
-
���������������
2011-07-07 10:36:03
ת��http://www.uml.org.cn/requirementproject/201011304.asp������������ķ�������
2010-11-30 ����: sdstc ��Դ: �����������ɱ�
���������������ǿ����������������ݣ���������ֽ��Խ��ϸ���������������������˽�Խ�����Ҫ���е��������ݾ�Խ�������Բ�����������������İ���Խ����ϸ�IJ��������Ǻ������Ը����ʵ���Ҫָ�꣬���������Ǽ�����Ը��ǵķ�ĸ��û����ϸ�IJ������������Ч�Ľ��в��Ը��Ǽ��㡣
����������ִ�н�����һϵ�в�ͬ�IJ������͵�ִ�й�����ɵģ�ÿ�ֲ������Ͷ��������IJ���Ŀ���֧�ּ�����ÿ�ֲ������Ͷ�ֻ�����ڶԲ���Ŀ���һ���������������Խ��в��ԣ�ȷ�IJ������Ϳ��Ը��������Դ��°빦����Ч����
�����е��������Է���������̫���죬�Բ�������Ͳ������͵ķ����������õķ�����Ҫ�Ǹ��ݾ�������ռ����������÷��������ڲ��������Ա�IJ��Ծ��飬�ɴ˷����ó��IJ��������������������²���������Ʋ���֣����Ը��Ƕȵͣ�����Ŀ���Բ�ǿ��������©��ȱ�ݡ�
���ɼ�����ζԲ����������ϸ�µ�������������ȷ����ִ��ʱ�IJ������ͣ���һ��ؽ����������⡣
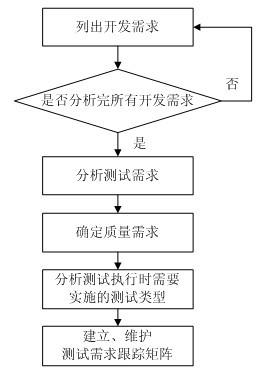
���м��ڴˣ�����������ҪĿ�������ṩһ��������������ķ������������Է��㡢�꾡�Ļ�ȡ����������ȷ����ִ��ʱ��Ҫʵʩ�IJ������͡�
��Ϊʵ������Ŀ�ģ��������ṩ��һ������������������ķ������������²��裺
��a���г��������������о��пɲ����ԵĿ�������
��b���Բ���a���г���ÿһ�����������γɿɲ��Եķֲ������IJ�������
��c���Բ���b���γɵ�ÿһ����������GB/T 16260.1-2006���������� ��Ʒ���� ��1���֣�����ģ�͡��ж���������ڲ�/�ⲿ����ģ����ȷ��������Ʒ����������
��d���Բ���c����ȷ������������������ִ��ʱ��Ҫʵʩ�IJ������ͣ�
��e����������������پ��Բ���������й�����
������ʵʩ��ʽ��
�������ϸ�ͼ��ʵʩ���Ա���������ϸ��˵����
���������������б����μ�ͼ2����ÿһ�����������Ӧ�Ŀ����ĵ����½ں���Ϊ���������ʶ��ʹ����������ļ�����Ϊԭʼ��������������û���ĵ���Դ�Ŀ���������������������©������б�ʶ���������������ȡ����Դ��Ϣ���翪���ĵ�����ر������û�����Ա�Ľ����ȡ�
����������ȡ�Ŀ��������п��ܴ����ظ������࣬��Ҫ����������ͨ�����·���������������
��1��ɾ����ɾ��ԭ���������б����ظ��ġ�����ĺ��а�����ϵ�Ŀ�������������
��2��ϸ������̫���ԵĿ���������������ϸ����
��3���ϲ�����������ƵĿ�������������ʱ��Ҫ������кϲ���
����ͼ2���У�����ÿһ���������Ӳ��ԽǶ������ǣ��γɿɲ��Եķֲ������IJ���������أ�ͨ������ÿ���������������е����롢��������������ơ�Լ���ȣ�������Ӧ����֤���ݣ�ͨ��������������ģ��֮���ҵ��˳��������ģ��֮�䴫�ݵ���Ϣ�����ݣ��Դ��ڹ��ܽ����Ĺ����������Ӧ����֤���ݡ�
����ÿһ����������GB /T16260.1������������������ԽǶȳ�����ȷ������Ӧ�����������ԡ��������ʺ��ԡ�ȷ�ԡ��������ԡ����ܰ�ȫ�ԡ������ԡ��ݴ��ԡ��ָ��ԡ��������ԡ���ѧ�ԡ��ײ����ԡ������ԡ�ʱ�����ԡ���Դ�����ԡ������ԡ��ı��ԡ��ȶ��ԡ��ײ����ԡ���Ӧ�ԡ��װ�װ�ԡ������ԡ����滻�Ժ������Է���Ķ��������ȷ��ÿһ��������������Ӧ�����������ԡ�
���������Կ��Ի���Ϊ���²������ͣ����ܲ��ԡ���ȫ�Բ��ԡ��ӿڲ��ԡ��������ԡ������Բ��ԡ��ṹ���ԡ��û�������ԡ����ز��ԡ�ѹ�����ԡ�ƣ��ǿ�Ȳ��ԡ��ָ��Բ��ԡ����ò��ԡ������Բ��ԡ���װ���Եȡ�
����ͬ�����������Կ���ȷ������ͬ�IJ������ݣ���Щ�������ݿ���ͨ����ͬ�IJ���������ʵʩ�����磬���װ�װ�Է��濼�ǣ��������ݰ�������������װ�Ĺ���������װ�Ŀɶ����ԡ���װ��Ƶ��걸�ԡ���װ�����ļ����ԡ��Ƿ��������°�װ�����Ӧ�˲��������еİ�װ���ԣ�ͨ����װ���Կ�����֤��Щ�������ݡ�
����������һ��ʵʩ���ǽ���һ��������������������͵Ĺ�ϵ�����μ�ͼ3���ö�Ӧ��������������������������͵Ķ�Ӧ��ϵ������ȷ�������������ԣ�����ʹ�øö�Ӧ����ȷ���������͡�
����������������پ��μ�ͼ4�����������������ȷ���Ŀ�������������������������Ը����������
��ʹ�ò���������پ���Բ���������й��������ڲ��Թ������ԣ�������������һ����Ա����Ĺ��̣������������˱�����������������֮�仯����������һ�������仯����Ҫ��������ٱ�����ά�����������ù������̣�����������������ص����ݽ���ͬ�������
��ʵʩ��������һ����������������������
��������������Ա����Ϣ
������������һ����������ѵ��Ϣ������ѵ�����⡢֤�顢���ݡ���ֹʱ�䡢���á��ص㡢������������ѵ�����⡢���ݡ���ֹʱ�䡢���á�����Ϊ�������ѵ����ʼʱ�䲻�����ڽ�ֹʱ�䣬��ѵ���þ�ȷ��Ԫ�Ƿ֡�ÿһ������������ݹ��Ӧ��ѭ�����ֵ��Ҫ��
��һ��������������������ķ����������£�
��1���������������б����г����пɲ����ԵĿ�������
���
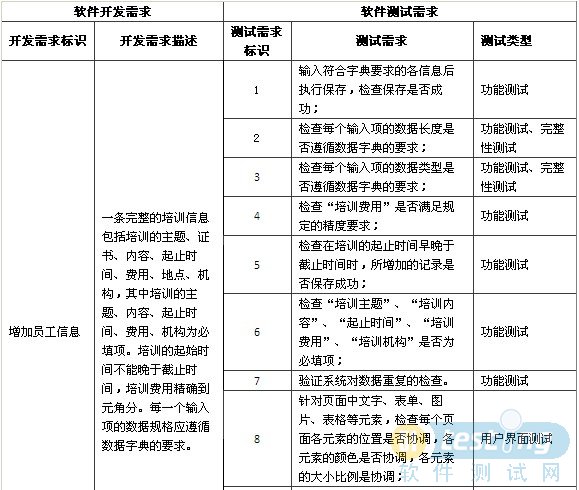
���������ʶ
������������
��Ϣ��Դ
1
����Ա����Ϣ
һ����������ѵ��Ϣ������ѵ�����⡢֤�顢���ݡ���ֹʱ�䡢���á��ص㡢������������ѵ�����⡢���ݡ���ֹʱ�䡢���á�����Ϊ�������ѵ����ʼʱ�䲻�����ڽ�ֹʱ�䣬��ѵ���þ�ȷ��Ԫ�Ƿ���ÿһ������������ݹ��Ӧ��ѭ�����ֵ��Ҫ��
��������Դ����ϵͳҵ������˵���顷
2�����ݿ���������������Ӳ��ԽǶ������ǣ�����ÿ���������������е����롢��������������ơ�Լ���ȣ��γɿɲ��Եķֲ������IJ�������
����3����GB /T16260.1������������������ԽǶȳ�����ȷ��ÿ��������������Ӧ�����������ԡ�
����4���ο�ͼ3��������ȷ�������������ԣ�ѡ���ʺϵIJ������͡�
����5������������������������������ȷ���Ŀ�������������������������Ը����������
ͼ1������������ͼ
���
���������ʶ
������������
��Ϣ��Դ
ͼ2���������б�

ͼ3������������������Ͷ�Ӧ��

-
���ܲ��ԡ����ز��ԡ�ѹ������
2010-08-01 19:46:10
�����Բ�����Ա��ʱ������һ���ܺõ����⣺����ζ�������/����/ѹ�����ԣ��ںܶ�ʱ�����Ƕ��ǽ�������Ϊ�ɻ����滻����ͬ������ʹ�ã�Ȼ��ʵ��������֮��IJ����DZȽϴ�ġ���������Ǹ������Լ���һЩ���飬�������������д��һ���Ƚϼ����ۣ���ȻҲͬʱ�ο���һЩ��������������Ķ��壬����˵��
"Testing computer software" by Kaner et al
"Software testing techniques" by Loveland et al
"Testing applications on the Web" by Nguyen et al
Update July 7th, 2005
����վ�ķ�����־���ҿ��Կ�����ƪ���Ӿ����ᱻ������GOOGLE�������������������������һ����д��һ���������ӵĵ�ַ����'More on performance vs. load testing'.
���ܲ���
���ܲ��Ե�Ŀ�IJ���ȥ��bugs,�����ų�ϵͳ��ƿ�����Լ�Ϊ�Ժ�Ļع���Խ���һ�����������ܲ��ԵIJ�����ʵ���Ͼ���һ���dz�С���ܿصIJ����������̡������������£��������������ʱ���Ѿ����㹻�ȶ��ˣ�����������̵���˳���Ľ��С�
һ�������Ѷ���õ�Ԥ��ֵ����һ������������ܲ��ԵĻ���Ҫ�ء���������Լ�����֪��ϵͳ������Щʲô��Ҫ��ģ���ô��������Ҫ���Եķ����ֶ���û��ָ�������*�����磬��һ��webӦ�������ܲ��ԣ���Ҫ֪����������������
�ڲ�ͬ�����û�������HTTP����������µĸ���Ԥ��ֵ*
�ɽ��ܵ���Ӧʱ��
����֪�����Ŀ�����Ϳ��Կ�ʼʹ�ö�ϵͳ�������Ӹ��صķ������۲�ϵͳ��ƿ�����ڡ�������webӦ��ϵͳ�������ӣ���Щƿ���ɴ����ڶ����Σ������ʹ�ö��ֹ������������ǵ����ڣ�
��Ӧ�ò㣬������Ա����ͨ��profilers�����ֵ�Ч�ʵĴ��룬����˵�ϲ�IJ����㷨
�����ݿ��㣬������Ա�����ݿ����Ա��DBA������ͨ���ض������ݿ�profilers���¼�̽����*��query optimizers��
�ڲ���ϵͳ�㣬ϵͳ����ʦ����ʹ��һЩ��������Unix��IJ���ϵͳ�е�top,vmstat,iostat,��Windowsϵͳ�е�PerfMon�����CPU�����ڣ�swap,����I/O��Ӳ����Դ��ר�ŵ��ں˼������Ҳ��������һ�����ϱ�ʹ�á�
��������ϣ����繤��ʦ����ʹ�ñ���̽��������tcpdump��,����Э�����������ethereal��,���������Ĺ��ߣ���netstat,MRTG,ntop,mii-tool��
�Ӳ��ԵĹ۵��������������������Ļ����һ�ְеķ���������ϵͳ���ڵ��⼰��ǶȽ�����鼰��ء��������*��ȡ�ü�������ϵͳ�ĵ������Ϊ������Ȼ����һ�����衣
Ȼ��������������ķ����⣩������Ա�ڸ�����ϵͳ���и�������*������Ϊ�˲�������������ĸ��ز���-load testing�ĸ����죬�������������飩��ʱ��Ҳ��ȡ�˺ںеķ����������WEBӦ��������������Ա����ʹ�ù�����ģ�Ⲣ���û�����HTTP���Ӽ�������Ӧʱ�䡣������ǰʹ�ù����������ĸ��ز��Կ�Դ������ab,siege,httperf��һ�����������Ĺ�����OpenSTA������û�ù�����Ҳ��û���ù�The Grinder������ߣ��������ҽ�Ҫ����������������ǰ��
����������*�Ľ����ʾ��ϵͳ��������û�дﵽ����Ԥ��Ŀ��ʱ�������Ҫ��Ӧ�ú����ݿ�ĵ�����ʱ���ˡ�ͬʱ��Ҫȷ������Ĵ������еþ����ܸ�Ч���Լ����ݿ��ڸ����IJ���ϵͳ��Ӳ�����õ���������Ż�����������������TDD����ʵ���ᷢ�����������Ľṹ����Ƿdz����õ�*�������ͨ����������*��ʱ������ĺ�����*����ǿ�ִ浥Ԫ���������Mike Clark��jUnitPerf*����һ���ض��ĺ������߷�����������*�͵��Թ�������Ա�Ϳ�����jUnitPerf�У��������ĵ�Ԫ����*��ȷ�������Դﵽ���ؼ�ʱ���ϵ���������Mike Clark����Ϊ���������ܲ��ԡ�����˳��Ҳ��һ�����Ѿ�����һ������Python��jUnitPerf�ij����о����ҳ�֮ΪpyUnitPerf.
�����ڵ��Թ�Ӧ�ó������ݿ��ϵͳ����û�дﵽ���ܵ�Ԥ��Ŀ�꣬����������£�������һЩ�����ĵ��Ե�����*�������ǰ�潲�����Ǽ��������ʹ�õġ��������һЩ��Ӧ�ó������*֮���Կ������WEBӦ��ϵͳ���ܵ����ӣ�
ʹ��WEB����װ�ƣ���Squid�ṩ��װ��
���߷���������ҳ��̬�����Ա�����Щ�߷����������ݿ���д����ĵ���
ͨ������ƽ��ķ�����ˮƽ����WEB�������Ľṹ*
��ˮƽ�������ݿ�Ⱥ�������Ƿ�Ϊ��д��������ֻ����������Ҫ��ֻ��������Ⱥ����ƽ�⡣*
ͨ�����Ӹ����Ӳ����Դ��CPU���ڴ棬���̵ȣ����������WEB�����ݿ������Ⱥ
��������Ĵ���
�������ڵ�WEBӦ��ϵͳ����ʮ�ָ��ӵ�ϵͳ�����ܵ�����ʱҪ����һЩ�����Բ��С���ÿ����һ�����������²�ȵ�ʱ��һ��Ҫ�dz�С�ģ�����Ļ����ڱ仯�н����кܶ�����ȷ�����ظ��IJ�ȷ������*��
��һ���淶�IJ��Ի�������˵һ������ʵ���ԣ����Dz��᳣��������ʵ��Ӧ��ʱ�ķ��������û�����������������£��ֶβ��Ի�����Ҳ��������ʵ�ʻ�����һ���Ӽ��Ϳ��������ó��ˡ���ͬʱϵͳ����������Ҳ��Ҫ��Ӧ�ĵ���һ�㡣
�����и�������*->�������->����ϵͳ�����ѭ��һֱҪ���ظ�ִ�е�������ϵͳ�ﵽ�����������ܱ��˲ſ���ͣ�������ʱ������Ա�Ϳ������������������µ�ϵͳ��ת��ô����ͬʱ��Щ�Ϳ�����Ϊ�Ժ��ڻع�����У������°汾���������ܵ�һ�����ˡ�
���ܲ��Ի�����һ��Ŀ����ǽ���һ�鱻��ϵͳ�Ļ����ݡ��ںܶ���ҵ�ж�����������ҵ���Ļ����ݣ�����˵TPC�����ġ����кܶ���Ӳ�����Ҷ�Ϊ����TCP�����п�ǰ�������ǵĻ������о��ĵ��ԡ�����˵��Ӧ���dz�������˵��������в��Ե�ʱ��û������������Ӳ����Ʒ�н���ȫ������*��
���ز���
���Ƕ��Ѿ������ܲ��Ե��ԵĹ����У���ʶ�����ز����ˡ������ֻ����У�����ζ��ͨ���Զ���������������ϵͳ���Ӹ��ء�������WEBӦ���������������Dz����û�����HTTP���ӵ�������
������ز��ԡ��ڲ�������������ͨ����������Ϊ������ϵͳ���������ܲ���������������Ĺ��̡����ز�����ʱҲ�ᱻ��Ϊ���������ԡ������ߡ��;��Բ���/�־��Բ��ԡ�*
�������Ե����ӣ�
ͨ���༭һ������ļ����������ִ�������
ͨ������һ�������ҵ�����Դ�ӡ��
ͨ����ǧ������û������������ʼ�������
��һ�ֱȽ��ر�����������ǽ��������������ԡ������Ǹ�ϵͳ���Ͽ����������Եġ�
�;��Բ���/�־��Բ��Եĵ����ӣ�
��һ��ѭ���в�ͣ�����пͻ��˳���һ����չʱ���*��
���ز��Ե�Ŀ�ģ�
�ҵ�һЩ�ڲ���������ǰ��Ľ������еĴ��Բ�����û�б��ҳ���bugs,���磬�ڴ����bugs,�ڴ�й¶������������ȵȡ�
��֤Ӧ�ó���ﵽ���ܲ�����ȷ�������ܻ��ߡ�������������лع�����ʱ��ͨ�������ض�������ȵĸ�����ʵ�֡�
�������ܲ��Ժ��ز����ƺ��������ǵ�Ŀ�Ļ����в���ġ�һ���棬���ܲ���ʹ�ø��ز��Եļ��������ߣ��Լ��ò�ͬ�ĸ��س̶�����Ⱥͻ���ϵͳ������һ�������������ز�������һЩ�Ѿ�����õĸ��س̶��Ͻ��в��Եģ�ͨ����ϵͳ���������֮��ϵͳӦ����Ȼ�����ṩȫ�����ܡ�������Ҫ��ȷһ�㣬���ز��Բ�����Ҫ��ϵͳ�����Ϲ��ȵĸ��ض�ʹϵͳ���ܹ���������Ҫʹϵͳ��һ���������͵Ļ������˽�*��
�ڸ��ز��Ե���������У�����Ӧ�÷dz���Ҫ����Ҫ��ʮ�ֳ�������������в��ԡ����ҵľ����е�֪���������÷dz��������*ȥ��Ļ����кܶ����ص�bug�Dz���ĵ��ġ�����˵��LDAP/NIS/Active Directory���ݿ��г�ǧ������û����ʼ��������г�ǧ��������䣬���ݿ��г�G��G�ı����ļ�ϵͳ�к�����ļ�����Ŀ¼�IJ�Σ��ȵȡ���Ȼ��������Ա����Ҫʹ���Զ���������������Щ�Ӵ�����ݼ����Ƚ����˵����κ�����Ľű�����������ʤ����Щ������
ѹ������
ѹ��������ָͨ����ϵͳ���ع��ȵ���Դ������ϵͳû��Ӧ�þ��е���ϵͳ����������������Դ����ʹϵͳ��������ijЩ�����ʱ�����ֿ��Խ���������ԣ���������������Ϊ����ҪĿ����Ϊ�˱�֤ϵͳ�����ϼ������ʵ��Ļָ���������ָ�����ô�����������ǽ����ɻָ��ԡ�
�����ܲ�����Ҫ����һ���ɿ��ƵĻ����Ͳ��ϵIJ�ȵ�ʱ��ѹ������������Ϊ��ϲ��������Ҽ�����Ԥ���ԣ����߰�������һ����Կ���������һ��������IJ�����Ա�������Ǿ�WEBӦ��ϵͳΪ����������һЩ��ϵͳ���е�ѹ�����Է�����
�������Ѿ����ߵIJ����û�������HTTP������
����Ĺرռ��ؿ����ӵ��������ϵ������ϼ�����/·�����Ķ˿ڣ����磬����ͨ��SNMP������ʵ�֣�
�����ݿ����Ȼ��������
��ϵͳ�������е�ʱ���ؽ�һ��RAID����
��WEB�����ݿ������������������Դ����CPU���ڴ棬���̣����磩�Ľ���
�ҿ��Կ϶�һЩ����ʹ�÷dz��淽�����ƻ�ϵͳ�IJ�����Ա���Խ�һ����ʵ����б��ġ�ֻ��ѹ�����Բ����Ǽ�Ϊ��һ���ƻ��Ŀ�ж�ȥ�ƻ�ϵͳ��ʵ�������ǿ����ò��Թ���ʦ�۲�ϵͳ�Գ��ֹ���ʱϵͳ�ķ�Ӧ��ϵͳ�Dz��DZ�������������ʱ��״̬���Dz�������ͻȻ��������ˣ����Ƿ�ֻ�ǹ����Ƕ�ɶҲ�����ˣ���ʧЧ��ʱ���Dz�����һЩ��Ӧ*��������֮�����Ƿ����������Իָ���ǰһ���������е�״̬�����Ƿ����û���ʾ��һЩ���õĴ�����Ϣ������ֻ����ʾһЩ���������ʮ�����ƴ��룿ϵͳ�İ�ȫ���Ƿ�Ϊ��ΪһЩ����Ԥ�ϵĹ��϶����������ͣ���Щ�������һֱ����ȥ�ġ�
����
��������ֻ���ᵽһЩ������/����/ѹ��������Ӧ��ֵ��ע���һЩ�Ƚϻ��������⣬�����������Ҹ��˾������ܲ��Լ�������һ������Ȥ�Ļ��⣬�ҽ������Ժ��������������������ġ���Դ�ġ�
Monday, February 28, 2005
Performance vs. load vs. stress testing
Here's a good interview question for a tester: how do you define performance/load/stress testing? Many times people use these terms interchangeably, but they have in fact quite different meanings. This post is a quick review of these concepts, based on my own experience, but also using definitions from testing literature -- in particular: "Testing computer software" by Kaner et al, "Software testing techniques" by Loveland et al, and "Testing applications on the Web" by Nguyen et al.
Update July 7th, 2005
From the referrer logs I see that this post comes up fairly often in Google searches. I'm updating it with a link to a later post I wrote called 'More on performance vs. load testing'.
Performance testing
The goal of performance testing is not to find bugs, but to eliminate bottlenecks and establish a baseline for future regression testing. To conduct performance testing is to engage in a carefully controlled process of measurement and analysis. Ideally, the software under test is already stable enough so that this process can proceed smoothly.
A clearly defined set of expectations is essential for meaningful performance testing. If you don't know where you want to go in terms of the performance of the system, then it matters little which direction you take (remember Alice and the Cheshire Cat?). For example, for a Web application, you need to know at least two things:
• expected load in terms of concurrent users or HTTP connections
• acceptable response time
Once you know where you want to be, you can start on your way there by constantly increasing the load on the system while looking for bottlenecks. To take again the example of a Web application, these bottlenecks can exist at multiple levels, and to pinpoint them you can use a variety of tools:
• at the application level, developers can use profilers to spot inefficiencies in their code (for example poor search algorithms)
• at the database level, developers and DBAs can use database-specific profilers and query optimizers
• at the operating system level, system engineers can use utilities such as top, vmstat, iostat (on Unix-type systems) and PerfMon (on Windows) to monitor hardware resources such as CPU, memory, swap, disk I/O; specialized kernel monitoring software can also be used
• at the network level, network engineers can use packet sniffers such as tcpdump, network protocol analyzers such as ethereal, and various utilities such as netstat, MRTG, ntop, mii-tool
From a testing point of view, the activities described above all take a white-box approach, where the system is inspected and monitored "from the inside out" and from a variety of angles. Measurements are taken and analyzed, and as a result, tuning is done.
However, testers also take a black-box approach in running the load tests against the system under test. For a Web application, testers will use tools that simulate concurrent users/HTTP connections and measure response times. Some lightweight open source tools I've used in the past for this purpose are ab, siege, httperf. A more heavyweight tool I haven't used yet is OpenSTA. I also haven't used The Grinder yet, but it is high on my TODO list.
When the results of the load test indicate that performance of the system does not meet its expected goals, it is time for tuning, starting with the application and the database. You want to make sure your code runs as efficiently as possible and your database is optimized on a given OS/hardware configurations. TDD practitioners will find very useful in this context a framework such as Mike Clark's jUnitPerf, which enhances existing unit test code with load test and timed test functionality. Once a particular function or method has been profiled and tuned, developers can then wrap its unit tests in jUnitPerf and ensure that it meets performance requirements of load and timing. Mike Clark calls this "continuous performance testing". I should also mention that I've done an initial port of jUnitPerf to Python -- I called it pyUnitPerf.
If, after tuning the application and the database, the system still doesn't meet its expected goals in terms of performance, a wide array of tuning procedures is available at the all the levels discussed before. Here are some examples of things you can do to enhance the performance of a Web application outside of the application code per se:
• Use Web cache mechanisms, such as the one provided by Squid
• Publish highly-requested Web pages statically, so that they don't hit the database
• Scale the Web server farm horizontally via load balancing
• Scale the database servers horizontally and split them into read/write servers and read-only servers, then load balance the read-only servers
• Scale the Web and database servers vertically, by adding more hardware resources (CPU, RAM, disks)
• Increase the available network bandwidth
Performance tuning can sometimes be more art than science, due to the sheer complexity of the systems involved in a modern Web application. Care must be taken to modify one variable at a time and redo the measurements, otherwise multiple changes can have subtle interactions that are hard to qualify and repeat.
In a standard test environment such as a test lab, it will not always be possible to replicate the production server configuration. In such cases, a staging environment is used which is a subset of the production environment. The expected performance of the system needs to be scaled down accordingly.
The cycle "run load test->measure performance->tune system" is repeated until the system under test achieves the expected levels of performance. At this point, testers have a baseline for how the system behaves under normal conditions. This baseline can then be used in regression tests to gauge how well a new version of the software performs.
Another common goal of performance testing is to establish benchmark numbers for the system under test. There are many industry-standard benchmarks such as the ones published by TPC, and many hardware/software vendors will fine-tune their systems in such ways as to obtain a high ranking in the TCP top-tens. It is common knowledge that one needs to be wary of any performance claims that do not include a detailed specification of all the hardware and software configurations that were used in that particular test.
Load testing
We have already seen load testing as part of the process of performance testing and tuning. In that context, it meant constantly increasing the load on the system via automated tools. For a Web application, the load is defined in terms of concurrent users or HTTP connections.
In the testing literature, the term "load testing" is usually defined as the process of exercising the system under test by feeding it the largest tasks it can operate with. Load testing is sometimes called volume testing, or longevity/endurance testing.
Examples of volume testing:
• testing a word processor by editing a very large document
• testing a printer by sending it a very large job
• testing a mail server with thousands of users mailboxes
• a specific case of volume testing is zero-volume testing, where the system is fed empty tasks
Examples of longevity/endurance testing:
• testing a client-server application by running the client in a loop against the server over an extended period of time
Goals of load testing:
• expose bugs that do not surface in cursory testing, such as memory management bugs, memory leaks, buffer overflows, etc.
• ensure that the application meets the performance baseline established during performance testing. This is done by running regression tests against the application at a specified maximum load.
Although performance testing and load testing can seem similar, their goals are different. On one hand, performance testing uses load testing techniques and tools for measurement and benchmarking purposes and uses various load levels. On the other hand, load testing operates at a predefined load level, usually the highest load that the system can accept while still functioning properly. Note that load testing does not aim to break the system by overwhelming it, but instead tries to keep the system constantly humming like a well-oiled machine.
In the context of load testing, I want to emphasize the extreme importance of having large datasets available for testing. In my experience, many important bugs simply do not surface unless you deal with very large entities such thousands of users in repositories such as LDAP/NIS/Active Directory, thousands of mail server mailboxes, multi-gigabyte tables in databases, deep file/directory hierarchies on file systems, etc. Testers obviously need automated tools to generate these large data sets, but fortunately any good scr��pting language worth its salt will do the job.
Stress testing
Stress testing tries to break the system under test by overwhelming its resources or by taking resources away from it (in which case it is sometimes called negative testing). The main purpose behind this madness is to make sure that the system fails and recovers gracefully -- this quality is known as recoverability.
Where performance testing demands a controlled environment and repeatable measurements, stress testing joyfully induces chaos and unpredictability. To take again the example of a Web application, here are some ways in which stress can be applied to the system:
• double the baseline number for concurrent users/HTTP connections
• randomly shut down and restart ports on the network switches/routers that connect the servers (via SNMP commands for example)
• take the database offline, then restart it
• rebuild a RAID array while the system is running
• run processes that consume resources (CPU, memory, disk, network) on the Web and database servers
I'm sure devious testers can enhance this list with their favorite ways of breaking systems. However, stress testing does not break the system purely for the pleasure of breaking it, but instead it allows testers to observe how the system reacts to failure. Does it save its state or does it crash suddenly? Does it just hang and freeze or does it fail gracefully? On restart, is it able to recover from the last good state? Does it print out meaningful error messages to the user, or does it merely display incomprehensible hex codes? Is the security of the system compromised because of unexpected failures? And the list goes on.
Conclusion
I am aware that I only scratched the surface in terms of issues, tools and techniques that deserve to be mentioned in the context of performance, load and stress testing. I personally find the topic of performance testing and tuning particularly rich and interesting, and I intend to post more articles on this subject in the future.
posted by Grig Gheorghiu at 7:33 AM������Դ��51testing���ͣ�ת����ע������
ԭʼ���ӣ�http://blog.51testing.com/?61747/action_viewspace_itemid_3036.html -
���簲ȫѧϰ�ʼǣ������У�
2010-07-14 00:22:51
//////////////////////////////////////////////////��ҵ���簲ȫ�ṹ
�����豸��·��������������
����ϵͳ
Ӧ�ó���
//////////////////////////////////////////////////�����豸���ٵ���в
·�������ڲ����������ͨ�ų��ڡ�һ���ڿ���·�������������˿����ڲ���������ⲿ�����Ȩ����
-������ �����
-IOS����©�� ��·�����IJ���ϵͳ���汾�ͣ���Ҫ��������
-����Ȩ�û����Թ����豸 Ȩ��
-CDPЭ�������Ϣ��й¶ ˼���豸֮����˽⡣�������رգ�
//////////////////////////////////////////////////����ϵͳ���ٵ���в
1��Windowsϵͳ
-δ��ʱ��װ����
-��������Ҫ�ķ���
-����Ա�������ò���ȷ �����ƽ�
-Ĭ�Ϲ���©��
2��Linuxϵͳ
-�˺�����ȫ
-NFS�ļ�ϵͳ©�� ���ƶ�Ӳ�̵�ij��Ŀ¼��������
-��Ϊroot���еij���ȫ Ӧ�ó��ڿͿ��Ƶõ�Ȩ��
//////////////////////////////////////////////////����ϵͳ���ٵ���в
1��Web����
-II5.0�����ļ����������©��
-����©��
2���ʼ�����
-�����ʼ���ɧ��
-�ʼ������еIJ���
3�����ݿ�
-Sa�˺�Ϊ�� 1��������Sa�˺š�2��ΪSa����ǿ׳�����롣
//////////////////////////////////////////////////��ҵ�������ٵ�������в
1������
-���
2��ľ��
-����
-�Ҹ���
3�������ڲ��Ĺ��� 80%������ҵ�ڲ�Ա�� 20%��������
-����ҵ������Ա��
-��ȫ���˽��Ա��
//////////////////////////////////////////////////���簲ȫ�������
1�������豸
2������ϵͳ
3��Ӧ�ó���
4������ǽ+IDS+���緢������ϵ����IDS������ϵͳ
����ϵͳ��ȫ�ӹ̣�
1������������ȫ�����������Ҫ������������ר�ŵĻ�����������Ա��
2���˻���ȫ�����������Ӷȸߡ�
3���ļ�ϵͳ�İ�ȫ����NTFS��FTP32��ȫ��Ȩ���漰�����ļ��к��ļ�����
4��ֹͣ����ķ������ٺڿ����ֿ��ܣ������Ƚ���©�����ߡ�
5��Windows��־ά�������˽����������Ƿ������ܵ�������������������Σ�
1��ȫ�沿�������ϵͳ����������ҵ��ɱ������
2����ʱ���²�����Ͳ�Ʒ
3��Ԥ��Ϊ��
4����ǿ��ѵ����߷�����ʶ��������ҵԱ�����а�ȫ��ѵIDS���ּ��ϵͳ
1����ϵͳ������״̬���м���
2�����ָ��ֹ�����ͼ��������Ϊ���߹������
3����֤ϵͳ��Դ�Ļ����ԡ������ԺͿ�����
4���Ƿ���ǽ�ĺ�������
5���ڶ�����ȫբ��IPS ��Intrusion Prevention System , ���ַ���ϵͳ��
IPS�ij��֣�Ӧ��˵��IDS������һ���·�չ���ƣ�IPS������IDS���Ĺ�������������������Ӧ�Ĺ��ܣ�һ�������й�����Ϊ��������Ӧ�������ж����ӡ����IJ���ʽ����IDS�����������У������Դ����ķ�ʽ���������С�
//////////////////////////////////////////////////���繥�������ַ�
1��ɨ�蹥������ɨ������������Щ����Ͷ˿�
2����ȫ©�������������ݷ���ȱ�ݽ��й���
3���������֡����������������¼�������ƽ�����
4��ľ������
5�������ʼ����������������ľ��
6��DoS���������ܾ�������DDoS�ֲ�ʽ�ܾ�����ɨ�蹥����
1���ڿ�����ר�Ź��߽���ϵͳ�˿�ɨ�裬�ҵ����Ŷ˿ں��������
2������ɨ��
-ping
-Tracert
-Nmap
3���˿�ɨ��
-һ���˿ھ���һ��DZ�ڵ�ͨ��ͨ��
-ɨ�跽��
�ֶ�ɨ��
����ɨ��ɨ��������
SuperScan ɨ���������ŵĶ˿ںͷ���
PortScanner
Xscan
MBSA ���ٷ��ṩ��ϵͳ��ȫ���������ȫ©��������
1������ϵͳ��Ӧ�������������е�Bugs
2����ȫ©������:
-���������
��Ŀ�����ϵͳ�յ��˳��������ܽ��յ�����Ϣ��ʱ���������������
�����û���10���ַ����ڿ�����100���ַ�����90���ַ�ע�뵽�ڴ��С��������������10���ַ�ʱ���������룩
-HttpЭ��©�����ºڿ����������֣�
1���ڿ���Ŀ��ʱ���������û��Ŀ��ֻҪ�������ܲ²��û�������ܻ�û�������Ȩ
-ͨ���������
ʹ��Sniffer���߲���������ͨѶ����ȡ�����̽��
-�����ƽ�
John the Ripper
L0pht Crack 5 ��LC5 ���������ֵ�Լ�����������Ե�½
-���ù���Աʧ��
���簲ȫ�����DZ�����һ��
����û����ر����������Ա�İ�ȫ��ʶľ������
1��������ľ��
�ڶԷ����������д��˿�Ϊ�ڿ��ṩ����
2��������ľ��
-BO��BackOriffice��
-���ӡ��Ҹ��ӡ������˵Ľ��������ʼ���
1�����ݲ������ʼ�
2������ʼ��������ܴ�һ��������ҳ
3������Ⱦ���ʼ�
4�������ʼ�
5��ľ���ʼ�DoS��Denial of Service���ܾ�������
1������ϵͳ��Դ���������ڴ桢���С�CPU��
2������Ŀ������崻�
3����ֹ��Ȩ�û��������ʷ��������������ӡ�û����Ӧ��DoS��������
SYN Flood ��ҪΪTCP���ӷ����ڴ棬�Ӷ�ʹ�������ܲ��ܷ����㹻�ڴ档�������֣����������Σ�SYN����SYN/ACK��,�����е��������֣�ACK�������Ӷ��д��ڵȴ�״̬�������������ȴ���ռ��ȫ�����пռ䣬ϵͳ����60Sϵͳ�Զ�RST����ϵͳ�Ѿ�������
Ping of Death IPӦ�õķֶ�ʹ������ò���װ�䣬�Ӷ�����ϵͳ������
ƫ����+�γ���>65535��ϵͳ�����������������ں�ת���ȡ�
Teardrop �ֶι�����������װ�����ͨ���������ֶ��ص���ʹĿ��ϵͳ���������
Smurf���������� �����Ϲ㲥ͨ�������ģ����������������������㲥��ַ���ʹ�����ƭ�Ե�ICMP ECHO������Щ�����Ŵ����͵��������ĵ�ַ�������������һ̨�������ӦECHO����Ŀ��ϵͳ��������//////////////////////////////////////////////////���簲ȫ��������
1���豸��ȫ����
-·������ȫ����
-��������ȫ����
2������ϵͳ��ȫ����
-Windows��ȫ����
-Linux��ȫ����
3��Ӧ�ó���ȫ����
-Web��ȫ����
-���ݿⰲȫ����//////////////////////////////////////////////////·������ȫ����
���·�����������ͣ�
-ֱ�����뵽ϵͳ�ڲ�����Զ�̿���·����
-Զ�̹���ʹ·��������������Ч�������½�
-�������Э��·����֧�ֵ����÷�ʽ��
TELNET����Զ�̿���Э��
TFTP�����ļ����䣬����UDP����·�������������ļ�
FTP�����ļ����䣬����TCP
HTTP��������ҪԶ�̵�¼��ͨ��IE�����ֱ�ӵ�¼·����
SNMP����Զ�̼��·������Ч�ʸ�
Console������·����ֱ������
Aux����ͨ���绰�ߡ�ISDN����Զ�̲������ٵ���в��
Telnet��ϢΪ���ġ���û�н��м���
HTTP����©��
Console�ڡ����ñʼDZ�ֱ����������
SNMPЭ��ȱʡ���á����������SNMP���ã��ڿͻ�����Ĭ��������·��������������ʩ��
��ʱ����IOS��������·��������ϵͳ
��¼·������Ҫ���ü��ܿ���
����Զ�̵�¼����
-Router(config)#line vty 0 4 ����Զ�̿��ƶ˿�0-4,��5���˿�
-Router(config-line)#login ���ö˿�
-Router(config-line)#password AAA ��������
-Router(config-line)#exec-timeout 10 ��ʱ10���Զ��˳���¼
���ÿ���̨��AUX��¼����
-Router(config)#line console 0
-Router(config-line)#transport input none ֧�ֵ�Э�飬none��ʾ��֧���κ�Э��
-Router(config-line)#password AAA
-Router(config)#line sux 0
-Router(config-line)#transport input none
-Router(config-line)#no exec
Ӧ��ǿ�������
-Router(config)#service password-encryption red5����
-Router(config)#enable secret AAA secret��password���ȼ��ߣ�password����Ч
�رջ���Web������
-Router(config)#no ip http server �رղ���Ҫ�ķ���
����ACL��ֹPing��ؽӿ�
-Router(config)#access-list 101 deny icmp any host 192.168.2.1 echo �ܾ�icmpЭ��ping������ping����ʱ��������Ӧ��
-Router(config)#access-list 101 permit ip any any �������������
-Router(config-if)#ip access-group 101 in
�ر�CDP
-Router(config)#no cdp run �ر�����·����CDPЭ��
-Router(config-if)#no cdp enable ����˿ڣ��رոö˿ڵ�CDPЭ��
��ֹ����Ҫ�ķ���
-Router(config)#no ip domain-lookup ��������
-Router(config)#no ip bootp server ��DHCP
-Router(config)#no snmp-server �����������
-Router(config)#no snmp-server community public RO
-Router(config)#no snmp-server community admin RW//////////////////////////////////////////////////��������ȫ����
��ʱ�����µ�IOS
ʹ�ù������ʿ���ϵͳ
����δʹ�õĶ˿�
�ر�Σ�շ���
����VLAN��ǿ�ڲ����簲ȫ����VLAN�������������������������·�ϸ����˹㲥������˿ڰ���VLAN�ϣ�
��Snifferץ����ֻ��ץ��ͬһ��VLAN��İ���//////////////////////////////////////////////////Windows��ȫ
1���رղ���Ҫ�ķ���
-Remote Registry Service Զ��ע���������Զ����ע�����services.msc
-Messenger ������ʹ����
2���رղ���Ҫ�Ķ˿�
-telnet
-Netbios
-FTP
-Web
3������Ʋ��ԡ������ذ�ȫ����->���ز���->��˵�¼�¼���
���ļ��м��ļ��������->����->��ȫ->��->���
4����Ҫ�ļ���ȫ��š���������Ҫ����ϵͳ�̣��ļ�ϵͳѡ��NTFS��
5����¼ʱ����ʾ�ϴε�¼���������ذ�ȫ����->���ز���->��ȫѡ��->����ʽ��¼������ʾ�ϴ��û�����
���ذ�ȫ����->���ز���->��ȫѡ��->�˻���������ϵͳ����Ա�˻����úڿͲ²�������Ա�˺�
gpupdate /force ǿ�Ƹ��������
6����ֹ���������ӡ�������XPsp3��2003sp2������ȫ
7���ر�Ĭ�Ϲ�������net share �鿴����
net share c$ /delete ɾ������
8���趨�˻�������ֵ�������ذ�ȫ����->�ʻ����ԡ��ɷ�ֹ�����ƽ⡣
//////////////////////////////////////////////////Linux��ȫ//////////////////////////////////////////////////����ǽ���ܼ�ACL
����ǽ��Ҫ���ܣ�
1��ǿ����ȫ���ԡ�������ǽͨ�����������Ͽɵġ��ͷ��Ϲ��������ͨ���ķ�ʽ��ǿ����ȫ����
2����Ч�ļ�¼���ϻ�������о�������ǽ�����������Ա���¼������������ҵ�û��������
3�������û�վ����������ˡ�������ǽ�ڸ���������������ͬʱ����NAT�����������ĸ���ϸ��
4����ȫ���Եļ�顪��������Ϣ�����뾭������ǽ������ǽ�ͳ�Ϊһ����ȫ����NAT����Network Address Translation����������˼�ǡ������ַת������NAT�����ھ������ڲ�������ʹ���ڲ���ַ��
�����ڲ��ڵ�Ҫ���ⲿ�������ͨѶʱ���������أ���������Ϊ���ڣ�����ȷ�����Ժ�ӵ���һ�����������ڲ���ַ�滻�ɹ��õ�ַ��
�Ӷ����ⲿ������internet��������ʹ�ã�NAT����ʹ��̨���������Internet���ӣ���һ���ܺܺõؽ���˹���IP��ַ��ȱ�����⡣����ǽ���ࣺ
1���������ͷ���ǽ��������㣬�����ݱ����м��
2�������ͷ���ǽ����Ӧ�ọ́��ô�������������
3��״̬����ͷ���ǽ��������㣬�������ݰ�״̬�������ͷ���ǽ��
-���ݶ���õĹ��˹������ÿ�����ݰ����Ա�ȷ�����Ƿ���ijһ�������˹���ƥ��
-���˹����Ǹ������ݰ��ı�ͷ��Ϣ���ж����
-û����ȷ�����Ķ�����ֹ�����ͷ���ǽ��
-Ҳ����Ϊ����������
-λ�ڿͻ����������֮�䣬��ȫ�赲�����������
-�������Ӧ�ò��������ɨ�裬�Ը�����Ӧ�ò�Ľ���Ͳ���ʮ����Ч״̬����ͷ���ǽ��
-���ÿһ����Ч���ӵ�״̬����������Щ��Ϣ�����������ݰ��Ƿ��ܹ�ͨ������ǽ -
Loadrunnerʵ�ü���1
2010-07-09 12:53:16
#######################################################regע�ắ��
����¼���ҳ����Ϣʱ
web_reg_find��web_reg_save_param //��reg�ĺ���Ҫ���ڵ�¼���ǰ
web_submit_form()
web_find //����reg�ĺ������ڵ�¼����������ʱ������Ҫ��reb_reg_save_param��������Ҫ����������ǰ�档
######################################################���нű���������ʱ����ִ����ȥ
Action()
{
lr_continue_on_error(1); lr_continue_on_error(1)��lr_continue_on_error(0)֮�����ִ�г���ʱ��ֹͣ������ִ���������䡣
web_link("test", lr_continue_on_error(1)�൱��Run-time Setting�� continue on error ��
"test=www.baidu.com",
LAST);
lr_continue_on_error(0);
lr_output_message("finished linking");
return 0;
}
#######################################################
View->Antimated run ��̬����
ѡȡ�ű��к�����F1��ʾ�ú����İ�����
#######################################################ѡ��java VuserЭ��
Eclipse SDKpackage com.lr.test; ����
public class HelloWorld{
public static void main(String[] args){
System.out.println("Hello World");
}
}import lrapi.lr;
import com.lr.test.*; �����
public class Actions
{public int init() throws Throwable {
return 0;
}//end of init
public int action() throws Throwable {
HellpWorld.main((String[])null);
System.out.println("������ֱ��дjava���");
return 0;
}//end of action
public int end() throws Throwable {
return 0;
}//end of end
}
#######################################################����dll
1�����ʺ�¼�ƹ��ܵ��ҵ��
2������C++������ҵ��ϵͳ
lr_load_dll("D:\\test\\dlltest.dll"); ���dll�ļ��ڽű����ļ����У���ֱ��дlr_load_dll("dlltest.dll");
˫������ת���ַ�
vuser_init()
{ lr_load_dll("D:\\test\\dlltest.dll");
return 0;
}
int sum; ����������Action���棨��������LoadRunner�ᱨ����
Action
{ sum=add(100,200);
}#######################################################¼��SQL�ű���ODBCЭ��
int ѡ���ѯ������ \\Mcrosoft SQL Server\80\Tools\inn\isqlw.exe
��¼
Action �������ݿ�
��ѯ������
#######################################################
-
������Ա��Ҫ������Щ����
2010-07-08 12:25:43
��������
C/C++
java
C#
VB
Delphi
Phthon��Shell��PHP���ݿ�
MS SQL
Oracle
My SQL
DB2�����������
Sniffer Pro
Omnipeek��Solarwinds�������������ϵͳ
IRIS�����Զ���
QTP
WinRunner
Robot
RFT
Selenium
Watir
TestComplete��Silktest
Webking��MaxQ���ܲ���
Loadrunner
Jmeter
Robot
Web Application Load Simulator��RPT
Application Center Test��apacheAB��Webking��TPTest���Թ���
QC/TD
bugzilla
bugfree
jira
mantis
TestLink
Clearquest
RQM��Ԫ����
Junit
C++ test
jtest
Quantify
Purify -
IP��ͷ�ṹ���
2010-07-07 09:27:06
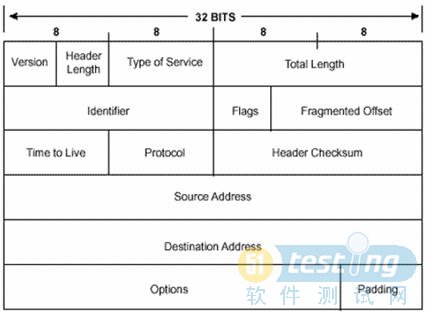
�汾�ţ�Version��������4���ء���ʶĿǰ���õ�IPЭ��İ汾�š�һ���ֵΪ0100��IPv4����0110��IPv6��
IP��ͷ���ȣ�Header Length��������4���ء�����ֶε�������Ϊ������IP��ͷ�ij��ȣ���Ϊ��IP��ͷ���б䳤�Ŀ�ѡ���֡��ò���ռ4��bitλ����λΪ32bit��4���ֽڣ�����������ֵ= IPͷ�����ȣ���λΪbit��/(8*4)����ˣ�һ��IP��ͷ�ij����Ϊ��1111������15*4��60���ֽڡ�IP��ͷ��С����Ϊ20�ֽڡ�
�������ͣ�Type of Service��������8���ء�8λ ��λ�����¶��� PPP DTRC0
PPP������������ȼ���ȡֵԽ������Խ��Ҫ
000 ��ͨ (Routine)
001 ���ȵ� (Priority)
010 �����ķ��� (Immediate)
011 ����ʽ�� (Flash)
100 �����绹����ʽ�� (Flash Override)
101 CRI/TIC/ECP(�Ҳ�������ʵķ���)
110 ������� (Internetwork Control)
111 ������� (Network Control)
D ʱ��: 0:��ͨ 1:�ӳپ���С
T ������: 0:��ͨ 1:����������
R �ɿ���: 0:��ͨ 1:�ɿ��Ծ�����
M ����ɱ�: 0:��ͨ 1:�ɱ�����С
0 ���һλ���������㶨Ϊ0
IP���ܳ���Total Length��������16���ء� ���ֽ�Ϊ��λ�����IP���ij��� (����ͷ��������)������IP�����65535�ֽڡ�
��ʶ����Identifier��:����16���ء����ֶκ�Flags��Fragment Offest�ֶ�����ʹ�ã��Խϴ���ϲ����ݰ����зֶΣ�fragment��������·������һ������ֺ����в�ֿ���С���������ͬ��ֵ���Ա�Ŀ�Ķ��豸�ܹ������ĸ������ڱ���ֿ��İ���һ���֡�
��ǣ�Flags��������3���ء����ֶε�һλ��ʹ�á��ڶ�λ��DF��Don't Fragment��λ��DFλ��Ϊ1ʱ����·�������ܶԸ��ϲ����ݰ��ֶΡ����һ���ϲ����ݰ����ڲ��ֶε�����½���ת������·�����ᶪ�����ϲ����ݰ�������һ��������Ϣ������λ��MF��More Fragments��λ����·������һ���ϲ����ݰ��ֶΣ���·�������ڳ������һ���ֶε�IP���İ�ͷ�н�MFλ��Ϊ1��
Ƭƫ�ƣ�Fragment Offset��������13���ء���ʾ��IP���ڸ����Ƭ����λ�ã����ն˿�������װ��ԭIP����
����ʱ�䣨TTL��������8���ء���IP�����д���ʱ���Ȼ�Ը��ֶθ���ij���ض���ֵ����IP������ÿһ����;��·������ʱ��ÿ����;��·�����ὫIP����TTLֵ����1�����TTL����Ϊ0�����IP���ᱻ����������ֶο��Է�ֹ����·�ɻ�·������IP���������в�ͣ��ת����
Э�飨Protocol��������8���ء���ʶ���ϲ���ʹ�õ�Э�顣
�����DZȽϳ��õ�Э��ţ�
1 ICMP
2 IGMP
6 TCP
17 UDP
88 IGRP
89 OSPF
ͷ��У�飨Header Checksum��������16λ��������IPͷ������ȷ�Լ�⣬�����������ݲ��֡� ��Ϊÿ��·����Ҫ�ı�TTL��ֵ,����·������Ϊÿ��ͨ�������ݰ����¼������ֵ��
��Դ��Ŀ���ַ��Source and Destination Addresses�����������ضζ���32���ء���ʶ�����IP������Դ��Ŀ���ַ��Ҫע�����ʹ��NAT��������������Ĺ����У���������ַ����ı䡣
���ˣ�IP��ͷ������20�ֽ��ѽ�����ϣ��˺����ڿ�ѡ����DZ���IJ��֡�
��ѡ�Options��������һ���ɱ䳤���ֶΡ����ֶ����ڿ�ѡ���Ҫ���ڲ��ԣ�����Դ�豸������Ҫ��д����ѡ��Ŀ�����������ݣ�
��ɢԴ·�ɣ�Loose source routing��������һ����·�����ӿڵ�IP��ַ��IP������������ЩIP��ַ���ͣ�������������̵�����IP��ַ֮���������·������
�ϸ�Դ·�ɣ�Strict source routing��������һ����·�����ӿڵ�IP��ַ��IP������������ЩIP��ַ���ͣ������һ������IP��ַ�������ʾ��������
·�ɼ�¼��Record route������IP���뿪ÿ��·������ʱ���¼·�����ij�վ�ӿڵ�IP��ַ��
ʱ�����Timestamps������IP���뿪ÿ��·������ʱ���¼ʱ�䡣
��䣨Padding������ΪIP��ͷ���ȣ�Header Length�����ֵĵ�λΪ32bit������IP��ͷ�ij��ȱ���Ϊ32bit������������ˣ��ڿ�ѡ����棬IPЭ���������ɸ�0���Դﵽ32bit���������� -
�������ѧϰ�ʼ�
2010-07-07 09:03:55
/////////////////////////////////////////////////////�������뻥����
����������˾֮�����ӡ���ҵ˽��������֮�����ˣ�
Internet������TCP/IP���в����������ܺڿ���
/////////////////////////////////////////////////////�������
���ʱ�����֯��ISO��
���ӵ�������ʦЭ�ᣨIEEE�� 802.3
�������ұ��֣�ANSI��
���ӹ�ҵЭ�ᣨEIA/TIA��
���ʵ������ˣ�ITU��
INTERNET�ж�ίԱ�ᣨIAB��
/////////////////////////////////////////////////////�߲�OSI
Application All Ӧ�ò� �����ʼ�SMTP��HTTP
Presentation People ��ʾ�� ͳһ���� ��ASCII���� ��ͬϵͳ�以��
Session Seem �Ի��� �ͻ��������������
Tranport To ����� ���䱣�� TCP
Network Need ����� ��ַ����������·�� ���㽻�����������繦�ܣ�
DataLink Data ������·�� ֡�����㽻����
Physical Processing ������ 1010
/////////////////////////////////////////////////////������
Ŀ�ģ���֤ԭʼ���ݱ�������������
����ȷ��������ý����صĵ������ԡ���е���ԡ��������Լ������������ bps bits/sec
UTP/STP ������/���� ˫����
5��/��5��/6��˫���� 100M/1000M/10000M
RJ45�ӿ� ˮ��ͷ ǧ��8������
ֱͨ�ߣ�����һ����һ�����߽�T568B�������뽻����
�����ߣ�T568B T568A �������뽻������������������ģ���ˣ����ֲ����䣬�����������4-5km��50 or 62.5/125
��ģ���ˣ�һ�ֲ����䣬����С���������40km��8.3-10/125�������磺
802.11ģ����ƽ������Modem ת����
���ִ���ĵ��Ʒ�����������ƣ�PCM��
PCM�Ķ������ƣ�����24·PCM-���T1��1.544Mb/s��
ŷ��30·PCM-���E1��2.048Mb/s��
�ҹ�����E1������Ϊ ����cisco��T1��
/////////////////////////////////////////////////////������·��
�����Ӳ���ɣ�����·�� LLC��ý����ʲ�MACý����ʲ�MAC��������ͷ�ռ���ŵ����⣨��Ҫ�������ݣ������Ƿ���ã�
Ŀ�ģ���ɷ��ͷ�ռ���ŵ�����
�����ϲ㴫���������ݷ�װ��֡���з���
ʵ�ֺ�ά��MACЭ��
���ز�����ռ���ŵ�������
����-Contention ��̫�����õ�
����-Token Passing ���ƻ���
��ѯ-Polling ��һ̨����������ŵ�
SNMP ���������Э�飬���ܹ���վ��������������ʱ��ʹ����ѯMACѰַ���㲥Ѱַ
��������������������·�� LLC���Ѹ߲��������ô��ɻ���
Ŀ��:��֤֡���͵���������������
���������ͷ�LLC���������
�ṩ��߲㣨����㣩�Ľӿ�
�������
�������ƣ���֤�����������豸֮��֡�����䣨��ֹ�����洦��IEEE802.3������̫��
ý���ȡ��ʽ������
���÷�ʽ��CSMA/CD
��ַ�ʽ��1
���룺����˹�ر��� �ߵ�ѹ1���͵�ѹ0��̫��ԭ��CSMA/CD �ز�������·����/��ͻ���
��������༶��7����ͣ���鿴֡��ȥ����Խ���ӳ�Խ��
/////////////////////////////////////////////////////�����
Ŀ�ģ������������ݴ���
����Ѱ�������ַ-����Ѱַ
�����������ݴ���-��������
·��ѡ���㷨-·��ѡ��
MAC��ַ�����ֲ㣬�㲥 ���Բ���·�ɣ���·�ɵ��ǵ������ֲ㡣086-029-8824-3027�绰����·������
�㲥 �����е�����ַ�ǹ㲥��ַ
�鲥tracert IP/���� ��·��
linux�²鿴IP ifconfig
netsend "��Ҫ��CS" 192.168.255.255 ��192.168���ι㲥255.255.255.255 �������㲥
����š���255 ��һ�������㲥
ping 127����ֵ����ȥȫ��ȫ1�� ���ص�ַ ���÷�Χ ���� ����
0 1-126 A W X.Y.Z
10 128-191 B W.X Y.Z
110 192-223 C W.X.Y Z
1110 224-239 D �鲥
11110 240-247 E ����·��+NAT��ֱ���ľ������İ�����������ַ����
���������û������������ַ��0��255��127
������ַ��
����ֵ ʵ�ʿ���ֵ
A 10.0.0.0-10.255.255.255 10.0.0.1-10.255.255.254
B 172.16.0.0-172.31.255.255 172.16.0.1-172.31.255.254
C 192.168.0.0-192.168.255.255 192.168.0.1-192.168.255.254��������
192.168.0.0 �����������룬�������ַ��Ϊ�����ַ����0,1���λ��ֵ�һ�����Ρ�
192.168.1.0
255.255.0.0192.168.0.1
255.255.255.224
11100000
000 00000 - 000 11111 0-31 192.168.0.0-31 ���õ�ַ192.168.0.1-30 ��С�������
001 00000 - 001 11111 32-63 ��㲥��ַ
010 00000 - 010 11111
����
route add 192.168.0.32 255.255.255.224·�ɻ���
·�ɱ���
����Ŀ�� ���� �߶�
192.168.0.1/24 10.0.0.2 1
172.16.0.1/10 10.0.0.1 1
�߶ȣ�����������һ��·����Ϊ1����ֱ��·��0�����뽻����������·�������������䣺
��·����cuicurt switch һ��ͨ·���������������ݴ������
��Ϣ����message switch ���ݱ��ֳɶ����Ϣ��ÿ����Ϣ����ѡ��·��
���齻��package switch ���ݱ��ֳɶ���飬ÿ���������ѡ��·��
IPЭ����Ƿ��齻��Э������·��ѡ��routing
·�ɷ��֣�
����ʸ����distance vector
״̬���ӷ�link state
·��ѡ��
��̬ѡ��-��Ϊ����·�ɱ�
��̬ѡ��-hop��tick ·����֮�以��ѧϰ·�ɱ�/////////////////////////////////////////////////////�Ự��
Ŀ�ģ�����ַ���Ͳ��ṩ�������ַ
���Ի�����
�Ự����
�Ի�����
����ͨ�� ����ȥ�Ͳ����������磺�㲥
��˫��ͨ�� ��ͬһʱ��ֻ�ܷ�������
ȫ˫��ͨ���Ự������
��������
���ݴ���
�ͷ�����/////////////////////////////////////////////////////��ʾ��
Ŀ�ģ�������ת���ɼ����Ӧ�ó���������ĸ�ʽ
������
����
���룺
-ASCII/////////////////////////////////////////////////////Ӧ�ò�
Ŀ�ģ�����������Ӧ��
��������������
����Ӧ�ó���
�������ͨ��
��������/////////////////////////////////////////////////////������
TCP/IP
IPX/SPX Internet���齻��/˳����齻��,Novell��˾��ͨ��Э�鼯
Apple Talk ƻ�����Ե���Э��
NetBIOS NetBIOS�����������46�ַ���
NetBEUI ������ͨ�źܿ죬������·��
SNA sna������IBMС�ͻ�
DECent/////////////////////////////////////////////////////TCP/IP��
TCP/IPЭ��ջ
IP���ݱ���IPЭ�����ϲ㣨��Ҫ��TCP�㣩�ṩͳһ��IP���ݱ�ICMP
ping www.baidu.com
tracert www.baidu.com ����·��TCP �������Э��
-�����Э�飬���ϲ�Э��������ⳤ�ȵı��ģ����ṩ�������ӵĴ������
-TCP���������������ֳɶΣ�Ȼ����Щ����IP����IPΪ�����ӵģ�����TCP����Ϊÿ�����ṩ˳��ͬ�����������ƣ����ڼ�����Ĵ����ٶȲ�ͬ���ڴ�������д������������ٶȡ�
IP���֣�����192.168.0.1:80 IP��ַ+�˿ں�
�˿ںŷ�Χ��
0-255 ����Ӧ�� 1-1023 ������֪
255-1023 ��ҵ��˾ >=1024 �漴�˿�
1024-65535 û������
�����˿ںţ�
Ӧ��Э�� �˿ں� ����Э��
HTTP 80 TCP
FTP 21 TCP
TELNET 23 TCP
SMTP 25 TCP
DNS 53 TCP/UDP
TFTP 69 UDP
SNMP 161 UDP
RIP 520 UDP
NTP ��ʱ��ͬ��Э��QQ 4000
Զ������ 3389UDP137��138 �������ھ�����ʾ�����
TCP139��445 \\IPnetstat �鿴TCPЭ��˿� netstat -n��ʾ����� netstat -an��ʾ���ж˿�����
��������
�������� send SYN ----> SYN received �������� ������������ʱ��fin-wait->time wait->close
(seq=100 ctl=SYN)
SYN received <---- Send SYN ACK �������� ����ȷ��
(seq=300 ack=101 ctl=syn,ack)
�������ݻ���ȷ�� Established ----> ���ӳɹ�
(seq=101 ack=301 ctl=ack)DoS�������ܾ��������ظ��������֣�ֻ���� SYN ��SYN ACK ��
UDP����TCP���û���������֣�û��У�飬ʧȥ������ȡ�ٶ�
nslookup ������������
/////////////////////////////////////////////////////ARP��ַ����Э��
arp -a arp��
arpЭ�飺����Arp�㲥��Ŀ���ַ10.1.1.254����һ��IP��ַMAC��ַ������������㲥ʽѰַ���Զ���
���㽻���豸����������������ֻ��MAC��ַ����������IP����������ͨ�ű���֪������MAC��ַ��
ȫ����ARP����replay������Ӧ������Լ�MAC��ַ����������
IPV6ȡ��ARPЭ�飬ת�á��ھ�Э�顱��
ARP������������������MACΪ22-22-22-22-22-22���õ�����IP 192.168.1.1��MAC��ַ 11-11-11-11-11-11������ȫ���㲥˵�Լ������غ���������ѧ�������ص�ַΪ192.168.1.1��MAC��ַΪ22-22-22-22-22-22��
������IJ������ڲ������ϰ�װ��С���������������������������������ߵ��Dz�������
��ARP�����ɾ�̬�arp -s 192.168.1.1 11-11-11-11-11-11
Win7 ARP�� netsh ii show in
netsh -c "ii" add neighbors 11 "IP��ַ" "mac��ַ"˫����ƭ����ƭ·��������·�����ϰ�IP��MAC��ַ��
/////////////////////////////////////////////////////DNS����������
������IP�����
DNS Server
nslookup ������������
-
Oracleѧϰ�ʼ�
2010-06-07 10:47:48
����Oracle����
����sqlplusw��sqlplus��Oracle
sqlplus worksheet �����õ�
Enterprise Manager Console ͼ�β���###########################################################Զ������
pl/sql developer����Զ�����ݿ�
��ʼ-�����г���-��Oracle-OraHome92-��Configuration and Migration Tools-��Net Manager
��һ������� ����-����������
�ٵ��������ɫ�ġ�+����Net��������д����Ҫ��ʾ���������磨orcl_ip��,Ȼ����һ��
ѡ TCP/IP��InternetЭ�飩 ��һ��
�������� Զ�����ݿ��IP��ַ���˿�Ĭ�ϣ�Զ��oracle�Ķ˿ڣ� ��һ��
��������windows����������unix����echo $ORACLE_HOME���ҵĻ���orcl ��һ��
���ԣ������û�������ԣ�����ɹ���ʾ����
scott tiger###########################################################��¼���ݿ�
conn �û���/����@��������� as sysdba|sysoper
connect scott/tiger@oracle
conn scott/tiger@oracle Զ�̷��ʣ�������oracle
conn scott/tiger ����
conn system as sysdba
conn system/123456 as sysdbashow user
disc �Ͽ�����
passw ������###########################################################�ļ���������
�ļ��������
@ d:\a.sql �� start d:\a.sql ִ��.sql���SQL����
edit d:\a.sql ��дa.sql
spool d:\b.sql ���� spool off ��sql*plus��Ļ�ϵ����ݡ��������ָ���ļ���###########################################################��ʾ�����û�������
��ʾ�����û�������
show linesize
set linesize 90 ÿ����ʾ90���ַ�
set pagesize 5 ÿ5�з�ҳ
###########################################################Ȩ��
�����û�����ҪsystemȨ�ޣ�
create user �û��� identified by my123; �����û�ʱ���������ֿ�ͷ
password �û���; ���û����룬�ı���������dba��ӵ��alter userȨ��
alter user �û��� identified by ����
drop user �û��� �Լ�����ɾ���Լ�
drop user �û��� cascade ��ɾ���û�ʱ������û��Ѿ������˱�������һ��ɾ��
�մ������û���û���κ�Ȩ�ޣ�����¼Ȩ��û�С�
Ȩ��Ϊ��ϵͳȨ��140���������Ȩ��25����select��insert��update��delete��all��
ϵͳȨ�ޣ�create session�д�Ȩ�ſɵ�¼�����ݿ�
��ɫ������һϵ��Ȩ�� connect��dba��resource�����κ�һ�����ռ佨����
grant connect to �û��� �߱���¼���ݿ�Ȩ��
grant resource to �û��� �߱�����Ȩ��
grant select on emp to �û��� �Ѷ�emp����selectȨ�����û���
��scott�û�ִ��grant select on emp to �û������Ѷ�scott��emp����selectȨ�����û�������¼�û���ִ��select * from scott.emp;
grant all on emp to �û���; ��emp������������Ȩ�����û���revoke select on emp from �û���; �ջ�Ȩ��
grant select on emp to �û��� with grant option ����Ȩ��+with grant option�ɽ���õ�Ȩ���ٴηָ������û�
grant connect to �û��� with admin option ϵͳȨ��+with admin option�ɽ���õ�Ȩ���ٴηָ������û�ע������û�A��Ȩ�ָ�B��B��Ȩ����C����B��Ȩ���ջغ�CȨ��Ҳ���Զ����ջء�����ģʽ
########################################################### profile�ļ�ʵ�ֹ����û�����
create profile �ļ������� limit failed_login_attempts 3 password_lock_time 2; ��������3�Σ�����2��
alter user �û��� profile �ļ�������; ���û�����
alter user �û��� account unlock; ����create profile �ļ��� limit password_life_time 10 password_grace_time 2; ÿ10�������룬������2��
create profile �ļ��� limit password_life_time 10 password_grace_time 2 password_reuse_time 5; ָ�����������ʱ��5��������drop profile �ļ��� ɾ��profile�ļ�,��profileԼ�����û����ͷ�
###########################################################����������������
����ĸ��ͷ
����30�ַ�
������oracle������
A-Z,a-z,0-9,$,#��
�ַ���:
char ���2000�ַ�
���� char(10) 'С��'ǰ4���ַ���'С��'������6���ո�ȫ����ѯ�ٶȿ죬��������֤��ȫ�ַ��Ƚϡ�
varchar2(20) �䳤 ���4000�ַ�
����varchar2(10) 'С��' ֻ����4���ַ�����ʡ�ռ䣬��ѯ�ٶ�����һ��һ���ַ��Ƚϡ�
clob(character large objient) �ַ��ʹ���� ���4G
������:
number 10-38�η�-10+38�η�
number(5,2) ��ʾһ��С����5λ��Ч����2λС������Χ-999.99-999.99
number(5) ��ʾһ��5λ��������Χ-99999-99999
���ڣ�
date ������
datestamp ���뼶��������Ŀ
ͼƬ��
blob ���������ݣ��ɴ��ͼƬ������ 4G �� һ�㱣���Ըߵ�ͼƬ���������Է������ݿ⣬��ֻͨ���ͼƬ·��
###########################################################��������������
ѧ����
create table student(
xh number(4),--ѧ��
xm varchar2(20),--����
sex char(2),--�Ա�
birthday date,--��������
sal number(7,2) --��ѧ��
);
desc student --�鿴���ṹ
alter table student add (classid number(2)); --�����ֶ�
alter table student modify (xm varchar2(30)); --���ֶ�
alter table student drop column sal; --ɾ���ֶ� ��һ�㲻�ã�
rename student to stu; --�ı���
drop table student; ɾ����
###########################################################�����������ݲ���
insert into student values ('A001','����','��','01-5��-05',10); oracleĬ�����ڸ�ʽ'DD-MON-YY'
alter session set nls_date_format='yyyy-mm-dd'; --��Ĭ�����ڸ�ʽ
insert into student(xh,xm,sex) values('A003','John','Ů'); --�����ֶ�
insert into student(xh,xm,sex) select * from student; --���������������ݣ��ٶ�2��N�η���
insert into student(xh,xm,sex,birthday) values(''A003','John','Ů',null); --���������
select * from student where birthday is null/not null; --��ѯ������
update student set sex='Ů',birthday='1997-12-11' where xh='A001'; --������
delete from student; ɾ�����м�¼�����ṹ���ڣ�д��־�����Իָ���ɾ���ٶ���
savepoint aa; �����
roolback to aa; --�ع�
drop table student; --ɾ�����Ľṹ������
delete from student where xh='A001'; --ɾ��һ����¼
truncate table student; --ɾ���������м�¼�����ṹ���ڣ���д��־�����һ�ɾ����¼��ɾ���ٶȿ�
###########################################################��������select����
set timing on; ��ʾsql���ִ�����ʱ��
��δ���nullֵ
select sal*13+nvl(comm,0)*13 "�깤��",ename,comm from emp; --nvl(comm,0) ���nvlΪ�գ�����0���㣬�����Ϊ�վ��ñ���ֵ��
���ڴ���1982-1-1Ҫд�� date>'1-1��-1982' ����д�� date>'1982-1-1' ��ΪOracleĬ�ϵ����ڸ�ʽ
like % _ 0������ַ���1���ַ�
is null / is not null
select * from emp by deptno,sal desc; --desc����
select ename,(sal+nvl(comm,0))*12 as "��н" from emp order by "��н"
###########################################################Oracle���Ӳ�ѯ���Ӳ�ѯ
max,min,avg,sum,count���麯��
select deptno,avg(sal) from emp group by deptno having avg(sal)<2000;
1�����麯��ֻ�ܳ�����ѡ���У���having��order by�Ӿ��У�
2�������select�����ͬʱ����group by,having,order by˳��Ϊgroup by,having,order by��
3��ѡ������������С�����ʽ�����麯��������Щ�кͱ���ʽ������һ��������group by�Ӿ��С�
�����ѯ����������Ϊ������-1���ѿ�������
between 1 and 2��
�����ӣ�
select worker.ename,boss.ename from emp worker,emp boss where worker.ename=FROD;
�Ӳ�ѯ��
�����ų�����ѯ���ݵ����������Ӳ�ѯ����ߣ�SQL���ɨ�� ��->�ҡ�
in
select * from emp where sal> all(select sal from emp where deptno=30);
select * from emp where sal> (select max(sal) from emp where deptno=30); --Ч�ʸ�
select * from emp where sal> any(select sal from emp where deptno=30);
select * from emp where sal> (select min(sal) from emp where deptno=30); --Ч�ʸ�
�����Ӳ�ѯ��
select * from emp where (deptno,job)=(select deptno,job from emp where ename="SMITH";
���ܸ���ȡ������
###########################################################Oracle��ҳ ���ַ�ʽ
1������rowid����
select * from emp where rowid in (select rid from (select rownum rn,rid
from(select rowid rid,cid from emp drder by cid desc) where rownum<=10) where rn>=6 order by cid desc;
ִ��ʱ��0.03��
2����������������
select * from (select a1.*,row_number() over (order by cid desc) rk from emp a1) where rk<10000 and rk>9980;
ִ��ʱ��1.01��
3����rownum����
select a1.*,rownum rn from (select * from emp) a1 where rownum<=10;
select * from (select a1.*,rownum rn from (select * from emp order by cid desc) a1 where rownum<=10) where rn>=6; ���ַ�����ѯ�ٶȿ�
������ʾ��ֻ����select * from emp��
ִ��ʱ��0.1��
emp������cid�ؼ��ֶΣ�ȡ��6-��10��¼��7������¼��###########################################################Oracle�ϲ���ѯ
M union N where �ϲ����� --M��NΪ��
M union all N where �ϲ�
M minus N M��N
M intersect N ȡM��N����
###########################################################Oracle �������ݿ�
Configuration and Migration Tools����Database Configuration Assistant
Data Warehouse ���ݲֿ�
General Purpose ��ͨ��;
New Database
Transaction Processing ���ﴦ��
###########################################################Oracle �������
create table myemp (id,ename,sal) as select empno,ename,sql from emp; --�ò�ѯ�������һ���±�
insert into myemp (Myid,myname,mydept) select empno,ename,deptno from emp where deptno=10; --������������
update emp set (job,sal,comm) = (select job,sal,comm from emp where ename='SMITH' where ename='SCOTT';commit; --�ύ����ִ�к�ȷ������ı仯����������ɾ������㡢�ͷ���
������Ҫ������
1������� savepoint a
2��ȡ���������� rollback to a
3��ȡ��ȫ������ rollback
-
SQL����ѧϰ�ʼ�
2010-06-07 10:39:26
���ݶ���
create
alter
droptable��view��index��procedure��trigger��schema��domain
���ݲ���
select
insert
delete
update���ݿ���
grant
deny
revoke�������
commit
rollback
set transactionע��������SQL�����M,NΪ�� A,B,CΪ��Ŀ
select distinct A from M where A>100 or (A<50 and A>30) ����ĿA����
select * from M where A in ('namea','nameb') ȡ��A=namea,A=nameb������
select * from M where A between '1982' and '1992' ȡ��1982-1992������
select * from M where A like 'a_z' 'a%' '%a' '%a%' _:һ���ַ� %:����ַ�
select * from M order by A asc, B desc asc���� desc����select sum(A),B from M group by A having sum(A)>100 �����select��ֻ�к�����������Ҫgroup by�Ӿ�//avg,count,max,min,sum
select count(distinct A),B from M group by B�ڲ�����
select * from M,N where M.A=N.A
�ⲿ����
where A1.A=A2.A(+) �±����ݶ�Ҫ
select concat(A,B) from M ��A,B�����ַ�����������
select substr(A,3,4) from M ץ��A�е�3���ַ���ʼ���ץ4���ַ�
select trim(' sample ') 'sample' �Ƴ�sample�����ַ�
select ltrim(' sample ') 'sample '
select rtrim(' sample ') ' sample'������
create table M (SID integer Unique,First_name char(50) not null,Last_name char(50),Birth_date date)
create table M (SID integer Unique)
create table M (SID integer Check (SID>0))
create table M (SID integer��Primary Key(SID)) //MySQL
create table M (SID integer Primary Key) //Oracle,SQLServer
alter table M Add Primary Key (SID) //������ȷ��������λnot null����
not null
unique �����������ظ�ֵ
check ��λ�����ݷ���ijЩ���� ��δ����MySQL��create view ��ͼ�� as select * from M ������ͼ
create index ������ on M(A,B) Ϊ��ĿA��B��������alter table M add C char(50) ������ĿC
alter table M change A C char(50) ����ĿAΪC
alter table M modify C char(30) ����ĿC
alter table M drop C ɾ����ĿCdrop table M ɾ����
truncate table M ��ձ�insert into M (A,B) values ('a','b') ��������
insert into M (A,B) select A,B from N where ���� ��N��A,B���ݲ���M��
update M set A=a,B=2 where ���� ������
delete from M where ���� ɾ������select A from M
union/union all/intersect/minus M,N��A��Ŀ�ϲ������ظ�/�����ظ�/A�ֶν���/M����N��û��
select A from N�Ӳ�ѯ
select * from M exists (select * from N where ����) ����ڲ�ѯ(select * from N where ����)�����ݣ���ִ�����ѯselect * from M
select A ,case A
when ���� then B*2 //����������һ��ֵ��ʽ
when ���� then B*2
����
else B
end
New_B,C from M New_BΪCASE��λ����λ�� -
Oracle init.ora�����������
2010-05-25 15:56:14
��������ժ��: www.51testing.com
db_name = "51test" ����һ�����ݿ���ʶ����Ӧ��CREATE DATABASE �����ָ�����������Ӧ��
instance_name = 51test �����ڶ������ʹ����ͬ������������£�����Ψһ�ر�ʶһ�����ݿ����̡�
INSTANCE_NAME ������Ӧ��SID��������ʵ�����Ƕ���һ̨�����Ϲ����ڴ�ĸ������̵�Ψһ��ʶ��
service_names = 51test ����Ϊ Net8 �������������ʶ��һ������ (��:���ƻ����е�һ���ض����ݿ�) ������ָ��������������÷���û�������� DB_DOMAIN ������
control_files = ("/opt/apps/oracle/oradata/51test/control01.ctl", "/opt/apps/oracle/oradata/51test/control02.ctl", "/opt/apps/oracle/oradata/51test/control03.ctl")
open_cursors = 320��������ٻ��� ָ��һ���Ựһ�ο��Դ��α꣨������������������������� PL/SQL ʹ�õ� PL/SQL �α���ٻ���Ĵ�С���Ա����û��ٴ�ִ�����ʱ���½�����������뽫��ֵ���õ��㹻�ߣ��������ܷ�ֹӦ�ó���ľ����αꡣ
max_enabled_roles = 32
db_block_buffers = 5120�������ٻ�����I/O ���������ٻ����� Oracle ����������ò���������Ӱ��һ�����̵� SGA �ܴ�С��
shard_pool_size = 75497472
large_pool_size = 15728640������--ָ����洢�صķ���ѣ����ɱ����̷߳����� (MTS) �����Ự�ڴ桢��������ִ�е���Ϣ�������Լ����� RMAN���ݺͻָ��Ĵ��� I/O ��������
java_pool_size = 65536 �������ֽ�Ϊ��λ��ָ�� Java �洢�صĴ�С�������ڴ洢 Java �ķ������ඨ���ڹ����ڴ��еı�ʾ�����Լ��ڵ��ý���ʱ��ֲ�� Java �Ự�ռ�� Java ����
log_checkpoint_interval = 10000 ����ָ���ڳ��ּ���֮ǰ������д��������־�ļ��е� OS �飨���������ݿ�飩�����������۸�ֵ��Σ����л���־ʱ������ּ��㡣�ϵ͵�ֵ�����������ָ̻������ʱ�䣬�����ܵ��´��̲���������
log_checkpoint_timeout = 1800 ����ָ������һ��������ֵ����ʱ������������������ʱ��ֵָ��Ϊ 0����������ʱ��Ϊ�����ļ��㡣�ϵ͵�ֵ�����������ָ̻���ʱ�䣬�����ܵ��´��̲�������
processes = 220
log_buffer = 8388608�������ֽ�Ϊ��λ��ָ���� LGWR ��������־��Ŀд��������־�ļ�֮ǰ�����ڻ�����Щ��Ŀ���ڴ�����������Ŀ���������ݿ���������ĵ�һ�ݼ�¼�������ֵ����65536�����ܼ���������־ �ļ� I/O���ر������г�ʱ���������������������ϵͳ�� **���ֵΪ 500K �� 128K * CPU_COUNT������֮��ȡ�ϴ���
oracle_trace_enable = true ��������һ��Ĭ�ϵ� Oracle Trace ���ϣ�ֱ����ֵ�ٴ�����Ϊ NULL��
sql_trace=false ������Щ��Ϣ�Ը������ܺ����á�����ʹ�� SQL �����豸������ϵͳ������ֻӦ����Ҫ�Ż���Ϣ�������ʹ�� TRUE��
timed_statistics=true �����ռ�����ϵͳ�ļ�ʱ��Ϣ����Щ��Ϣ�ɱ������Ż����ݿ�� SQL
������䡣Ҫ��ֹ��Ӳ���ϵͳ����ʱ�������Ŀ������뽫��ֵ����Ϊ�㡣 ����ֵ����Ϊ TRUE ���ڲ鿴��ʱ������Ľ���Ҳ�����á�
background_dump_dest = /opt/apps/oracle/admin/51test/bdump ����ָ���� Oracle ����������Ϊ��̨���̣�LGWR��DBW n �ȵȣ�д������ļ���·������Ŀ¼����̣������������¼����Ҫ�¼�����Ϣ�����ݿ�Ԥ���ļ���λ�á�
core_dump_dest = /opt/apps/oracle/admin/51test/cdump ����ָ������ת��λ�õ�Ŀ¼�������� UNIX����
resource_manager_plan = system_plan �������ָ����ֵ����Դ������������ƻ������̵��������� ���Ӽƻ���ָ���ʹ�����飩�������ָ������Դ�������������ã���ʹ�� ALTER SYSTEM ����������á�
user_dump_dest = /opt/apps/oracle/admin/51test/udump ����Ϊ����������һ���û���������������д����Ը����ļ���Ŀ¼ ָ��·���������磬��Ŀ¼����������: NT ����ϵͳ�ϵ� C:/
����ORACLE/UTRC��UNIX ����ϵͳ�ϵ� /oracle/utrc���� VMS ����ϵͳ�ϵ�DISK$UR3:[ORACLE.UTRC]��
db_block_size = 8192 ����һ�� Oracle ���ݿ��Ĵ�С�����ֽڼƣ�����ֵ�ڴ������ݿ�ʱ���ã����Ҵ˺������ġ� 1024 - 65536 �����ݲ���ϵͳ��������
remote_login_passwordfile = exclusive ����ָ������ϵͳ��һ�� �ļ��Ƿ������Ȩ���û��Ŀ���������Ϊ NONE��Oracle �����Կ����ļ����������Ϊ EXCLUSIVE����ʹ�����ݿ�Ŀ����ļ���ÿ������Ȩ���û�������֤���������Ϊ SHARED��������ݿ⽫���� SYS �� INTERNAL �����ļ��û�
os_authent_prefix = "" ����ʹ���û��IJ���ϵͳ�ʻ����Ϳ�������֤�� �ӵ����������û����ò�����ֵ����û��IJ���ϵͳ�ʻ�������һ��Ҫȥ�� OS
�����ʻ�ǰ����ָ����ֵ��
job_queue_processes = 4 ����ֻ���ڸ��ƻ�������ָ��ÿ�����̵� SNP ��ҵ���н��̵����� (SNP0, ... SNP9, SNPA, ... SNPZ)��Ҫ�Զ����±����ջ�ִ���� DBMS_JOB �����������뽫�ò�������Ϊ 1 ������ֵ�� 0 �� 36
job_queue_interval = 60 ������ҵ���� ֻ���ڸ��ƻ�����������Ϊ��λָ�������̵�ÿ�� SNPn ��̨���̵Ļ���Ƶ�ʡ� 1 �� 3600
distributed_transactions = 10 ����һ�����ݿ�һ�οɲ���ķֲ�ʽ��������������������������������쳣Ƶ�������ٸ�ֵ������ɴ���δ����������
open_links = 4 ����ָ����һ�λỰ��ͬʱ����Զ�����ݿ�����ӵ������������ֵӦ���ڻ�һ�����ö�����ݿ�ĵ��� SQL ��������õ����ݿ���������������ܴ��������ݿ��Ա�ִ�и���䡣
mts_dispatchers = "(protocol=TCP)(mul=ON)(tick=15)(pool=(in=2)(out=2))" ����Ϊ����ʹ�ö��̷߳������� �������������õ��ȳ�������������͡�����Ϊ�ò���ָ������ѡ������ַ���ֵ��һ��ʾ��:"(PROTOCOL=TCP) (DISPATCHERS=3)"��
compatible = "8.1.0" ��������ʹ��һ���µķ��а棬ͬʱ��֤����ǰ�� �����������ԡ�
sort_area_size = 524288 �������ֽ�Ϊ��λ��ָ��������ʹ�õ�����ڴ������������ ���н����أ������ڴ潫�ͷš������ֵ������ߴ��������Ч�ʡ���������˸��ڴ�������ʹ����ʱ���̶Ρ��൱�� 6 �����ݿ���ֵ ����Сֵ�� ������ϵͳȷ����ֵ�����ֵ����
sort_area_retained_size = 131072 �������ֽ�Ϊ��λ��ָ�� ��һ������������Ϻ������û�ȫ���� (UGA) �ڴ��������ֵ�����һ�д�����ռ��б���ȡ���ڴ潫���ͷŻ� UGA���������ͷŸ�����ϵͳ��
-
���������������75������
2010-05-25 15:36:27
��������ժ��www.51testing.com
����1. ���ǵ���Ŀ��ʹ��Դ�������������ô��
����Ӧ���á�VSS��CVS��PVCS��ClearCase��CCC/Harvest��FireFly�����ԡ��ҵ�ѡ����VSS��
����2. ���ǵ���Ŀ��ʹ��ȱ�ݹ���ϵͳ��ô��
����Ӧ���á�ClearQuest̫���ӣ��ҵ��Ƽ���BugZilla��
����3. ���ǵ������黹����Wordд��������ô��
������Ҫ��Wordд����������Test Case����Ӧ����һ��ר�ŵ�ϵͳ��������Test Manager��Ҳ�������Լ�����һ��ASP.NET��С��վ����ҪĿ����Track��Browse��
����4. ���ǵ���Ŀ����û�н���һ���Ż���վ��
����Ҫ��һ���Ż���վ��������Contact Info��Baselined Schedule��News�ȵȡ��Ƽ�Sharepoint Portal Server 2003��ʵ�֣�15���Ӿ㶨������SPS 2003������WSS (Windows Sharepoint Service)��
����5. ���ǵ���Ŀ��������������õĹ���ô��
����Ӧ���þ����õĹ��������������磬Ӧ����VS.NET������Notepad��дC#����Notepadд������ֻ��һ����ҫ����ҲҪ���ǵ����ѣ�����˵�ǡ���������õġ���
����6. ���ǵij���Ա�����ڰ����Ļ�����ô��
������Ҫ������������㼫����Ҫ������Ҫ��֤ÿ���˵Ŀռ����һ�������
����7. ���ǵ�Ա��ÿ���˶���һ���绰ô����Ҫÿ��һ���绰�����ҵ绰����Ǵ����Թ��ܵġ���Ȼ������ôһ�״����Ե绰ϵͳ������С����������ÿ��һ���绰Ҫ�У�ǧ����þ�������վ����������ijijij�绰�������˼��������ǿ��Ǵ������������
����8. ����ÿ���˶�֪����������Ӧ����˭ô��
����Ӧ��֪�����κ�һ��Feature���ٶ�Ӧ����һ��Owner����Ȼ��Owner���Լ���Dispatch�������ˡ�
����9. ������������˵������Ϊ����ô��
����Ҫ��������Ϊ����Never assume anything��
����10. ���ǵ���Ŀ�������е��˶�����һ��ô��
������Ҫ���ҷ���Virtual Team��Ҳ����Dev��������Test���й����ֿ�����ʽ��������һ����������һ�𣬺ô���ò����ˡ�
����11. ���ǵĽ��ȱ��Ƿ�ӳ���¿�����չ�����
����Ӧ�÷�ӳ�����ǣ�Ӧ����Baseline�ķ������������ȱ���ά��һ���ȶ���Schedule����ά��һ�����¸��ġ�Baseline�ķ���ҲӦ������������Spec��Baseline�DZ�����������һ����Ҫ�ֶΡ�
����12. ���ǵĹ�����������ÿ�����Լ������ô��
����Ӧ����ÿ�����Լ����㡣Ҫ���¶��Ϲ��㹤�����������Ǵ������·��ɡ�����������ԭ�������������ڹ̶��ȡ�
����13. ���ǵĿ�����Ա����Ŀһ��ʼ�ͼӰ�ô��
������Ҫ��������Ҫһ��ʼ��ƣ��ս������Ŀһ��ʼ�ͼӰֻ࣬��˵����Ŀ���Ȳ���������Ȼ��һЩ�������������������Ӱ࣬�����ڰ����ķ��롣
����14. ���ǵ���Ŀ�ƻ���Buffer Time�Ǽ���ÿ��С��������ô��
������Ҫ��Buffer Time����ÿ��С������棬���������ľͱ����ĵ���Buffer TimeҪ���εļ���һ��Milestone����checkpointǰ�档
����15. ֵ���ٶһЩʱ�䣬��95%����100%��ֵ�ã��dz�ֵ�á�
�������䵱��Ŀ��������������ʱ��Ҫ��֡�������Ʒ�����ʵ�����
����16. �Ǽ���ȱ��ʱ���Ƿ�д�������ֲ��裿
����Ҫ��������Dev��Test֮��Ĺ�ͨ�ֶΡ�����湵ͨ��Ҫ����ϸ��дRepro StepsҲ��Ҫ��
����17. д�´���ǰ�����֪ȱ�ݽ��ô��Ҫ��ÿ���˵�ȱ�ݲ��ܳ���10����15������������Ƚ���ϵ�bug���ܼ���д�´��롣
����18. ���Ƕ�ȱ�ݵ����ػ��������ȵ�Լ��ô��
���������ж��塣SeverityҪ��1��2��3��Լ���ã�������Data Lost��Sev 1��Function Error��Sev 2�������ϵ���Sev 3��������Լ�����Ը��ݲ�Ʒ������״�ʵ����е�����
����19. ���Ƕ������һ��ȱ������������ô������Ҫ�С�Ҫ��һ����ȷ�ľ��߹��̡���������CCB (Change Control Board)�ĸ��
����20. ���е�ȱ�ݶ����ɵǼǵ������رյ�ô��
����BugӦ����Opener�رա�Dev����˽�Թر�Bug��
����21. ���ǵij���Ա������ϵĴ���ô��
��������������ġ������������֯Code Review����������ʱ������XPҲ��һ��������
����22. ������Ŀ����Team Morale Activityô��
����ÿ���¶�Ҫ��һ�Σ��Է������衢Outing�������������ȵȣ�һ��Ҫ�С���Ҫʣ��ЩǮ��
����23. ������Ŀ�����Լ���Logoô��
����Ҫ���Լ���Logo������Ӧ�����Լ���Codename��
����24. ���ǵ�Ա����ӡ�й�˾Logo��T-Shirtô��
����Ҫ�С�����ǿ�����С���Ȼ��T-ShirtҪ���ĺÿ�һЩ�������80֧������������û�����ξ��������õġ�
����25. �ܾ�������ÿ�²μӴ���Ŀ�����Ҫ�ġ�
����Ҫ��team member���ø߲��ע�����Ŀ��
����26. �����Ǹ�ÿ��Dev��һ����֧ô��
�������ԡ�Branch�Ĺ����Լ�Merge�Ĺ�����̫�������׳�����
����27. ���˳��ڲ�Check-In����ô��
���������ԡ��Դ���Ŀ��˵������������Ӧ��Check-In��
����28. ��Check-In����ʱ����дע����ô��
����Ҫд�ģ�����һ���仰�����硰�����Bug No.225����������ߴ��Σ���Ҳ������������ơ���һ���֡�
����29. ��û���趨ÿ��Check-In��������ޣ�
����Ҫ�ģ�Ҫ��ȷCheck-In Deadline�������Build Break��
����30. �����ܰ�����Դ��һ���ӱ���ɰ�װ�ļ���
����Ҫ�ġ�����ÿ�ձ��루Daily Build���Ļ��������ұ���Ҫ�ܹ������Զ��ġ�
����31. ���ǵ���Ŀ����ÿ�ձ���ô��
������ȻҪ����������������������Ŀ/��Ʒ�����ر��ģ�1. bug management; 2. source control; 3. daily build��
����32. ���ǹ�˾��û�л���һ����Ŀ�����б���
����Ҫ��Risk Inventory�������¸���Ŀ��ʼ��ʱ����ֻ�����Դ�����Risk�ˡ�
����33. ���Խ��Խ��Խ��Խ�á�
�������ʱ���һ�仰���������ܾʹ����������ķ��ա�Ӧ�ô�һ��ʼ���¸ҵĿ������scope management��
����34. �����������еIJ�Ʒ������������ǧ���ʲô�������Լ�Coding��BizTalk��Sharepoint������õ����ӣ�����������Ϊ���������������ߺܶࡣ���߿��Ծ��������ֳɵ�Control֮��ġ����߾�����XML���������Լ�ȥParseһ���ı��ļ���������RegExp���������Լ���ͷ�����ַ������ȵȵȵȡ�����ǡ��������á������֡�
����35. ���ǻ��һ��ʱ���ͣ������ʵ����ô��
����Ҫ�����һ��������һ�Ρ�����ȥ�����Windows����Stevb��������ͣ��һ������ǿ��ȫ��Btw��������������hang������һ����
����36. ���ǵ���Ŀ��ÿ���˶�дDaily Reportô��
����Ҫд������Ӿ��ˣ�д10�仰���ң������Լ�С����˽����Ҹ���ʲô��һ��Ϊ�˹�ͨ��������Լ���Ҫ�����ֺ���һ�죬�Լ��������˼д�ģ���
����37. ���ǵ���Ŀ�����ᷢ��Weekly Reportô��
����Ҫ��Ҳ��Ϊ�˹�ͨ�����ݰ���Ŀǰ���ȣ����ܵķ��գ�����״�������ֹ����Ľ�չ�ȡ�
����38. ������Ŀ���Ƿ�����ÿ��ȫ�忪��һ�Σ�
����Ҫ��һ��Ҫ���ᡣ����Ա���Ὺ�ᣬ��ÿ����ݿ���ʱ�����������Ӧ����4Сʱ������team meeting, spec review meeting, bug triage meeting��ǧ�������ͷдcode��
����39. ������Ŀ��Ļ��顢���۶��м�¼ô��
������ǰ��meeting request��agenda���������˸������ֺͼ�¼��������˸���meeting minutes���ⶼ��effective meeting��Ҫ�㡣���ң�ÿ�����鶼Ҫ�γ�agreements��action items��
����40. ��������֪��������Ŀ���ڸ�ʲôô��
����Ҫ��һЩNewsflash����������֯��Show your team��s value�����������ڵ������棬�������ŵ����ʣ��������ڸ������ش�ABC��Ŀ����ʱ����ȫȻ��֪�����ָо���̫�á�
����41. ͨ��Email����������ʽ��ͨ
����Email�ĺô�����õ�������ҲҪ���������������õķ��������õ绰�͵���˵��Ȼ��Email��ȷ�ϡ�
����42. Ϊ��Ŀ�齨�����Mailing Group
���������AD+Exchange���棬�ͽ�Distribution List�����磬�һὨABC Project Core Team��ABC Project Dev Team��ABC Project All Testers��ABC Project Extended Team�ȵȡ���������Email�����㣬�������ø��յ�email���˶��յ��������յ�����ɧ�š�
����43. ÿ���˶�֪����������ҵ�ȫ�����ĵ�ô��
����Ӧ��ÿ���˶�֪���������֪ʶ������Knowledge Management�������ľ��ǰ��ĵ�����һ�����е�File Share�����õķ�������Sharepoint��
����44. �������������仯ʱ�����ߴ��ԭ����ô��
����Ҫ���ߴ��ԭ��Empower team member���ֶ�֮һ���ṩ�㹻��information������MSFһ��ƪ�ļ���ԭ��֮һ����ȷ��ˣ�tell me why����֮���飬tell me why�˲�����understanding���й�������ϲ�������ƣ�������Ϣ���ƺ��ܹ�����ijһ���ļ����˾��������ݵ��ˡ�����ش���Ȩ����Ȩ�����������Dz�����access information/data���������Dz���������Դ��
����45. Stay agile and expect change Ҫ������
��������һ�����ģ��Ѿ�д�õĴ���һ���ᱻҪ���ĵġ���������������change��Ҫ���ܣ�����expect change��
����46. ������û��רְ������������Ա��
����Ҫ��רְ���ԡ�������ֲ���������peer test�������˲��ԡ�ǧ����Լ������Լ��ġ�
����47. ���ǵIJ�����һ���ܵļƻ����涨��ʲô����ô��ô�������Test Plan��Ҫ��Ҫ�����ܲ��ԣ�Ҫ��Ҫ��Usability���ԣ�ʲôʱ��ʼ�������ܣ�����ͨ���ı���ʲô����ʲô�ֶΣ��Զ��Ļ����ֶ��ģ���Щ������Ҫ��Test Plan���ش�
����48. ������дTest CaseȻ���ٲ��Ե�ô��
����Ӧ����ˡ�Ӧ��������ٱ�̡���test case�ٲ��ԡ���Ȼ�����������ġ�����ʱ��������һ����Ե�ͬʱ����test case��������test case�ٿ������Ҳ�ϲ������Ϊ��ϰ�ߣ�̫�鷳�����ڱ����Ƽ��������Կ�Ҳ����
����49. ���Ƿ��Ϊ����������ϴ�������������
������Ҫ����Ҫ��߽�������ϡ�������ϱ�ը���кܶ�test case�����ܹ��Զ����ɸ��ֱ߽���������ϡ�����Ҫ����������Ƿ���ʱ��ȥ������ô��test case��
����50. ���ǵij���Ա�ܿ�����������ô��
����Ҫ����Dev����Test Case�ɡ����Ƕ���Ϊ��ͬһ��Ŀ���ߵ�һ�����ģ����������
����51. �����Ƿ����ץһЩ�����������Բ��ԣ�
����Ҫ��ô�����Լ����Լ�д�ij�����棬��ô������˳�۵ġ����������ƣ�͡������Ŀ�����Ҳ�Ͳ����ˣ��������������Ҳ��ϰ���ˡ�
����52. ����Զ����Ե�������ȷô��
����������̫�ߡ����ҿ����������ܲ������⣬������ʱ���������Զ����ԡ��ɣ�����WinRunner��LoadRunner�ɡ����ڹ��ڵ��������Ե���״��˵��ֻ�ܡ���������������ˡ�
����53. ���ǵ����ܲ����ǵ����й��ܶ������������ô��
�����������������ܲ��Բ��ܱ��鵽��ν�ġ�ϵͳ���ԡ��Ρ��������������������졣
����54. ��ע������е�ɱ���ЧӦ��ô��
���������п�ҩ�ԣ�BugҲ�С����ֵ���BugԽ��Խ���������ġ���ʱ����ô�ҽ���һ�²��Ե�area���������ÿ��������ߺ��ַ������ֻᷢ��һЩ��bug�ˡ�
����55. ������Ŀ����������˵����Ʒ�ĵ�ǰ�����������ô��
����Ҫ�С����ϰ����������ƷĿǰ������Σ�Test Lead/ManagerӦ�ø���ش�
����56. �����е�Ԫ����ô��
������Ԫ����Ҫ�еġ�����û�е�Ԫ����Ҳ���Dz����ԣ�������û�е�Ԫ���Ե���Ŀ��Ҳ���ɹ��ˡ��������ǽ��ң������Ǵ�Ҷ������ֵĹ�ϵ�������Ǿ仰�����������Ƿdz�ʵ�����dz����̡��dz�����һ������ijЩ������ijЩ����»����һЩ�����ã���֮��Ȼ��
����57. ���ǵij���Ա��д�������ӹ�ǽ��ô��
������ɡ�д��һ������Ժ��㲻����Ԫ���ԣ�ҲӦ���Լ�����һ�ܡ���Ȼ����ר�ŵIJ�����Ա������������Ҳ������һ����Զ�������������Test Release Document��˵��������̫�õĻ���������Ȩ��ȥ��
����58. ���ǵij��������еĺ�������������ô��
������Ҫ����Ȼ˵����������write secure code��Ҫ�㣬����Ҫ��̫��������飬��Щ�ڲ�����֮��IJ������ݾͲ��ؼ�������ˣ�ʡ�㹦��ͬ���ĵ�����δ��Ҫ�����еĺ�����дע�͡�дһ������Ҫ�ľ��ˡ�
����59. ��Ʒ��ͳһ�Ĵ��������ƺͱ�������ô��
����Ҫ�С��������ͳһ��error message��Ȼ��ÿ��error message����һ��error number���������û������Լ�����error number��user manual����ȥ��������ľ��������Ϳ���ԭ����SQL Server�Ĵ���������ͬ����ASP.NETҲҪ��ͳһ��Exception���������Բο��йص�Application Block��
����60. ������ͳһ�Ĵ�����д�淶ô��
����Ҫ�С�Code Convention�ܶ࣬��һ����������ҾͿ����ˡ���Ȼ��Ҫ����FxCop���ֹ���������������ˡ�
����61. ���ǵ�ÿ���˶��˽���Ŀ����ҵ����ô��
����Ҫ������Vision����˼�������Ŀֻ���ɹ�������ʱ��Ҫ�����Լ�����Ϊ�й�ijij��ҵ����Ϣ���������ߣ�����ʱ��ʱ�ĸ���team member�������Ŀ�ܹ�Ϊijijij���Ҳ���ÿ���ʡ���ٶ��ٰ������˰�˵�Ǯ���������ж����ˡ�ƽ��������Ҳ�ǿ����и���ߵ�Ŀ��ġ�
����62. ��Ʒ�����ֵĽ���Ͳ���ϰ��һ��ô��
����Ҫ������Ҫ���û������������������һ����д������������
����63. �п�����Ϊ���������Cool Featureô��
����Ҫ��������ǿ�Ŷ������������ĵġ����ң���һ���ڰٳ�������Ϳ����ڸ�һЩ���⡣���������ڿͻ���˵����о���Ʒ�������Ƕ���˵����acceptable�ġ�����˵��cool feature����˵���������Ϊ���������һ���º��ֲ���ʩ��
����64. ���������̲�Ʒ������ʱ��Ҫ������
������������ʱ�䣨Start-Up time���ǿͻ������ܺû��ĵ�һӡ��
����65. ��Ҫ����ע������Ʒ�ʶ������˵�һ�۵�����ӡ�����Ա�����������̫�������ܡ��ȶ��ԡ��洢Ч�ʣ������������ڸ��ܡ����߲㾭�����ͻ����෴����������Ҫ��ˣ�Э����Щ��PM�Ĺ�����
����66. ���Ǹ�����ϸ��Ʒ����˵����������ô��
����Ҫ������Ҫ����Ʋ��ܿ��������DZ���ġ�����ĵ���Ӧ��˵��������Ʒ����ô���У�Ӧ�ò�ȡһЩ�����µķ�������Ƶ�ʱ��ǧ�����ϸ�ڣ����굽���ݿ⡢����Ⱦ���ʵ������ȥ����Щ�Ǻ�������飬һ�����������ż���
����67. ��ʼ�����Ͳ���֮ǰÿ���˶���ϸ���Ĺ������ô��
����Ҫ����Function Spec review������ͳһ˼��ġ����ң�review���Ժ��γ���һ�������������Ҳû���˿���˵���㿴�������Ҿ��Ƿ�����ô��Ƶģ����ڳԿ�ͷ�˰ɡ�
����68. �����˶�ʼ������The Whole Imageô��Ҫ��������Ŀ����ÿ������Ȼ��ֻ��������һƬҶ�ӣ���ÿ���˶�Ӧ��֪���Լ����������ƬҶ�����ڵ�������ô���ӵġ��ҷ����������죬���Թ��ֵİ��������쿴����ˮ�ߡ����䡣�μ���61����
����69. Dev�����Ļ����ǵ������������ô��
�������ܵ����ĸ��ݹ���ģ��֣����ߵ������ݱ��ֲ㡢�м�㡢���ݿ��֡����Ƽ���ô�������ȸ��ݹ���ģ��֣�Ȼ��ÿ�����㡱����һ��Owner��Review�����˵���ƺʹ��룬��֤consistency��
����70. ���ǵij���Աд�������˵���ĵ�ô��
����Ҫ����������˵���ij���Ա1999����ǰҲ��д������˵��д��дҲ���Ǿ��Եģ�͵����ʱ��Ҳ�ǿ��Եġ��μ���56����
����71. ������������ʱ����дһ�γ���ô��
����Ҫ�ġ�����ϲ���������ַ���������һ�����Ŀ��������Ŀ�кܶ�ѭ�����жϡ�ָ�롢�ݹ�ȣ��Ȳ�ƫ����ڿ��㷨��Ҳ��ƫ����ڿ��ض���API��
����72. ������û�м�������������
����Ҫ�ġ�ÿһ������ݸ�һ���ڲ���Tech Talk����Chalk Talk�ɡ�����Ա֮����������ĵã���ʻ�Ǯ�͵�����ȥ��ѵ���㡣
����73. ���ǵij���Ա����רע��һ������ô��
����Ҫ�ó���Աרעһ���¡�����˵��һ��������������Ŀ��10���ˣ�һ�ַ�������10����ͬʱ�μ�������Ŀ��ÿ����Ŀ��ÿ���˶���50%ʱ�䣻��һ�ַ�����5����ȥ��ĿA��5����ȥ��ĿB��ÿ���˶�100%��ijһ����Ŀ�ϡ���һ��ѡ����һ�֡���������ܶ��˶��������ܶ��쵼ʵ�������Ͱ����µ��ɿ��������ֵ���Դ�ˡ�
����74. ���ǵij���Ա�������ij�������Ҫ��ʱ��ô��
������ģ����dz����ģ����������Ŀ���ڿ����ij��change����Ҫ��ʱ�䣬�Դ�������change������ķ���������������ĥ��ĥ������Ա���淴������һ����������ѹ���ʱ��Ŀ����ȱ�С��
����75. ������Ҫ��Virtual Heads ��ò�Ҫ��Virtual Heads��
����Virtual heads��ζ��resource is not secure��shared resource�ή��resource�Ĺ���Ч�ʣ��������ӳ����Ļ��ᣬ����һ�Ķ��õ���û��̫��ʱ��ȥreview spec��review design��һ��dedicated���ˣ�Ҫǿ������ֻ��Ͷ��50%ʱ��;������ˡ����dzԹ����ģ�7��part time��tester�����ֵ�Bug�ɵĻ����������������full-time�ġ��μ���73����73������Գ���Ա�ģ�75������� Resource Manager�ġ�
-
Linux����ѧϰ
2010-05-18 17:45:39
startx ���ַ�����Console����ͼ�ν���X-Window Ctrl+Alt+BackSpace�ص��ַ�����
init [0123456]
��X-Windowͼ�β��������а���Alt+Ctrl+���ܼ�Fn��n=1~6
0��ͣ������ס��Ҫ��initdefault ����Ϊ0����Ϊ������ʹLinux������ ��
1�����û�ģʽ������Win9X�µİ�ȫģʽ��
2�����û�������û�� NFS ��
3����ȫ���û�ģʽ���������м���
4��һ�㲻�ã���һЩ��������¿�����������һЩ���顣
5��X11�������� X-Window ϵͳ��
6���������� ����ס��Ҫ��initdefault ����Ϊ6����Ϊ������ʹLinux���ϵ�������������
/etc/inittab
���� ������e��, �ڶ��� ����e��������� �ո�1��Esc ��b ���뵥�û�ģʽ(���û�ģʽ����inittab�ļ�)shutdown -h now �ػ�
shutdown -r now ���� reboot
shutdown -a now �������뵥�û�ģʽsu - root �л���root�û�
su root ��ȡrootȨ��logout �û�ע��
useradd �û���
passwd �û��� ->��������
userdel �û��� ɾ���û�
userdel -r �û��� ɾ���û��Լ��û���Ŀ¼//////////////////////////////////////////////////////////////////////////////////////
route ��ʾ����
#route del default gw xx.xx.xx.xx. xxx.xxx.xx.xxx
#route add default gw xx.xx.xx.xx. xxx.xxx.xx.xxx
netconfig ������������
/etc/init.d/network restart �� service network restart �����������
ip��������/etc/sysconfig/network-scrips/ifcfg-ethX������ģ��������ҵ�ifcfg-eth0����
DEVICE=eth0
BOOTPROTO=none
NBOOT=yes
IPADDR=192.168.0.2
NETMASK=255.255.255.0
USERCTL=no
PEERDNS=no
GATEWAY=192.168.0.1
TYPE=Ethernet
NETWORK=192.168.0.0
BROADCAST=192.168.0.255
////////////////////////////////////////////////////////////////////////////////////////
mount /dev/cdrom /mnt/cdrom/ ���ع���
mount -t iso9660 xxxx.iso /mnt/cdrom -o loop ����iso����etc/vsftpd/vsftpd.conf
var/ftp/pub
service vsftpd start/restart///////////////////////////////////////////////////////////////////////////////////////////
pwd ��ʾ��ǰĿ¼
ls -a ��ʾ�����ļ�
ls -l ��ʾ���б���ʽ
ls -al
ls -l /etc | more �ܵ����� ����һ������������ | ����������mkdir ����Ŀ¼
rmdir ɾ��Ŀ¼touch �������ļ�
cp ���� cp a.out /home/xiaoming/ (tab�����Զ���ȫ����,��2����ʾѡ��)
cp -r dir1 dir2 �ݹ鸴�ƣ�������Ŀ¼��Ϣ��mv �ƶ��ļ����ļ���
rm ɾ���ļ���Ŀ¼more ��ʾ�ļ����ݣ�����ҳ
grep ���ı��в�ѯ����
grep -n "ab" install.log ��install.log�в���ab(��ʾ�ڵڼ���)
grep "ab" install.logfind /home -name *.* ����/home�У��ļ���Ϊ*.*���ļ�
ls -l > 1.txt �ض���grep -n "ab" install.log > kkk.txt
ls -l >>1.txt ������ӵ�1.txtcat 1.txt ֻ������
/////////////////////////////////////////////////////////////////////////////////////////////
cat /etc/group | more
groupadd ����
useradd -g ���� �û��� �����û������䵽��
usermod -g ���� �û��� ���û�������
cat /etc/passwdr 4 100��
w 2 010д
x 1 001��ִ��
rwx 7 111
rw 6 110��д-rw-r--r-- 1 root root 1213 Feb 2 09:39 abc
�ļ����� �ļ������� �ļ������� �������û�
��һ���ַ������ļ�-��Ŀ¼d������l
1 ���ӵ��ļ���
root �û�
root ��
1213 �ļ���С(�ֽ�)
Feb 2 09:39 abc ���������
abc �ļ���ls -ahl ���ļ�������
chmod 777 �ļ��к��ļ�/////////////////////////////////////////////////////////////////////////////////////////////////
fdisk -l �鿴���� ��������/dev/sda5 ��ʼ
df [-����] df -l / df -h�鿴����ʹ�����
df [Ŀ¼ȫ·��] �鿴Ŀ¼���ĸ�����
mount [-����] [�豸����] [���ص�] ���ع���ʱ����ֱ��ʹ�� mount /mnt/cdrom �� mount /dev/cdrom /mnt/cdrom
umount �����
find -size +100000K ��ʾ100M���ϵ��ļ�
////////////////////////////////////////////////////////////////////////////////////////////////////
shell
Bourne S.R.Borne /bin/sh -> bash ��½
C Bill Joy /bin/csh -> tcsh
Kom David /bin/ksh ŷ��
/bin/bsh -> ashenv �鿴linux��������
chsh -s /bin/cshhistory n ��ʾ���n������
!5 ִ�е�5������///////////////////////////////////////////////////////////////////////////
setup linux����
/etc/rc.d/init.d/network restart �� service network restart ����������Ч
ifconfig eth0 192.168.1.5 ��ʱ��ЧIP���������ֱ��ԭ��IP
/etc/sysconfig/netwrok-scripts/ifcfg-eth0 ���������ļ���linux�������豸�����ļ���
ifconfig eth0 down ��ֹʹ��eth0
ifconfig eth0 up ��////////////////////////////////////////////////////////////////////////////////////////
RPM ReadHat Package Manager ��RedHat�������������ߣ�
apache-1.3.23-11.i386.rpam ��������-���汾��-�ΰ汾��-����ƽ̨
rpm -qa | more ��rpm -qa | grep X �������а�װ��rpm������ѯ����X�ַ���rpm��
rpm -q mozilla ����Ƿ�װ
rpm -qi mozilla �鿴����Ϣ
rpm -ql mozilla ����е��ļ�
rpm -qf /etc/passwd ���ļ������İ�
rpm -��װ��
rpm -i RPM��ȫ·��
rpm -ivh RPM��ȫ·��
������i install ��װ
v verbose ��ʾ
h hash ������
ɾ����
rpm -e RPM������ rpm -e --nodeps samba ǿ��ɾ��
������
rpm -U RPM��ȫ·��tar -zxfv filename.tar.gz ��ѹ
-
loadrunner¼�Ƶ�¼����תmd5
2010-04-06 22:54:51
��¼���û�ע���¼�ű�ʱ������������Web������û��������MD5���ܣ���������һ�νű���web_submit_data("MagaRegister.aspx_2",
"Action=http://www.feidubook.com/MagaRegister.aspx",
"Method=POST",
"TargetFrame=",
"RecContentType=text/html",
"Referer=http://www.feidubook.com/MagaRegister.aspx",
"Snapshot=t13.inf",
"Mode=HTML",
ITEMDATA,
"Name=__EVENTTARGET", "Value=", ENDITEM,
"Name=__EVENTARGUMENT", "Value=", ENDITEM,
"Name=__VIEWSTATE", "Value={Siebel_Analytic_ViewState4}", ENDITEM,
"Name=topNaviId$txtUserName", "Value=", ENDITEM,
"Name=topNaviId$txtUserPwd", "Value=", ENDITEM,
"Name=topNaviId$ValidCodeId", "Value=", ENDITEM,
"Name=searchType", "Value=qikan", ENDITEM,
"Name=searchdomain", "Value=", ENDITEM,
"Name=q", "Value=", ENDITEM,
"Name=txtUserName", "Value=user0001", ENDITEM,
"Name=txtUserPwd", "Value=e10adc3949ba59abbe56e057f20f883", ENDITEM, //����123456��תΪ32λ��MD5
"Name=txtUserPwd2", "Value=e10adc3949ba59abbe56e057f20f883", ENDITEM,�����������ʱ����һ�ַ������ǽ����û�������������������Ϊһ������ÿ���û��������붼Ϊe10adc3949ba59abbe56e057f20f883����һ�ַ�����������MD5�������������һ���㷨��#ifndef MD5_H
#define MD5_H
#ifdef __alpha
typedef unsigned int uint32;
#else
typedef unsigned long uint32;
#endif
struct MD5Context {
uint32 buf[4];
uint32 bits[2];
unsigned char in[64];
};
extern void MD5Init();
extern void MD5Update();
extern void MD5Final();
extern void MD5Transform();
typedef struct MD5Context MD5_CTX;
#endif
#ifdef sgi
#define HIGHFIRST
#endif
#ifdef sun
#define HIGHFIRST
#endif
#ifndef HIGHFIRST
#define byteReverse(buf, len) /* Nothing */
#else
void byteReverse(buf, longs)unsigned char *buf; unsigned longs;
{
uint32 t;
do {
t = (uint32) ((unsigned) buf[3] << 8 | buf[2]) << 16 |((unsigned) buf[1] << 8 | buf[0]);*(uint32 *) buf = t;
buf += 4;
} while (--longs);
}
#endif
void MD5Init(ctx)struct MD5Context *ctx;
{
ctx->buf[0] = 0x67452301;
ctx->buf[1] = 0xefcdab89;
ctx->buf[2] = 0x98badcfe;
ctx->buf[3] = 0x10325476;
ctx->bits[0] = 0;
ctx->bits[1] = 0;
}
void MD5Update(ctx, buf, len) struct MD5Context *ctx; unsigned char *buf; unsigned len;
{
uint32 t;
t = ctx->bits[0];
if ((ctx->bits[0] = t + ((uint32) len << 3)) < t)
ctx->bits[1]++;
ctx->bits[1] += len >> 29;
t = (t >> 3) & 0x3f;
if (t) {
unsigned char *p = (unsigned char *) ctx->in + t;
t = 64 - t;
if (len < t) {
memcpy(p, buf, len);
return;
}
memcpy(p, buf, t);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
buf += t;
len -= t;
}
while (len >= 64) {
memcpy(ctx->in, buf, 64);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
buf += 64;
len -= 64;
}
memcpy(ctx->in, buf, len);
}
void MD5Final(digest, ctx)
unsigned char digest[16]; struct MD5Context *ctx;
{
unsigned count;
unsigned char *p;
count = (ctx->bits[0] >> 3) & 0x3F;
p = ctx->in + count;
*p++ = 0x80;
count = 64 - 1 - count;
if (count < 8) {
memset(p, 0, count);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
memset(ctx->in, 0, 56);
} else {
memset(p, 0, count - 8);
}
byteReverse(ctx->in, 14);
((uint32 *) ctx->in)[14] = ctx->bits[0];
((uint32 *) ctx->in)[15] = ctx->bits[1];
MD5Transform(ctx->buf, (uint32 *) ctx->in);
byteReverse((unsigned char *) ctx->buf, 4);
memcpy(digest, ctx->buf, 16);
memset(ctx, 0, sizeof(ctx));
}
#define F1(x, y, z) (z ^ (x & (y ^ z)))
#define F2(x, y, z) F1(z, x, y)
#define F3(x, y, z) (x ^ y ^ z)
#define F4(x, y, z) (y ^ (x | ~z))
#define MD5STEP(f, w, x, y, z, data, s) ( w += f(x, y, z) + data, w = w<<s | w>>(32-s), w += x )
void MD5Transform(buf, in)
uint32 buf[4]; uint32 in[16];
{
register uint32 a, b, c, d;
a = buf[0];
b = buf[1];
c = buf[2];
d = buf[3];
MD5STEP(F1, a, b, c, d, in[0] + 0xd76aa478, 7);
MD5STEP(F1, d, a, b, c, in[1] + 0xe8c7b756, 12);
MD5STEP(F1, c, d, a, b, in[2] + 0x242070db, 17);
MD5STEP(F1, b, c, d, a, in[3] + 0xc1bdceee, 22);
MD5STEP(F1, a, b, c, d, in[4] + 0xf57c0faf, 7);
MD5STEP(F1, d, a, b, c, in[5] + 0x4787c62a, 12);
MD5STEP(F1, c, d, a, b, in[6] + 0xa8304613, 17);
MD5STEP(F1, b, c, d, a, in[7] + 0xfd469501, 22);
MD5STEP(F1, a, b, c, d, in[8] + 0x698098d8, 7);
MD5STEP(F1, d, a, b, c, in[9] + 0x8b44f7af, 12);
MD5STEP(F1, c, d, a, b, in[10] + 0xffff5bb1, 17);
MD5STEP(F1, b, c, d, a, in[11] + 0x895cd7be, 22);
MD5STEP(F1, a, b, c, d, in[12] + 0x6b901122, 7);
MD5STEP(F1, d, a, b, c, in[13] + 0xfd987193, 12);
MD5STEP(F1, c, d, a, b, in[14] + 0xa679438e, 17);
MD5STEP(F1, b, c, d, a, in[15] + 0x49b40821, 22);
MD5STEP(F2, a, b, c, d, in[1] + 0xf61e2562, 5);
MD5STEP(F2, d, a, b, c, in[6] + 0xc040b340, 9);
MD5STEP(F2, c, d, a, b, in[11] + 0x265e5a51, 14);
MD5STEP(F2, b, c, d, a, in[0] + 0xe9b6c7aa, 20);
MD5STEP(F2, a, b, c, d, in[5] + 0xd62f105d, 5);
MD5STEP(F2, d, a, b, c, in[10] + 0x02441453, 9);
MD5STEP(F2, c, d, a, b, in[15] + 0xd8a1e681, 14);
MD5STEP(F2, b, c, d, a, in[4] + 0xe7d3fbc8, 20);
MD5STEP(F2, a, b, c, d, in[9] + 0x21e1cde6, 5);
MD5STEP(F2, d, a, b, c, in[14] + 0xc33707d6, 9);
MD5STEP(F2, c, d, a, b, in[3] + 0xf4d50d87, 14);
MD5STEP(F2, b, c, d, a, in[8] + 0x455a14ed, 20);
MD5STEP(F2, a, b, c, d, in[13] + 0xa9e3e905, 5);
MD5STEP(F2, d, a, b, c, in[2] + 0xfcefa3f8, 9);
MD5STEP(F2, c, d, a, b, in[7] + 0x676f02d9, 14);
MD5STEP(F2, b, c, d, a, in[12] + 0x8d2a4c8a, 20);
MD5STEP(F3, a, b, c, d, in[5] + 0xfffa3942, 4);
MD5STEP(F3, d, a, b, c, in[8] + 0x8771f681, 11);
MD5STEP(F3, c, d, a, b, in[11] + 0x6d9d6122, 16);
MD5STEP(F3, b, c, d, a, in[14] + 0xfde5380c, 23);
MD5STEP(F3, a, b, c, d, in[1] + 0xa4beea44, 4);
MD5STEP(F3, d, a, b, c, in[4] + 0x4bdecfa9, 11);
MD5STEP(F3, c, d, a, b, in[7] + 0xf6bb4b60, 16);
MD5STEP(F3, b, c, d, a, in[10] + 0xbebfbc70, 23);
MD5STEP(F3, a, b, c, d, in[13] + 0x289b7ec6, 4);
MD5STEP(F3, d, a, b, c, in[0] + 0xeaa127fa, 11);
MD5STEP(F3, c, d, a, b, in[3] + 0xd4ef3085, 16);
MD5STEP(F3, b, c, d, a, in[6] + 0x04881d05, 23);
MD5STEP(F3, a, b, c, d, in[9] + 0xd9d4d039, 4);
MD5STEP(F3, d, a, b, c, in[12] + 0xe6db99e5, 11);
MD5STEP(F3, c, d, a, b, in[15] + 0x1fa27cf8, 16);
MD5STEP(F3, b, c, d, a, in[2] + 0xc4ac5665, 23);
MD5STEP(F4, a, b, c, d, in[0] + 0xf4292244, 6);
MD5STEP(F4, d, a, b, c, in[7] + 0x432aff97, 10);
MD5STEP(F4, c, d, a, b, in[14] + 0xab9423a7, 15);
MD5STEP(F4, b, c, d, a, in[5] + 0xfc93a039, 21);
MD5STEP(F4, a, b, c, d, in[12] + 0x655b59c3, 6);
MD5STEP(F4, d, a, b, c, in[3] + 0x8f0ccc92, 10);
MD5STEP(F4, c, d, a, b, in[10] + 0xffeff47d, 15);
MD5STEP(F4, b, c, d, a, in[1] + 0x85845dd1, 21);
MD5STEP(F4, a, b, c, d, in[8] + 0x6fa87e4f, 6);
MD5STEP(F4, d, a, b, c, in[15] + 0xfe2ce6e0, 10);
MD5STEP(F4, c, d, a, b, in[6] + 0xa3014314, 15);
MD5STEP(F4, b, c, d, a, in[13] + 0x4e0811a1, 21);
MD5STEP(F4, a, b, c, d, in[4] + 0xf7537e82, 6);
MD5STEP(F4, d, a, b, c, in[11] + 0xbd3af235, 10);
MD5STEP(F4, c, d, a, b, in[2] + 0x2ad7d2bb, 15);
MD5STEP(F4, b, c, d, a, in[9] + 0xeb86d391, 21);
buf[0] += a;
buf[1] += b;
buf[2] += c;
buf[3] += d;
}
void GetMd5FromString(const char* s,char* resStr)
{
struct MD5Context md5c;
unsigned char ss[16];
char subStr[3];
int i;
MD5Init( &md5c );
MD5Update( &md5c, s, strlen(s) );
MD5Final( ss, &md5c );
strcpy(resStr,"");
for( i=0; i<16; i++ )
{
sprintf(subStr, "%02x", ss[i] );
itoa(ss[i],subStr,16);
if (strlen(subStr)==1) {
strcat(resStr,"0");
}
strcat(resStr,subStr);
}
strcat(resStr,"\0");
}�������㷨ճ�������±�������Ϊmd5.h��LR������ͷ�ļ�md5.h����globals.h����������#include "md5.h"md5���߲�ѯ�ƽ� www.cmd5.com -
LoadRunner�������ķ���2
2010-04-06 02:37:59
LoadRunner�������ķ���ϵ��֮��--Check
web_find
�����
��int web_find (const char *StepName, <Attributes and Specifications list>, char *searchstring, LAST );������
��1��StepName���������ƣ���Tree��ͼ�г��֡�2��Attributes and Specifications list��
֧�ֵ������У�
Frame���ڶ�Frame������£�����Ҫ����Frame�ķ�Χ��
Expect��������ʲô����º������ɹ����ҵ���ָ��������������û���ҵ�������˵�����Լ��ָ���Ĵ�����Ϣ�Ƿ������webҳ���С��Ϸ���ֵ��2����found��notfound��Ĭ��ֵ����found����
Matchcase��ָ�������Ƿ����ִ�Сд��
Repeat��ָ������һ�η���Ҫ���ҵ��ַ���ʱ�������Ƿ��������һ��webҳ���а�����������ҵ��ַ���ʱ���˲����Ƿdz����õġ��Ϸ���ֵ��2����yes��no��Ĭ��ֵ����yes����
Report��ָ����ʲô����£�VuGen��ִ����־����ʾ�˺����ļ�������Ϸ���ֵ�У�success��failure��always��Ĭ��ֵ����always����
Onfailure���˲��������ں������ʧ�ܺ�Vuser�Ƿ��жϡ�����ֵ��abort�����ָ����Onfailure=abort,���������ʧ��ʱ������������ʱ�����е�error-handling��ʲô���ű������жϡ�
���û��ָ��Onfailure=abort,��ô����ʱ������error-handling���������á�
֧�ֵ������У�RightOf, LeftOf ����֧��7.x�����߰汾����
RightOf��Ҫ���ҵ��ַ����ұߵ����ݡ�
LeftOf��Ҫ���ҵ��ַ�����ߵ����ݡ�
3��Searchstring����Ҫ���ҵ��ַ�������ʽΪ��What=stringxyz���������������ִ�Сд��
4��LAST���������������
����ֵ
�����͡� �ɹ�ʱ����LR_PASS(0)��ʧ��ʱ����LR_FAIL (1)��˵��
���˺�������������HTMLҳ���в���ָ�����ַ������˺���ֻ���ڻ���HTML¼�ƵĽű���ʹ�á���ָ����HTML����ȫ������Ժ�ʼִ���������̣���web_reg_findҪ����
web_find������C���ԵĽű����Ѿ���web_reg_find�������web_reg_find�����ٶȱȽϿ죬������HTML-based��URL-based��¼�Ʒ�ʽ�ж�����ʹ�á� ��C���Խű��У�web_find�������ݵġ�Java��Visual Basic�ű��в���֧������
������HTTPģʽ�µ�WAP�û�����������WSP�ط�ģʽ�µ�WAP�û�����֧�ִ˺�����
web_global_verification
�����
��int web_global_verification (<List of Attributes>, LAST )��������
��List of Attributes��1��Text����������һ���ǿյģ���NULL��β���ַ�������ʾҪ���ҵ����ݡ������Text=string����������ʹ��text flags�Զ����ַ�����
2��TextPfx��û��ָ��Text�������ʹ�ô����ԡ�Ҫ���ҵ��ַ�����ǰ������� TextPfx =string����������ʹ��text flags�Զ����ַ�����
3��TextSfx��û��ָ��Text�������ʹ�ô����ԡ�Ҫ���ҵ��ַ����ĺ�������� TextSfx =string����������ʹ��text flags�Զ����ַ�����
4��Search����ѡ�����������ַ�������ѡ��ֵ�ǣ�Headers��Body��NORESOURCE��All��Ĭ��ֵ��NORESOURCE�������Search=value����
5��Fail�����ַ����Ҳ���ʱ�Ĵ���ѡ�Found ��Ĭ��ֵ����NotFound��Found��ʾ���ҵ���Ӧ���ַ���ʱ�����˴���������Error������NotFound��ʾ���Ҳ����ַ���ʱ�����˴��������Fail=value����
6��ID������־�ļ��б�ʶ��ǰ������
LAST���������������
ע��text flags��/IC��ʾ���Դ�Сд��/BIN��ʾָ�����Ƕ��������ݡ�
����ֵ
�����͡� �ɹ�ʱ����LR_PASS(0)��ʧ��ʱ����LR_FAIL (1)��˵��
��web_global_verification����ע�ắ����ע��һ����webҳ���������ı��ַ�����������web_reg_findֻ����һ��Action������ִ��������ͬ���ǣ�������֮�����е�Action�ຯ����ִ�������ġ���������ҳ���body��headers��html�������������ҳ�档�ڼ��һЩӦ�ó��𣨲�ͨ��http״̬�������֣��Ĵ���ʱ��web_global_verification�Ƿdz����õġ����Ҫ��λͨ��HTTP״̬����ֵĴ���ʱ��ʹ��web_get_int_property��
���ҷ�Χ��all�����HTMLҳ�棻Headers��ҳ���ͷ��body��ҳ����壬�������е���Դ��������ͷ��NORESOURCE��Ĭ��ѡ�����������ҳ����壬�Ѱ���ͷ����Դ��
�����֪��Ҫ���ҵľ�ȷ���ı�������Ҫ���ҵĶ���ı�������ȫ��ͬ��,����ʹ��ǰ�ͺ�����ʾ����ʱ��Ҫ�õ�TextPfx��TextSfx���ԡ���2�����Ա���ͬʱָ����һ��ָ��������һ�����Ͳ���ָ��Text�����ˡ�
ע�⣺web_global_verification��WAPЭ���²������С�
web_image_check
�����
��int web_image_check(const char *CheckName, <List of Attributes>, <"Alt=alt"|| "Src=src">, LAST );������
��1��CheckName�����ƣ���Tree��ͼ�г��֡�2��List of Attributes��
֧�ֵ������У�Frame���ڶ�Frame������£�����Ҫ����Frame�ķ�Χ����
֧�ֵ�ѡ���У�expect, matchcase, repeat, report, onfailure��
Tip��ѡ������Ե����𣬴�ѡ�ֻ��������Ԥ�����ֵ��������ֵ������Ч�ġ�
3��Alt�����ͼ���ALT��ǡ���������ֵ��
4��Src�����ͼ���SRC��ǡ���������ֵ��
5��LAST�������б�������ָʾ����
����ֵ
�����͡�˵��
��web_image_check���ָ����ͼ���Ƿ���HTMLҳ���г��֡�Alt����Src���߱�����һ���ڲ����б��г��֡�������ͨ������ô���ɹ���
�˺�������֧�ֻ���HTML�Ľű���
��web_reg_add_cookie
�����
��int web_reg_add_cookie(const char * cookie, const char * searchstring, LAST );������
��1��Cookie��������Ҫ���ӻ��ĵ�Cookie��Cookie�IJ�����ʽΪ��<name>=VALUE; (required)��domain=DOMAIN_NAME;(required)��expires=DATE��path=PATH��(default path is "/")��secure��
�˲����е�cookieԪ�غ�HTTP��Ӧͷ�е�Set-Cookie����ͬ�ġ�������Session=1234��domain=sanditon.com�����������Session����cookie�����ơ�
2��Searchstring��Ҫ���ҵ��ı��ַ������ַ�������Ϊ�գ���null��β����ʽΪ��Text=string����
3��LAST�������б��Ľ�������
����ֵ
�����͡� �ɹ�ʱ����LR_PASS(0)��ʧ��ʱ����LR_FAIL (1)��˵��
��web_reg_add_cookie��ע�����͵ĺ�����������ע��һ�������ı��ַ���������鶯���ں�����Action����֮����С�����ַ������ҵ��������ӵ�cookie�С���Ҫע�⣬����web_reg_add_cookie�ڹ����ϸ�HTTP Set_Cookieͷ���ƣ����ǻ����и����Ե����� ����HTTP����domain������Set-Cookieͷ���ǿ�ѡ�ġ����û��ָ����Ĭ�ϵ�domain��ֵ�Dz���cookie�ķ�������host name����ʹ��web_reg_add_cookie����ʱ����������hostname����ѹ�����ԵĻ�����˵�Dz����õģ�����domain�����DZ�ѡ�
�˺�����HTML-based ��URL-based�Ľű��ж�����ʹ�á�������¼��ѡ���¼�Ʊ�ǩҳ�����˺������ڷ��������ݵ���ͻ���֮ǰע����������ģ����Ե������������һ���ͻ�ִ�������������ű���Ƚϸ��ԡ�
web_reg_add_cookie���û��ֶ����ӵģ���¼�ơ�
web_reg_find
�����
��int web_reg_find (const char *attribute_list, LAST);������
��1��attribute_list��ͨ��Name=Value�������ݲ�����������Text=string����Text��TextPfx��TextSfx����������һ�����֡������������ǿ�ѡ�ġ�
a) Text��Ҫ�������ַ������ַ�������ǿգ���NULL��β������ʹ��text flags�Զ��������ַ�����
b) TextPfx��Ҫ�������ַ�����ֱ��ǰ��
c) TextSfx��Ҫ�������ַ�����ֱ�Ӻ���
d) Search�������ķ�Χ����ѡ��ֵ�ǣ�Headers ��Body��������������������Noresource (������HTML��������������������ͷ����Դ)��ALL ���������塢ͷ����Դ����������Ĭ��ֵ����BODY����
e) SaveCount��ƥ��ĸ�����
f) Fail�����ú��������ʲô״̬��ʧ�ܡ�
g) ID����־�ļ��б�ʶ�˺�����һ���ַ�����
h) RelFrameId���������FrameId��ע�⣺�˲�����GUI����Ľű��в���֧�֡�
2��LAST�������б������ı�Ƿ���
����ֵ
�����͡� �ɹ�ʱ����LR_PASS(0)��ʧ��ʱ����LR_FAIL (1)��˵��
��web_reg_find����ע�ắ����ע��һ����webҳ���������ı��ַ����������ڽ�������Action����web_url���ຯ����ִ��������ͨ�������������ַ��Ƿ��������֤�Ƿ���������ҳ�档���磬ͨ��������Welcome���������ҳ�Ƿ���ȫ���ˡ�Ҳ���Բ�����Error�����������Ƿ�����������ʹ�ô˺���ע��һ��������ͳ���ض��ַ������ֵĴ�����
������ʧ�ܣ��ڽ�������Action��ĺ����лᱨ����˺�������ע��������ִ�С������ķ���ֵֻ����ע���Ƿ�ɹ���������ʾ���Ľ����
�˺��������ܹ�����text�����ܲ��ҵ�Χ����text��strings����Ҫͬʱָ��text��ǰ����
Fail������ѡ���������Found����NotFound����Ĭ������NotFound����
��Fail=Found�� ָʾ����Ӧ���ַ��ҵ�ʱ���������ʧ�ܡ����磬���ҵ�����Error��������ҵ��ˣ�˵��web����û�гɹ�������Ѻ����������Ϊʧ�ܡ�
��Fail=NotFound��ָʾ����Ӧ���ַ��Ҳ���ʱ���������ʧ�ܡ�������ҵ���web����ɹ�ʱ���ֵ��ַ���ʱ����Ҫʹ��NotFound��
SaveCount����ָʾ���浽�����е�ƥ����ַ����ĸ�����ʹ��������ԣ���Ҫָ����SaveCount=param������������ִ�к�param ��ֵ��null��β���������͵�ֵ��
���ָ����SaveCount����û��ʹ��Fail��������鲻��ʧ�ܣ�������Ҫ���ҵ��ַ����Ƿ��ҵ���ͨ�����SaveCount��ֵȷ���ַ����Ƿ��ҵ��� <SPAN style="FONT-FAMILY: ����; mso-ascii-font-family:
-
LoadRunner�������ķ���1
2010-04-06 02:08:57
LoadRunner�������ķ���ϵ��֮һ--Action
web_url
���
Int Web_url(const char *name, const char * url, <Lists of Attributes>, [EXTRARES,<Lists of Resource Attributes>,LAST)����ֵ
�ɹ�ʱ����LR_PASS (0)��ʧ��ʱ���� LR_FAIL (1)��������
Name��VuGen��������ͼ����ʾ�����ƣ����Զ���������Ҳ����������������ơ�url��ҳ��url��ַ��
List of Attributes
EXTRARES���ָ����������һ����������Դ���Ե��б��ˡ�
List of Resource Attributes
LAST�������б������ı�Ƿ���
˵��
Web_url���ݺ����е�URL���Լ��ض�Ӧ��URL������Ҫ�����ġ�ֻ��VuGen����URL-based����HTML-based����ʱA script. containing explicit URLs onlyѡ�ѡ��ʱ����¼��ģʽʱ��web_url�Żᱻ¼�Ƶ���
����ʹ��web_url ģ���FTP�������������ļ���web_url ������ʹFTP������ִ���ļ�����ʵ����ʱ�IJ����������ֹ�ָ����"FtpAscii=1"�����ػ��Զ�����ģʽ��ɡ�
��¼��ѡ���У�Toos��Recording Option�£�Recordingѡ���У���һ��Advanced HTMLѡ����������Ƿ�¼�Ʒ�HTML��Դ��ֻ��ѡ���ˡ�Record within the current script. step��ʱ��List of Resource Attributes�Żᱻ¼�Ƶ�����HTML��Դ��������gif��jpgͼ���ļ���
ͨ����HTTPͷ���Դ��ݸ�������һЩ���ӵ�������Ϣ��ʹ��HTTPͷ���������а����������������ͣ�Content_type������ѹ���ļ�һ����������ֻ�����ض�״̬�µ�webҳ�档
���е�Web Vusers ��HTTPģʽ�µ�WAP Vusers���ط�ģʽ�µ�Wireless Session Protocol��WSP������֧��web_url������
web_image
���
Int web_image (const char *StepName, <List of Attributes>, [EXTRARES, <List of Resource Attributes>,] LAST );����ֵ
�ɹ�ʱ����LR_PASS (0)��ʧ��ʱ���� LR_FAIL (1)��������
StepName��VuGen��������ͼ����ʾ�����ƣ����Զ���������Ҳ����������������ơ�List of Attributes���������˺Ϳͻ���ӳ���ͼƬ����SRC������һ���ᱻ¼�Ƶ��ģ�������ALT��Frame��TargetFrame��Ordinal�����еĻ��ᱻ¼�Ƶ���
1��ALT������ͼ���Ԫ�ء������ָ��ͼ��ʱ������������������ʾ��
2��SRC������ͼ���Ԫ�أ�������ͼ����ļ���. �磺 button.gif��Ҳ����ʹ��SRC/SFX��ָ��ͼ��·���ĺ�������ӵ����ͬ�˺����ַ������ᱻƥ�䵽��
3��Frame��¼�Ʋ���ʱ���ڵ�Frame�����ơ�
4��TargetFrame����List of Attributes��ͬ��������
5��Ordinal���μ�Web_link��ͬ��������
List of Attributes���ͻ���ӳ���ͼƬ����
1��AreaAlt����굥�������ALT���ԡ�
2��AreaOrdinal����굥�������˳��š�
3��MapName��ͼ���ӳ������
List of Attributes����������ӳ���ͼƬ�������ܵ�����겻�������ԣ������������Եĸ�ʽ��ʹ�á�
1��Xcoord�����ͼ��ʱ��X���ꡣ
2��Ycoord�����ͼ��ʱ��Y���ꡣ
EXTRARES���ָ����������һ����������Դ���Ե��б��ˡ�
List of Resource Attributes���μ�List of Resource Attributesһ�ڡ�
LAST�������б������ı�Ƿ���
˵��
web_imageģ�������ָ��ͼƬ�ϵĵ����������˺�����������ǰ�ò�������������ʹ�á���Toos��Recording Option�����¼�Ƽ�����Ϊ����HMTL��¼�Ʒ�ʽʱ��web_image�Żᱻ¼�Ƶ���
web_image֧�ֿͻ��ˣ�client-side���ͷ�������server-side��ͼƬӳ�䡣
��¼��ѡ���У�Toos��Recording Option�£�Recordingѡ���У���һ��Advanced HTMLѡ����������Ƿ�¼�Ʒ�HTML��Դ��ֻ��ѡ���ˡ�Record within the current script. step��ʱ��List of Resource Attributes�Żᱻ¼�Ƶ�����HTML��Դ��������gif��jpgͼ���ļ���
ͨ����HTTPͷ���Դ��ݸ�������һЩ������Ϣ��ʹ��HTTPͷ���������а������ݣ���ͬѹ���ļ�һ����������ֻ�����ض�״̬��webҳ�档
web_image֧��Web�����û�����֧��WAP�����û���
����
���������ģ���û�����Homeͼ���Իص���ҳ�����岿�֣���web_url("my_home", "URL=http://my_home/", LAST)��
web_link("Employees", "Text=Employees", LAST)��
web_image("Home.gif", "SRC=../gifs/Buttons/Home.gif", LAST)��
web_link("Library", "Text=Library", LAST)��
web_image("Home.gif", "SRC=../../gifs/buttons/Home.gif", LAST)��
���������ģ���û��ڿͻ���ӳ���ͼƬ�ϵ�����
web_image("dpt_house.gif",
"Src=../gifs/dpt_house.gif",
"MapName=dpt_house",
"AreaOrdinal=4",
LAST)��
���������ģ���û��ڷ����ӳ���ͼƬ�ϵ�����
web_image("The Web Developer's Virtual Library",
"Alt=The Web Developer's Virtual Library",
"Ordinal=1",
"XCoord=91",
"YCoord=17",
LAST)��
������һ��ʹ���ļ����������ӣ���ָ����dpt_house.gif��Ϊ����������../gifs/dpt_house.gif��/gifs/dpt_house.gif��gifs/dpt_house.gif��/dpt_house.gif�ȶ���ƥ�䵽��
web_image("dpt_house.gif",
"Src/sfx=dpt_house.gif", LAST)��web_link
���
Int web_link (const char *StepName, <List of Attributes>, [EXTRARES, <List of Resource Attributes>,] LAST )������ֵ
�ɹ�ʱ����LR_PASS (0)��ʧ��ʱ���� LR_FAIL (1)��������
StepName��VuGen��������ͼ����ʾ�����ƣ����Զ�����������Ҳ�������������ơ�List of Attributes��֧�����е����ԣ�
1. Text���������е����֣����뾫ȷƥ�䡣
2. Frame��¼�Ʋ���ʱ���ڵ�Frame�����ơ�
3. TargetFrame��ResourceByteLimit����List of Attributesһ�ڡ�
4. Ordinal������ø��������ԣ�Attributes��ɸѡ����Ԫ�ز�Ψһ����ôVuGenʹ�ô�������ָ�����е�һ�������磺��SRC=abc.gif������Ordinal=3����ǵ���SRC��ֵ�ǡ�abc.gif���ĵ�3��ͼƬ��
EXTRARES����������IJ���������list of resource attributes�ˡ�
LAST����β��ʾ����
˵��
ģ������������ɸ����Լ��������������Ͻ��е������˺���������ǰ�ö������������вſ���ִ�С�web_link �����ڻ���HTML��¼�Ʒ�ʽ�вŻᱻVuGen������
��HTML���ɵ���Դ��������.gif ��.jpgͼ����List of Resource Attributes������˵��������Recording Options--Recording --HTML-based script-- Record within the current script. stepѡ�ѡ��ʱ�����DzŻᱻ���뵽�����С�
����ͨ���ı�HTTPͷ��Ϣ������������һЩ������Ϣ��ʹ��HTTPͷ��Ϣ���ԣ�������Ӧ���а����������������ͣ�Content-Type��������ѹ���ļ�������ֻ���������ض���״̬��ȥ����webҳ��
�˺���ֵ֧��Web�����û�����֧��WAP�����û���
web_submmit_form
���
Int web_submit_form. (const char *StepName, <List of Attributes>, <List of Hidden Fields>, ITEMDATA, <List of Data Fields>, [ EXTRARES, <List of Resource Attributes>,] LAST );����ֵ
�ɹ�ʱ����LR_PASS (0)��ʧ��ʱ���� LR_FAIL (1)��������
StepName��Form�����֡�VuGen��������ͼ����ʾ�����ƣ����Զ���������Ҳ����������������ơ�List of Attributes��֧���������ԣ�
1. Action��Form�е�ACTION���ԣ�ָ�������Form�еIJ����õ���URL��Ҳ����ʹ�á�Action/sfx�� ��ʾʹ�ô˺�������Action��
2. Frame��¼�Ʋ���ʱ���ڵ�Frame�����ơ�
3. TargetFrame��ResourceByteLimit����List of Attributes��ͬ��������
4. Ordinal���μ�Web_link��ͬ��������
VuGenͨ����¼������Ψһ�ı�ʶÿ��Form���������������ʶ��Form��VuGen���¼Action ���ԡ������������ʶ������¼Ordinal ���ԣ���������²����¼Action���ԡ�
List of Hidden Fields���������ԣ�Serves���� ͨ�������Կ���ʹ��һ������������ʶForm��ʹ������ĸ�ʽ��
STARTHIDDENS,
"name=n1", "value=v1", ENDITEM,
"name=n2", "value=v2", ENDITEM,
ENDHIDDENS,
List of Data Fields
Data��������ʶform��Form��ͨ�����Ժ���������ͬʶ��ġ�
ʹ������ĸ�ʽ����ʾ�������б�
"name=n1", "value=v1", ENDITEM,
"name=n2", "value=v2", ENDITEM,
ITEMDATA��Form�����ݺ����Եķָ�����
EXTRARES��һ���ָ����������һ����������Դ���Ե��б��ˡ�
List of Resource Attributes���μ�List of Resource Attributesһ�ڡ�
LAST�������б������ı�Ƿ���
˵��
web_submit_form. ���������ύ�������˺������ܱ�����ǰһ����������������ִ�С���Toos��Recording Option��ֻ��¼�Ƽ�����Ϊ����HMTL��¼�Ʒ�ʽ��web_image�Żᱻ¼�Ƶ�����¼��ѡ���У�Toos��Recording Option�£�Recordingѡ���У���һ��Advanced HTMLѡ����������Ƿ�¼�Ʒ�HTML��Դ��ֻ��ѡ���ˡ�Record within the current script. step��ʱ��List of Resource Attributes�Żᱻ¼�Ƶ�����HTML��Դ��������gif��jpgͼ���ļ���
ͨ������£����¼����web_submit_form. ������VuGen��ѡ�name���͡�value��һ��¼�Ƶ�ITEMDATA�����С���������ڽű�����������ʾ��value�������Զ������м��ܡ��ѡ�Value����Ϊ��EncryptedValue��,Ȼ���¼�Ƶ���ֵ��Ϊ���ܺ��ֵ��
���磺���� "Name=grpType", "Value=radRoundtrip", ENDITEM
����"Name=grpType", EncryptedValue=409e41ebf102f3036b0549c799be3609", ENDITEM
����������İ�װ��LoadRunner����ô��ʼ�˵�--Mercury LoadRunner��Tools--Password Encoder�����С���������������ַ����ġ�����Ҫ���ܵ�ֵճ����Passwordһ�����ٵ�Generate��ť�����ܺ���ַ����������Encoded string���С����ŵ�Copy��ť��Ȼ�����ճ�����ű��У�����ԭ����ʾ�ġ�Value����
���ܵ���һ�ַ���ʱʹ��lr_decrypt������������ѡ�������ַ��������硰Value=radRoundtrip����ע�ⲻҪѡ�����ţ����һ���꣬ѡ��Encrypt stringѡ�֣��ű����Ϊ��
"Name=grpType", lr_decrypt("40d176c46f3cf2f5fbfaa806bd1bcee65f0371858163"), ENDITEM,
web_submit_form֧��Web�����û�����֧��WAP�����û���
���ӣ�
����������У�web_submit_form. �����������ǡ�employee.exe�����˺����ύ��һ������,�����������Ա��ϢJohn Green���˺���û��ʹ�����ԣ�Attributes������Ϊͨ���������Ѿ���Ψһ�ı�ʶ���Form�ˡ�web_submit_form("employee.exe",
ITEMDATA,
"name=persons", "value=John Green - John", ENDITEM,
"name=go_page", "value=Go to Page", ENDITEM,
LAST);
web_submmit_data
���
Int web_submit_data ( const char *StepName, <List of Attributes>, ITEMDATA, <List of data>, [ EXTRARES, <List of Resource Attributes>,] LAST );����ֵ
����LR_PASS��0�������ɹ���LR_FAIL��1������ʧ�ܡ�������
StepName���������ƣ�VuGen��������ͼ��ʾ�����ơ�List of Attributes��֧���������ԣ�
1. Action��Form�е�ACTION���ԣ�ָ�������Form�еIJ����õ���URL��
2. Method�������ύ������POST��GET��Ĭ����POST����
3. EncType�����뷽ʽ��
4. EncodeAtSign���Ƿ�ʹ��ASCIIֵ�Է��š�@�����롣Yes���� No��
5. TargetFrame��������ǰ���ӻ���Դ��Frame���μ�List of Attributes��ͬ��������
6. Referer��Mode���μ�List of Attributes��ͬ��������
ITEMDATA������������Եķָ�����
List of Data��
�������б������˱����ύ�����ݡ����ڴ��������������صģ������������������е�������ʹ��Form�ı��������֯������
�������б�����ʹ����������һ�ָ�ʽ��
"name=n1", "value=v1", ENDITEM,
"name=n2", "EncryptedValue=qwerty", ENDITEM,
EXTRARES���ָ����������һ������������Դ���Ե��б���
List of Resource Attributes���μ�List of Resource Attributes��
LAST��������Ƿ���
˵��
web_submit_data����������״̬�����������صı����ύ�����������ɱ�����GET��POST������Щ������Form�Զ����ɵ�������һ���ġ�������Щ����ʱ����Ҫ���������ġ���VuGen��Ϊ����URL��¼��ģʽ��������HTML��¼�Ʒ�ʽ����Recording Options��HTML Advanced �µ�A script. containing explicit URLs only ѡ�ѡ��ʱ��web_submmit_data�����Ż�¼�Ƶ���
���������URL��ѯ�ķ�ʽ��GET�������Dz��������巢�ͣ�POST���ķ�ʽ���˺�����ָʾ��Form�е���������η��͵��������ġ�
���VuGen����HTTP¼��ģʽ�£���ʱ��¼Web����ʱ��������˺��������ύFormʱ�����������web_submit_form������VuGenҲ������web_submit_data������
��¼��ѡ���У�Toos��Recording Option�¡�Recordingѡ���У���һ��Advanced HTMLѡ����������Ƿ�¼�Ʒ�HTML��Դ��ֻ��ѡ���ˡ�Record within the current script. step��ʱ��List of Resource Attributes�Żᱻ¼�Ƶ�����HTML��Դ��������gif��jpgͼ���ļ���
EncType���Ը���һ���������ͣ�ָ������Ϊ��Content-Type������ͷ��ֵ����ָʾ�˸��ݲ�������HTTP����ʱʹ�õı������ͣ�����URL-encoding����multi-part������������ĸ�ʽ��
1. ��EncType=application/x-www-form-urlencoded��
2. ��EncType=multipart/form-data�� ���κεġ�; boundary=�����ᱻĬ�Ϻ��Ե���
3. ��EncType=�� (�մ�������û�в����������ͣ���Content-Type��������ͷ��
�κζ��ڡ�EncType����ָ�����Ḳ��web_add_[auto_]header����ָ����Content-Type����ʡ���ˡ�EncType��ʱ���κ�һ��web_add_[auto_]header�������������á������û��ָ��EncTypeҲû��web_add_[auto_]header�������ҡ�Method=POST������application/x-www-form-urlencoded������ΪĬ��ֵ��ʹ�á���������£��������Content-Type����ͷ��
ContentType���ļ����ͱ�ʶ���������EncType���ǡ�multipart/form-data�������ϴ��ļ�ʱ����Ҫ�õ���ContentType��������ITEMDATA�е�Data�Ӿ���ָ���ˡ�File=Yes�������ļ�Ҳ�ڴ��Ӿ��У�ContentType�����ã���ʱ������Ϊͬһ���Ӿ��ֵ�����ݡ�
��������£���Content-Type���������ϴ��ļ�����չ���Զ����ɡ����磺
-----------------------------7d025e2b16b064e\r\n Content-Disposition: form-data; name="uploaded_file"; filename="D:\\temp\\a.txt"\r\n Content-Type: text/plain\r\n \r\n
������Σ����ڷ�������ij�����˵������ģ������ļ��������ɵġ�ContentType����һ������ȷ�ġ���ʱ��ͨ���ֹ�ָ��������Ĭ�ϵġ�ContentType�������ָ���˿�ֵ����ô��Content-Type��ͷ�����������ļ��С�
���û����ʾ��ָ����ContentType����ֵ�����ϴ����ļ�Ϊ��ʱ�������ļ���չ����ʲô����Ĭ��ʹ�á�application/x-unknown-content-type����Ϊ��ContentType����ֵ��
VuGen������ָ����ContentType�Ƿ���Ч��
ͨ������£����¼����web_submit_data ������VuGen��ѡ�name���͡�value��һ��¼�Ƶ�ITEMDATAһ���С���������ڽű�����������ʾ��value�������Զ������м��ܡ��ѡ�Value����Ϊ��EncryptedValue��,Ȼ���¼�Ƶ���ֵ��Ϊ���ܺ��ֵ����ο�web_submit_form����ص����ݡ�
���е�Web�����û���������HTTPģʽ�µ�WAP�û���������WSP�ط�ģʽ�µ�WAP�û�������ʹ�ñ�������
����
����������У�web_submit_data����ʹ��POST�����ύ��һ��������web_submit_data("default.aspx",
"Action=http://lazarus/flightnet/default.aspx",
"Method=POST",
"TargetFrame=",
"RecContentType=text/html",
"Referer=http://lazarus/flightnet/",
"Snapshot=t7.inf",
"Mode=HTML",
ITEMDATA,
"Name=grpType", "Value=radRoundtrip", ENDITEM,
"Name=lstDepartingCity", "Value=DEN", ENDITEM,
"Name=lstDestinationCity", "Value=LAX", ENDITEM,
"Name=txtDepartureDate", "Value=8/19/2003", ENDITEM,
"Name=txtReturnDate", "Value=8/19/2003", ENDITEM,
"Name=txtQuantity", "Value=1", ENDITEM,
"Name=radClass", "Value=1", ENDITEM,
"Name=radSeat", "Value=1", ENDITEM,
"Name=btnAvailableFlights", "Value=Next >", ENDITEM,
LAST)��
��������ӣ� web_submit_data����ʹ��POST�����ύ��2���ļ���
web_submit_data("Attachments",
"Action=http://barton.cottage@.Devonshire.uk/Attachments?YY=45434",
"Method=POST",
"EncType=multipart/form-data",
"TargetFrame=",
"RecContentType=text/html",
"Referer=http:///barton.cottage@.Devonshire.uk/Compose?YY=20435",
"Snapshot=t5.inf",
"Mode=HTML",
ITEMDATA, "Name=userFile0",
"Value=E:\\sense_sensibility\\Elinor.txt",
"File=yes",
"ContentType=text/html", // �������ı��ļ�Ĭ�ϵġ�text/plain�� ֵ��
ENDITEM,
"Name=userFile1",
"Value=E:\\sense_sensibility\\Marianne.jpg",
"File=yes",
ENDITEM,
LAST)��
web_custom_request
���
Int web_custom_request (const char *RequestName, <List of Attributes>,[EXTRARES, <List of Resource Attributes>,] LAST );
����ֵ
����LR_PASS��0�������ɹ���LR_FAIL��1������ʧ�ܡ�������
RequestName����������ƣ�VuGen��������ͼ����ʾ�����ơ�List of Attribute��֧�ֵ����������¼��֣�
1. URL��ҳ���ַ��
2. Method ��ҳ����ύ��ʽ��POST��GET��
3. TargetFrame��������ǰ���ӻ���Դ��frame�����ơ��μ�List of Attributes��ͬ��������
4. EncType���������͡�
5. RecContentType����Ӧͷ���������͡��μ�List of Attributes��ͬ��������
6. Referer���μ�List of Attributes��ͬ��������
7. Body�������塣�μ�List of Attributes��ͬ��������
8. RAW BODY���μ�List of Attributes��ͬ��������
9. BodyFilePath����Ϊ�����崫�͵��ļ���·���������������������һ��ʹ�ã�Body����������Body���Ի�Raw Body������BodyBinary��BodyUnicode�� RAW_BODY_START��Binary=1��
10. Resource��ResourceByteLimit��Snapshot��Mode���μ�List of Attributes��ͬ��������
11. ExtraResBaseDir���μ�List of Attributes��ͬ��������
12. UserAgent���û�����������һ��HTTPͷ�����֣�������ʶӦ�ó���ͨ����������������ֵ����û��ͷ������Ľ�����
���磺ͷ��Ϣ��User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)��ʶ�����Window NT�µ�IE�����6.0��������User-Agent��ֵ������������������������߷����������ͨ����һ��Ӧ�ó��������е�����ʹ����ͬ���û�������¼������Ϊһ������ʱ������ָ����Run-Time Setting��Browser Emulation��User Agent����������ô˵����ʹ����һ��������������У����п��ܻ��õ�ֱ��������������ķ���������������ActiveX�ؼ�����ͨ���������Ų�ͬ����������û��������ԡ�ָ����UserAgent����ʾ����һ���������������ָ�����ַ�����HTTPͷ��User-Agent:�� ʹ�ã���ijЩ����£���ͬʱ��Ӱ��طŽű�ʱ����Ϊ�����磬��ʹ����������棬����ָ����URL������Դ�ȵȡ�
LoadRunner���������ָ�����ַ����������������ֵ�Ƿ���ͬ��
13. Binary����Binary=1����ʾҳ���������е�ÿһ����\\x##��ʽ���ֵ�ֵ�������##������2��ʮ���������֣������ᱻ�滻Ϊ���ֽڵ�ʮ�����Ƶ�ֵ��
�����Binary=0����Ĭ��ֵ�������е��ַ�����ֻ�ǰ��������ֵ���ݡ�
��Ҫע��˫б�ܵ��÷�����C��������˫б�ܱ�����Ϊ��б�ܡ��������Ҫ���ֽڣ���б�ܿ�����Binary������1�������ʹ�ã����磬ʹ��\x20����\\x20���������Ҫ���ֽڣ���ôֻ��ʹ��\\x00������ ��Binary=1����\x00�����ϻᱻ�ضϡ�
14. ContentEncoding
ָ���������ʹ��ָ���ķ�ʽ��gzip����deflate�����б��루���磬ѹ��������Ӧ�ġ�Content-Encoding:�� HTTPͷ��ʹ�����һ���͡��������������web_custom_request��web_submit_data��
EXTRARES����������IJ���������List Of Resource Attributes�ˡ�
LAST ����β�ı�ʾ����
˵��
����ʹ���κη����������崴���Զ����HTTP����Ĭ�������,��VuGen��ʹ���������������û�����ʱ,�����ɴ˺�����ʹ��Add�Ի����ڽű�������,�һ����,����ֿ�ݲ˵����������ֹ�����˺�����Ҫָ�������HTTPͷ��Ϣ,��Ҫ����web_add_header����web_add_auto_header������
RecContentType���μ�List of Attributes��ͬ��������
EncType���������͡��˲�������һ���������ͣ�Content-Type����ָ������Ϊ�طŽű�ʱ��Content-Type������ͷ��ֵ������ ��text/html����Web_custom_request����������δ����������塣�������������ʹ���Ѿ�ָ���ı��뷽ʽ����ˣ����ָ���˲�ƥ��HTTP������ġ�EncType��,����������˵Ĵ���ͨ�����ǽ��鲻Ҫ�ֶ���¼��ʱ�ġ�EncType��ֵ��
�κζ��ڡ�EncType����ָ�����Ḳ��web_add_[auto_]header����ָ����Content-Type����ָ���ˡ�EncType=�� ����ֵ��ʱ�����������Content-Type�� ����ͷ����ʡ���ˡ�EncType��ʱ���κ�һ��web_add_[auto_]header�������������á������û��ָ��EncTypeҲû��web_add_[auto_]header�������ҡ�Method=POST�����ҡ�Method=POST������application/x-www-form-urlencoded������ΪĬ��ֵ��ʹ�á���������£��������Content-Type����ͷ��
������Recording Options--Recording --HTML-based script-- Record within the current script. stepѡ�ѡ��ʱ��List of Resource Attributes�Żᱻ���뵽�����С�
���е�Web Vusers ��������HTTPģʽ����Wireless Session Protocol (WSP) �ط�ģʽ�µ�WAP Vusers��֧��web_custom_request������
Using Binary Code
����ʹ������ĸ�ʽ��web_custom_request �����ġ�Body�������м���������ַ�����
\x[char1][char2]
ͨ��2���ַ�[char1][char2]����ʾʮ�����Ƶ�ֵ��
���磺\x24��ʾ16*2+4=36����������$�����ţ�\x2B�������ǡ�+�����š�
�������2���ַ���Ҳ������Ч��ʮ�������ַ���VuGen��ᵱ��ASCII�ı�����������Ҫע�⣬���ڲ���2���ַ���ʮ�����ƣ�Ҫ��ǰ�油0������ ��\x2������Ч��ʮ�����ƴ�����Ҫ��Ϊ��\x02����
ע������Ƶ�ֵ���ԡ�\\x�� ����ʽ�����ڽű��еģ�Ҳ����˵�ڡ�x�� ǰ����2����б�ܡ�������C���Ե�ת��������ġ����ǣ���ʹ��VuGen����web_custom_request ����ʱ��ֻ��Ҫ����һ����б�ܡ�
�����web_custom_request ��ʹ�ò��������������ʱֻ��Ҫ����һ����б���������ڲ����滻ʱ�Dz�����C���ת���ġ�
List of Attributes
FtpAscii����1��ʹ��ASCIIģʽ����FTP������"0" ʹ�ö�����ģʽ��TargetFrame�� ��ǰ���ӻ���Դ����Frame�����ơ�����Frame�����֣�������ָ������IJ�����
_BLANK����һ���մ��ڡ�
_PARENT�������¸��Ĺ��ĵ�Frame�滻Ϊ�����ϼ���
_SELF���滻���¸��Ĺ��ĵ�Frame��
_TOP���滻����ҳ�档
RecContentType��¼�ƽű�ʱ��Ӧͷ���������͡�����text/html�� application/x-javascript�ȡ���û������Resource����ʱ��������ȷ��Ŀ��URL�Ƿ��ǿɼ�¼����Դ������������Ҫ�ĺʹ�Ҫ����Դ����Ƶ��ʹ�õ������� text��application��image����Ҫ����������Դ��ͬ�仯�ܶࡣ���磺"RecContentType=text/html"����ʾhtml�ı���"RecContentType=application/msword"����ʾ��ǰʹ�õ���Msword��
Referer: ��ǰҳ�������ҳ�档����Ѿ���ʽָ����url�ĵ�ַ���������ʡ�ԡ�
Resource��ָʾURL�Ƿ�������Դ��1 �ǣ�0 ���ǡ����������������RecContentType���������ԡ���Resource=1������ζ�ŵ�ǰ���������ڽű��ijɹ�����ϵ������������Դʱ������������ǵ�����������Ǵ����������ģ�URL�Ƿ������ܡ�Run-Time Setting��Browser Emulation--Download non-HTML resources�� ���ѡ���Ӱ�졣�˲�������Ӧ��Ϣ�Dz���ΪHTML�������ġ���Resource=0����������URL����Ҫ�ģ����ܷ�������RTS����Ӱ�죬����ҪʱҲ���������
ResourceByteLimit��webҳ��������Դ�ļ���С�����ﵽ���õļ���������������Դ����������Ҫ���ص���Դ��Ч��
���ع��̣�����ܼ����ش�СС�ڼ���ֵ����������ʼ���ء����������ʱ�ﵽ�����õļ���ֵ����Դ��С��֪����HTTP��Ӧͷ��ָ����Content-Length������������£����ֻ��Ҫһ������������ô���ؿ���������ɡ������Ҫ�IJ�ֹһ����������������Դ��С����֪�����ؾͻ��ж�ͬʱ�رյ�ǰ���ӡ�
������Կ�������ģ���û����ȴ�һ��ҳ���������ʱ��������һ��ҳ��������
ResourceByteLimit ��HTTPģʽ����ʹ�ã���Concurrent Groups��Vuser�ű��е�һ�����������е����к�������ִ�У�����Ҳ��ʹ�á�����������Sockets�Ļطţ�WinInetҲ�Dz����õġ�
Snapshot�����յ��ļ���������ʱʹ�á�
Mode������¼�Ƽ���HTML��HTTP��
HTML�����ڵ�ǰWeb������¼��ֱ�۵�HTML��������һ������web_url��web_link��web_image��web_submit_form��¼����Щ������VuGen����¼�Ʒ���HTMLҳ������������ű���Ӧ�ó���
HTTP����VuGen�����е�����¼��Ϊweb_urlָ�������web_link��web_image��web_submit_form��Щ���������ַ�����Ϊ���������ɵĽű�����ֱ�ۡ�
ExtraResBaseDir��Ŀǰ��������web_custom_request����������URL������EXTRARES������������������URL�ģ����ӣ�������Windows�����·���;���·������
URL�����Ǿ���·��������http://weather.abc.com/weather/forecast.jsp?locCode=LFPO����Ҳ���������·�������硰forecast.jsp?locCode=LFPO������
������URL��������ͨ������·�����еģ��������URL·������ʹ�ø�·��URLȥ���������磬ʹ��http://weather.abc.com/weather/��Ϊ��·����������forecast.jsp?locCode=LFPO��������URL�ǣ�http://weather.abc.com/weather/forecast.jsp?locCode=LFPO�����û��ָ����ExtraResBaseDir����Ĭ�ϵĸ�URL����ҳ���URL��
Body��Ŀǰ��������web_custom_request�������������塣��ͬ��Ӧ���У�������ֱ�ͨ��Body��BodyBinary����BodyUnicode���������ݡ����������ֻʹ������һ��������Ҳ����ʹ��һ�����ķֿ��IJ�����ɶ������塣���磺
web_custom_request��
����
"BodyUnicode=REPRICE"
"BodyBinary=\\x08\\x00\\xCC\\x02\\x00\\x00"
"Body=.\r\n"
"-dxjjtbw/(.tp?eg:ch/6--\r\n",
LAST����
������Ĵ����У�ʹ����3�����������������壬һ����Unicode�Σ�һ���Ƕ����ƶΣ����һ���dz�����ַ��������յ�����������3�����������ں����е�˳������������ֵ��
����һ�������õ��IJ�����Binary����Ҳ�����������������壬��ֻ����������ֻ��һ�������������
���е������嶼��ASCII�ַ�����null������
Body����ʾ����ģ��ɴ�ӡ���ַ���������ʾ���ֽڡ����е��ַ�����һ����б�ܱ�ʾ��ע�⣺�ھɵĽű���,���Կ������ɴ�ӡ���ַ�������������16���Ʒ�ʽ���б��롣������ ��\\x5c����������������£�����ʹ�á�Binary=1������ʶ�����ֽ�ʹ��"\\00"����ʾ�� �෴���½ű����Ѱ�������ֿ����ڲ�ͬ�IJ����У�"Body=...", "BodyBinary=...", Body=..."����
BodyBinary ����ʾ�����ƴ��롣���ɴ�ӡ���ַ�������������16���Ʒ�ʽ\\xHH���б��롣������HH ��ʾʮ������ֵ�����ֽ�ʹ��"\\00"����ʾ��
BodyUnicode������Ӣ� ��ָ���� UTF-16LE��little-endian�����롣���ֱ��뷽ʽ������ÿ���ַ�ĩβ����һ��0�ֽڣ��Ա�ʹ�ַ����ɶ���������VuGen��ʵ�ʵIJ��������е�0�ֽڶ�ȥ���ġ������ڷ���Web ������֮ǰ, web_custom_request��������������0�ֽڵġ����ڲ��ɴ�ӡ���ַ�,ʹ�õ���б�ܱ�ʾ������ʾ���ֽڡ�
ע��:������������100K,��ʹ��һ������������Body�������������� lrw_custom_body.h�ж���ġ�
Raw Body��Ŀǰ��������web_custom_request������������������Ϊָ�봫�ݵģ���ָ��ָ��һ�����ݡ� �����Ƶ����������ʹ��BodyBinary ����������(����ʹ��Body ����������,ǰ���DZ�������"Binary=1" )���������,���ַ�����Ҫʹ��ת���ַ���б�ܰѲ��ɴ�ӡ���ַ�ת��ΪASCII�ַ���Ϊ������һ�ָ����ı���ԭʼ���ݵķ�ʽ��Raw Body����Ӧ�˶��������Դ���ָ����������ݵ�ָ�롣
ʹ��4�������IJ���������ʾָ�룬���ұ��밴��˳�����У�
RAW_BODY_START
ָ�����ݻ�������ָ��
��int�� ����
RAW_BODY_END
���ӣ�
char *abc= .../* a pointer to the raw data */
web_custom_request("StepName",
"URL=http://some.url ",
"Method=POST",
RAW_BODY_START,
"abc",
3,
RAW_BODY_END,
LAST);
��Ӧ���У���ʹ���������ݵij���Ϊ0��ָ��Ҳ������ֵ������Ϊ�ա�
�ڡ�Binary=1��ʱ������ʹ������������ԭʼ���ݡ�
���ݻ������е����ݲ���ʹ�ò�������Ҳ��ʱ˵���������е��κβ���(���� "{MyParam}")���ܱ���ȷ�����Ϊ��Ӧ��ֵ��ֻ��������ֵ���͡�
List of Resource Attributes
Webҳ���еķ�HTML���Ʋ�������Դ�б���������Javascript, ActiveX, Java applets and Flash���������Դ��VuGen's ��Recording ѡ���У��������ð���Щ��Դ¼���ڵ�ǰ�IJ����У�Ĭ���Ǵ����ã�������Ϊ�����IJ�����¼�ơ�֧��������Դ��
����ڰ�ÿ����Դ��¼��Ϊ�����IJ�����˵����¼�Ʒ�HTMLԪ��ʹ�ű����Ӽ�̺Ϳɶ����ر�����VuGen��Tree��ͼ�¸�Ϊͻ����
��VuGen¼�ƹ����з��ָ��ӵ���Դ������JS��ʱ�������б�����ʽ�ӵ�������Դ���С��طŽű�ʱ����Щ��Դ�ļ�Ҳ�������һ���֡����Զ�һЩ������仯����Դʹ�ù�����
-
�ȸ�Googleϵͳ�ܹ�
2010-03-09 16:40:04
ת�� http://www.ctoof.com/archives/1610
Googleϵͳ�ܹ����������Ͽ���˵�����ˣ�Googleһֱ��Ŀ����ǹ��������ܸ������ԵĻ�����֯��֧�����ǵIJ�Ʒ��
ƽ̨
Linux
ʹ�ô����������ԣ�Python��Java��C++
״̬
��2006���Լ��450,000̨���۷�������
��2005��Google������80��Webҳ�棬����û����֪����Ŀ��
Ŀǰ��Google�г���200��GFS��Ⱥ��һ����Ⱥ������1000��������5000̨��������ǧ����Ļ�����������5000000000000000�ֽڴ洢��GFS��Ⱥ��ȡ���ݣ���Ⱥ�ܵĶ�д���������Դﵽÿ��40���ֽڣ�
Ŀǰ��Google��6000��MapReduce������ÿ���¶�д�ɰٸ��³���
BigTable�����洢��ʮ�ڵ�URL������ǧǧ������ͼƬ�ͼ����û��IJ���ѡ����ջ
Google�������ǵĻ�����֯Ϊ����ܹ���
1����Ʒ����������棬email����ͼ����Ƶ�����죬���ͣ�
2���ֲ�ʽϵͳ������֯��GFS��MapReduce��BigTable��
3������ƽ̨��һȺ��ͬ������������Ļ�����
4��ȷ����˾������Dz�������������С��
5�����Ѹ����Ǯ�ڱ��ⶪʧ��־���ݵ�Ӳ���ϣ��������͵������ѽ��٣��������Ĵ洢����-�ȸ��ļ�ϵͳGFS(Google File System)
1���������������Դ洢���κγ���ĺ������ȸ��ļ�ϵͳGFS����Google�ĺ��Ĵ洢ƽ̨��
2��Google File System �C ���ͷֲ�ʽ�ṹ����־�ļ�ϵͳ��Google���������˴��������ݣ�
3��Ϊʲô����GFS�������������еĶ�������Ϊ�����Լ�����һ�в������ƽ̨���IJ�һ����Google��Ҫ��
-���������ĵĸ߿ɿ��ԣ�
-��ǧ���������ڵ�������ԣ�
-������������
-֧�ִ������ݣ�����Ϊ��ǧ���ֽڣ�
-��Ч�Ŀ�ڵ�����ַ�������ƿ����
4��ϵͳ��Master��Chunk������
-Master�������ڲ�ͬ�������ļ��ﱣ��Ԫ���ݡ�������64MBΪ��λ�洢���ļ�ϵͳ�С��ͻ�����Master���������������ļ�����Ԫ���ݲ��������ҵ������û���Ҫ���ݵ���ЩChunk��������
-Chunk��������Ӳ���ϴ洢ʵ�����ݡ�ÿ��Chunk��������Խ3����ͬ��Chunk�����������Դ������������������������һ����Master������ָ�����ͻ��˳���ͻ�ֱ�Ӵ�Chunk��������ȡ�ļ���
5��һ�����ߵ��³������ʹ�����е�GFS��Ⱥ���߿��������Լ���GFS��Ⱥ��
6���ؼ����������㹻�Ļ�����֯�������Ƕ��Լ��ij�������ѡ��GFS���Ե�������Ӧ������������ʹ��MapReduce����������
1���������Ѿ�����һ���ܺõĴ洢ϵͳ���������������˶�������أ�������������TB�����ݴ洢��1000̨�����ϡ����ݿⲻ�������������������ּ��Ѽ��������MapReduce���ֵ�ԭ��
2��MapReduce��һ�����������ɴ������ݼ��ı��ģ�ͺ����ʵ�֡��û�ָ��һ��map����������һ����/ֵ��������һ���м�ļ�/ֵ�ԣ�����һ��reduce�������ϲ����й�����ͬ�����м�����м�ֵ��������ʵ�����������ʹ������ģ�������֡������ַ����д�ij�����Զ����е���һ�����������ļ�Ⱥ�����С�����ʱϵͳ�չ��������ݻ��֡������ڻ�����֮��ִ�еĵ��ȡ�����ʧ�ܴ����ͱ�����ڲ�����������ϸ�ڡ�����������Աû�ж��ٲ��кͷֲ�ʽϵͳ�ľ���Ϳ��Ժ�����ʹ��һ�����ͷֲ�ʽϵͳ��Դ��
3��Ϊʲôʹ��MapReduce��
-��Խ���������ָ�����ĺ÷�ʽ��
-��������ʧ�ܣ�
-�����벻ͬ���͵ij�����������������档�����κγ�����map��reduce���͵IJ����������Ԥ�ȼ������õ����ݡ���ѯ����ͳ�ơ���TB����������ȵȣ�
4��MapReduceϵͳ�����ֲ�ͬ���͵ķ�����
-Master�����������û�����Map��Reduce����������Ҳ���������״̬��
-Map�����������û����벢��������ϴ���map���������д���м��ļ���
-Reduce����������Map�������������м��ļ�����������ϴ���reduce������
5�����磬����������Webҳ������������㽫�洢��GFS�������ҳ������MapReduce���⽫�ڳ�ǧ����̨������ͬʱ���в������еĵ������������ȡ�ʧ�ܴ��������ݴ��佫�Զ���ɣ�
-���������ڣ�GFS -> Map -> Shuffle -> Reduction -> Store Results back into GFS��
-��MapReduce��һ��map������һЩ����ӳ�䵽��һ���У�����һ����ֵ�ԣ������ǵ�����������ֺ�������
-Shuffling�����ۼ������ͣ�
-Reduction�����������м�ֵ�Ե��ۺϲ��������յĽ����
6��Google���������ܵ��д�Լ20����ͬ��map��reduction��
7��������Էdz�С����20��50�д��룻
8��һ�������ǵ����ߡ���������һ���������������ļ��㣬�������������������߿�����Ϊ������IO������ʱ��CPU����ʹ�ö�������������������ж��ͬ���ļ��㲢�ҵ�һ����ɺ�ɱ�����������ģ�
9��������Map��Reduce������֮�䴫��ʱ��ѹ���ˡ�����Խ�ʡ������I/O����BigTable��洢�ṹ������
1��BigTable��һ���������ԡ��������̡��Թ�����ϵͳ��������ǧǧ���ڴ��1000000000000000�Ĵ洢��������ÿ���Ӵ�������Ķ�д��
2��BigTable��һ��������GFS֮�ϵķֲ�ʽ��ϣ���ơ������ǹ�ϵ�����ݿ⡣����֧��join����SQL���Ͳ�ѯ��
3�����ṩ��ѯ������ͨ�������ʽṹ�����ݡ�GFS�洢�洢���������ݶ�������������нṹ�����ݣ�
4����ҵ���ݿⲻ�ܴﵽ���ּ���������Բ��Ҳ����ڳ�ǧ����̨�����Ϲ�����
5��ͨ�����������Լ��ĵͼ��洢ϵͳGoogle�õ�����Ŀ���Ȩ���Ľ����ǵ�ϵͳ�����磬����������ÿ��������ĵIJ�������������ԣ����ǿ����ڽ�����
6��ϵͳ����ʱ�����������ɵ���ɾ������ϵͳ���ֹ�����
7��ÿ��������Ŀ�洢��һ�������������ͨ��һ����key����key����ʱ��������ʣ�
8��ÿһ�д洢��һ������tablet�С�һ��tablet��һ��64KB����������в��Ҹ�ʽΪSSTable��
9��BigTable���������͵ķ�������
-Master����������tablet��������������tablet�����ﲢ�������Ҫ�����·�������
-Tablet������Ϊtablet������д����tablet������С����(ͨ����100MB-200MB)ʱ���Dz�tablet����һ��Tablet������ʧ��ʱ����100��Tablet������������ѡһ���µ�tabletȻ��ϵͳ�ָ���
-Lock�������γ�һ���ֲ�ʽ���������һ��tablet��д��Master�����ͷ��ʿ��Ƽ��ȶ���Ҫ���⣻
10��һ��locality����������������Ͻ���ص����ݴ洢��һ�����õ����õ�localityѡ��
11��tablet�����ܵĻ�����RAM�Ӳ��
1�������кܶ����ʱ��������֯������ʹ��ʹ�úͻ�����Ч��
2��ʹ�÷dz����۵�Ӳ����
3�����ʹ�ù��϶�Ļ�����ʩ������������������߳ɱ�����˽����ɿ��Ļ�����ʩ�ܹ�һ����Ҫ��ս�����⡣
4��Linux��in-house rack design��PC���壬�Ͷ˴洢��
5�������һ��������ߵ����⣬���������ȴҲ�Ǻܴ����⣻
6��ʹ��һЩcollocation��Google�Լ����������ģ�����
1��Ѹ�ٸ��Ķ����ǵȴ�QA��
2�����ǹ��������Խ��ʽ��
3��һЩ������Ϊ�����ṩ��
4��һ��������֯��������İ汾���������ǿ��Է��������ú��»��ƻ�ʲô������Google�����ķ���
1��֧�ֵ���λ�÷ֲ��ļ�Ⱥ��
2��Ϊ�������ݴ���һ��������ȫ�����ֿռ䡣��ǰ�������ɼ�Ⱥ���룻
3��������õ��Զ�������Ǩ�ƺͼ��㣻
4�������ʹ�����绮��������������ı���ʱ��һ��������(���籣�ַ���ʹһ����Ⱥ����ά��������һЩ�������)��ѧ���Ķ���
1��������֯���о����Ե����ơ��ر��Ƕ�Google���ԡ�Google���Ժܿ�����۵��Ƴ��·����������������˺��Ѵﵽ�����˾��ȡ��ȫ��ͬ�ķ�ʽ�����˾��Ϊ������֯����̫��Google��Ϊ�Լ���һ��ϵͳ���̹�˾������һ���µĿ������������ķ�ʽ��
2����Խ�������������Ȼ��һ��δ��������⡣����վ����һ��������������������ġ����Dz��ò�����������һЩ��������֮�������ķֲ���վ�Ǻ���Ҫ���ɵģ�
3��������Լ�û��ʱ����㿪ʼ���¹���������Щ������֯����Կ���Hadoop��Hadoop������ܶ�ͬ���������һ����Դʵ�֣�
4��ƽ̨��һ���ŵ��dz���������Ա������ƽ̨�Ļ����Ͽ��ٲ��ҷ��ĵĴ�����ȫ�ij������ÿ����Ŀ����Ҫ����ͬ���ķֲ�ʽ������֯�����ӣ���ô�㽫����������Ϊ֪��������������������Խ��٣�
5��Эͬ������һֱ�������ӡ�ͨ����ϵͳ�е����в���һ������һ�����ֵĸĽ����������еIJ��֡��Ľ��ļ�ϵͳ��ÿ���˴���������������ġ����ÿ����Ŀʹ�ò�ͬ���ļ�ϵͳ����������ջ�����ܲ����������ӵĸĽ���
6�������Թ���ϵͳ����û��Ҫ��ϵͳ�ػ�����������������ڷ�����֮��ƽ����Դ����̬���Ӹ�����������û������ߺ����ŵĴ���������
7�������ɽ����Ļ�����֯�����е�ִ������ʱ��IJ�������ȡ�Ϻõķ�����
8����Ҫ����ѧԺ��ѧԺ������û��ת��Ϊ��Ʒ�ĺ����⡣Most of what Google has done has prior art, just not prior large scale deployment.
9������ѹ��������������CPU��IO����ʱѹ����һ���õ�ѡ�� -
ʹ�þۼ������ͷǾۼ�����������
2009-12-02 15:07:45
ʹ�þۼ�����
�ۼ�����ȷ���������ݵ�����˳�ۼ����������ڵ绰�������ھۼ������涨�����ڱ��е������洢˳�����һ����ֻ�ܰ���һ���ۼ�������������������������У����������������绰�������Ϻ����ֽ�����֯һ����
�ۼ�����������Щ����Ҫ������Χֵ�����ر���Ч��ʹ�þۼ������ҵ�������һ��ֵ���к����ȷ��������������ֵ�������������ڡ�����ÿ�β�ѯ����ʱ���������Ӷ���ʡ�ɱ���
ע������
����ۼ�������ʱʹ�õ���Խ��Խ�á�
• �����������ظ�ֵ���С�
• ʹ���������������һ����Χֵ�IJ�ѯ��BETWEEN��>��>=��< �� <=��
• ���������ʵ��С�
• ���ش��ͽ�����IJ�ѯ��
• ������ʹ�����ӻ� GROUP BY �Ӿ�IJ�ѯ���ʵ��У�һ����˵����Щ������С��� ORDER BY �� GROUP BY �Ӿ���ָ�����н�������������ʹ SQL Server ���ض����ݽ���������Ϊ��Щ���Ѿ���������������߲�ѯ���ܡ�
• OLTP ���͵�Ӧ�ó�����Щ����Ҫ����зdz����ٵĵ��в��ң�һ��ͨ����������Ӧ�������ϴ����ۼ�������
�ۼ������������ڣ�• Ƶ�����ĵ��� ���⽫���������ƶ�����Ϊ SQL Server ���밴����˳�������е�����ֵ������һ��Ҫ�ر�ע�⣬��Ϊ�ڴ�������������ϵͳ����������ʧ�ġ�
• ���� �����Ծۼ������ļ�ֵ�����зǾۼ�������Ϊ���Ҽ�ʹ�ã���˴洢��ÿ���Ǿۼ�������Ҷ��Ŀ�ڡ�
ʹ�÷Ǿۼ�����
�Ǿۼ�������α��е�Ŀ¼���ơ����ݴ洢��һ���ط��������洢����һ���ط�����������ָ��ָ�����ݵĴ洢λ�á������е���Ŀ��������ֵ��˳��洢�������е���Ϣ����һ��˳��洢��������ɾۼ������涨��������ڱ���δ�����ۼ�������������֤��Щ�о����κ��ض���˳��
����Ǿۼ�����
��Щ�鼮����������������磬һ�������յ�����ܻ����һ��ֲ��ͨ��������������һ��ֲ��ѧ����������Ϊ���Ƕ��߲�����Ϣ��������õķ��������ڷǾۼ�����Ҳ����ˡ�����Ϊ�ڱ��в�������ʱ���õ�ÿ���д���һ���Ǿۼ�������
ע�������ڴ����Ǿۼ�����֮ǰ��Ӧ���˽�������������α����ʵġ��ɿ��ǽ��Ǿۼ��������ڣ�
• �����������ظ�ֵ���У������Ϻ����ֵ���ϣ�����ۼ��������������У������ֻ�к��ٵķ��ظ�ֵ����ֻ�� 1 �� 0����������ѯ����ʹ����������Ϊ��ʱ��ɨ��ͨ������Ч��
• �����ش��ͽ�����IJ�ѯ��
• ���ؾ�ȷƥ��IJ�ѯ������������WHERE �Ӿ䣩�о���ʹ�õ��С�
• ������Ҫ���Ӻͷ���ľ���֧��ϵͳӦ�ó���Ӧ�����Ӻͷ��������ʹ�õ����ϴ�������Ǿۼ����������κ�������ϴ���һ���ۼ�������
• ���ض��IJ�ѯ�и���һ�����е������С��⽫��ȫ�����Ա���ۼ������ķ��ʡ���������һ������ֻ�Ǿۼ�������������������е�����������ͬ��һ�µģ����Ǿۼ���������������������ݵ�����ͬ��
�������ڸ���ͳ����Ϣ��ʱ������Щ�ۼ������в���Ҫ��������ҳ��Ҫͬʱ�������������������������ԷǾۼ���������ֻ��Ҫ��������ҳ��
ת�أ�http://hi.baidu.com/yuleboxcn/blog/item/1a2464faf153ad6d034f5697.html
-
���ݿ���������ϸ˵��
2009-12-02 15:03:44
һ�����
�����Դ��������Ŷӳɹ��Ŀ����Ͳ�����һ��INTERNET��վ,�Ѿ���ȥ������,�����վ�ں̵ܶ�ʱ������������ǧ�û�ǰ��ע���ʹ��,���������һ���dz�����Ŀͻ��������������Ŷӡ������㡢�ͻ���ÿ���˶��dz����ˡ�
�������������һ����˳�ġ���վ����û���ʼ�վ�����������ʱ�������漴�����ˣ��ͻ������ʼ���ʼ��Թ��վ����̫����ͬʱ����վ���ڶ�ʧ�ͻ���
�����㿪ʼ�������ϵͳ���ܿ��㷢�ֵ�ϵͳ���ʻ�������ݵ�ʱ���ٶȷdz����������ݿ�һ�������ݿ�ļ�¼���ӵĺܿ죬��Щ���ļ�¼�ﵽ�˳�ǧ�����У������Ŷ��ڲ�Ʒ���ݿ�������һ�����ԣ���������ڲ��Է������Ͻ�2/3�������ɵ�һ���������̣�������Ҫ5���ӡ���
����������ϵĹ��·�����ȫ��Χ�ڵ�����ǧ�Ƶ�ϵͳ���ϡ����������ڣ�����ÿ��������Ա���������Ŀ��������л�����ͬ�������顣��֪��Ϊʲô���������λᷢ����ͬʱ��Ҳ֪�����ȥ�˷�����
���������Ķ���Χ
������ע�Ȿһϵ���������۵���Ҫ�Ľ����ǡ������Ե�SQLServer���ݿ����ݷ��������Ż����������Ż�����ͬ�����������������ݿ⡣
�����ҽ�Ҫ���۵��Ż�������������������������Ա����Ϊһ�������ߣ�����Ҫ�����ҹ�ע�����⣬ȷ�����Ѿ������������������飬ȥ�Ż����Ѿ�д�Ļ�Ҫд�����ݷ��ʴ��롣���ݿ������Ա(DBA)ͬ�����Ż�����������ϰ����˺���Ҫ�Ľ�ɫ������DBA�������Ż�����������ƪ�������۵ķ�Χ��
����������ʼ�Ż�һ�����ݿ�
�������������ݿ��Ӧ��ϵͳ������ʱ��99%�Ŀ�����ϵͳ�����ݷ��ʹ���û���Ż�������û��ʹ����õķ�ʽ����������Ҫ�ع˺��Ż�������ݷ���/�������̣����ϵͳ��ȫ�����ܡ�����������ͨ��һ��һ���ķ�ʽ��ʼ���ǵ��Ż�����
������һ���������ϲ�����ȷ������
������Щ�˿�������ʵʩ��ȷ�������Ƿ������ݿ��Ż����̵ĵ�һ������������Ϊ�����ݿ�Ӧ����ȷ�������ǵ�һλ�ġ�ԭ����2�㣺
����1.��һ����Ʒϵͳ�����ʹ���ںܿ��ʱ������߾����ܴ�����ܡ�
����2.�������ݿ���������Ҫ�����κε�ϵͳ�ģ���˲���Ҫ�κ����±���Ͳ���
��������㷢���е�ǰ�����ݿ�û�кܺõĴ����������㽨������������������ܵĿ���������Ȼ������������Ѿ������ˣ����ǽ�������IJ��衣
����ʲô������
�������������Ѿ�������ʲô�����������ǣ����Ծɿ����ܶ��˶�������̫�������������һ��Ū����ʲô���������뿴�����С���¡�
�����ܾ���ǰ����һ���ų�������һ���ܴ��ͼ��ݣ�����������ǧ�Ƶ�ͼ�飬ͼ�����ҵĴ��������ϡ���ˣ�һ���ж�����ͼ��Ա��Ҫһ��ͼ�飬ͼ��Ա����һ��һ���ļ��ͼ��,���Ƿ�ƥ�������Ҫ��ͼ�飬����û�и��õİ취������һ��������ͼ��������Ҫ����ͼ��Ա����Сʱ��ͬʱ����Ҳ���ò��Ⱥܳ���ʱ�䡣
[�⿴������һ��û�������ı������ڱ�������������ݵ�ʱ�����ݿ�������Ҫ����ȫ����������������صļ�¼���������������dz�����]
���������ߺ�ͼ��ÿ�춼�ڴ������ӵ�ʱ��ͼ��Ա�Ĺ���Խ��Խ���ء���һ�죬��һ����������ͼ��ݣ�����ͼ��Ա�ķ��صĹ�������������ÿһ�����ţ�ͬʱ��˳�����������ϡ����ҿ��Դ��еõ�ʲô�ô�?��ͼ��Ա�ʣ��Ǹ����ش�:������ж���ͨ������һ���������Ҫͼ�飬��ܿ���ܷ������ĸ�����ϴ���˰�������ŵ�ͼ�飬Ȼ�����������ϣ���ͬ���ܺܿ���ҵ���Ҫ��ͼ�顱
����[�����ž��������ݱ��ﴴ��һ������,������һ�����ﴴ����һ��������,ϵͳ�ʹ�����һ���ۼ�������,���еİ�����¼������ҳ����������ֵ���ļ�ϵͳ�н�������.ÿһ������ҳ�ڲ�Ҳͬ������������ֵ��������.����,���������ݿ������κ�һ�������е�ʱ��,�������ݿ������ʹ�þ۽������ҵ����ʵ�ҳ(�����ȷ������һ��),������ҳ����Ұ�������ֵ�ļ�¼(������ܷ���һ����)]
������������������Ҫ�ġ�,�˷ܵ�ͼ��Ա��ʼ������,���Ű����������ڲ�ͬ�������,��������һ���ʱ��������.������������ʱ��,�����˲���,������ּ������û���ʱ������ҵ�һ����.ͼ��Ա���˼���.
����[�������㴴����������������������.����,�����˾۽�����,��������ҳ�������ļ��ﰴ��������ֵ������.��һ��������Ӧ�ú���������,��Ϊ���ݽ���ֻ��ʹ��һ�е�ֵ��Ϊƾ֤������,����һ����ֻ�ܴ���һ���۽�����.����ͼ��ֻ��ʹ��һ���������������һ��.]
������һ��,���û�б���ȫ���,�ڽ�������ʱ����,�и�����û��ͼ��ı��,ֻ��ͼ�������,����ͨ��������Ҫͼ��,��ΰ���?������ͼ��Աֻ�ܰ��մ�1��N����������Ѿ���ŵ�ͼ��.���ͼ������67�������,��������Ҫ20����,������ͼ��û�б������ʱ��,�������ѵ�2-3��Сʱ.��ȷʵ��һ������.���Ǻͻ���30��ͨ����Ų���һ����Ƚ�����,,20�����Ծ���һ�����̵�ʱ��.����û�и��õİ취��?�����Ǹ����ߡ�
����[��������һ����Ʒ��,�����ֻ��һ��ProductID������û������������,���������ͬ���ᷢ��,����,��ʹ�ò�Ʒ������������ʱ��,��������ֻ�ܱ����ļ��������������������ҳ,û�������İ취.]
�����Ǹ����߸���ͼ��Ա:��Ϊ���Ѿ�������Ŷ�ͼ����������,�㲻��ʹ��������ƾ֤��������,����,�Ϻõķ����Ǵ���һ��������������֮��Ӧ�ı�ŵ�Ŀ¼������,�����Ŀ¼��,����ͼ�����ĸ˳������,��ʹ�ð�������ĸ���з���,����,�����������DatabaseManagementSystem�Ȿ���ʱ��,��ʹ�����еĹ�����ܷ����Ȿ��
����1.������Ŀ¼������D��,�ҵ��������������ͼ��.
����2.�õ��Ȿ������,Ȼ�������ȥ�����Ȿ��
������������һ����š�,ͼ��Ա����,������������һЩʱ�䴴����������Ŀ¼,ͨ��һ�����ٵIJ���,������ʹ����������ѯ������Ҫ1����,����30�������ı��,30���ñ��������.
����ͼ��Ա�뵽,��������ʹ��������ƾ֤������ͼ��,�������ߵ�����,������Ϊ���ߴ�����ͬ����Ŀ¼.�ڴ�������ЩĿ¼��,ͼ��Ա����ʹ����Щƾ֤��1�������ҵ�ͼ��.ͼ��Ա�ķ��صĹ������ڽ�����,�������Ҳ��Ϊ�ܿ�IJ��ҵ�ͼ����ۼ���ͼ���,ͼ��ݱ�ķdz���������.
����ͼ��Ա���ʼ�������Ŀ��ֵ�����,���½�����.
���������������ȷ�����Ѿ�������ʲô������,Ϊʲô���������Ҫ�Լ����ǵ��ڲ�����ԭ��,,����,������һ���Ѵ����۽������IJ�Ʒ��Products,��Ϊ��������������ʱ��,�漴�ʹ����˾۽�����������Ӧ����Productname�д���һ���Ǿ۽�����,һ��������������,���ݿ������Ϊ�Ǿ۽���������һ��������,������������Ŀ¼�����ղ�Ʒ������������ҳ������ÿ������ҳ����һ����Χ�IJ�Ʒ���ֺ���֮��Ӧ��ProductID�����Ե�ʹ�ò�Ʒ������Ϊƾ֤������ʱ�����ݿ��������Ȳ�ѯ��Ʒ���ֵķǾ۽��������������Ȿ�������productID��һ�����֣����ݿ������ʹ������ProductID�������۽����������Ӷ����õ���ȷ�Ľ����
�������Ĺ���ԭ��
������ΪB+�����м�Ľڵ����һ��������ֵ��ָʾ���ݿ����浱�Ӹ��ڵ�����һ������ֵ��ʱ����α���.�������һ���۽���������ҳ�ڵ�����������ҳ.����ǷǾ۽���������ҳ�ڵ������������ֵ����֮��Ӧ�ľ۽�����ֵ.
����ͨ�����������������Ҫ��ֵ����ת��Ŀ�����ݼ�¼���������ݿ�������˵���ѵ�ʱ���Ǻ̵ܶģ����ԣ������ݿ�Ӧ�������������������ݵļ�������.
������������еIJ���ȷ����ȷ������������������ݿ��
����ȷ�����ݿ��ÿ������һ������
������ô����ȷ��ÿ������һ���۽�������ͨ��������ֵ����������ҳͨ������˳�������ڴ����ϡ�����,�κ�ʹ�����������ݼ�������,�κ��������ֶε�����������ܷdz�Ѹ�ٵļ������ݡ�
��������Щ���ϴ����Ǿ۽�����
������������Ϊ����ƾ֤����
����������������������
����������Ϊ�⽡����
���������������
������ѡ������
����Xml����
����������һ���������������������
����CREATEINDEX
����NCLIX_OrderDetails_ProductIDON
����dbo.OrderDetails(ProductID)
�ڶ�����������ȷ�ĸ�������
�������ڣ����Ƿ��Ѿ������ݿⴴ�������е��ʺϵ�����?���裬��һ��Sales��(SelesID,SalesDate,SalesPersonID,ProductID,Qty)�����Ѿ������(ProductID)���������������ProductID��һ����ѡ�����У��κ���where�����ʹ��������(ProductID)�ļ������ݵ�SELECT��ѯ�������еķdz�����?
�����ԣ����û��������������������(����Ҫȫ������ҳ�ı���)��˵�����Ƿdz���ģ����ǣ����н�һ�������Ŀռ�.
���������Ǽ��裺Sales������10,000�����ݣ������SQL���ѡ��400�С�
����SELECTSalesDate,SalesPersonIDFROMSalesWHEREProductID=112��������������Ū���������ݿ�������ôִ��SQL����:
����1.Sales������ProductID��һ���Ǿ۽����������ԣ����Ȳ�ѯ�Ǿ۽������������ְ���ProductID=112����ڡ�
����2.����ProductID=112��ڵ�����ҳͬ��ͬ��Ҳ�����˾۽�������ֵ(���е�������ֵ����SalesID)
����3.����ÿһ������(��400��)�����ݿ��������۽���������������ȷ���е�λ��
����4.����ÿһ��������һ��������ȷ���е�λ�ã����ݿ�������ƥ����еõ�SalesDate��SalesPersonID���е�ֵ��
������ע�⣬�������IJ����У�����ÿһ��ProductID=112���������(��400��)�����ݿ�������������۽�������400�Σ����������ӵ���(SalesDate,SalesPersonID)��
�����Dz���һ��,����Ǿ۽��������������˾۽�������ֵ(����)��ͬʱ��������ѯ���ע��������2����(SalesDate,SalesPersonID)��ֵ�����ݿ�����Ͳ���ִ�������ĵ�3���͵�4����ֻ�����ProductID���еķǾ۽���������������ҳ�϶�ȡ3���е�ֵ���������е��ٶȲ��Ǹ�����?
�������˵��ǣ���һ�ְ취��ʵʩ�����ص㣬����Ǹ���������������ڱ������ϴ�������������������Щ���Ǻ;۽�����һ���Ӧ�ø��Ӵ洢���С�������һ���ڱ�Sales������ProductID�����������������ӡ�
����CREATEINDEXNCLIX_Sales_ProductID--Indexname
����ONdbo.Sales(ProductID)--Columnonwhichindexistobecreated
����INCLUDE(SalesDate,SalesPersonID)--Additionalcolumnvaluestoinclude������ע�⣬������������Ӧ���������������У�������Щ�о�����select��ѯ��ʹ�á��ڸ������������̫����в�������������̫��ô�����������ʹ���൱����ڴ����洢�����������е�ֵ���������ڴ���������ܽ��͡�
��������������������ʱ����ʹ��DatabaseTuningAdvisor(���ݿ��Ż�����)�İ�����
��������֪����һ��һ��SQL��ʼ���У�SQLSERVER�����Ż����������¼��㶯̬�IJ�����ͬ�ļ����ƻ���
����������
����ͳ��
���������仯
����TSQL�IJ���ֵ
�����������ĸ���
��������ζ�ţ�����һ�������SQL��䣬�ڲ�Ʒ�������ϵ�ִ�мƻ����ܺ��ڲ��Է������ϵ�ִ�мƻ�������ͬ���������������ṹһ������ͬ��Ҳ������һ���ڲ��Է������ϴ������������ܻ���ٲ��Է������ϵ����ܣ������ڲ�Ʒ�������ϵ�ͬ�����������ܲ���������κ��洦��Ϊʲô?��Ϊ�ڲ��Ի����µ�SQLSEVVERִ�мƻ�����ʹ�ô�������������˸���ܺõ����ܣ����ǣ��ڲ�Ʒ�������ϵ�ִ�мƻ����ܳ������е�ԭ���������ʹ���´��������������磺һ���Ǿ۽��������ڲ�Ʒ�������ϲ��Ǹ�ѡ�����У����ڲ��Է��������Ǹ�ѡ������.
�������ԣ�������������ʱ��������ҪŪ������һ�㣺������ִ��������������ٶȵġ��������Ǹ����ȥ����?
�����������DZ����ڲ��Է�������ģ���Ʒ�������ĸ��أ����Ŵ����������Լ��������ǡ�ֻ���������ڲ��Է���������������ܵ����������ܸ��п����ڲ�Ʒ��������������ܡ�
������ô��Ӧ�ú����ѣ������˵��ǣ�������һЩ���õĹ���ȥʵ����������������ָ����
����1��ʹ��SQLprofiler�����Ʒ�������ϵĺۼ���ʹ��Tuningtemplate(��֪�������˽��鲻Ҫ�ڲ�Ʒ��������ʹ��SQLprofiler,����Щʱ���㲻�ò��ڲ�Ʒ��������������������ʱ��ʹ����)������㲻��Ϥ������ߣ����������˽����Ĺ���SQLprofiler��֪ʶ�����Ķ�http://msdn.microsoft.com/en-us/library/ms181091.aspx
����2.������һ�������ĸ����ļ��������ݿ��Ż������ڲ������ݿⴴ�����Ƶĸ���,���Ż����ʵõ�һЩ���飬�ر��Ǵ��������Ľ��飬��ܿ��ܴ��Ż����������ñȽ�ʵ�ʵĽ��顣��Ϊ�Ż�����ʹ�ò�Ʒ�����������ĸ����ļ���װ�ز��Է������������ܲ�������ܺõ��������顣����㲻��Ϥ�Ż����ʹ��ߣ����������˽����Ĺ���ʹ���Ż����ʵĵ����ϣ����Ķ���http://msdn.microsoft.com/en-us/library/ms166575.aspx.
���������������Ƭ����������������
�����������������Ѿ��ڱ��ﴴ����������ȷ�����������ǣ�����ܻ�û�л����ϣ�������õ����ܡ�ʲôԭ����?��һ�ֿ����dz�����������Ƭ��
����1��ʲô��������Ƭ
����������Ƭ������һ�����Σ������ڱ�������IJ��롢�ġ�ɾ��������ʹ����ҳ���ѡ�����������˸ߵ���Ƭ�������������һ�������ɨ��������Ҫ���Ѻܶ��ʱ�䣬��һ��������ڲ�ѯ��ʱ������������ʹ������,���ᵼ�����ܽ��͡�
������2�����͵���Ƭ��
�����ڲ����飺��������ҳ������ݲ�����IJ�������������������Ϊϡ��������ʽ�ķֲ����������⽫��������ҳ�����ӣ��Ӷ����Ӳ�ѯʱ�䡣
�����ⲿ���飺��������/����ҳ�����ݲ�����Ķ���������ҳ���������ļ�ϵͳ�ﲻ������µ�����ҳ�ķ�������������ݿ��������������Ԥ���������ŵ㣬��Ϊ����һ�������������ҳ���ٽ���������Щ������������ҳ������������ļ����κεط���
����2�����֪�����������Ƿ��Ѿ�����?
���������ݿ�ִ�������SQL���(����������SQLserver2005���Ժ�İ汾���������������Ŀ�����ݿ������ȡ��AdventureWorks��)
����SELECTobject_name(dt.object_id)Tablename,si.name
����IndexName,dt.avg_fragmentation_in_percentAS
����ExternalFragmentation,dt.avg_page_space_used_in_percentAS
����InternalFragmentation
����FROM
����(
����SELECTobject_id,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent
����FROMsys.dm_db_index_physical_stats(db_id('AdventureWorks'),null,null,null,'DETAILED'
����)
����WHEREindex_id<>0)ASdtINNERJOINsys.indexessiONsi.object_id=dt.object_id
����ANDsi.index_id=dt.index_idANDdt.avg_fragmentation_in_percent>10
����ANDdt.avg_page_space_used_in_percent<75ORDERBYavg_fragmentation_in_percentDESC��������Ľ��������ܷ��������������������Ƭ��Ӧ������Ĺ���
����ExternalFragmentation��ֵ>10��Ԥʾ��Ӧ�����������ⲿ��Ƭ��InternalFragmentation��ֵ<75��Ԥʾ��Ӧ�����������ڲ���Ƭ
����3��������������������Ƭ
������2�ַ�ʽ��
�����������飺ִ����������
����ALTERINDEXALLONTableNameRECOGNIZE
���������ؽ���
����ALTERINDEXALLONTableNameREBUILDWITH(FILLFACTOR=90,ONLINE=ON)
����ͨ��ʹ�þ������������ִ���ALL,����������ؽ���������������Ҳ����ʹ�����ݿ����̨���ؽ�/��������
����

����4��ʲôʱ��������ؽ�����?
�������ⲿ��Ƭ��ֵ��10-15���ڲ���Ƭ��ֵ��60-75��������������������Ӧ������������������Ӧ���ؽ�������
�������������ؽ���һ����Ҫ�������ǣ�һ����һ���ض��ı����ؽ����������ͻᱻ����(�����ʱ�ᷢ��)�����ԣ�����һ����Ʒ���ݿ��һ����ı�����Ϊ��һ������ϵ������ؽ�������Ҫ��������Сʱ�����Dz�ϣ���������������˵��ǣ���SQL2005��һ�������������������ؽ�һ������������ʱ��ONLINEѡ���ֵ��ΪON��������ʹ�ؽ������ͱ��ϵ���������ͬ�����С�
�����ġ�ʵ�����ݷ��ʽ�����
���������ݱ���������ʺϴ����������ֶ��ϴ������������Ƿdz��ջ��˵ġ�������������ڴ���һ���������ݿ������ÿ���ֶ��ϴ�������������ÿ�ζ�����Ҫ�ġ���ʵ�ϣ���һ��OLTPϵͳ�ϴ����������������ܻή�����ݿ�����ܡ�(��Ϊ���ܶ�����Ǹ��²�����ʱ����������ζ�Ÿ�������)
����һ����Ҫ�Ĺ��������£�
����������ڴ���һ�����������ݿ⣬ƽ����Ҫ��һ�����ϴ�������5�����������⣬������ڴ������ݲֿ⣬ƽ����߿���һ�����ϴ���10��������
ת�أ�http://hi.baidu.com/yuleboxcn/blog/item/dd0c4dd1bbf96f87a1ec9c54.html -
���⻯���� VMotionʵʱǨ�����
2009-07-20 12:08:12
ת�ص�ַ��http://smb.pconline.com.cn/zxpc/0906/1693468.html��
�����⻯���ڸı����ǶԼ��������ʶ��˵�����⻯��VMotion�����Ǹ���ӡ����̵���������е�һ����VMware��˾һֱ�����⻯������ռ�����ȵĵ�λ�����VMware VMotion�ͺ���վ����VMware������˵ļ����һ������ʵʱǨ�Ƽ����������ڸ߷�֮�ۡ�
VMware VMotion����
����VMware VMotion�ܹ�����̨�������е�������֮�����ʵʱǨ�ƣ�������ͣ�����ܣ��ܹ����������˷������Ŀ����ԣ���֤�������ݵ������ԡ�VMotion�Ǵ�����̬���Զ��Ż��������ĵĹؼ����أ������Ʒ��������⻯���洢�����⻯���������⻯�ȼ��������ش��Ӱ�졣

VMware VMotion��Ǩ��ʾ��ͼVMware VMotion�Ĺ���
�������ڷ���������Ա��˵��VMotion��������Ա��1������Դ���в��ϵ��Զ������������2���ڲ��ж�ҵ������������½��и���ά�������Ӷ�������������ߵĿ����ԡ�
���������û���˵��VMotion�����û���1���Զ��Ż��ͷ�����Դ�⣬�Ӷ����������Ӳ���������ʣ�����ԺͿ����ԡ�2�����ж��ڵ�Ӳ���豸ά����������ȴ����ҪԤ���趨ͣ��ʱ�䡣3���ڷ������������ϻ��߱��ֲ���֮ǰ������Ǩ�ơ�
VMotion�����õļ���
����VMotion��һ̨�����������������Ǩ�Ƶ�����һ̨�����Ҫ�õ������������
����1. �������ȫ��״̬��Ϣ��ѹ����һ�״洢�ڹ����洢�����ļ��С���Ϊ����Ĵ洢�����Ϳ����ǹ���ͨ����Fibre Channel����iSCSI�洢�������磨iSCSI Storage Area Network��SAN���������總�Ӵ洢����Network Attached Storage��NAS����VMware��Ⱥ�������ϵͳ��VMFS��������̨ESX������ͬʱ����ͬһ��������ļ���
����2. ������Ķ�̬�ڴ��ִ��״̬��һ�����ٵ������Ͻ��п��ٴ��䣬�����������ʱ����ԴESX��������Ŀ��ESX������֮�������Ϣ��������Ǩ�ƹ����У�VMotionֻ���ڵ���ͼ�����Ϣ�������м�أ���������ת�ƹ��̶��û���˵�����ġ�һ�������ڴ��ϵͳ״̬ȫ�����Ƶ�Ŀ��ESX�������У�VMotion�ͻ��Զ���ֹԴ�������ͬʱ������ͼת�Ƶ�Ŀ��ESX�������У�����Ŀ��ESX�������������������������������������������һ��ǧ����̫�����н���,��ô���������ʱ��Ϳ�����ɡ�
����3. �����ʹ�õ�����ͬ��Ҳ�ᱻĿ��ESX���������⻯��ȷ����ʵʱǨ��֮����������������ݺ������ܹ��õ�������VMotion��MAC��ַ��Ϊ���̵�һ���������й�����һ��Ŀ��������VMotion��������·������ȷ������ʶ�������MAC��ַ�µ�����λ�á����������ʹ��VMotion������ʵʱǨ�ƣ�����ִ��״̬���������ݺͶ�̬���Ӷ��ܹ��õ����������Զ����û���˵������Ǩ�ƹ��̲�û�����������ͣ�����������жϡ�
VMware VMotion�Ĺؼ��ص�
�����ɿ��ԣ��Դ�2004���Ƴ��˸ò�Ʒ֮���ڳ�ǧ������û���֧���£�VMotionһֱ���ϵ�Ϊ��ɿ���ʵʱǨ�����ܵ�������
�����߿����ԣ������û������쵽ʵʱǨ���������ķ�������ͣ����CPU��������Դ���������ȷ����ʵʱǨ��Ѹ�ٺ���Ч�ؽ��С�
�����������ԣ����������������ʲô����ϵͳ�ϣ�ʵʱǨ�ƶ��������κ����͵�Ӳ���豸�������Ͻ��У�ֻҪVMware ESX������֧�ָ��豸�����硣֧���ɹ���ͨ�����ӵĴ洢�������磨SAN����ʵ�е�ʵʱǨ�Ƶ���������ô����ߴ�4GB�Ĺ���ͨ�����ӵĴ洢��������ϵͳ��SAN����
����֧�����總���洢��NAS����iSCSI�Ĵ洢�������磨SAN����ʵ��ʵʱǨ�Ƶ���������Ѹ��͵ijɱ���ʹ�ø��������Ĵ洢�������Զ����CPU���������á�ȷ������������ڲ�ͬ�汾��Ӳ���豸�Ͻ���Ǩ�ƣ��Ա������������Զ�������µ�CPU�����˳�֮�С�
�����ײ�����Ǩ����ͨ��Ǩ�����ṩ�ļ�ʱ��Ϣ������Ϊһ̨��������ٱ����õ�ת�ƶ���
�����������Ǩ�ơ�������IT���������У����ж������Ǩ�ƣ����������ϵ��Ż�������IJ��֡�
�������ȵȼ���Ϊÿһ��ʵʱǨ�Ʋ�������һ�����ȵȼ���ȷ����ǰ����Ҫ���е�Ǩ�ƿ��Լ�ʱ������������Ҫ����Դ��
��������Ǩ��������ÿ��Ԥ���õ�ʱ����ϣ�����Ҫ����Ա�ڳ�������Ǩ�ƾ��ܹ��Է����С�
����Ǩ�Ƽ���١�ÿ��Ǩ�ƶ���һ����ϸ�IJ������棬��������/ʱ����������ʼ��Ǩ�ƵĻظ���Ϣ��
VMotion�ľ������
����ʹ��VMotion����ʵʱǨ������������ڲ��жϹ������̵�����½��С������������״̬��Ϣ��ͬ���������ļ����ᱻǨ�Ƶ��µ������ϡ�Ȼ����֮�����ӵ�������̽��ᱣ���������������Ĵ洢���С����������״̬��Ϣȫ��Ǯһ���滻��������֮��������Ϳ������µ������������ˡ�
������ҪǨ�Ƶ�״̬��Ϣ������ǰ���ڴ������Լ������ܹ������ʶ������������Ϣ�����У��ڴ���Ϣ�����������ݣ�����ϵͳ��λ���Լ��洢���ڴ��е�Ӧ�ó���������Ķ����ʶ����Ϣ��������ӳ�䵽�����Ӳ���ϵ����ݣ�����BIOS���豸��CPU�� ������MAC��ַ ��оƬ������״̬�ȡ����⣬��Ϊ�滻���������������������Ҫ��
����ʹ��VMotion������ʵʱǨ��һ��Ҫ���������������裺
1. ��VMotion�յ�ʵʱǨ�Ƶ�����ʱ��vCenter�������ͻ��鵱ǰ�����ϵ�������Ƿ����ȶ���״̬��
2. ����VMotionͨ����ʵʱǨ��������ô�����������״̬��Ϣ�������ڴ棬ע������������ӣ��ͻᱻ���Ƶ�Ŀ�������ϡ�
3. ��Ϣ�������֮������������µ�����������������Ͷ��������

VMware VMotion�����������������Ǩ�ƹ����з����˴�����ô����������Զ��ָ���ԭ����״̬��λ�á�

VMware VMotion������ʾ����vSphere 4�е�VMotion
�������գ�VMware��������һ�����������⻯���������Ʒ������VMware Infrastructure 3��ΪVMware vSphere 4���������VMware���ڷ��������⻯�Ѿ���һ�����⻯�Ļ���ƽ̨������һ�������⻯�����������������ġ�VMotion��vSphere 4��Ҳ�õ��˺ܴ�ĸĽ��������Ե��ص�����ܹ���һ̨�������е��������һ̨����ESX������Ǩ�Ƶ�һ̨����ESX�����ϡ�

����ESX����������ESX����֮���Ǩ��������ESX 3.5������vSphere 4�Ĺ����У�ESX 3.5��VMotion���Բ���Ҫ���κθı��Ҳ��������vSphere 4�����ǣ����ʹ�õ��Dz�ͬ�Ĵ�����оƬ�����һ���Ҫ������̫�������ӣ�EVC������ô����Ҫ��һ��С�䶯������EVC�����ӿ��ܻ�����ͣ����Σ�ա����⣬vSphere 4��VMotionȴ������ESX 3.5�汾��������
Storage VMotion
����Storage VMotion����ֻ������ESX 3.5��vCenter 2.5�Լ����ϰ汾����ESXϵ�е�һ����Ҫ�ĸĽ����ܵ��˿��ܻ���ΪStorage VMotion��VMotion�е�һ��ܣ���ʵ�ϲ�����ˣ�������ʵ�Dz��еġ�VMotion��Ե��Ƿ��������������Ǩ�ƣ���Storage VMotion��Ե���������д洢��Ϣ��Ǩ�ƣ���Ҫ���ƶ�������ĸ�����Ŀ¼�������ļ���vmx������־�������ļ���VSWP�������գ����̻�����Ӳ����vmdk��������ϵͳ���̣��������Լ����и����������ص��ļ���

Storage VMotion����ʾ��ͼStorage VMotion������Ҫ��
����Storage VMotion������Ҫ��Ҫ��VMotion�ϸ�öࣺ
������װ����VMware VMotion ����֤��VMware vCenter��VMware VMotion��ESX�������ϱ��뱻����ҽ������ʵ������ã����Բο�VMware����Ա����ָ�ϣ���
����1. ���������ʹ���κ�VMotion���õ��豸���������̣�CD-ROM����
����2. Storage VMotion����Ҫ��һ��Ҫ�������������硣
����ESX����������ӵ���㹻����Դ�����Storage Vmotion������������
����������Ĵ��̱���ͨ�����Ҽ�������һ���Ӵ��̣�������ԭ�д��̵����ݸ��Ƶ��µĽڵ��ϡ����û������ܣ�Storage VMotion��������������
����ESX�����������ܹ�����Ա��������Ŀ��������Ĵ洢����
����Storage VMotionһ����������ͬһ�����ݴ洢����ͬʱִ���ĸ�Ǩ�Ʋ�����
����ֻ֧�ֹ���ͨ����iSCSI�洢���С�
���������Ҫ��Storage VMotion�������ڲ����������������������ӡ�
���������Ҫ��Storage VMotion���ܸ������������Ⱥ����ϵ���ر���ʹ����Ⱥ������������SunȺ������ʱ��
������ͬһ̨������ϲ�����ͬʱʹ��Storage VMotion��VMotion��һ̨����������ݴ洢���ı�����ʹ��Storage VMotion���Ƶ�Ŀ��������Ĵ洢���С�Ȼ��������ſ���ʹ��VMotionǨ�Ƶ�Ŀ��ESX�������ϡ����ߵ�Ǩ��˳��û�����ơ�
Storage VMotion�IJ�������
����1. ����������ĸ�����Ŀ¼���µĽڵ㡣�������ʹ�ý���������ͨ�ż�����NFC�������������ļ����Ƶĵ��µĽڵ��ϡ�

�������Ŀ¼��������2. ����Ǩ�ƣ�Self-VMotion�����µ��������Ŀ¼�ϡ�Self-VMotion�Ľ��̸�������VMotion��һ���ġ���һ��ʹ���µ�ת���ļ��������´����������ļ�����������������ļ��Լ��������Ƶ��ļ���

����Ǩ��3. �Դ��̽��п��մ�������һ���贴����һ���Ӵ��̣�������¼��������������ϵı仯��

�Ӵ��̵Ĵ�������4. ������������̵�Ŀ���������

��������̵Ŀ�������5. �������Ĵ������Ӵ������Ͻ����������С�

�Ӵ��̵Ľ������6. ɾ��ԭ�����������Ŀ¼�ʹ��̣������µĿ������̵�״̬����Ϊ�ɶ���

�Ƴ�Դ�����vSphere 4�е�Storage VMotion
������vSphere 4�п���ʹ��ͼ���û����棨GUI��������Storage VMotion����������������Ϊ���ӻ��IJ����������÷dz���Storage VMotion�����й��ܶ�������vCenter�У�����Ҫ�κ��ⲿ�����

Storage VMotion�������������ڵ�һ��������ѡ�������ݴ洢��Change datastore����ֵ��ע����ǣ�ѡ��һ�����������֮���VMotion��ѡ����ֻ����������ĵ�Դ���Ͽ�֮��ſ��á�

Storage VMotion������������ѡ����ʵ����ݴ洢������Ǩ�������Ϣ�����ҵ��������

Storage VMotion������������ȷ��ǰ�ѳɹ�֮��ѡ��������Ҫ��ѡ���һ��ѡ�����������������֮ǰ�����á��ڶ���ѡ���ǽ���thin provisionedģʽ�������һ����next������ʼ����Storage VMotion���������ڹ���Ա��˵��������ܿ��Դ��ؼ�Storage VMotion�Ľ��̡�
-
Adslè+Dlink����·������
2009-06-18 23:46:25
è��·�ɺ�è�ڵ�DHCP�ص���ֱ�����ú�·��Ϊ��̬IP���������ú�·��dlinkΪ��̬ip��
�������ã�
èip��192.168.1.1
·�����������ã�IP��ַ��192.168.1.2
�������룺255.255.255.0
ȱʡ���أ�192.168.1.1��·����Ϊè���¼��豸��������Ϊè��IP��
·����������ΪèIP��192.168.1.1
·�����������ñ��ֲ��䣨·����IP��DHCP�����ã����������IP��ȫ���Զ���ȡ�Ϳ���
��������
�ҵĴ浵
����ͳ��
- ������: 108231
- ��־��: 57
- ����ʱ��: 2007-12-14
- ����ʱ��: 2011-07-07
