes>, [EXTRARES, <List of Resource Attributes>,] LAST );
返回值
成功时返回LR_PASS (0),失败时返回 LR_FAIL (1)。
参数:
StepName:VuGen中树形视图中显示的名称,在自动事务处理中也可以用做事务的名称。
List of Attributes(服务器端和客户端映射的图片):SRC属性是一定会被录制到的,其他的ALT、Frame、TargetFrame、Ordinal则是有的话会被录制到。
1、ALT:描述图象的元素。用鼠标指向图象时,所浮出来的文字提示。
2、SRC:描述图象的元素,可以是图象的文件名. 如: button.gif。也可以使用SRC/SFX来指定图象路径的后缀。所有拥有相同此后缀的字符串都会被匹配到。
3、Frame:录制操作时所在的Frame的名称。
4、TargetFrame:见List of Attributes的同名参数。
5、Ordinal:参见Web_link的同名参数。
List of Attributes(客户端映射的图片):
1、AreaAlt:鼠标单击区域的ALT属性。
2、AreaOrdinal:鼠标单击区域的顺序号。
3、MapName:图象的映射名。
List of Attributes(服务器端映射的图片):尽管点击坐标不属于属性,但还是以属性的格式来使用。
1、Xcoord:点击图象时的X坐标。
2、Ycoord:点击图象时的Y坐标。
EXTRARES:分隔符,标记下一个参数是资源属性的列表了。
List of Resource Attributes:参见List of Resource Attributes一节。
LAST:属性列表结束的标记符。
说明
web_image模拟鼠标在指定图片上的单击动作。此函数必须在有前置操作的上下文中使用。
在Toos—Recording Option,如果录制级别设为基于HMTL的录制方式时,web_image才会被录制到。
web_image支持客户端(client-side)和服务器端server-side的图片映射。
在录制选项中,Toos—Recording Option下,Recording选项中,有一个Advanced HTML选项,可以设置是否录制非HTML资源,只有选择了“Record within the current scrīpt step”时,List of Resource Attributes才会被录制到。非HTML资源的例子是gif和jpg图象文件。
通过修改HTTP头可以传递给服务器一些请求附加信息。使用HTTP头允许请求中包含内容,如同压缩文件一样。还可以只请求特定状态的web页面。
web_image支持Web虚拟用户,不支持WAP虚拟用户。
例子
下面的例子模拟用户单击Home图标以回到主页(黑体部分):
web_url("my_home", "URL=http://my_home/", LAST);
web_link("Employees", "Text=Employees", LAST);
web_image("Home.gif", "SRC=../gifs/Buttons/Home.gif", LAST);
web_link("Library", "Text=Library", LAST);
web_image("Home.gif", "SRC=../../gifs/buttons/Home.gif", LAST);
web_image("The Web Developer's Virtual Library",
"Alt=The Web Developer's Virtual Library",
下面是一个使用文件名后缀的例子:它指定了dpt_house.gif作为后缀,所以象../gifs/dpt_house.gif、/gifs/dpt_house.gif、gifs/dpt_house.gif、/dpt_house.gif等都会匹配到。
web_image("dpt_house.gif",
"Src/sfx=dpt_house.gif", LAST);web_link
语法:
Int web_link (const char *StepName, <List of Attributes>, [EXTRARES, <List of Resource Attributes>,] LAST );
返回值
成功时返回LR_PASS (0),失败时返回 LR_FAIL (1)。
参数:
StepName:VuGen中树形视图中显示的名称,在自动事务设置中也被用做事务名称。
List of Attributes:支持下列的属性:
1. Text:超链接中的文字,必须精确匹配。
2. Frame:录制操作时所在的Frame的名称。
3. TargetFrame、ResourceByteLimit:见List of Attributes一节。
4. Ordinal:如果用给出的属性(Attributes)筛选出的元素不唯一,那么VuGen使用此属性来指定其中的一个。例如:“SRC=abc.gif”,“Ordinal=
EXTRARES:表明下面的参数将会是list of resource attributes了。
LAST:结尾标示符。
说明
模拟鼠标在由若干个属性集合描述的链接上进行单击。此函数必须在前置动作的上下文中才可以执行。
web_link 仅仅在基于HTML的录制方式中才会被VuGen捕捉到。
非HTML生成的资源的例子有.gif 和.jpg图像。对于List of Resource Attributes参数来说,仅仅当Recording Options--Recording --HTML-based scrīpt-- Record within the current scrīpt step选项被选中时,它们才会被插入到代码中。
可以通过改变HTTP头信息给服务器传递一些附加信息。使用HTTP头信息可以,允许响应体中包含其他的内容类型(Content-Type),例如压缩文件,或者只有满足了特定的状态才去请求web页。
此函数值支持Web虚拟用户,不支持WAP虚拟用户。
web_submmit_form
语法:
Int web_submit_form (const char *StepName, <List of Attributes>, <List of Hidden Fields>, ITEMDATA, <List of Data Fields>, [ EXTRARES, <List of Resource Attributes>,] LAST );
返回值
成功时返回LR_PASS (0),失败时返回 LR_FAIL (1)。
参数:
StepName:Form的名字。VuGen中树形视图中显示的名称,在自动事务处理中也可以用做事务的名称。
List of Attributes:支持以下属性:
1. Action:Form中的ACTION属性,指定了完成Form中的操作用到的URL。也可以使用“Action/sfx” 表示使用此后缀的所有Action。
2. Frame:录制操作时所在的Frame的名称。
3. TargetFrame、ResourceByteLimit:见List of Attributes的同名参数。
VuGen通过记录数据域唯一的标识每个Form。如果这样不足以识别Form,VuGen会记录Action 属性。如果还不足以识别,则会记录Ordinal 属性,这种情况下不会记录Action属性。
List of Hidden Fields:补充属性(Serves)。 通过此属性可以使用一串隐含域来标识Form。使用下面的格式:
"name=n1", "value=v1", ENDITEM,
"name=n2", "value=v2", ENDITEM,
Data项用来标识form。Form是通过属性和数据来共同识别的。
"name=n1", "value=v1", ENDITEM,
"name=n2", "value=v2", ENDITEM,
EXTRARES:一个分隔符,标记下一个参数是资源属性的列表了。
List of Resource Attributes:参见List of Resource Attributes一节。
LAST:属性列表结束的标记符。
说明
web_submit_form 函数用来提交表单。此函数可能必须在前一个操作的上下文中执行。在Toos—Recording Option,只有录制级别设为基于HMTL的录制方式,web_image才会被录制到。
在录制选项中,Toos—Recording Option下,Recording选项中,有一个Advanced HTML选项,可以设置是否录制非HTML资源,只有选择了“Record within the current scrīpt step”时,List of Resource Attributes才会被录制到。非HTML资源的例子是gif和jpg图象文件。
通常情况下,如果录制了web_submit_form 函数,VuGen会把“name”和“value”一起录制到ITEMDATA属性中。如果不想在脚本中以明文显示“value”,可以对它进行加密。把“Value”改为“EncryptedValue”,然后把录制到的值改为加密后的值。
例如:可以把 "Name=grpType", "Value=radRoundtrip", ENDITEM
改为:"Name=grpType", EncryptedValue=409e41ebf
如果你完整的安装了LoadRunner,那么打开开始菜单--Mercury LoadRunner—Tools--Password Encoder,这个小工具是用来加密字符串的。把需要加密的值粘贴到Password一栏,再点Generate按钮。加密后的字符串会出现在Encoded string框中。接着点Copy按钮,然后把它粘贴到脚本中,覆盖原来显示的“Value”。
加密的另一种方法时使用lr_decrypt函数。方法:选择整个字符串,例如“Value=radRoundtrip”(注意不要选择引号),右击鼠标,选择Encrypt string选现,脚本会变为:
"Name=grpType", lr_decrypt("40d
web_submit_form支持Web虚拟用户,不支持WAP虚拟用户。
例子:
下面的例子中,web_submit_form 函数的名字是“employee.exe”。此函数提交了一个请求,此请求包含雇员信息John Green。此函数没有使用属性(Attributes)是因为通过数据项已经能唯一的标识这个Form了。
web_submit_form("employee.exe",
"name=persons", "value=John Green - John", ENDITEM,
"name=go_page", "value=Go to Page", ENDITEM,
web_submmit_data
语法:
Int web_submit_data ( const char *StepName, <List of Attributes>, ITEMDATA, <List of data>, [ EXTRARES, <List of Resource Attributes>,] LAST );
返回值
返回LR_PASS(0)代表成功,LR_FAIL(1)代表失败。
参数:
StepName:步骤名称,VuGen中树形视图显示的名称。
List of Attributes:支持以下属性:
1. Action:Form中的ACTION属性,指定了完成Form中的操作用到的URL。
2. Method:表单提交方法:POST或GET(默认是POST)。
3. EncType:编码方式。
4. EncodeAtSign:是否使用ASCII值对符号“@”编码。Yes或者 No。
5. TargetFrame:包含当前链接或资源的Frame。参见List of Attributes的同名参数。
6. Referer、Mode:参见List of Attributes的同名参数。
ITEMDATA:数据域和属性的分隔符。
List of Data:
数据域列表定义了表单提交的内容。由于此请求是上下文无关的,因此数据域包含了所有的隐含域。使用Form的编码规则组织数据域。
数据域列表可以使用下面任意一种格式:
"name=n1", "value=v1", ENDITEM,
"name=n2", "EncryptedValue=qwerty", ENDITEM,
EXTRARES:分隔符,标记下一个参数将是资源属性的列表。
List of Resource Attributes:参见List of Resource Attributes。
LR_函数_小结
2008-04-11 18:06:00
1. Intweb_reg_save_param("参数名","LB=左边界","RB=右边界",LAST);/注册函数,在参数值出现的前面使用,注册成功时返回值为0,注册失败时返回值为1。左右边界需根据TreeView里相关步骤的SeverResponse代码来确定。用以上函数能获取第一个符合条件的数值。
2. web_reg_save_param("参数名”,"LB=左边界”,"RB=右边界","Ord=All",LAST);/当参数有多个值时,加上"Ord=All”后可获取所有的数值。注册成功后,{参数名_count}表示取得的数值个数,{参数名_1}为第一个数值,{参数名_2}为第二个数值。
3. lr_save_string(“字符串变量”,"参数名")/将字符变量里的值传递给指定参数。通过该函数来改变DataFile类型参数的数值。
4. lr_eval_string("{参数名}")/取得参数的数值。可取得已注册参数或DataFile类型参数的数值。eval就是evaluation(估价, 评价, 赋值)的缩写。
5. int sprintf(char * string , const char*format_string[,args]);/字符串赋值函数
Action()
{
int index=56;
charfilename[64],*suffix="txt";
sprintf(filename,"log_%d.%s",index,suffix);
lr_output_message("Thenewfilenameis%s",filename);
return 0;
}
Output:Thenewfilenameislog_56.txt
6. char*strcat(char*to,constchar*from);/将一字符串追加到另一字符串后面
7. web_find("find_time","What=2006-03-0118:21:16.882",LAST);/增加检查点,检查“2006-03-0118:21:16.882”这个字符串是否出现在当前页面上。find_time为自己任意输入的检查点名称。
8. 事务函数
lr_end_sub_transaction/标记子事务的结束以便进行性能分析
lr_end_transaction/标记LoadRunner事务的结束
lr_end_transaction_instance/标记事务实例的结束以便进行性能分析
lr_fail_trans_with_error/将打开事务的状态设置为LR_FAIL并发送错误消息
lr_get_trans_instance_duration/获取事务实例的持续时间(由它的句柄指定)
lr_get_trans_instance_wasted_time/获取事务实例浪费的时间(由它的句柄指定)
lr_get_transaction_duration/获取事务的持续时间(按事务的名称)
lr_get_transaction_think_time/获取事务的思考时间(按事务的名称)
lr_get_transaction_wasted_time/获取事务浪费的时间(按事务的名称)
lr_resume_transaction/继续收集事务数据以便进行性能分析
lr_resume_transaction_instance/继续收集事务实例数据以便进行性能分析
lr_set_transaction_instance_status/设置事务实例的状态
lr_set_transaction_status/设置打开事务的状态
lr_set_transaction_status_by_name/设置事务的状态
lr_start_sub_transaction/标记子事务的开始
lr_start_transaction/标记事务的开始
lr_start_transaction_instance/启动嵌套事务(由它的父事务的句柄指定)
lr_stop_transaction/停止事务数据的收集
lr_stop_transaction_instance/停止事务(由它的句柄指定)数据的收集
lr_wasted_time/消除所有打开事务浪费的时间
lr_end_sub_transaction/标记子事务的结束以便进行性能分析
r_end_transaction/标记LoadRunner事务的结束
lr_end_transaction_instance/标记事务实例的结束以便进行性能分析
lr_fail_trans_with_error/将打开事务的状态设置为LR_FAIL并
9. 命令行分析函数
lr_get_attrib_double/检索脚本命令行中使用的double类型变量
lr_get_attrib_long/检索脚本命令行中使用的long类型变量
lr_get_attrib_string/检索脚本命令行中使用的字符串
10. 信息性函数
lr_user_data_point/记录用户定义的数据示例
lr_whoami/将有关Vuser脚本的信息返回给Vuser脚本
lr_get_host_name/返回执行Vuser脚本的主机名
lr_get_master_host_name/返回运行LoadRunnerController的计算机名
11. 字符串函数
lr_eval_string/用参数的当前值替换参数
lr_save_string/将以NULL结尾的字符串保存到参数中
lr_save_var/将变长字符串保存到参数中
lr_save_datetime/将当前日期和时间保存到参数中
lr_advance_param/前进到下一个可用参数
lr_decrypt/解密已编码的字符串
lr_eval_string_ext/检索指向包含参数数据的缓冲区的指针
lr_eval_string_ext_free/释放由lr_eval_string_ext分配的指针
lr_save_searched_string/在缓冲区中搜索字符串实例,并相对于该字符串实例,该缓冲区的一部分保存到参数中
12. 消息函数
lr_debug_message/将调试消息发送到输出窗口
lr_error_message/将错误消息发送到输出窗口
lr_get_debug_message/检索当前的消息类
lr_log_message/将输出消息直接发送到output.txt文件,此文件位于Vuser脚本目录中。该函数有助于防止输出消息干扰TCP/IP通信。
lr_output_message/将消息发送到输出窗口
lr_set_debug_message/为输出消息设置消息类
lr_vuser_status_message/生成格式化输出并将其打印到ControllerVuser状态区域。
lr_message/将消息发送到Vuser日志和输出窗口
13. 操作函数
web_custom_request允许您使用HTTP支持的任何方法来创建自定义HTTP请求
web_image在定义的图像上模拟鼠标单击
web_link在定义的文本链接上模拟鼠标单击
web_submit_data执行“无条件”或“无上下文”的表单
web_submit_form模拟表单的提交
web_url加载由“URL”属性指定的URL14. 身份验证函数
身份验证函数web_set_certificate使Vuser使用在InternetExplorer注册表中列出的特定证书
身份验证函数web_set_certificate_ex指定证书和密钥文件的位置和格式信息
身份验证函数web_set_user指定Web服务器的登录字符串和密码,用于Web服务器上已验证用户身份的区域15. 缓存函数
缓存函数web_cache_cleanup清除缓存模拟程序的内容
16. 检查函数
检查函数web_find在HTML页内搜索指定的文本字符串
检查函数web_global_verification在所有后面的HTTP请求中搜索文本字符串
检查函数web_image_check验证指定的图像是否存在于HTML页内
检查函数web_reg_find在后面的HTTP请求中注册对HTML源或原始缓冲区中文本字符串的搜索17. 连接定义函数
连接定义函数web_disable_keep_alive禁用Keep-AliveHTTP连接
连接定义函数web_enable_keep_alive启用Keep-AliveHTTP连接
连接定义函数web_set_connections_limit设置Vuser在运行脚本时可以同时打开连接的最大数目18. 并发组
web_concurrent_end标记并发组的结束
web_concurrent_start标记并发组的开始19. cook函数
web_add_cookie添加新的Cookie或修改现有的Cookie
web_cleanup_cookies删除当前由Vuser存储的所有Cookie
web_remove_cookie删除指定的Cookie20. 关联函数
web_create_html_param将HTML页上的动态信息保存到参数中。(LR6.5及更低版本)
web_create_html_param_ex基于包含在HTML页内的动态信息创建参数(使用嵌入边界)(LR6.5及更低版本)。
关联函数web_reg_save_param基于包含在HTML页内的动态信息创建参数(不使用嵌入边界)
关联函数web_set_max_html_param_len设置已检索的动态HTML信息的最大长度21. 筛选器函数
web_add_filter设置在下载时包括或排除URL的条件
web_add_auto_filter设置在下载时包括或排除URL的条件
web_remove_auto_filter禁用对下载内容的筛选22. 标头函数
web_add_auto_header向所有后面的HTTP请求中添加自定义标头
web_add_header向下一个HTTP请求中添加自定义标头
web_cleanup_auto_headers停止向后面的HTTP请求中添加自定义标头
web_remove_auto_header停止向后面的HTTP请求中添加特定的标头381页
web_revert_auto_header停止向后面的HTTP请求中添加特定的标头,但是生成隐性web_save_header将请求和响应标头保存到变量中
代理服务器函数web_set_proxy指定将所有后面的HTTP请求定向到指定的代理服务器
代理服务器函数web_set_proxy_bypass指定Vuser直接访问(即不通过指定的代理服务器访问)的服务器列表
代理服务器函数web_set_proxy_bypass_local指定Vuser对于本地(Intranet)地址是否应该避开代理服务器
代理服务器函数web_set_secure_proxy指定将所有后面的HTTP请求定向到服务器
重播函数web_set_max_retries设置操作步骤的最大重试次数
重播函数web_set_timeout指定Vuser等待执行指定任务的最长时间
其他函数web_convert_param将HTML参数转换成URL或纯文本
其他函数web_get_int_property返回有关上一个HTTP请求的特定信息
其他函数web_report_data_point指定数据点并将其添加到测试结果中
其他函数web_set_option在非HTML资源的编码、重定向和下载区域中设置Web选项
其他函数web_set_sockets_option设置套接字的选项23. 控制类函数
lr_start_transaction为性能分析标记事务的开始
lr_end_transaction为性能分析标记事务的结束
lr_rendezvous在Vuser脚本中设置集合点
lr_think_time暂停Vuser脚本中命令之间的执行LR_函数2
2008-04-11 18:03:47
web_custom_request
允许您使用 HTTP 支持的任何方法来创建自定义 HTTP 请求
web_image
在定义的图像上模拟鼠标单击
web_link
在定义的文本链接上模拟鼠标单击
web_submit_data
执行“无条件”或“无上下文”的表单
web_submit_form
模拟表单的提交
web_url
加载由“URL”属性指定的 URL
web_set_certificate
使 Vuser 使用在 Internet Explorer 注册表中列出的特定证书
web_set_certificate_ex
指定证书和密钥文件的位置和格式信息
web_set_user
指定 Web 服务器的登录字符串和密码,用于 Web 服务器上已验证用户身份的区域
web_cache_cleanup
清除缓存模拟程序的内容
web_find
在 HTML 页内搜索指定的文本字符串
web_global_verification
在所有后面的 HTTP 请求中搜索文本字符串
web_image_check
验证指定的图像是否存在于 HTML页内
web_reg_find
在后面的 HTTP 请求中注册对 HTML源或原始缓冲区中文本字符串的搜索
web_disable_keep_alive
禁用 Keep-Alive HTTP 连接
web_enable_keep_alive
启用 Keep-Alive HTTP 连接
web_set_connections_limit
设置 Vuser 在运行脚本时可以同时打开连接的最大数目
web_concurrent_end
标记并发组的结束
web_concurrent_start
标记并发组的开始
web_add_cookie
添加新的 Cookie 或修改现有的 Cookie
web_cleanup_cookies
删除当前由 Vuser 存储的所有 Cookie
web_remove_cookie
删除指定的 Cookie
web_create_html_param
将 HTML 页上的动态信息保存到参数中。(LR 6.5 及更低版本)
web_create_html_param_ex
基于包含在 HTML 页内的动态信息创建参数(使用嵌入边界)(LR 6.5 及更低版本)。
web_reg_save_param
基于包含在 HTML 页内的动态信息创建参数(不使用嵌入边界)
web_set_max_html_param_len
设置已检索的动态 HTML 信息的最大长度
web_add_filter
设置在下载时包括或排除 URL 的条件
web_add_auto_filter
设置在下载时包括或排除 URL 的条件
web_remove_auto_filter
禁用对下载内容的筛选
web_add_auto_header
向所有后面的 HTTP 请求中添加自定义标头
web_add_header
向下一个 HTTP 请求中添加自定义标头
web_cleanup_auto_headers
停止向后面的 HTTP 请求中添加自定义标头
web_remove_auto_header
停止向后面的 HTTP 请求中添加特定的标头
web_revert_auto_header
停止向后面的 HTTP 请求中添加特定的标头,但是生成隐性标头
web_save_header
将请求和响应标头保存到变量中
web_set_proxy
指定将所有后面的 HTTP 请求定向到指定的代理服务器
web_set_proxy_bypass
指定 Vuser 直接访问(即不通过指定的代理服务器访问)的服务器列表
web_set_proxy_bypass_local
指定 Vuser 对于本地 (Intranet) 地址是否应该避开代理服务器
web_set_secure_proxy
指定将所有后面的 HTTP 请求定向到服务器web_set_max_retries
设置操作步骤的最大重试次数
web_set_timeout
指定 Vuser 等待执行指定任务的最长时间
web_convert_param
将 HTML 参数转换成 URL 或纯文本
web_get_int_property
返回有关上一个 HTTP 请求的特定信息
web_report_data_point
指定数据点并将其添加到测试结果中
web_set_option
在非 HTML 资源的编码、重定向和下载区域中设置 Web 选项
web_set_sockets_option
设置套接字的选项LR_函数
2008-04-11 18:01:55
给出一部分常用的LoadRunner函数,供大家参考。 LR函数:
lr_start_transaction
为性能分析标记事务的开始
lr_end_transaction
为性能分析标记事务的结束
lr_rendezvous
在 Vuser 脚本中设置集合点
lr_think_time
暂停 Vuser 脚本中命令之间的执行
lr_end_sub_transaction
标记子事务的结束以便进行性能分析
lr_end_transaction
标记 LoadRunner 事务的结束
Lr_end_transaction("trans1",Lr_auto);
lr_end_transaction_instance
标记事务实例的结束以便进行性能分析
lr_fail_trans_with_error
将打开事务的状态设置为 LR_FAIL 并发送错误消息
lr_get_trans_instance_duration
获取事务实例的持续时间(由它的句柄指定)
lr_get_trans_instance_wasted_time
获取事务实例浪费的时间(由它的句柄指定)
lr_get_transaction_duration
获取事务的持续时间(按事务的名称)
lr_get_transaction_think_time
获取事务的思考时间(按事务的名称)
lr_get_transaction_wasted_time
获取事务浪费的时间(按事务的名称)
lr_resume_transaction
继续收集事务数据以便进行性能分析
lr_resume_transaction_instance
继续收集事务实例数据以便进行性能分析
lr_set_transaction_instance_status
设置事务实例的状态
lr_set_transaction_status
设置打开事务的状态
lr_set_transaction_status_by_name
设置事务的状态
lr_start_sub_transaction
标记子事务的开始
lr_start_transaction
标记事务的开始
Lr_start_transaction("trans1");
lr_start_transaction_instance
启动嵌套事务(由它的父事务的句柄指定)
lr_stop_transaction
停止事务数据的收集
lr_stop_transaction_instance
停止事务(由它的句柄指定)数据的收集
lr_wasted_time
消除所有打开事务浪费的时间
lr_get_attrib_double
检索脚本命令行中使用的 double 类型变量
lr_get_attrib_long
检索脚本命令行中使用的 long 类型变量
lr_get_attrib_string
检索脚本命令行中使用的字符串
lr_user_data_point
记录用户定义的数据示例
lr_whoami
将有关 Vuser 脚本的信息返回给 Vuser 脚本
lr_get_host_name
返回执行 Vuser 脚本的主机名
lr_get_master_host_name
返回运行 LoadRunner Controller 的计算机名
lr_eval_string
用参数的当前值替换参数
lr_save_string
将以 NULL 结尾的字符串保存到参数中
lr_save_var
将变长字符串保存到参数中
lr_save_datetime
将当前日期和时间保存到参数中
lr _advance_param
前进到下一个可用参数
lr _decrypt
解密已编码的字符串
lr_eval_string_ext
检索指向包含参数数据的缓冲区的指针
lr_eval_string_ext_free
释放由 lr_eval_string_ext 分配的指针
lr_save_searched_string
在缓冲区中搜索字符串实例,并相对于该字符串实例,将该缓冲区的一部分保存到参数中
lr_debug_message
将调试信息发送到输出窗口
lr_error_message
将错误消息发送到输出窗口
lr_get_debug_message
检索当前消息类
lr_log_message
将消息发送到日志文件
lr_output_message
将消息发送到输出窗口
lr_set_debug_message
设置调试消息类
lr_vuser_status_message
生成带格式的输出,并将其写到 ControllerVuser 状态区域
lr_message
将消息发送到 Vuser 日志和输出窗口
lr_load_dll
加载外部 DLL
lr_peek_events
指明可以暂停 Vuser 脚本执行的位置
lr_think_time
暂停脚本的执行,以模拟思考时间(实际用户在操作之间暂停以进行思考的时间)
lr_continue_on_error
指定处理错误的方法
lr_continue_on_error (0);lr_continue_on_error (1);
lr_rendezvous
在 Vuser 脚本中设置集合点
TE_wait_cursor
等待光标出现在终端窗口的指定位置
TE_wait_silent
等待客户端应用程序在指定秒数内处于静默状态
TE_wait_sync
等待系统从 X-SYSTEM 或输入禁止模式返回
TE_wait_text
等待字符串出现在指定位置
TE_wait_sync_transaction
记录系统在最近的 X SYSTEM 模式下保持的时间
WEB函数列表:
web_custom_request
允许您使用 HTTP 支持的任何方法来创建自定义 HTTP 请求
web_image
在定义的图像上模拟鼠标单击
web_link
在定义的文本链接上模拟鼠标单击
web_submit_data
执行“无条件”或“无上下文”的表单
web_submit_form
模拟表单的提交
web_url
加载由“URL”属性指定的 URL
web_set_certificate
使 Vuser 使用在 Internet Explorer 注册表中列出的特定证书
web_set_certificate_ex
指定证书和密钥文件的位置和格式信息
web_set_user
指定 Web 服务器的登录字符串和密码,用于 Web 服务器上已验证用户身份的区域
web_cache_cleanup
清除缓存模拟程序的内容
web_find
在 HTML 页内搜索指定的文本字符串
web_global_verification
在所有后面的 HTTP 请求中搜索文本字符串
web_image_check
验证指定的图像是否存在于 HTML页内
web_reg_find
在后面的 HTTP 请求中注册对 HTML源或原始缓冲区中文本字符串的搜索
web_disable_keep_alive
禁用 Keep-Alive HTTP 连接
web_enable_keep_alive
启用 Keep-Alive HTTP 连接
web_set_connections_limit
设置 Vuser 在运行脚本时可以同时打开连接的最大数目
web_concurrent_end
标记并发组的结束
web_concurrent_start
标记并发组的开始
web_add_cookie
添加新的 Cookie 或修改现有的 Cookie
web_cleanup_cookies
删除当前由 Vuser 存储的所有 Cookie
web_remove_cookie
删除指定的 Cookie
web_create_html_param
将 HTML 页上的动态信息保存到参数中。(LR 6.5 及更低版本)
web_create_html_param_ex
基于包含在 HTML 页内的动态信息创建参数(使用嵌入边界)(LR 6.5 及更低版本)。
web_reg_save_param
基于包含在 HTML 页内的动态信息创建参数(不使用嵌入边界)
web_set_max_html_param_len
设置已检索的动态 HTML 信息的最大长度
web_add_filter
设置在下载时包括或排除 URL 的条件
web_add_auto_filter
设置在下载时包括或排除 URL 的条件
web_remove_auto_filter
禁用对下载内容的筛选
web_add_auto_header
向所有后面的 HTTP 请求中添加自定义标头
web_add_header
向下一个 HTTP 请求中添加自定义标头
web_cleanup_auto_headers
停止向后面的 HTTP 请求中添加自定义标头
web_remove_auto_header
停止向后面的 HTTP 请求中添加特定的标头
web_revert_auto_header
停止向后面的 HTTP 请求中添加特定的标头,但是生成隐性标头
web_save_header
将请求和响应标头保存到变量中
web_set_proxy
指定将所有后面的 HTTP 请求定向到指定的代理服务器
web_set_proxy_bypass
指定 Vuser 直接访问(即不通过指定的代理服务器访问)的服务器列表
web_set_proxy_bypass_local
指定 Vuser 对于本地 (Intranet) 地址是否应该避开代理服务器
web_set_secure_proxy
指定将所有后面的 HTTP 请求定向到服务器
web_set_max_retries
设置操作步骤的最大重试次数
web_set_timeout
指定 Vuser 等待执行指定任务的最长时间
web_convert_param
将 HTML 参数转换成 URL 或纯文本
web_get_int_property
返回有关上一个 HTTP 请求的特定信息
web_report_data_point
指定数据点并将其添加到测试结果中
web_set_option
在非 HTML 资源的编码、重定向和下载区域中设置 Web 选项
web_set_sockets_option
设置套接字的选项
标题搜索
我的存档
数据统计
- 访问量: 61519
- 日志数: 62
- 建立时间: 2007-10-11
- 更新时间: 2015-02-12
RSS订阅
清空Cookie - 联系我们 - 51Testing软件测试网 - 交流论坛 - 空间列表 - 站点存档 - 升级自己的空间
Powered by 51Testing © 2003-2021
沪ICP备05003035号
