
-
http_load的安装和使用
2013-01-29 10:10:40
http_load以并行复用的方式运行,用以测试web服务器的吞吐量与负载。但是它不同于大多数压力测试工具,它可以以一个单一的进程运行,一般不会把客户机搞死。还可以测试HTTPS类的网站请求。
下载:http://acme.com/software/http_load/
安装:
解压后只要 make , make install 就行了
环境: 需要gcc 如果是在服务器上安装的话还需要有sudo
执行命令:
./http_load
参数说明:
-parallel 简写-p :含义是并发的用户进程数。
-fetches 简写-f :含义是总计的访问次数
-rate 简写-r :含义是每秒的访问频率
-seconds简写-s :含义是总计的访问时间准备URL文件:urllist.txt,文件格式是每行一个URL,URL最好超过50-100个测试效果比较好.文件格式
如下:
http://www.51testing.com/?uid-410671-action-viewspace-itemid-834199
http://www.51testing.com/?uid-410671-action-viewspace-itemid-834198
http://www.51testing.com/?uid-410671-action-viewspace-itemid-834197
执行及结果说明:
./http_load -rate 5 -seconds 10 urls说明执行了一个持续时间10秒的测试,每秒的频率为5。

结果分析:
1.49 fetches, 1 max parallel, 2.04472e+06 bytes, in 10.0005 seconds 说明在上面的测试中运行了49个请求,最大的并发进程数是2.389,总计传输的数据是204463bytes,运行的时间是10.0148秒
2.41729 mean bytes/connection 说明每一连接平均传输的数据量41729/49=581.6
3.4.89977 fetches/sec, 204463 bytes/sec
说明每秒的响应请求为4.89977,每秒传递的数据为204463 bytes/sec
4.msecs/connect: 1.70367 mean, 2.389 max, 1.322 min 说明每连接的平均响应时间是1.70367 msecs,最大的响应时间2.389 msecs,最小的响应时间1.322 msecs
5.msecs/first-response: 65.0539 mean, 108.677 max, 56.335 min
6、HTTP response codes: code 200 — 49 说明打开响应页面的类型,如果403的类型过多,那可能要注意是否系统遇到了瓶颈。
特殊说明:
测试结果中主要的指标是 fetches/sec、msecs/connect 这个选项,即服务器每秒能够响应的查询次数,用这个指标来衡量性能。似乎比 apache的ab准确率要高一些,也更有说服力一些。
Qpt-每秒响应用户数和response time,每连接响应用户时间。
测试的结果主要也是看这两个值。当然仅有这两个指标并不能完成对性能的分析,我们还需要对服务器的cpu、men进行分析,才能得出结论
-
web性能测试基础(一)
2013-01-25 17:20:00
1.1基本概念
并发用户:用户并发一般发生在使用比较频繁的模块中,而且遇到异常通常都是程序的问题。
用户并发数量:在线用户数量是计算并发用户数量的主要依据之一。=使用系统的用户数量*(5%~20%)
并发主要针对WEB服务器而言,是否并发的关键是看用户的操作是否对服务器产生了影响。
吞吐量:一次性能测试过程中网络上传输的数据量的总和。
吞吐率:吞吐量/传输时间,单位时间内网络上传输的数据量,也可以指单位时间内处理的客户端请求数量。吞吐率用“请求数/秒”或者“页面数/秒”来衡量。
点击率:每秒钟用户向web服务器提交的HTTP请求数。点击率越大,对服务器的压力也越大。重要的是分析点击时产生的影响。
点击不是指鼠标的一次“单击”操作,因为在一次“单击”操作中,客户端可能向服务器发出多个HTTP请求。
1.2WEB性能测试种类
压力测试:确定一个系统的瓶颈或者不能接收用户请求的性能点,来获得系统能提供的最大服务级别的测试。
负载测试:在被测系统上不断增加压力 ,直到性能指标达到极限,响应时间超过预定指标或者某种资源已经达到饱和状态。这种测试可以找到系统的处理极限,为系统调优提供依据。
大数据量测试:针对某些系统存储、传输、统计查询等业务进行大数据量的测试。
配置测试:通过测试找到系统各资源的最优分配原则。
可靠性测试:可以施加cpu资源保持70%-90%使用率的压力,连续对系统加压运行8小时,然后根据结果分析系统是否稳定。即加载一定压力的情况下,使系统运行一段时间。
并发测试:多以发现一些算法设计上的问题。
性能测试以用户并发测试为主的测试。
性能测试主要是为了发现软件问题和硬件瓶颈。
对于性能方面给系统留有30%左右的扩展空间即可。
1.3Web全面性能测试模型
1.3.1预期指标的性能测试
主要指需求分析和设计阶段提出的一些性能指标。
针对每个指标都要编写一个或者多个测试用例来验证系统是否达到要求。
预期指标的性能测试用例通常以单用户为主,如果涉及并发用户内容,则归并到并发用户测试用例中进行设计。
1.3.2并发性能测试
选择具有代表性、关键的业务来设计用例,并且用户的设计应该面向“模块”
用户并发性能测试分为:独立核心模块并发性能测试,组合模块并发性能测试
独立核心模块并发:完全一样功能的并发测试;完全一样操作的并发测试;相同/不同的子功能并发。
针对独立核心模块用户并发性能的测试用例设计,可发现一些核心算法或者功能方面的问题,如一些多线程、同步并发算法在单用户模式下测试是很难发现问题的,通过模拟多用户的并发操作,更容易验证其是否正确和稳定。
核心模块测试一般属于基本的性能测试,它较多地关注模拟的“功能”,一般不会对服务器进行测试。
组合模块并发:具有耦合关系的核心模块进行组合并发测试;彼此独立的、内部具有耦合关系的核心模块组的并发测试;基于用户场景的并发测试。
组合模块测试一般发现接口方面的功能问题,并尽早发现综合性能问题。
在实际中,各种类型的用户都会对应一组模块,相当于不同的业务组在并发访问系统,要充分考虑实际场景,如话费管理系统中的每月10日左右的收费高峰等场景。
在编写组合模块用户并发性能测试用例时,不但要考虑用户使用场景,还要注意并发点的运用,并发点是指一定数量的用户开始执行同一功能或者操作的时间点,一组测试场景通常包含多个并发点,从而实现了核心模块同一功能或者操作的真正并发。
1.3.3独立业务性能测试
独立业务实际是指一些核心业务模块对应的业务。这些模块通常具有功能比较复杂,使用比较频繁,属于核心业务等特点。主要测试这类模块和性能相关的一些算法、还要测试这类模块对并发用户的响应情况。
用户并发测试是核心业务模块的重点测试内容。
1.3.4组合业务性能测试
是最接近用户实际使用情况的测试,也是性能测试的核心内容。
组合并发的突出特点是根据用户使用系统的情况分成不同的用户组进行并发,每组的用户比例要根据实际情况来进行匹配。
用户并发测试是组合业务性能测试的核心内容。“组合”并发的突出特点是根据用户使用系统的情况分成不同的用户组进行并发,每组的用户比例要根据实际情况来进行匹配。
1.3.5网络性能测试
为准确展未带宽、延迟、负载和端口的变化是如何影响用户的响应时间的。主要是测试应用系统的用户数目与网络带宽的关系。
调整性能最好的办法就是软硬相结合。
1.3.6大数据量测试
主要是针对对数据库有特殊要求的系统进行的测试,主要分为三种:
1.实时大数据量:模拟用户工作时的实时大数据量,主要目的是测试用户较多或者某些业务产生较大数据量时,系统能否稳定地运行。
2.极限状态下的测试:主要是测试系统使用一段时间即系统累积一定量的数据时,能否正常地运行业务
3.前面两种的结合:测试系统已经累积较大数据量时,一些实时产生较大数据量的模块能否稳定地工作。
大数据量测试用例的设计:1,历史数据引起的大数据量测试和2运行时大数据量测试
首先确定系统数据的最长迁移周期和选择一些前面的核心模块或者组合模块的并发用户测试用例作为其主要内容即可.
1.3.7服务器性能测试
性能测试的主要目的是在软件功能良好的前提下,发现系统瓶颈并解决,而软件和服务器是产生瓶颈的两大来源,因此在进行用户并发性能测试,疲劳强度与大数据量性能测试时,完成对服务器性能的监控,并对服务器性能进行评估。
服务器性能测试用例设计就是确定要采集的性能计数器,并将其与前面的测试关联起来。
1.3.8设计性能测试用例注意的原则:
可以满足预期性能指标测试用例要求的,就没有必要设计更多的内容,因为用例越多,执行的成本也越高。
一定要服从整体性能测试策略,千万不能仅从技术角度来考虑设计“全面”的测试用例,“全面”应该以是否满足自己的测试要求作为标准。
适当裁剪原则
只有根据实际项目的特点制定合理的性能测试策略、编写适当的性能测试用例,并在测试实施中灵活地变通才可以做好性能测试工作。
-
性能测试基础知识-性能的规划与实现
2013-01-25 16:43:29
性能的规划与实现
一个不能按意愿执行的程序是没有用处的。每个程序都必须满足某组用户(有时会是一组很大且需求各不相同的用户)的需求。如果程序的性能确实不能满足那些用户中很大一部分用户的需求,则不会使用这个程序。一个不被使用的程序是不能实现预期功能的。
这种情况对经许可的软件包和用户编写的应用程序是确实存在的,尽管大多数软件包开发者意识到低性能的影响,并尽力提高程序的运行速度。不幸的是,他们不能 预测程序要经历的所有环境和用途。让程序具有可接受性能的最终职责就落在了那些选择或编写、规划以及安装软件包的人身上。
本章描述程序员或系统管理员可以确保新编写或购买的程序具有可接受性能的步骤。(当程序员这个词单独出现时,它包含系统管理员和任何对程序的最终成功负责的人。)
为使程序达到可接受的性能,在工程开始时就要确定和量化可接受性,并且决不能忽视达到目标所需的方法和资源。尽管听起来这是基本方法,但一些编程工程却有意抵制它。他们采用一种清楚地描述为设计、编码、调试、可能是编写文档,有时间的话再确定其性能的策略。
为使程序运行时不仅在逻辑上,而且在时间上都是可预知的,唯一办法就是在软件规划和开发过程中对性能注意事项进行整体考虑。由于安装者较之开发者有较少的自由,所以在现有软件安装时提前规划也许就更关键了。
尽管对一个小程序来说,这个过程的细节可能看起来很繁重,但不要忘了我们还有第二个“记事本”。我们不仅必须保证新程序具有令人满意的性能,还须确保该程序对现有系统的补充部分不会降低运行于该系统的其它程序的性能。
确定工作负载的组成部分
无论程序是新编写的还是购买的、大程序还是小程序,开发者、安装者和预期用户都对程序的使用有所假设,比如:
谁使用该程序
程序在何种环境下运行
这些环境出现的频度,以及在某年某月某日某时会出现多少次
在这些环境下是否还需使用其它现有程序
程序运行于何种系统
有多少数据将要从何处进行处理
由程序或为程序创建的数据是否会在其它方面用到
除非这些想法是作为设计过程的一部分提出的,否则很可能模糊不清,并且程序员将几乎无疑会有与预期用户不同的假设。甚至在程序员同时也是用户这样明显很普 通的情况中,让假设无关会使以任何严格方式进行设计与假设的比较成为不可能。更糟的是,在对正进行的工作没有完全理解的情况下是不可能确定性能需求的。
编写性能需求文档
在确定和量化性能需求时,确定某一特殊要求背后的推理是很重要的。这是规划过程总能力的一部分。用户可能会将其需求声明基于与程序员的假设不匹配的程序逻辑的假设。性能需求集至少应记录下面几点:
各种特定类型的用户 — 计算机交互作用在大部分时间会经历的最佳响应时间,以及对大部分时间的定义。响应时间从用户执行“运行”这个操作的时间直到用户从计算机接收到足够反馈以 继续执行任务来衡量。这是用户的主观等待时间。它不是从一个子例程的入口到第一个写语句的时间。
如果用户对响应时间不感兴趣,而仅仅对结果感兴趣,您可以询问“当前独立执行时间估计值的十倍”是否可以接受。如果回答“是”,您就可以继续讨论吞吐量。否则,您可以在用户十分注意的情况下继续讨论响应时间。
最低程度可接受剩余时间的响应时间。较长的响应时间会使用户认为系统当机。您还需要指定剩余时间,例如,一天的高峰时刻,百分之一的交互作用。在一天的某特定时间减少响应时间很难办到,或者代价更高。
需要的典型吞吐量和将发生的次数。这并不是临时注意事项。例如,对一个程序的需求可能是每天运行两次:上午 10:00 和下午 3:15。如果这是一个运行 15 分钟,并且计划运行于多用户系统的有 CPU 限制的程序,则需要某种协商以便依次运行。
最大吞吐量周期的大小和计时。
综合预期请求及其如何随时间变化。
多用户应用程序中每台机器的用户数及总用户数。此描述应包括这些用户登录和注销的次数,以及假设的击键速率、完成的请求和思考次数。您可能想弄清楚思考次数是否随前后请求而系统地变化。
用 户所做的关于工作负载要在其上运行的机器的任何假设。如果用户头脑中存在一台具体的机器,那么确保您早就了解它。同样,如果用户所采用的是特殊类型、大 小、成本、位置、互联或任何其它变量,而这些变量将限制您满足前述需求的能力,那么假设也变为需求的一部分。满意程度可能不会在程序开发、测试或首次安装的系统上进行评估。
估计工作负载的资源需求
除非您正在购买配有详细资源需求文档的软件包,否则资源估计可能是性能规划过程中最困难的任务。造成困难有如下几个原因:
执行任何任务都有几种方法。您可以编写 C(或其它高级语言)程序、shell 脚本、perl 脚本、awk 脚本、sed 脚本、AIXwindows 对话等等。从性能观点看,一些看来特别适合算法和程序员生产力的技术非常昂贵。
有一条准则很有用,即,抽象级别越高,就越要谨慎,以确保某个系统不会承受令人惊讶的性能。请仔细考虑由一些明显无害的构造所暗示的数据量大小和迭代数量。
单 个过程的精确成本是很难确定的。困难之处不仅仅是技术上的;还有哲学上的。如果多用户运行的给定程序的多个实例正在共享程序文本页面,则哪一个进程应该负 责那些内存页面呢?操作系统将最近用过的文件页面保留在内存中,以便为重新访问该数据的程序提供高速缓存的效果。重新访问数据的程序应该对用来保留数据的 空间负责吗?某些评估的粒度,比如系统时钟,可以在用于同一程序连续实例的 CPU 时间上产生变化。
有两种方法来处理资源报告的模糊性和可变性。第一种是忽略模糊性,持续消除可变性的来源,直到评估变得可一致性接受。第二种方法是尝试让评估尽可能真实,并从统计上描述结果。注意后者产生与生产环境有某种相关性的结果。
系 统很少专门运行单个程序的单个实例。存在几乎一直处于运行的守护程序、频繁的通信活动和通常来自多个用户的工作负载。这些活动很少线性增加。例如,增加给 定程序的实例个数几乎没有增加使用的新程序文本页面数,因为大部分程序已存在于内存中。但是,附加的进程可能导致对处理器高速缓存的额外争用,所以,不仅 其它进程不得不和新进程共享处理器时间,而且所有进程都会经历执行每条指令需要更多周期的情况。这实际上使得处理器速度减慢,结果导致更频繁的高速缓存未 命中。
为使您的估计与具体情况所允许的一样真实,请使用以下准则:
如果程序存在,对最类似您自己需求的现有安装进行评估。最好的方法是使用容量规划工具,如 BEST/1。
如果没有合适的安装可用,则进行试安装并对综合工作负载进行评估。
如果生成与需求相匹配的综合工作负载是不实际的,则评估个体的交互作用并将结果用作仿真输入。
如果程序还不存在,查找使用同种语言和通用结构的同等程序并对其进行评估。再次强调,语言越抽象,在确定可比性时就越需谨慎。
如果同等程序不存在,则用规划的语言开发一个主要算法的原型,对这个原型进行评估并对工作负载建模。
只有当任何类型的评估都是不可能或不可行的,您才应作一个有根据的猜测。如果在规划阶段有必要对资源需求进行猜测,则在其开发阶段尽早对实际程序进行评估是很关键的。
牢记独立软件供应商(ISV)对他们的应用程序常常有可缩放的准则。
在估计资源时,我们主要对四个方面感兴趣(无特殊顺序):
CPU 时间
工作负载的处理器成本
磁盘访问
工作负载产生的磁盘读写速率
LAN 流量
工作负载生成的信息包数目和交换的数据字节数
实内存
工作负载所需 RAM 的大小
以下各节讨论了在各种情况下如何确定这些值。
评估工作负载资源
如果实际程序、可比程序或原型对评估都是可用的,则技术方法的选择依赖以下几点:
除了我们要评估的工作负载以外,系统是否还在处理其它工作。
我们是否有权使用会降低性能的工具(例如,系统是否处于生产中或在评估持续时间中是否为我们所专用?).
我们能够模拟或观察真实工作负载的程度。
估计新程序需要的资源
对未编写的程序进行精确估计是不可能的。编码阶段发生的创作和重新设计是难以预见的,但下面的准则可以帮助您对需求有一个全面了解。作为一个起点,最小程序需要以下条件:
大约 50 毫秒的 CPU 时间,大部分是系统时间。
实内存
一个程序文本页面
大约 15 个页面(其中 2 个是暂存页面)用于工作(数据)段
对 libc.a 进行访问。通常这和所有其它程序共享,并当作操作系统基本成本的一部分。
大约 12 个页面调进的磁盘 I/O 操作(如果程序最近尚未编译、复制或使用)。否则什么都不需要。
除了上述一些方面,还有由设计所隐含要求的基本成本容差(给出的单元仅作示例用):
CPU 时间
不包含高级迭代或昂贵子例程调用的普通程序的 CPU 消耗小得几乎不可测量。
如果提到的程序包含计算复杂的算法,则开发一个原型,对算法进行评估。
如果提到的程序使用计算复杂的库子例程,如 X 或 Motif 构造或 printf() 子例程,则用其它小程序对它们的 CPU 消耗进行评估。
实内存
每个程序文本页面允许大约 350 行代码,其中每行大约 12 字节。不要忘了编码风格与编译器选项可在任一方面产生一两种因素的差异。该容差是针对与您典型情况相关的页面的。如果您的设计在可执行程序的结束处安插有执行次数很少的子例程,则那些页面通常不消耗实内存。
引用共享库而不是 libc.a 会增加内存需求,仅从这个意义上来说,那些库并不与其它程序或正在估计程序的实例共享。为量度这些库的大小,请编写一个长期运行的引用那些库的小程序,并对进程使用 svmon -P 命令。
估计在设计中所确定的数据结构所需存储量大小。集中到最靠近的页面。
在短时间的运行中,每一个磁盘 I/O 操作使用一个内存页面。假设页面必须已是可用的。不要假设程序会等待另一个程序的页面释放。
磁盘 I/O
对于顺序 I/O,每读或写 4096 字节导致一个 I/O 操作,除非文件最近刚被访问过并且一些页面仍留在内存中。
对于随机 I/O,每一次对不同的 4096 字节页面的访问,无论大小,都会导致一个 I/O 操作,除非文件最近刚被访问过并且一些页面仍留在内存中。
每 一次对大文件进行 4 KB 页面的顺序读写会占用大约 100 个单元。每一次进行 4 KB 页面的随机读写会占用大约 300 个单元。记住实际文件不一定顺序存储在磁盘上,尽管程序对它们进行顺序写和读。因此,与顺序存取成本相比,实际磁盘存取的典型 CPU 成本与随机存取成本更接近。
通信 I/O
如果磁盘 I/O 实际上是对网络文件系统(NFS)远程安装的文件系统的,则磁盘 I/O 在服务器上执行,但客户机会承担更高的 CPU 和内存要求。
任何一种 RPC 对 CPU 负载都有非常大的贡献。设计中提出的 RPC 应该预先进行最小化、批处理、原型化和评估。
每一次进行 4 KB 页面的顺序 NFS 读或写会占用客户机大约 600 个单元。每一次进行 4 KB 页面的随机 NFS 读或写会占用客户机大约 1000 个单元。
Web 浏览和 Web 服务暗示有大量的网络 I/O,同时 TCP 连接的打开和关闭非常频繁。
变换程序级别估计为工作负载估计
估计高峰和典型资源需求的最好方法是使用排队模型,如 BEST/1。您可以使用静态模型,但有冒高估或低估高峰资源的危险。在任一情况下,从资源需求的观点出发,您都需要理解工作负载中的多个程序是如何交互的。
如果您正在构建一个静态模型,请使用时间间隔,这是对大多数频繁运行或苛求的程序(通常两者是相同的)而言可接受性最差的响应时间。决定在每个时间间隔中通常运行哪些程序,这要基于您所规划的用户数、他们的思考次数、击键输入速率以及预期的混合操作。
使用以下准则:
CPU 时间
在时间间隔中运行的所用程序的 CPU 需求总和。包括程序正要执行的磁盘和通信 I/O 的 CPU 需求。
如果在时间间隔中这个数字大于可用 CPU 时间的 75%,则应考虑减少用户数或增加 CPU。
实内存
操作系统内存需求随物理内存大小而变化。操作系统本身使用 6 到 8 MB。单机系统中该数字更小。后一个数字是对 LAN 连接以及使用 TCP/IP 和 NFS 的系统而言的。
在时间间隔中运行的程序所有实例的工作段需求总和,包括为程序数据结构所估计的空间。
即将运行的每个不同程序文本段的内存需求(一个程序文本副本为该程序所有实例服务)的总和。记住来自非共享库的任何(且仅仅)子例程将成为可执行程序的一部分,但这些库本身并不在内存中。
每一个由工作负载中任何程序使用的共享库所消耗的空间大小总和。再次强调,一个副本可供所有实例使用。
为了提供足够的空间用作某种文件高速缓存和自由列表,您的内存规划总和不应超过要使用的机器大小的 80%。
磁盘 I/O
每个程序的每个实例所暗示的 I/O 总数。分别计算小文件(或随机读写的大文件)与完全顺序读或写的大文件(大于 32 KB)的 I/O 总数。
除 去那些您认为可以从内存中获得的 I/O。前一个时间间隔的任何读或写记录在当前时间间隔中很可能仍然可用。此外,检查提出的机器的大小并与机器工作负载的总 RAM 需求对比。操作系统需求与工作负载需求之外的所有剩余空间可能包含最近读或写的文件页面。如果您的应用程序设计如上面所述,那么很有可能您会重新使用最近 访问过的数据,您可以针对高速缓存的效果计算容差。记住重新使用是在页面级别上,而不是记录级别上。如果重新使用一条给定记录的可能性很低,但每个页面又 有大量记录,则在任何给定时间间隔中需要的一些记录可能会像最近使用过的其它记录一样落在同一页面中。
把净 I/O 需求(每张磁盘每秒钟的磁盘 I/O)与当前磁盘驱动器的近似容量相比较。如果随机或顺序需求超过要保存应用程序数据的相应的磁盘总容量的 75%,那么就有必要在应用程序运行时进行调谐(并且可能是扩展)。
通信 I/O
计算工作负载的带宽消耗。如果 LAN 上所有节点的总带宽消耗大于额定带宽的 70%(以太网中的 50%),您可能想使用带宽更高的网络。
对要加在服务器上的额外负载的 CPU、内存和 I/O 需求进行类似分析。
注:
记住只有当不可能进行综合评估时,这些准则才有用。任何可用来代替某个准则的应用程序特定的评估都会显著提高估计的精确性。 -
性能测试基础知识-处理器调度程序性能
2013-01-25 14:37:30
处理器调度程序性能概述
线程支持
线程可看作开销低的进程。它是一个可分派实体,创建它需要的资源比创建一个进程需要的资源少。
进程由一个或多个线程组成。事实上,操作系统的早期发行版中负载的直接迁移就是继续创建和管理进程。每个新进程在创建时只带有单一的线程,该线程具有其父进程的优先级并与其它进程中的线程争用处理器。进程在执行时拥有它所使用的资源,而线程仅仅拥有它的当前状态。
当新的或修改的应用程序利用操作系统的线程支持创建额外的线程时,那些线程在该进程的上下文中创建。它们共享进程的私有段和其它资源。
进程中的一个用户线程有一个特定的争用作用域。如果争用作用域是全局的,则该线程与系统中所有其它线程一起争用处理器时间。在进程创建时产生的线程具有全局争用作用域。如果争用作用域本地的,则该线程与进程中的其它线程竞争以成为进程共享的处理器时间的接收方。
决定接下来应该运行哪个线程的算法叫调度策略。
进程和线程
进程是系统中的一个活动,它由某个命令、shell 程序或另一进程启动。
进程的属性如下:
pid
pgid
uid
gid
环境
cwd
文件描述符
信号操作
进程统计信息
nice
线程的属性如下:
堆栈
调度策略
调度优先级
暂挂信号
阻塞信号
线程特定的数据
每个进程由一个或多个线程组成。线程是一个单独的控制序列流。多个控制线程允许应用程序进行重叠操作,例如读取终端和写文件。
多个控制线程也允许应用程序同时为来自多个用户的请求服务。线程提供了这些能力而不需多个进程那样的额外开销,例如要通过 fork() 系统调用创建多个进程。
AIX 4.3.1 中引入了一个快速的 fork 例程 f_fork()。该例程对多线程应用程序非常有用,它们将立刻调用 exec() 子例程,前提是之前应先调用 fork() 子例程。fork() 子例程运行起来较慢,因为在实际派生及让其子例程运行全部子处理程序来初始化所有锁之前,它必须调用 fork 处理程序获得所有的库锁。f_fork() 子例程忽略这些处理程序并直接调用 kfork() 系统调用。Web 服务器是一个可以使用 f_fork() 子例程的很好的应用程序示例。
进程和线程的优先级
优先级管理工具处理进程的优先级。在 AIX V4 中,进程优先级只是线程优先级的前驱。当调用 fork() 子例程时,会创建一个进程和一个要在其中运行的线程。线程的优先级归结于进程。
内核为每个线程维护一个优先级值(有时称为调度优先级)。优先级值是一个正整数且与关联线程的重要性的变化方向相反。也就是说,较小的优先级值表示一个相对重要的线程。当调度程序寻找线程进行分派时,它选择具有较小优先级值的可分派线程。
线 程可以有固定的优先级或不固定的优先级。优先级固定的线程的优先级值是一个常量,而优先级不固定的线程的优先级值根据用户线程最小优先级级别(常量 40)、线程的 nice 值(缺省值是 20,可随意由 nice 或 renice 命令进行设置)和其处理器使用的损失而变化。
线 程的优先级可以固定成某个值,如果用 setpri() 子例程设置(固定)它们的优先级的话,它们可以具有小于 40 的优先级值。这些线程不会受到调度程序重算算法的影响。如果它们的优先级值固定且小于 40,这些线程将在可以运行所有用户线程之前运行和完成。例如,一个具有固定值 10 的线程将在具有固定值 15 的线程之前运行。
用户可以应用 nice 命令使线程的不固定优先级变低。系统管理员可将一个负的 nice 值应用给线程,这样就给了它较好的优先级。
下图显示了一些可以更改优先级值的方法。
图 6. 如何确定优先级值. 插图显示了如何能在执行过程中或应用了 nice 命令之后更改线程调度优先级值。优先级值越小,线程优先级越高。开始时,nice 值缺省为 20 而基本优先级缺省为 40。在执行一些操作及处理器损失后,nice 的值仍为 20 且基本优先级仍为 40。在运行 renice --5 命令后及使用和以前相同的处理器的情况下,nice 值现在是 15 而基本优先级仍为 40。在以 50 的值发出子例程 setpri() 之后,固定优先级现在是 50 而 nice 值和处理器的使用无关。
线程的 nice 值在创建线程时设置并且在线程的整个生命期中都是常量,除非用户通过 renice 命令或 setpri()、setpriority()、thread_setsched() 或 nice() 系统调用明确更改了它的值。
处 理器损失是一个整数,它通过线程最近的处理器使用来计算。如果每次在一个 10 ms 的时钟滴答结束时线程受处理器控制,则最近的处理器使用值近似加 1,直到达到最大值 120。每个滴答的实际优先级损失随着 nice 的值增加。所有线程的最近处理器使用值每秒重算一次。
结果如下:
不固定优先级的线程的优先级随着其最近处理器使用的增加而变低,反之亦然。这暗示一般来讲,某线程最近被分配的时间片越多,则它被分配下一个时间片的可能性越小。
不固定优先级的线程的优先级随着其 nice 值的增加而变低,反之亦然。
注:
使用多处理器运行队列及其负载平衡机制以后,nice 或 renice 的值对线程的优先级可能没有预期的影响,因为较低优先级的运行时间可能等于或大于较高优先级的运行时间。要求 nice 或 renice 产生预期效果的线程应该放在全局运行队列中。
可以使用命令 ps 显示进程的优先级值、nice 值和短期的处理器使用值。
请参阅『处理器的控制争用』中对使用 nice 和 renice 命令的更详细的讨论。
请参阅『调谐线程优先级值的计算』,里面有处理器损失计算和最近处理器使用值衰减的详细信息。
优先级机制也用于 AIX 工作负载管理器中来加强处理器资源管理。因为在工作负载管理器下分类的线程具有的优先级由工作负载管理器管理,它们可能与没有在工作负载管理器下分类的线程具有不同的优先级行为。
线程的调度策略
下面是线程调度策略的可能值:
SCHED_FIFO
这种策略的线程被调度后,它会一直运行到结束,除非被阻塞或有一个较高优先级的线程可分派,它将自愿服从处理器的控制。只有固定优先级的线程才能有 SCHED_FIFO 调度策略。
SCHED_RR
当一个 SCHED_RR 线程在时间片的末尾有控制权时,它将移动到和它具有相同优先级的可分派线程队列的尾部。只有固定优先级的线程才能有 SCHED_RR 的调度策略。
SCHED_OTHER
这个策略在“POSIX 标准 1003.4a”中作为定义的执行程序进行定义。在每个时钟中断时重算运行线程的优先级值意味着该线程可能失去控制权,因为它的优先级值已经超过了另一可分派线程的优先级值。
SCHED_FIFO2
该策略和 SCHED_FIFO 相同,只是它允许一个仅睡眠了很短时间的线程在被唤醒时可放置在其运行队列的头部。这个时间周期是相似性限制(可用 schedtune -a 进行调节)。该策略仅可用于 AIX 4.3.3 及其后续版本。
SCHED_FIFO3
调 度策略设置成 SCHED_FIFO3 的线程总是放置在运行队列的头部。为了防止属于 SCHED_FIFO2 调度策略的线程放置在 SCHED_FIFO3 之前,当 SCHED_FIFO3 线程入队列时更改运行队列参数,这样属于 SCHED_FIFO2 的线程就不满足使其能够加入运行队列头部时必须满足的标准。该策略仅可用于 AIX 4.3.3 及其后续版本。
SCHED_FIFO4
只 要优先级值相差 1,较高优先级的 SCHED_FIFO4 调度类线程就不会抢占当前正运行的低优先级线程。缺省行为是当前运行于某给定 CPU 的低优先级线程被有资格在同一 CPU 上运行的高优先级线程抢占。该策略仅可用于 AIX 5L V5100-01 + APAR IY22854 及其后续版本。
调度策略可用系统调用 thread_setsched() 进行设置并且仅对调用线程有效。然而,通过指定进程标识发出 setpri() 调用可将线程设置成 SCHED_RR 调度策略;setpri() 的调用者和 setpri() 的目标不必匹配。
只 有那些具有 root 权限的进程可以发出 setpri() 系统调用。只有那些具有 root 权限的线程可将调度策略更改成任何 SCHED_FIFO 选项或 SCHED_RR。如果调度策略是 SCHED_OTHER,则优先级参数被 thread_setsched()子例程忽略。
线程的主要优点是适用于当前由多个异步进程组成的应用程序。这些应用程序可通过转变成多线程结构使得系统中有较轻的负载。
调度程序运行队列
调度程序维护一个所有就绪等待分派的线程的运行队列。
给定优先级的所有可分派线程在运行队列中占有一定的位置。
调 度程序的基本可分派实体是线程。AIX 5.1 维护 256 个运行队列(128 个在 AIX 4.3 及以前的发行版中)。在 AIX 5.1 中,运行队列与每个线程优先级字段可能值的范围(从 0 到 255)直接相关。这个方法使调度程序更容易确定哪个线程最先运行。调度程序无需搜索一个完整的运行队列,只需要考虑一个掩码,该掩码的某一位启用后可表 示在相应的运行队列中存在就绪等待运行的线程。
线程的优先级值快速而频繁地变更。持续的变动归因于调度程序重算优先级的方法。然而,这并不适用于固定优先级的线程。
从 AIX 4.3.3 开始,每个处理器都有自己的运行队列。性能工具中报告的运行队列值将是每个运行队列中所有线程的总和。让每个处理器都有自己的运行队列可节省分派锁的开销 并改善总体的处理器相似性。线程通常会更加趋向于留在同一处理器中。如果因为另一处理器上的事件使某线程变得可运行且有空闲的处理器的话,即使不同于最近 可运行线程曾经运行过的处理器,该线程也只会立即被分派。在可以检查处理器状态(例如在该线程的处理器上的中断)之前不会出现抢占。
在具 有多个运行队列的多处理器系统中,可能出现瞬间的优先级倒置。在任何一个时间点都可能出现这种情况:某个运行队列能使若干线程具有的优先级比另一运行队列 更有利。AIX 有一些机制可以随着时间的推移来进行优先级平衡,但是如果要求严格的优先级(例如,对于实时应用程序)可用一个叫做 RT_GRQ 的环境变量,如果将它设置成 ON,将导致该线程位于一个全局运行队列中。在那种情况下,将搜索全局运行队列来察看哪个线程具有最佳优先级。这可以改善中断驱动线程的性能。如果将 schedtune -F 设置成 1,以固定优先级运行的线程就放置在全局运行队列中。
运行队列中的线程平均数可在命令 vmstat 输出的第一列中看到。如果用处理器数去除这个数,结果是每个处理器上可运行线程的平均数。如果这个值大于 1,这些线程必须等待轮到它们使用处理器(这个数越大,性能延迟可能越明显)。
当某线程移到运行队列的末端时(例如,当线程在时间片的末尾拥有控制权时),它会移动到具有相同优先级值的队列中最后一个线程之后的位置上。
调度程序处理器时间片
处 理器时间片是调度程序转换到另一个具有相同优先级的线程之前,一个 SCHED_RR 线程能获得的时间的总和。可以使用命令 schedtune 的选项 -t 在时间片上以 10 毫秒的增量来增加时钟滴答数(参阅『用 schedtune 命令修改调度程序时间片』)。
注:
时间片并不是保证的处理器时间量。它是一个线程在面临由另一线程取代的可能性之前可以受控的最长时间。在控制时间达到完整时间片之前有很多方法可使线程失去处理器的控制。
方式转换
用户进程在需要访问系统资源时会经历一个方式转换。这通过系统调用接口或诸如缺页故障这样的中断来实现。有两种方式:
用户方式
内核方式
花在用户方式(应用程序和共享库)下的处理器时间作为用户时间在一些命令的输出中反映出来,例如,vmstat、iostat 和 sar 命令。花在内核方式下的处理器时间作为系统时间在这些命令的输出中反映出来。
用户方式
在用户保护域中执行的程序是用户进程。在这种保护域中执行的代码以用户执行方式执行,且具有下列访问:
读/写访问进程专用区域中的用户数据
读访问用户文本和共享文本区域
使用共享内存功能访问共享数据区域
在用户保护域中执行的程序不能访问内核或内核数据段,除非通过使用系统调用间接访问。在该保护域中的程序只能影响自身的执行环境并在进程或非特权状态下执行。
内核方式
在内核保护域中执行的程序包含中断处理程序、内核进程、基内核和内核扩展(设备驱动程序、系统调用和文件系统)。这个保护域暗示以内核执行方式执行代码,具有下列访问:
读/写访问全局内核地址空间
在进程中执行时读/写访问进程区域中的内核数据
内核服务必须用来访问进程地址空间中的用户数据。
在该保护域中执行的程序会影响所有程序的执行环境,因为它们具有下列特征:
它们可访问全局系统数据
它们可使用内核服务
它们免受所有安全性约束
它们执行于处理器特权状态下。
方式转换
用户方式的进程使用的系统调用允许通过用户方式调用内核函数。直接或间接地调用系统调用来访问的函数一般由程序设计库提供,它们提供对操作系统函数的访问。
方式转换应该不同于在命令 vmstat(cs 列)和 sar(cswch/s)的输出中所看到的上下文转换。在当前运行的线程不同于该处理器上先前运行的线程时会出现上下文转换。
当下列任一情况出现时调度程序执行上下文转换:
线程必须等候某个资源(自愿),比如磁盘 I/O、网络 I/O、睡眠或锁
一个较高优先级线程被唤醒(非自愿)
线程已经用完了它的时间片(通常是 10 ms)。
上下文转换的时间、系统调用、设备中断、NFS I/O 和内核中任何其它活动都看作系统时间。
2004-8-23 19:48:39 鲜花(0) 鸡蛋(0)
snappyboy
等级:论坛游民
文章:123
积分:283
注册:2003-10-20
第2楼
多处理介绍
无论何时,单处理器芯片的运行速度都存在着技术上的限制。如果单处理器无法令人满意地处理系统的工作负载,一种响应是使用多处理器来解决这个问题。
这种响应是否成功不仅仅取决于系统设计者的技术熟练程度,还取决于工作负载是否服从多处理控制。就人的任务而言,如果任务是应答一个免费电话号码的呼叫,增加人员也许不失为一个好主意,但是假如任务是开车的话,这种做法是否有效就值得怀疑了。
如果建议从一个单处理器系统迁移到一个多处理器系统的目标是为了改进性能,则下列条件必须成立:
工作负载受处理器限制并且已经使得它的单处理器系统饱和。
工作负载包含多种处理器密集的元素,例如事务或者复杂计算,这些操作可以同时并且各自独立地执行。
现有的单处理器不能升级,也不能由另一个能量充足的单处理器代替。
虽然正常情况下不变的单线程应用程序在某个多处理器环境中能正确运行,但它们的性能常常会有意外的变化。迁移到多处理器可以改善系统的吞吐量,并能改进复杂的多线程应用程序的执行时间,但是很少能改进个别的单线程命令的响应时间。
要从一个多处理器系统获得最佳性能,需要对多处理器系统独有的操作系统和硬件执行动态有所了解
对称多处理器(SMP)概念和体系结构
对 于增加系统复杂性的任何变化,为了获得令人满意的操作和性能,使用多处理器产生了一些设计时必须引起注意的事项。额外的复杂性使得软/硬件权衡的作用域更 大,并且比在单处理器系统中更需要软/硬件的密切配合。设计响应和权衡的不同组合使得多处理器系统的体系结构更加多样化。
这一节描述了多处理器系统的主要设计注意事项和这些事项的硬件响应。
多处理的类型
有几种多处理(MP)系统,如下所述:
非共享 MP(纯群集)
每 个处理器都是一个完全独立的机器,运行操作系统的一个副本。处理器之间没有共享的部分(每一个都有自己的内存,高速缓存和磁盘),但是它们是互联的。通过 LAN 连接时,处理器之间是松散耦合的。而通过转换器连接时,处理器之间是紧密耦合的。处理器之间的通信是通过消息传送来实现的。
这样一个系统的优点是它具有很好的可伸缩性和高可用性。而缺点则是该系统是一个不为人熟悉的编程模型(消息传送)。
共享磁盘 MP
处理器拥有自身的内存和高速缓存。处理器并行运行并共享磁盘。每个处理器都运行操作系统的一份副本,并且处理器之间是松散耦合的(通过 LAN 连接)。处理器之间的通信是通过信息传送实现的。
共享磁盘的优点是保留了熟悉的编程模型的一部分(磁盘数据是可寻址和连续的,而内存则不是),而且与共享内存的系统相比,这种系统更容易实现高可用性。缺点是由于在对共享数据进行物理和逻辑访问时存在瓶颈,它的可伸缩性受到限制。
共享内存群集(SMC)
一个共享内存群集中的所有处理器有自己的资源(主存储器、磁盘和 I/0),并且每个处理器运行一份操作系统的副本。处理器之间是紧密耦合的(通过一个转换器连接)。处理器之间的通信是通过共享内存实现的。
共享内存 MP
所有处理器通过一条高速总线或者一个转换器在同一机器中紧密耦合。处理器共享同样的全局内存、磁盘和 I/0 设备。只有一份操作系统的副本跨所有处理器运行,并且操作系统必须设计为能利用这种体系结构(多线程操作系统)。
SMP 有几个优点:
它们是增加吞吐量的一种划算的方法。
由于操作系统由所有处理器共享,它们提供了一个单独的系统映像(易于管理)。
它们对一个单独的问题应用多处理器(并行编程)。
负载平衡是由操作系统实现的。
这种单处理器(UP)编程模型可用于一个 SMP 中。
对于共享数据来说,它们是可伸缩的。
所有数据可由所有处理器寻址,并且由硬件监视逻辑保持连续性。
由于通信经由全局共享内存执行,在处理器之间通信不必使用消息传送库。
更多能量的需求可通过向系统添加更多处理器来解决。然而,在一个 SMP 系统里添加更多处理器时,您必须设置关于性能增强的现实期望值。
现在越来越多的应用程序和工具都可以使用。大多数 UP 应用程序可以在 SMP 体系结构中运行或者被移植到 SMP 体系结构中。
SMP 系统有一些局限性,如下所述:
由于高速缓存相关性、锁定机制、共享对象和其它问题,可伸缩性受到限制。
需要新技术来利用多处理器,例如线程编程和设备驱动程序编程。
并行化应用程序
有两种方法可以在一个 SMP 中使应用程序并行化,如下所述:
传统方法是把应用程序分解为多个进程。这些进程使用进程间通信(IPC)方法进行通信,例如管道、信号量或者共享内存。必须能够阻塞进程使其等待事件的发生(例如来自其它进程的消息),并且进程必须用类似锁的东西协调对共享对象的访问。
另一种方法是使用面向 UNIX(POSIX)线程的可移植操作系统接口。线程和进程一样存在协调的问题,并有类似的处理机制。因此一个单独的进程可以同时有很多线程运行在不同的处理器上。协调这些线程并且使得对共享数据的访问序列化是开发者的责任。
在 并行化一个应用程序的时候,考虑线程和进程两者各自的优势并且决定使用哪种方法。线程可能比进程快,并且它对内存的共享也比较容易。另一方面,进程的实现 更容易分布到多个机器或者群集中。如果一个应用程序需要创建或者删除新实例,则线程会更快(在派生进程中开销更大)。就其它功能而言,线程的开销和进程差 不多。
数据序列化
任何可由多个线程读或写的存储元素在程序运行中都可能改变。通常,这对多程序设计环境以及多处理环境都是成立的,但是多处理器的出现以两种方式增加了这种注意事项的作用域和重要性。
多处理器和线程的支持使得编写在线程中共享数据的应用程序具有吸引力和更容易。
内核再也不能通过简单地禁用中断来解决序列化问题。
注:
为了避免产生严重问题,共享数据的程序必须安排好,以对数据进行串行访问,而不是并行访问。在一个程序更新一个共享数据项之前,必须确保没有其它程序(包括它本身在另一个线程里运行的另一副本)会改变该项。通常读操作可以并行地执行。
用 来避免程序互相干扰的主要机制是锁。锁是一种抽象概念,它代表对访问一个或多个数据项的许可。锁定和解锁的请求是原子级的;也就是说,它们的实现方式为: 其结果既不受中断也不受多处理器访问的影响。所有访问一个共享数据项的程序在处理它之前必须先获得与它相关的锁。如果这个锁已经由另一个程序(或者另一个 运行同一程序的线程)占有,则请求的程序必须推迟访问,直到锁变得可用。
除了等待锁所花的时间之外,序列化也增加了一个线程成为不可分派线程所花的时间。当线程不可分派时,其它线程很可能会使这个不可分派线程的高速缓存线路被替换,这将导致线程最后获得锁并被分派时内存等待时间成本增加。
操作系统的内核包含很多共享的数据项,所以它必须在内部进行序列化。因此序列化延迟甚至可能在一个不与其它程序共享数据的应用程序中发生,因为由该程序使用的内核服务必须序列化共享的内核数据。
锁的类型
开 放软件基金会/1(OSF/1)1.1 的锁定方法被作为一个 AIX 的多处理器锁定功能模型使用。然而,由于系统是可抢占和可调页的,对 OSF/1 1.1 锁定模型增加了一些特征。简单和复杂的锁都是可抢占的。一个线程在尝试获得一个忙状态的简单锁时也可以睡眠,如果锁的所有者当前并不在运行的话。另外,当 一个处理器在一个简单锁上自旋一段时间(这段时间是一个全系统的变量)以后,这个简单锁会变成睡眠锁。
锁粒度
一个在多处理器环境中工作的程序员必须决定对共享数据一定要创建多少单独的锁。如果只有一个锁来序列化整个共享数据项的集合,则相比之下很可能出现锁争用。广泛使用锁的存在给系统吞吐量加了上限。
如 果每一个不同的数据项都有自己的锁,则两个线程争用这个锁的概率相对来说就比较低。然而,每一个附加的锁定和解锁调用都会消耗处理器时间,并且多个锁的存 在使得可能发生死锁。最简单的死锁情况如下图所示,其中线程 1 拥有锁 A 并且正在等待锁 B。同时,线程 2 拥有锁 B 并且正在等待锁 A。这两个程序都永远用不上会打破死锁的 unlock() 调用。通常对死锁的预防措施是建立一个协议,根据该协议,所有使用一个指定的锁集合的程序必须始终按照完全相同的顺序获得它们。
根据排队理论,一个资源闲置得越少,要得到它的平均等待时间就越长。这种关系是非线性的;如果锁的个数翻倍,平均等待这个锁的时间就比原来的两倍还要多。
减少对锁的等待时间的最有效方法是减少这个锁所保护的范围大小。下面是一些准则:
减少对任何锁的请求频率。
只锁定访问共享数据的代码,而不是一个组件的所有代码(这将减少锁的持有时间)。
只锁定特定的数据项或结构,而不是整个例程。
始终将锁和特定的数据项或结构关联起来,而不是和例程关联。
对于大的数据结构,为结构的每一元素选择一个锁,而不是为整个结构选择一个锁。
当持有一个锁时,从不执行同步 I/O 或者任何其它阻塞活动。
如果您对您组件中的同一数据有多个访问,请试着把它们移到一起,以便它们可以包含在一个锁定 — 解锁操作中。
避免双唤醒的情况。如果您在一个锁下修改了一些数据,并且不得不通知某人您做了这件事,则在公布唤醒之前请释放该锁。
如果必须同时持有两个锁,则最后请求那个最忙的锁。
另一方面,过细粒度将增加对锁的请求和释放的频率,因而会增加额外的指令。您必须在过细和过粗粒度之间找到平衡。最佳粒度不得不通过试验和错误找到,这也是一个 MP 系统中的最大挑战之一。
锁定开销
请求锁,等待锁和释放锁在几方面增加了处理开销:
一个支持多处理的程序总是进行相同的锁定和解锁处理,即使它是在一个单处理器里运行或者是一个多处理器系统里对于这个锁的唯一使用者。
当一个线程请求一个由另一线程持有的锁时,发出请求的线程可能会自旋一会或者置于睡眠状态,如果可能的话,会分派另一个线程。这会消耗处理器时间。
广 泛使用锁的存在给系统吞吐量加了一个上限。例如,如果一个给定的程序花 20% 的执行时间来持有一个互斥锁,这个程序最多只有五个实例能同时运行,不管系统里有多少个处理器。事实上,即使只有五个实例,它们也很可能永远不会精确同 步,以免互相等待。(参阅『多处理器吞吐量可伸缩性』)。
等待锁
当一个线程需要另一个线程已拥有的锁时,该线程被阻塞并且必须等到锁变得可用为止。有两种不同的等待方式:
对于只被持有很短时间的锁来说,自旋锁是很适合的。它允许等待中的线程保持其处理器重复检查某个死循环(自旋)里的锁定位,直到锁变得可用。自旋导致 CPU 时间(内核或内核扩展锁定的时间)增加。
睡眠锁适合于可能会被持有较长时间的锁。线程会睡眠到锁可用为止,当锁变得可用后,它会被放回到运行队列里。睡眠导致更多的闲置时间。
等待总会降低系统性能。如果使用自旋锁,处理器是繁忙的,但是它不是在做有用功(不是在为吞吐量出力)。如果使用睡眠锁,会导致上下文切换和分派的开销以及随之而来的高速缓存未命中的增加。
操作系统开发者们可以在两种类型的锁之间选择:在等待锁变得可用时允许进程自旋和睡眠的互斥简单锁,和在等待锁变得可用时可以自旋和阻塞进程的复杂读写锁。
一些约定管理着使用锁的规则。不管是硬件还是软件都没有实施或校验的机制。尽管使用锁已经使得 AIX V4 是“MP 安全”的,开发者们还是有责任定义和实现一个合适的锁定策略来保护他们自己的全局数据。
高速缓存一致性
在设计多处理器时,工程师们对保证高速缓存的一致性给予了相当多的注意。他们取得了成功;但是高速缓存一致性是以性能为代价的。我们需要理解这个遭受攻击的问题:
如 果每个处理器都有一个反映内存不同部分状态的高速缓存,就可能会有两个或更多高速缓存拥有相同线路的副本。也有可能是一个给定的线路会包含不止一个可锁定 的数据项。如果两个线程对那些数据项作了适当的序列化更改,结果可能是两个高速缓存都以不同的,错误版本的内存线路而告终。换句话说,系统的状态不再一 致,因为系统包含了应该是一个特定内存区域的内容的两个不同版本。
对高速缓存一致性问题的解决方案通常包括在线路修改之后,除了一条线路以外,使所有重复线路都失效。尽管硬件使用监视逻辑使线路失效,没有任何软件干预的话,任何高速缓存线路已经失效的处理器由于随之而来的延迟,将会在下一次寻址到该线路时出现高速缓存未命中。
监视是用来解决高速缓存一致性问题的逻辑。处理器中的监视逻辑每次修改了其高速缓存中的一个字后,会在总线上广播一条消息。监视逻辑也在总线上监视,寻找来自其它处理器的这种消息。
当 一个处理器检测到另一个处理器已经更改了存在于它本身高速缓存内的一个地址的值时,监视逻辑会使得它自己的高速缓存中的该项失效。这被称为交叉式失效。交 叉式失效提醒处理器高速缓存中的值已经无效了,处理器必须在别处(内存或其它高速缓存)寻找正确的值。由于交叉式失效增加了高速缓存未命中率,而监视协议 增加了总线流量,因而解决高速缓存的一致性问题会降低所有 SMP 的性能和可伸缩性。
处理器相似性和绑定
如果一个线程中断后又 重新分派到同一个处理器中,该处理器的高速缓存也许仍含有属于该线程的线路。如果该线程被分派到不同的处理器,它将很可能经历一系列高速缓存未命中,直到 它的高速缓存工作集从 RAM 或其它处理器的高速缓存中检索到。另一方面,如果一个可分派的线程必须等到它先前在其中运行的处理器可用,该线程也许会经历一个更长的延迟。
处理器相似性是指将一个线程分派到先前运行它的处理器之上的概率。对处理器相似性的强调程度应随线程的高速缓存工作集大小直接变化,而随自它上一次分派以来的时间长短反向变化。AIX V4 分派器强制对处理器的相似性,因此相似性是由操作系统暗中完成的。
最 高程度的处理器相似性是把一个线程绑定到一个特定处理器上。绑定意味着线程将只分派到该处理器,不管其它处理器是否可用。bindprocessor 命令和 bindprocessor() 子例程将一个特定进程的线程绑定到一个特殊的处理器(参阅 bindprocessor 命令)上。显式绑定是通过 fork() 和 exec() 系统调用继承而来的。
绑定对于 CPU 密集的很少经历中断的程序是有用的。有时,它对一般的程序可能会有反作用,因为它也许会在一个 I/O 之后延迟对一个线程的重新分派,直到线程所绑定的处理器变得可用。如果线程已阻塞了一个 I/O 操作的持续时间,它的处理上下文中的大部分不太可能还保留在它所绑定的处理器的高速缓存中。如果该线程被分派到下一个可用的处理器中,它很可能会得到更好 的服务。
内存和总线争用
在一个单处理器中,一些内部资源(例如内存条和 I/O 或者内存总线)的争用通常是组件使用时间的一小部分。在一个多处理器中,这些影响会变得更重要,特别是如果高速缓存一致性算法增加了对 RAM 的访问数量
SMP 性能问题
为了有效使用 SMP,当您尝试提高性能时请考虑以下问题:
工作负载并行性
SMP 系统特有的主要性能问题是工作负载的并行性,这个问题可以这样表达:“现在我们有 n 个处理器,我们如何保持它们全都有效地工作”?如果在任何指定时间,一个四路的多处理器系统中只有一个处理器在做有用功,则它比一个单处理器好不了多少。 由于用来避免处理器间干扰的额外代码,它可能会更糟。
工作负载并行性是序列化的补充。在系统软件或应用程序工作负载(或者是这两者之间的交互作用)要求序列化这一点上,工作负载并行性就得遭受损失。
工作负载并行性也可以通过增加处理器相似性来更像期望的那样下降。从处理器相似性得来的提高的高速缓存效率可能会使得程序更快的完成。工作负载并行性是降低了(除非有更多可分派的线程处于可用状态),但是响应时间得到了改善。
工作负载并行性的一个组成部分,进程并行性,是指一个多线程进程在任何时候都拥有多个可分派线程的程度。
吞吐量
一个 SMP 系统的吞吐量主要由以下因素决定:
一直处于高级别的工作负载并行性。处理器在特定时间里拥有更多的可分派线程并不能补偿一些处理器在其它时间闲置的情况。
锁争用的数量。
处理器相似性的程度。
响应时间
一个处于 SMP 系统中的特定程序的响应时间取决于:
该程序的进程并行性级别。如果该程序一直拥有两个或更多可分派线程,它的响应时间很可能会在 SMP 环境里得到改善。如果程序只包含一个单独的线程,它的响应时间最多也就是和一个处于相同速度单处理器中的程序相当。
与程序其它实例或者其它使用相同锁的程序之间的锁争用的数量。
程序对处理器的相似性程度。如果程序每次都被分派到不同的处理器中,该处理器中没有它的任何高速缓存线,则该程序可能会比在一个相当的单处理器中运行得更慢。
工作负载多处理
在 快速计算机上运行繁重工作负载的多程序设计操作系统给人的感觉印象是有几件事情在同时发生。事实上,很多费力的工作负载在任意给定时刻并没有大量的可分派 线程,即使是当它运行在一个序列化相对来说不是大问题的单处理器系统中时。除非至少总是有与处理器一样多的可分派线程,要不然总有一个或多个处理器在一部 分时间里闲置。
可分派线程的数量是系统中线程的总数
减去正在等待 I/O 的线程数,
减去正在等待共享资源的线程数,
减去正在等待另一个线程结果的线程数,
减去正对它们自己的请求睡眠的线程数。
工 作负载据说是可以多处理的,从这一点来说,它不论何时都显示出与系统中的处理器数一样多的可分派线程数。请注意,这并不只意味着可分派线程的平均数量和处 理器一样多。如果可分派线程数在一半时间里为零,剩余时间里是处理器计数的两倍,则可分派线程的平均数将等于处理器数,但是系统里任一给定的处理器只能在 一半时间里工作。
增加工作负载的多处理性涉及到以下的一个或两个方面:
确认并解决引起线程等待的任何瓶颈
增加系统中的线程总数
这些解决方案不是独立的。假如有一个单独的、主要的系统瓶颈,增加现有的通过该瓶颈的工作负载的线程数将只会仅仅增加线程等待的比例。假如目前没有瓶颈,增加线程数可能会创建一个瓶颈。
多处理器吞吐量可伸缩性
实际工作负载并不能在 SMP 系统中极佳的伸缩。一些禁止极佳伸缩的因素如下所述:
当处理器的数量增加时,总线/开关的争用也增加。
内存争用增加(所有内存都为所有处理器共享)
随着内存不断消耗,高速缓存未命中的成本增加
高速缓存交叉式失效和读取另一个高速缓存以保持高速缓存一致性
由于更高分派率而引起的增加的高速缓存未命中(更多的进程/线程需要在系统中分派)
增加的同步指令成本
由于更大的操作系统和应用程序数据结构而增加的高速缓存未命中
为锁定/解锁而增加的操作系统和应用程序路径长度
由于等待锁而增加的操作系统和应用程序路径长度
所 有这些因素都对称为工作负载的可伸缩性起作用。可伸缩性是工作负载吞吐量受益于其它处理器可用性的程度。它通常表示为一个多处理器的工作负载吞吐量由一个 相当的单处理器的吞吐量所除得到的商。例如,如果一个单处理器在给定的工作负载下每秒获得 20 个请求,而一个四处理器的系统每秒获得 58 个请求,则比例因子将是 2.9。这个工作负载是高度可伸缩的。一个专门由长期运行、计算机密集的程序组成的工作负载,如果其 I/O 或其它内核活动是可忽略的,并且没有共享数据,则可以在一个四路系统中达到 3.2 到 3.9 的比例因子。然而,现实中大多数工作负载不能达到这个水平。由于可伸缩性是很难估计的,可伸缩性的假设应基于真实工作负载的评估值。
在多 处理器上,两个处理器处理程序执行,但是仍然只有一个锁。为简单起见,显示了所有影响处理器 B 的锁争用。在所示的时间段里,多处理器处理 14 个命令。因此比例因子为 1.83。我们只讨论两个处理器,因为更多处理器的情况不会有什么变化。现在锁在 100% 的时间里都处于使用状态。在一个四路的多处理器中,比例因子可能是 1.83 或更小。
实际程序很少会像插图中的命令那样对称。另外,我们仅仅考虑了争用的一个尺度:锁定。如果我们把高速缓存一致性和处理器相似性的影响包括进来,无疑比例因子几乎会更小。
该示例说明了工作负载通常不能通过简单添加处理器来使它更快运行。确定和最小化线程之间的争用源也是必要的。
伸缩是与工作负载相关的。一些公布的基准程序暗示高水平的可伸缩性是容易获得的。大多数这样的基准程序是通过运行小型的 CPU 密集程序的组合而构造出来的,这些 CPU 密集程序几乎不用什么内核服务。这些基准程序的结果代表了可伸缩性的上限,而不是现实期望。
基准程序的另一个值得注意的有趣观点是通常情况下,一个单路 SMP 的运行速度会比运行操作系统的 UP 版本的同等单处理器慢(大约 5%-15%)。
多处理器响应时间
一个多处理器只能把一个独立程序的执行时间改进到让该程序可以多线程方式运行的程度。有几种方法可以让一个单独程序的某些部分实现并行执行:
显式调用 libpthreads.a 子例程(或者,在老式程序里调用 fork() 子例程)来创建多个同时运行的线程。
用一个并行化的编译器或者预处理器处理程序,该编译器或预处理器会检测到可同时执行的代码序列,并生成多个线程来并行运行这些代码。
使用一个本身是多线程的软件包。
除非使用这些技术的一种或多种,程序在一个多处理器系统中不会比在一个相当的单处理器中运行得快。事实上,由于程序会经历更多的锁定开销和在不同时间分派到不同处理器而产生的延迟,它有可能会更慢。
即使所有可用的技术都用到了,最大限度的改进也受到一个称为“Amdahl 定律”规则的限制。
举例来说,如果一个程序的 50% 的处理必须顺序执行,50% 可以并行执行,则最大的响应时间改进小于因子 2(在另一个闲置的 4 路多处理器中,该值至多为 1.6)。 -
软件测试基础知识
2013-01-25 14:20:56
软件测试基础知识
一、软件测试概述
软件测试是软件开发过程的重要组成部分,是用来确认一个程序的品质或性能是否符合开发之前所提出的一些要 求。软件测试的目的,第一是确认软件的质量,其一方面是确认软件做了你所期望的事情(Do the right thing),另一方面是确认软件以正确的方式来做了这个事件(Do it right)。第二是提供信息,比如提供给开发人员或程序经理的反馈信息,为风险评估所准备的信息。第三软件测试不仅是在测试软件产品的本身,而且还包括 软件开发的过程。如果一个软件产品开发完成之后发现了很多问题,这说明此软件开发过程很可能是有缺陷的。因此软件测试的第三个目的是保证整个软件开发过程 是高质量的。
软件质量是由几个方面来衡量的:一、在正确的时间用正确的的方法把一个工作做正确(Doing the right things right at the right time.)。二、符合一些应用标准的要求,比如不同国家的用户不同的操作习惯和要求,项目工程中的可维护性、可测试性等要求。三、质量本身就是软件达到 了最开始所设定的要求,而代码的优美或精巧的技巧并不代表软件的高质量(Quality is defined as conformance to requirements, not as “goodness” or “elegance”.)。四、质量也代表着它符合客户的需要(Quality also means “meet customer needs”.)。作为软件测试这个行业,最重要的一件事就是从客户的需求出发,从客户的角度去看产品,客户会怎么去使用这个产品,使用过程中会遇到什么 样的问题。只有这些问题都解决了,软件产品的质量才可以说是上去了。
测试人员在软件开发过程中的任务:
1、寻找Bug;
2、避免软件开发过程中的缺陷;
3、衡量软件的品质;
4、关注用户的需求。
总的目标是:确保软件的质量。
二、常用的软件测试方法
1. 黑盒测试
黑盒测试顾名思义就是将被测系统看成一个黑盒,从外界取得输入,然后再输出。整个测试基于需求文档,看是否能满足需求文档中的所有要求。黑盒测试要求测试者在测试时不能使用与被测系统内部结构相关的知识或经验,它适用于对系统的功能进行测试。
黑盒测试的优点有:
1)比较简单,不需要了解程序内部的代码及实现;2)与软件的内部实现无关;
3)从用户角度出发,能很容易的知道用户会用到哪些功能,会遇到哪些问题;
4)基于软件开发文档,所以也能知道软件实现了文档中的哪些功能;
5)在做软件自动化测试时较为方便。
黑盒测试的缺点有:
1)不可能覆盖所有的代码,覆盖率较低,大概只能达到总代码量的30%;2)自动化测试的复用性较低。
2. 白盒测试
白盒测试是指在测试时能够了解被测对象的结构,可以查阅被测代码内容的测试工作。它需要知道程序内部的设计结构及具体的代码实现,并以此为基础来设计测试用例。如下例程序代码:
HRESULT Play( char* pszFileName )
{
if ( NULL == pszFileName )
return;
if ( STATE_OPENED == currentState )
{
PlayTheFile();
}
return;
}
读了代码之后可以知道,先要检查一个字符串是否为空,然后再根据播放器当前的状态来执行相应的动作。可以这样设计一些测试用例:比如字符串(文件)为空的 话会出现什么情况;如果此时播放器的状态是文件刚打开,会是什么情况;如果文件已经在播放,再调用这个函数会是什么情况。也就是说,根据播放器内部状态的 不同,可以设计很多不同的测试用例。这些是在纯粹做黑盒测试时不一定能做到的事情。
白盒测试的直接好处就是知道所设计的测试用例在代码级上哪些地方被忽略掉,它的优点是帮助软件测试人员增大代码的覆盖率,提高代码的质量,发现代码中隐藏的问题。
白盒测试的缺点有:
1)程序运行会有很多不同的路径,不可能测试所有的运行路径;
2)测试基于代码,只能测试开发人员做的对不对,而不能知道设计的正确与否,可能会漏掉一些功能需求;
3)系统庞大时,测试开销会非常大。
3. 基于风险的测试
基于风险的测试是指评估测试的优先级,先做高优先级的测试,如果时间或精力不够,低优先级的测试可以暂时 先不做。有如下一个图,横轴代表影响,竖轴代表概率,根据一个软件的特点来确定:如果一个功能出了问题,它对整个产品的影响有多大,这个功能出问题的概率 有多大?如果出问题的概率很大,出了问题对整个产品的影响也很大,那么在测试时就一定要覆盖到。对于一个用户很少用到的功能,出问题的概率很小,就算出了 问题的影响也不是很大,那么如果时间比较紧的话,就可以考虑不测试。
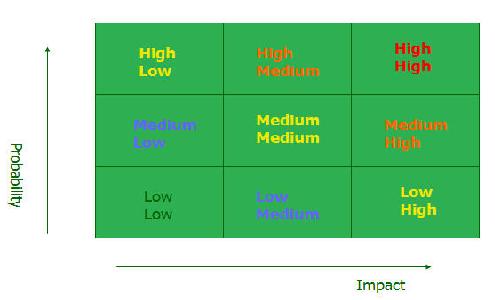
基于风险测试的两个决定因素就是:该功能出问题对用户的影响有多大,出问题的概率有多大。其它一些影响因素还有复杂性、可用性、依赖性、可修改性等。测试人员主要根据事情的轻重缓急来决定测试工作的重点。
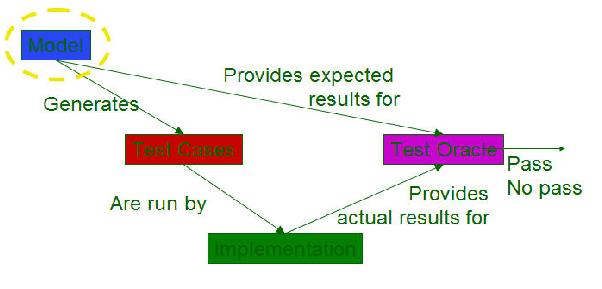
4. 基于模型的测试
模型实际上就是用语言把一个系统的行为描述出来,定义出它可能的各种状态,以及它们之间的转换关系,即状态转换图。模型是系统的抽象。基于模型的测试是利用模型来生成相应的测试用例,然后根据实际结果和原先预想的结果的差异来测试系统,过程如下图所示。
三、软件测试的类型
常见的软件测试类型有:
BVT (Build Verification Test)
BVT是在所有开发工程师都已经检入自己的代码,项目组编译生成当天的版本之后进行,主要目的是验证最新 生成的软件版本在功能上是否完整,主要的软件特性是否正确。如无大的问题,就可以进行相应的功能测试。BVT优点是时间短,验证了软件的基本功能。缺点是 该种测试的覆盖率很低。因为运行时间短,不可能把所有的情况都测试到。
Scenario Tests(基于用户实际应用场景的测试)
在做BVT、功能测试的时候,可能测试主要集中在某个模块,或比较分离的功能上。当用户来使用这个应用程序的时候,各个模块是作为一个整体来使用的,那么 在做测试的时候,就需要模仿用户这样一个真实的使用环境,即用户会有哪些用法,会用这个应用程序做哪些事情,操作会是一个怎样的流程。加了这些测试用例 后,再与BVT、功能测试配合,就能使软件整体都能符合用户使用的要求。Scenario Tests优点是关注了用户的需求,缺点是有时候难以真正模仿用户真实的使用情况。
Smoke Test
在测试中发现问题,找到了一个Bug,然后开发人员会来修复这个Bug。这时想知道这次修复是否真的解决了程序的Bug,或者是否会对其它模块造成影响, 就需要针对此问题进行专门测试,这个过程就被称为Smoke Test。在很多情况下,做Smoke Test是开发人员在试图解决一个问题的时候,造成了其它功能模块一系列的连锁反应,原因可能是只集中考虑了一开始的那个问题,而忽略其它的问题,这就可 能引起了新的Bug。Smoke Test优点是节省测试时间,防止build失败。缺点是覆盖率还是比较低。
此外,Application Compatibility Test(兼容性测试),主要目的是为了兼容第三方软件,确保第三方软件能正常运行,用户不受影响。Accessibility Test(软件适用性测试),是确保软件对于某些有残疾的人士也能正常的使用,但优先级比较低。其它的测试还有Functional Test(功能测试)、Security Test(安全性测试)、Stress Test(压力测试)、Performance Test(性能测试)、Regression Test(回归测试)、Setup/Upgrade Test(安装升级测试)等。
四、微软的软件测试工作
1. 基本情况
测试在微软公司是一项非常重要的工作,微软公司在此方面的投入是非常巨大的。微软对测试的重视表现在工程开发队伍的人员构成上,微软的项目经理、软件开发 人员和测试人员的比例基本是1:3:3或1:4:4,可以看出开发人员与测试人员的比例是1:1。对于测试的重视还表现在最后产品要发布的时候,此产品的 所有相关部门都必须签字,而测试人员则具有绝对的否决权。
测试人员中分成两种职位,Software Development Engineer in Test(测试组的软件开发工程师)实际上还是属于开发人员,他们具备编写代码的能力和开发工具软件的经验,侧重于开发自动化测试工具和测试脚本,实现测 试的自动化。Software Test Engineer(软件测试工程师)具体负责测试软件产品,主要完成一些手工测试以及安装配置测试。
2. 测试计划
测试计划是测试人员管理测试项目,在软件中寻找Bug的一种有效的工具。测试计划主要有两个作用,一是评判团队的测试覆盖率以及效率,让测试工作很有条理 的逐步展开。二是有利于与项目经理、开发人员进行沟通。有了测试计划之后,他们就能够知道你是如何开展测试工作的,他们也会从中提出很多有益的意见,确保 测试工作顺利进行。总之,有了测试计划可以更好的完成测试工作,确保用户的满意度。
测试人员在编写测试计划之前,应获得以下文档:
1)程序经理编写的产品功能说明书或产品开发计划;
2)程序经理或开发人员提供的开发进度表。
根据产品的特性及开发进度安排,测试人员制定具体的测试计划。测试计划通常包括以下内容:
1)测试目标和发布条件:
a. 给出清晰的测试目标描述;
b. 定义产品的发布条件,即在达到何种测试目标的前提下才可以发布产品的某个特定版本。
2)待测产品范围:
a. 软件主要特性/功能说明,即待测软件主要特性的列表;
b. 特性/功能测试一览,应涵盖所有特性、对话框、菜单和错误信息等待测内容,并列举每个测试范围内要重点考虑的关键功能。
3)测试方法描述:
a. 定义测试软件产品时使用的测试方法;
b. 描述每一种特定的测试方法可以覆盖哪些测试范围。
4)测试进度表:
a. 定义测试里程碑;
b. 定义当前里程碑的详细测试进度。
5)测试资源和相关的程序经理/开发工程师:
a. 定义参与测试的人员;
b. 描述每位测试人员的职责范围;
c. 给出与测试有关的程序经理/开发工程师的相关信息。
6)配置范围和测试工具:
a. 给出测试时使用的所有计算机平台列表;
b. 描述测试覆盖了哪些硬件设备;
c. 测试时使用的主要测试工具。
此外,还应列出测试中可能会面临的风险及测试的依赖性,即测试是否依赖于某个产品或某个团队。比如此项测试依赖性WindowsCE这个操作系统,而这个 系统要明年2月份才能做好,那么此项测试就可能只有在明年5月份才能完成,这样就存在着依赖关系。如果那个团队的开发计划往后推,则此项测试也会被推迟。
3. 测试用例开发
一个好的测试用例就是有一个合理的概率来找到Bug,不要冗余,要有针对性,一个测试只针对一件事情。特别是功能测试的时候,如果一个测试是测了两项功能,那么如果测试结果失败的话,就不知道到底是哪项功能出了问题。
测试用例开发中主要使用的技术有等价类划分,边界值的分析,Error Guessing Testing。
等价类划分是根据输入输出条件,以及自身的一些特性分成两个或更多个子集,来减少所需要测试的用例个数,并且能用很少的测试用例来覆盖很多的情况,减少测试用例的冗余度。在等价类划分中,最基本的划分是一个为合法的类,一个为不合法的类。
边界值的分析是利用了一个规律,即程序最容易发生错误的地方就是在边界值的附近,它取决于变量的类型,以及变量的取值范围。一般对于有n个变量时,会有6n+1个测试用例,取值分别是min-1, min, min+1, normal, max-1, max,max+1的组合。边界值的分析的缺点,是对逻辑变量和布尔型变量不起作用,还有可能会忽略掉某些输入的组合。
Error Guessing Testing完全靠的是经验,所设计的测试用例就是常说的猜测。感觉到软件在某个地方可能出错,就去设计相应的测试用例,这主要是靠实际工作中所积累的 经验和知识。其优点是速度快,只要想得到,就能很快设计出测试用例。缺点就是没有系统性,无法知道覆盖率会有多少,很可能会遗漏一些测试领域。
实际上在微软是采用一些专门的软件或工具负责测试用例的管理,有一些测试信息可以被记录下来,比如测试用例的简单描述,在哪些平台执行,是手工测试还是自 动测试,运行的频率是每天运行一次,还是每周运行一次。此外还有清晰的测试通过或失败的标准,以及详细记录测试的每个步骤。
4. Bug跟踪过程
在软件开发项目中,测试人员的一项最重要使命就是对所有已知Bug进行有效的跟踪和管理,保证产品中出现的所有问题都可以得到有效的解决。一般地,项目组发现、定位、处理和最终解决一个Bug的过程包括Bug报告、Bug评估和分配、Bug处理、Bug关闭等四个阶段:
1)测试工程师在测试过程中发现新的Bug后,应向项目组报告该Bug的位置、表现、当前状态等信息。项目组在Bug数据库中添加该Bug的记录。
2)开发经理对已发现的Bug进行集中讨论,根据Bug对软件产品的影响来评估Bug的优先级,制定Bug的修正策略。按照Bug的优先级顺序和开发人员的工作安排,开发经理将所有需要立即处理的Bug分配给相应的开发工程师。
3)开发工程师根据安排对特定的Bug进行处理,找出代码中的错误原因,修改代码,重新生成产品版本。
4)开发工程师处理了Bug之后,测试人员需要对处理后的结果进行验证,经过验证确认已正确处理的Bug被标记为关闭(Close)状态。测试工程师既需要验证Bug是否已经被修正,也需要确定开发人员有没有在修改代码的同时引入新的Bug。
5. Bug的不同处理方式
在某些情况下,Bug已处理并不意味着Bug已经被修正。开发工程师可以推迟Bug的修正时间,也可以在分析之后告知测试工程师这实际上不是一个真正的Bug。也就是说,某特定的Bug经开发工程师处理之后,该Bug可能包括以下几种状态。
已修正:开发工程师已经修正了相应的程序代码,该Bug不会出现了。
可推迟:该Bug的重要程度较低,不会影响当前应提交版本的主要功能,可安排在下一版本中再行处理。
设计问题:该Bug与程序实现无关,其所表现出来的行为完全符合设计要求,对此应提交给程序经理处理。
无需修正:该Bug的重要程度非常低,根本不会影响程序的功能,项目组没有必要在这些Bug上浪费时间。
五、成为优秀测试工程师的要求
要成为一名优秀的测试工程师,首先对计算机的基本知识要有很好的了解,精通一门或多门的编程语言,具备一定的程序调试技能,掌握测试工具的开发和使用技 术。同时要比较细心,会按照任务的轻重缓急来安排自己的工作,要有很好的沟通能力。此外,还要善于用非常规的方式思考问题,尽可能多的参加软件测试项目, 在实践中学习技能,积累经验,不断分析和总结软件开发过程中可能出错的环节。这样,一名优秀的测试工程师就从软件测试的实践中脱颖而出了。
结束语:微软的软件开发经验积淀深厚,微软工程师们的授课生动溢彩,其中有些内容是结合编程代码所作的详细讲解,较难用介绍性文字加以概括提炼,加之笔者 受能力和精力所限,只能撷取部分精华内容整理成文以飨读者,因此难免是挂一漏万,甚至会有失误之处,敬请对本系列文章的关注者谅解及指正。最后对微软老师 们的辛勤付出再表由衷谢意!
-
java学习系列(三)--面向对象编程
2013-01-18 17:13:10
一、面向对象的基本思想
从现实世界中客观存在的事物出发来构造软件系统,并在系统的构造中尽可能运用人类的自然思维方式
1.考虑这个问题里面应该有哪些个类哪些个对象
2.考虑这些个类里面的每种类每种对象具有哪些个属性和方法
3.考虑类和类之间具备的关系
二、对象和类的概念
对象用计算机语言对问题域中事物的描述,对象通过属性和方法来分别对应事物所具有的静态属性和动态属性
类是用于描述同一类型的对象的一个抽象的概念,类中定义了这一类对象具有的静态和动态属性
类可以看成一类对象的模版,对象可以看成该类的一个具体实例
三、关系
1.关联关系
2.继承关系
3.聚合关系(整体和部分)
4.实现关系
四、java和面向对象
1.必须首先定义类,才有对象
2.万事万物皆对象
3.对象可以看成是静态属性(成员变量) 和动态属性(方法)的封装体
五、类的定义
1.类的定义主要有两方面组成--成员变量和方法
2.成员变量:先声明,可以初始化,也可以不初始化;
3.局部变量:先声明,必须初始化
4.引用变量:占用2个字节
5.new出来的东西都存放在内存的stack中
6.如何在内存中区分类和对象
类是静态的概念,代码区中
对象是new出来的,位于堆内存,类的每个成员变量在不同的对象中都有不同的值(除了静态变量)
7.对象的创建和使用
a.必须使用new关键字创建对象
b.使用对象(引用).成员变量或来引用的成员变量
c.使用对象(引用).方法来调用对象的方法
d.同一类的每个对象有不同的成员变量存储空间
e.同一类的每个对象共享该类的方法,非静态方法是针对每个对象进行调用
六、构造方法(构造函数)
1.使用new+构造方法 创建一个新的对象
2.构造函数是定义在java类中的一个用来初始化对象的函数
3.构造函数和类同名,且没有返回值
4.当没有指定构造函数时,编译器为类自动添加构造函数
七、类的约定俗成的命名规则
1.类名首字母大写
2.变量名和方法名的首字母小写
3.运用驼峰标识
八、方法的重载
1.方法的重载是指一个类中可以定义有相同的名字,但参数不同的多个方法。调用时,会根据不同的参数来选择对应的方法
2.与普通方法一样,构造方法也可以重载
3.this 关键字
*this可以看作是一个变量,一般在方法里面,是执行自身对象的引用
*在类的方法定义中使用的this关键字代表使用该方法的对象的引用
*有时使用this可以处理方法中成员变量和参数重名的情况
*当你确定不了一个参数到底它是指向哪个变量,找离它最近的声明
4.static关键字
*在类中,用static声明的成员变量为静态成员变量,它为该类的公用变量,在第一次使用时被初始化,对于该类的所有对象来说,static成员变量只有一份
*方法是针对某一个对象来调用的
*用static声明的方法为静态方法,在调用该方法时,不会将对象的引用传递给它,所以在static方法中不可访问非static的成员。
*可以通过对象引用或类名(不需要实例化)访问静态变量
九、package和import语句
1.为了解决类的命名冲突问题,java引入包的机制,提供类的多重类命名空间
*package作为java源文件的第一条语句,指明该文件中定义的类所在的包(若缺省该语句,则为无名包)
*如果你要把一个类放在包里面,第一句话写package,package后面想跟多少层包就跟多少层包,不过注意点是,你编译出来的这个class文件,必须位于正确的目录下面,正确的目录是指和包的层次完全一致。
*如果你想在另外一个类里面使用我这个类,必须将这个类名字写全了 。访问位于同一个包下的类不需要引用
*必须class文件的最上层包的父目录位于classpath下
*执行一个类需要写全包名
2.J2SDK中主要的包介绍
*java.lang--包含一些java语言的核心类,如String、Math、Integer、System和Thread,提供常用功能;*java.lang里面的类除了String不需要引用,其他的类都需要引用
*java.awt--包含了构成抽象窗口工具集的多个类,这些类被用来构建和管理应用程序的图形用户界面
*java.net--包含执行与网络相关的操作的类
*java.io--包含能提供多种输入输出功能的类
*java.util--包含一些实用工具类,如定义系统特性,使用与日期日历相关的函数
十、类的继承与权限控制
1.继承
java中使用extends关键字实现类的继承机制
*通过继承,子类自动拥有了基类(superclass)的所有成员(成员变量和方法)
*java只支持单继承,不允许多继承;一个子类只能有一个基类,一个基类可以派生出多个子类
2.访问控制
java权限修饰符有四种:
private:最严格的修饰符 类内部可以访问,同一个包、子类、任何地方不能访问
default:类内部、同一个包可以访问,子类、任何地方不能访问
protected:类内部、同一个包、子类可以访问,任何地方不能访问
public:类内部、同一个包、子类、任何地方都可以访问
*对于class的权限修饰只可以用public和default,default类只可以被同一个包内部的类访问
十一、方法的重写
1.在子类中可以根据需要对从基类中继承来的方法进行重写
2.重写方法必须和被重写方法具有相同方法名称、参数列表和返回类型
3.重写方法不能使用比被重写方法更严格的访问权限
4.重写的时候,最好的办法,就是copy父类中要重写的方法
十二、super关键字
1.java类中使用super来引用当前对象的基类的对象
十三、继承中的构造方法
1.子类的构造的过程中必须调用其基类的构造方法
2.子类可以在自己的构造方法中使用super(argument_list)调用基类的构造方法;使用this(argument_list)调用本类的另外的构造方法;如果调用super,必须写在子类构造方法的第一行;
3.如果子类的构造方法中没有显式地调用基类构造方法,则系统默认调用基类无参数的构造方法
4.如果子类构造方法中既没有显式调用基类构造方法,而基类中没有无参数的构造方法,则编译出错
十四、Object类
1.Object类是所有java类的根基类
2.如果在类的声明中未使用extends关键字指明其基类,则默认基类为Object类
3.toString方法
Object类中定义有public String toString()方法,其返回值为String类型,描述当前对象的有关信息
在进行String与其类型数据的连接操作时,将自动调用该对象类的toString()方法
可以根据需要在用户自定义类型中重写toString()方法
4.哈希编码独立无二的代表一个对象,并且通过哈希编码找到这个对象
5.equals方法
十五、对象转型(casting)
1.一个基类的引用类型变量可以指向其子类的对象
2.一个基类的引用不可以访问其子类对象新增加的成员(属性和方法)
3.可以使用引用变量instanceof类名来判断该引用型变量所指向的对象是否属于该类和该类的子类
4.子类的对象可以当作基类的对象来使用称做向上转型(upcasting),反之称为向下转型(downcasting)
十六、动态绑定和多态
1.动态绑定是指在执行期间(而非编译期)判断所引用对象的实际类型,根据其实际的类型调用其相应的方法
2.帮助程序扩展性达到极致
3.多态存在的三个条件
要有继承
要有重写
父类引用指向子类对象
十七、抽象类
1.用abstract关键字来修饰一个类时,这个类叫做抽象类;用abstract来修饰一个方法时,该方法叫做抽象方法;
2.含有抽象方法的类必须被声明为抽象类,抽象类必须被继承,抽象方法必须被重写
3.抽象类不能被实例化
4.抽象方法只需声明,而不需实现
十八、final关键字
1.final的变量的值不能被改变
包括final的成员变量,final的局部变量(形参)
2.final的方法不能被重写
3.final的类不能被继承
十九、接口
定义:接口(interface)是抽象方法和常量值的定义的集合
从本质上讲,接口是一种特殊的抽象类,这种抽象类中只包含常量和方法的定义,而没有变量和方法的实现
1.多个无关的类可以实现同一个接口
2.一个类可以实现多个无关的接口
3.与继承关系类似,接口与实现类之间存在多态性
*接口特性
1.接口可以实现多重继承
2.接口中声明的属性默认为public static final的,也只能是public static final的
3.接口中只能定义抽象方法,而且这些方法默认为public的,也只能是public的
4.接口可以继承其他的接口,并添加新的属性和抽象方法 -
java学习系列(四)--异常处理
2013-01-18 17:10:28
***观察错误的名字和行号最重要
**捕获异常的时候,先捕获小的异常,再捕获大的异常
一、异常的概念
1.java异常是java提供的用于处理程序中错误的一种机制
2.所谓错误是指在程序运行的过程中发生的一些异常事件(如:除0溢出,数组下标越界,所要读取的文件不存在)
3.设计良好的程序应该在异常发生时提供处理这些错误的方法,使得程序不会因为异常的发生而阻断或产生不可预见的结果
4.java程序的执行过程中如出现异常事件,可以生成一个异常类对象,该异常对象封装了异常事件的信息并将提交给java运行时系统,这个过程成为抛出(throw)异常
5.当java运行时系统接收到异常对象时,会寻找能处理这一异常的代码并把当前异常对象交给其处理,这一过程称为捕获(catch)异常
二、异常的分类
Throwable:可被抛出的异常
Error:系统错误,不能处理的
Exception:可以被处理的异常 RuntimeException和其他错误
*Error:称为错误,由java虚拟机生成并抛出,包括动态链接失败,虚拟机错误等,程序对其不做处理
*Exception:所有异常类的父类,其子类对应了各种各样可能出现的异常事件,一般需要用户显式的声明或捕获
*Runtime Exception:一类特殊的异常,如被0除、数组下标越界等,其产生比较频繁,处理麻烦,如果显式的声明或捕获将会对程序可读性和运行效率影响很大。因此由系统自行检测并将它们交给缺省的异常处理程序(用户可不必对其处理)
三、异常的捕获和处理
1.try代码段包含可能产生例外的代码
2.
*try语句
try {...}语句指定了一段代码,该段代码就是一次捕获并处理例外的范围。
在执行过程中,该段代码可能会产生并抛出一种或几种类型的异常对象,它后面的catch语句要分别对这些异常做相应的处理。
如果没有例外产生,所有的catch代码段都被略过不执行。
*catch语句
在catch语句块中是对异常进行处理的代码,每个try语句块可以伴随一个或多个catch语句,用于处理可能产生的不同类型的异常对象。
在catch中声明的异常对象(catch (SomeException e))封装了异常事件发生的信息,在catch语句块中可以使用这个对象的一些方法获取这些信息。
例如:
getMessage()方法,用来得到有关异常事件的信息
printStackTrace()方法,用来跟踪异常事件发生时执行堆栈的内容。
*finally语句
finally语句为异常处理提供一个统一的出口,使得在控制流程转到程序的其他部分一起,能够对程序的状态做统一的管理。
无论try所指定的程序块中是否抛出例外,finally所指定的代码都要被执行。
通常在finally语句中可以进行资源的清除工作,如关闭打开的文件,删除临时文件
**重写方法需要抛出与原方法所抛出异常类型一致异常或不抛出异常。 -
java学习系列(二)--基础语法
2013-01-18 16:17:50
一、标识符
1.由字母、下划线、美元符或数字组成
2.以字母、下划线、美元符开头,不能以数字开头
3.大小写敏感,长度无限制
4.约定俗成:标识符名字是见名知意
二、关键字
1.都是小写英文
2.goto和const虽未被使用,但被当作关键字保留
三、常量
值不变被改变的变量
四、变量
1.变量其实是内存中的一小块区域,使用变量名来访问这块区域。
2.每个变量都属于特定的数据类型,使用前必须要先声明,然后再赋值。
3.程序执行过程
程序--》load到内存中--》代码(main方法开始)--》执行过程中的内存管理
内存管理:
code segment:存放代码
data segment:静态变量 字符串常量
stack:局部变量
heap:new出来的东西
4.变量的分类
a.按声明分类:局部变量 和 成员变量
局部变量:方法体内
成员变量:方法体外,类体内
**方法的参数属于局部变量
5.数据类型划分
1).基本数据类型
4类8种:逻辑型(boolean)、文本型(char)、整数型(byte、short、int、long)、浮点类型(float、double)
a.字符型
java字符采用Unicode编码,每个字符占两个字节 (Unicode是全球语言统一编码)
Unicode分为UTF-8和UTF-16
*2进制、10进制、16进制之间的转换
1101变成10进制 1 x 1 + 0 x 2 + 1 x 4 + 1 x 8
13变成2进制 1 + 4 + 8 --> 1101
1101变成16进制:先转换成10进制13,再转换成16进制D
b.整数类型
bype:占1字节 表数范围:-128 ~ 127
short:占2字节 表数范围:-2的15次方 ~ 2的15次方-1
int:占4字节 表数范围:-2的31次方 ~ 2的31次方-1
long:占8字节 表数范围:-2的63次方 ~ 2的63次方-1
*java语言的整型常量默认为int型,声明long常量可以后加'l'或'L',一般使用'L',如long l1 = 888888888L;
c.浮点类型
float:占4字节 表数范围:-3.403E38 ~ 3.403E38 精确度为7位
double:占8字节 表数范围:-1.798E308 ~ 1.798E308 精确度为15位
*java浮点型常量默认为double型,声明一个常量为float型,需要在数字后加'f'或'F',如float f1 = 0.11f;
2)基本数据类型转换
a.boolean类型不可以转换成其他数据类型
b.整型,字符型,浮点型的数据在混合运算中国互相转换,转换遵循以下原则:
*容量小的自动转换为容量大的,数据类型按容量大小排序为:
bype,short,char->int->long->float->double
*int转换成bype时,数值溢出时不会报错;double转换成float时,数值溢出时会报错;
原因:因为double或float在内存中有部分专门记录小数点
*bype,short,char之间不会互相转换,三者在计算时首先会转化为int类型
*容量大的转换为容量小时,要加上强制转换
*有多种类型的数据混合运算时,系统自动将所有数据转换成容量最大的那一种数据类型,然后再计算
******程序格式******
a.大括号对齐
b.遇到{时,要缩进,使用Tab,向右缩进;使用Shift+Tab,向左缩进;
c.程序块之间加空行
d.并排语句之间加空格
e.运算符两侧加空格
f.{前面有空格
g.成对编程
五、运算符
*注意:
++(--)
在前时先运算再取值
在后时先取值再运算
a.逻辑运算符
^逻辑异:两者不相同时为true;相同时为false
b.字符串连接符
"+"运算符两侧的操作数中只要有一个是字符串(String)类型,系统会自动将另一个操作数转换为字符串然后再进行连接
当进行打印时,无论任何类型,都自动转为字符串进行打印
c.三目条件运算符
语法格式:x?y:z
其中x为boolean类型表达式,先计算x的值,若为true,则结果为表达式y的值,否则为表达式z的值
d.语句
if语句:只有一句需要执行的语句时,可以省略{},但建议都加上。
for语句:JDK1.5新补充的for语法
while 和do while的区别:while先判断逻辑表达式;do while先执行语句,再判断逻辑表达式;
break 和continue语句
break语句:用于终止某个语句块的执行。用于循环语句体中,可以强行退出循环
continue语句:用在循环语句体中,用于终止某次循环;continue语句下面未执行的循环,开始下一次循环过程。
switch语句:
switch(){
case x:
执行语句1;
break;
case x:
执行语句2;
break;
default:
执行语句;
}
*小心case穿透,推荐使用break语句
*多个case可以合并到一起
*default可以省略,但不推荐省略
*java中switch语句只能探测int类型值
六、方法
1.java的方法类似于其他语言的函数,是一段用来完成特定功能的代码片段,声明格式:
[修饰符1 修饰符2 ...] 返回值类型 方法名(形式参数列表){
java语句;
}
形式参数:在方法被调用时用于接收外界输入的数据
实参:调用方法时实际传给方法的数据
返回值:方法在执行完毕后返回给调用它的环境的数据
返回值类型:事先约定的返回值的数据类型,如无返回值,则必须指明返回值类型为void
七、递归
方法在执行的时候才占内存,同一个方法可能同时在执行
递归调用指在方法执行过程中出现该方法本身的调用 -
java学习系列(一)--简介
2013-01-18 11:26:10
一、JDK的安装与配置
1、需要设置的环境变量有三个:JAVA_HOME; CLASSPATH; Path
2、右键单击我的电脑--》属性,选择高级选项,点击环境变量,进入环境变量设置对话框,在系统变量里边找到“Path”这一项,然后双击它,在弹出的界面上,在变量值开头添加如下语句“C:\Program Files\Java\jdk1.6.0_14\bin”,注意不要忘了后边的分号。然后点击新建添加系统变量。
(1)、新建JAVA_HOME变量,值为:C:\Program Files\Java\jdk1.6.0_14;此值为JDK的安装位置。
(2)、新建classpath变量,值为:.,注意是点和分号。然后点击环境变量界面的确定按钮,点击系统属性界面的确定按钮。
3、如何知道安装成功没与否
(1)、点击开始---》点击运行,在弹出的对话框中输入“cmd”。
(2)、然后点击确定,在弹出的dos窗口里面,输入“javac”,然后出现:
用法:javac《选项》《源文件》以及可能的选项等信息,标识安装配置成功。
二、HelloWorld程序总结
a.一个源文件中最多只能有一个public类,其他类的个数不限制
b.类名和文件名要一致
c.main方法:public static void main(String[] args)
d.三种注释方式
单行注释://
块注释:
/*
*/
java doc注释:
/**
*
*/
标题搜索
我的存档
数据统计
- 访问量: 4271
- 日志数: 10
- 建立时间: 2007-08-23
- 更新时间: 2013-01-29
