
-
面试题小记
2010-03-31 15:58:32
1、TTLB TPS 什么意思?
2、怎么开展性能测试工作?
3、LR产生随机数代码?
4、关联数据怎么获取?
5、并发怎么理解?怎么做到严格的并发?
6、Session 、cokies 有什么区别和联系?
7、post、get 有什么区别有联系?
8、安全性测试中最常用的测试方法是?具体怎么操作的?怎么很好的做到WEB 安全保障?
9、怎么判断测试结束?
10、测试用例因果图法是指?具体应用怎么做的?
11、一般一个项目大概写多少用例?用例的粒度怎么把握?
12、个人有别别的测试人员的优势在哪?
13、为什么要跳槽?
14、网站并发测试你是怎么做的?多个业务多用户同时进行,具体的场景设置是怎样的?
-
rand函数和srand函数
2010-03-17 22:55:44
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
int main(void)
{
int i;
time_t t;
srand((unsigned) time(&t));
printf("Random numbers from 0 to 99\n");
for(i=0; i<5; i++)
printf("%d ", rand() % 100);
return 0;
}srand((unsigned) time(&t)); 产生随机种子(以系统时间来产生)。 如果没有这一句,rand()出来的老是同一个数 .
例子:函数 rand()随机产生90~100中6个数?
初始化种子用的,要不然每次运行程序的时候,产生的6个随机数都是一样的。 #include <stdio.h> #include <stdlib.h> #include <time.h> int main() { int i; time_t t; srand((unsigned) time(&t)); for (i=0;i<6;i++) printf("%d\t%d\n",i,rand()%10+90); getch(); } -
SQL语句中,Group by
2010-03-17 22:37:05
你的里面用到了Sum函数 这是个聚合函数 就必须要使用到group by 那么其他非聚合函数的列都要加到group by 中去。
补充 有个折中的方法 可以不用写这么多
打个比方(你的例子太长,表太多,我自己找个简单的例子):
a表
id name
1 jim
2 kate
b
id money
1 100
1 40
2 40
2 50
我要求id name money
按照你的写法是:
select a.id,a.name,sum(b.money)
from a inner join b on a.id=b.id grop by a.id,a.name;
这样group by 后面有2个
而我的写法:
select a.id,a.name,test.total from
a inner join (select id,sum(money) as total form. b group by id) test
on a.id=test.id;
这样 group by 后面就只有一个列。 -
Sql 中Top用法
2010-03-17 22:33:50
问题:
在SQL 中top n*可以查出前N条记录,我现在想把N用表达式表示出来 。
解答:
TOP后面是不能跟表达式的,如果你必须在SQL中通过计算获得n值的话 可以像下面这么写
declare @n int , @i int
set @i=5
set @n=(@i-1)*@i
execute ('select top ' + @n +' * from table1')Tips:
top 5是只取5行,
top 5 with ties×是把和这5行有相同数据的行也取出来 -
按时间排序后取第2大的时间,oracle怎么办
2010-03-17 22:30:51
问题:
在表中按时间从大到小排序后取第2大的那一行记录,怎么做? PS:最大的那个时间有可能有2行
问题补充:最大的时间就是最近的时间,可是最大的时间有可能是2行记录,即两行一样最大时间的
解答:
select rownum,表名.* from (select distinct 时间 from 表名 order by 时间 desc) as time1,表名
where rownum=2 and 表名.时间=time1.时间 -
LR脚本练习2
2010-03-11 10:50:02
1、循环读取并显示该文件中的每行数据:(只能读数字内容)
- Action(){
- int MyFile;
- int loadNum,i;
- // Assigning the file path to a string
- char FileName[80] ="C:\\temp\\solem.txt";
- // Opening the file
- // Note the use of variable to replace the file path
- MyFile = (int)fopen(FileName,"r");
- while ( feof(MyFile)==0) {
- fscanf(MyFile,"%d",&loadNum);
- lr_output_message("LoadNum----------------> :%d \n", loadNum);
- }
- return 0;
- }
2、循环读取并显示该文件中的每行数据:
- Action() {
- char line[100] ;
- long file_stream;
- char *filename = "C:\\temp\\solem.txt";
- if ((file_stream = fopen(filename, "r")) == null ) {
- lr_error_message("Cannot open %s", filename);
- return -1;
- }
- while ( fgets(line, 100, file_stream)!= null) {
- lr_output_message( "The line is \"%s\"", line);
- }
- if (fclose(file_stream))
- lr_error_message("Error closing file %s", filename);
- return 0;
- }
-
LR脚本练习(转)
2010-03-11 10:45:51
1、写入数据到文件:(实际应用中可以将关联得到的参数写入文件)
- Action()
- {
- int MyFile;
- char Name[] = "测试数据"; MyFile = fopen( "c:\\temp\\names.txt", "w+" );
- fprintf(MyFile,"%s", Name);
- return 0;
- }
2、atol类型转换字符串转成整型(atoi atof itoa)
Action()- {
- char a[512];
- lr_output_message("value:%s",lr_eval_string("{param1}"));
- sprintf(a,"value=%ld",atol(lr_eval_string("{param1}"))+1);
- lr_output_message("value:%s",a);
- return 0;
- }
3、循环读取并显示该文件中的每行数据:(只能读数字内容)
- Action(){
- int MyFile;
- int loadNum,i;
- // Assigning the file path to a string
- char FileName[80] ="C:\\temp\\solem.txt";
- // Opening the file
- // Note the use of variable to replace the file path
- MyFile = (int)fopen(FileName,"r");
- while ( feof(MyFile)==0) {
- fscanf(MyFile,"%d",&loadNum);
- lr_output_message("LoadNum----------------> :%d \n", loadNum);
- }
- return 0;
- }
4、循环读取并显示该文件中的每行数据:- Action() {
- char line[100] ;
- long file_stream;
- char *filename = "C:\\temp\\solem.txt";
- if ((file_stream = fopen(filename, "r")) == null ) {
- lr_error_message("Cannot open %s", filename);
- return -1;
- }
- while ( fgets(line, 100, file_stream)!= null) {
- lr_output_message( "The line is \"%s\"", line);
- }
- if (fclose(file_stream))
- lr_error_message("Error closing file %s", filename);
- return 0;
}
3、 fopen():返回一个FILE数据类型的指针.因为LoadRunner不支持FILE数据类型,所以返回值需要转化成int型.
int MyFile;
MyFile=(int)fopen("C:\\temp\\loans.txt","w");
fopen()函数的第一个参数是创建文件的路径.第二个参数指定了创建文件的模式.下面是常用的几种模式:
“w” - 写,当需要往文件中写的时候.如果文件存在,就覆盖该文件,如果文件不存在,根据第一个参数来创建新文件.
“r” 读,需要从文件中读的时候.这个文件必须已经存在.
“a” 附加,当往文件末尾添加数据时用到.
“rw” 读和写.
第一个参数中注意文件路径为"\\",因为"\"在C语言中为转义字符.另外,如果文件和脚本在同一个目录中,文件的完整路径可以省略.- Action() {
- int count, total = 0;
- char buffer[1000];
- long file_stream;
- char *filename = "c:\\readme.txt";
- if ((file_stream = fopen(filename, "r")) == NULL ) {
- lr_error_message("Cannot open %s", filename);
- return -1;
- }
- while (!feof(file_stream)) {
- count = fread(buffer, sizeof(char), 1000, file_stream);
- lr_output_message("%3d read", count);
- if (ferror(file_stream)) {
- lr_output_message("Error reading file %s", filename);
- break;
- }
- total += count;
- }
- lr_output_message("Total number of bytes read = %d", total );
- if (fclose(file_stream))
- lr_error_message("Error closing file %s", filename);
- return 0;
- }
4、lr_save_string
(将非空字符串保存到指定的参数中,可将关联景中处理过的字符保存起来,以便后面进行参数化。)
5、lr_eval_string (用于返回参数中的实际字符串值,可以使用该函数来查看参数化取值是否正确。)
如:lr_output_message(“ID is %s” , lr_eval_string(“{id}”));
补充:web_url()函数详解
web_url()函数可以模拟用户请求,它也是在脚本中最常使用的函数之一。
web_url()函数的基本语法如下所示:
web_url("在测试结果中显示的名称","URL=需要访问的超链地址",LAST);
和web_link不同的地方在于这里只需要在URL=后填写需要访问的地址即可,和在IE地址栏中输入的内容相同,使用web_url的好处是没有任何请求的前后依赖关系,只负责发送一个标准的Get HTTP请求。
如果需要访问51Testing论坛,可以直接这样写:
1. web_url("51testing","URL=http://bbs.51testing.com",LAST);
除了以上这些元素,在录制出来的web_link或者web_url函数中经常还能看到如下所示的大量内容:
1. EXTRARES
2. "Url=../bite.jpg", "Referer=http://192.168.0.200", ENDITEM,
3. "Url=../title.gif", "Referer=http://192.168.0.200", ENDITEM,
4. ……
这一段内容说明在载入这个页面时还有其他图片或者附属资源需要下载。
web_link()和web_url()函数都是页面访问型函数,实现HTTP请求中的GET方法,如果需要提交表单,实现HTTP请求中的POST方法,那么需要使用web_submit_form()或web_submit_data()函数。
补充:web_submit_form()函数详解
该函数会自动检测在当前页面上是否存在form,然后将后面的ITEMDATA数据进行传送。例如录制在Web Tours网站上登录操作,可以得到以下代码:
1. web_submit_form("login.pl",
2. "Snapshot=t3.inf",
3. ITEMDATA,
4. "Name=username", "Value=admin", ENDITEM,
5. "Name=password", "Value=123456", ENDITEM,
6. "Name=login.x", "Value=0", ENDITEM,
7. "Name=login.y", "Value=0", ENDITEM,
8. LAST);
隐藏的表单数据系统会自行发送。
补充:web_submit_data()函数详解
和web_submit_form()函数不同,web_submit_data()函数无须前面的页面支持,直接发送给对应页面相关数据即可。录制Web Tours网站登录,代码会变为:
1. web_submit_data("login.pl",
2. "Action=http://127.0.0.1:1080/WebTours/login.pl",
3. "Method=POST",
4. "TargetFrame=body",
5. "RecContentType=text/html",
6. "Referer=http://127.0.0.1:1080/WebTours/nav.pl?in=home",
7. "Snapshot=t5.inf",
8. "Mode=HTML",
9. ITEMDATA,
10. "Name=userSession", "Value=100084.208748481fVtiAiVptiHfDAiiiptiiQcf", ENDITEM,
11. "Name=username", "Value=admin", ENDITEM,
12. "Name=password", "Value=123456", ENDITEM,
13. "Name=JSFormSubmit", "Value=off", ENDITEM,
14. "Name=login.x", "Value=0", ENDITEM,
15. "Name=login.y", "Value=0", ENDITEM,
16. LAST);
其中Action说明提交表单的处理页面,Method表明提交数据的方式。
当使用web_submit_data()函数时,隐藏表单的数据也会被记录下来作为ITEMDATA数据提交给服务器。 这里介绍了在HTTP页面中最常用的4个页面函数web_link()、web_url()、web_submit_form()、 web_submit_data(),通过这些函数可以实现大多数页面访问的请求和数据提交的过程。除了这4个函数,还有一个函数可能会经常看到:web_custom_request()。当请求比较特别时,VuGen无法简单使用以上4个函数进行表述,那么录制后便会出现 web_custom_request()函数,这个函数的作用是自定义HTTP请求规则。该函数更适合在使用自定义的HTTP请求规则中处理二进制内容。具体格式请参考帮助文档。
补充:web_link()函数详解
web_link()函数用来模拟用户单击一个超链接的操作。VuGen会记录访问页面后服务器返回的内容中有多少个超链接。当使用web_link()函数时,只要写出正确的链接名,VuGen会自动查找并访问页面中该链接名所指向的URL地址。
web_link()函数的基本语法如下所示:
web_link(“在测试结果中显示的名称”,“TEXT=需要单击的超链接名”,LAST);
◇ 在测试结果中显示的名称
也被称作步骤名,在测试结果中显示的名称是指在脚本运行完成后,打开Test Result,在link函数后的名称(此处为sign up now),如图3.16所示。
图3.16 Test Result执行步骤
这是通过web_link(“sign up now”,….)来实现的,我们能够在测试结果中方便、快速地定位。
◇ 需要单击的超链接名
单击的链接是通过Text=来说明的,等号后的内容就是需要单击的链接。这里需要注意,如果Text后的链接名不存在,那么就会得到以下错误: 该错误信息提示单击的signupnow这个链接不存在,整个web_link函数是错误的。
“Snapshot=t2.inf”用来说明该操作后的内容会被抓图保存到文件t2.inf中。最后LAST表明这个函数的结束。
例如:想要该脚本去点击WebTours首页上的administration链接,我们只需要将web_link修改为: 回放脚本看看是否正确通过,并进入管理页面。
思考:
如果一个页面中有多个同名的链接,使用web_link()该如何处理?
Ord这个关键字可以帮助你,在VuGen中很多函数都使用这个参数来判断对象的次序。
例如要单击页面上的第二个链接,那么可以这样写:
在这里需要注意,同名链接的先后顺序是根据HTML代码的解释顺序(从左往右,从上往下)来确定的。使用HTML-base script下的A script. describing user actions好处是脚本简洁,基于用户操作进行模拟,浅显易懂,并且自身就包含了对象检查过程,无须校验。其缺点是当页面中存在多个同名链接时难以区分。所以我们建议使用下面一种脚本模式:A script. containing explicit URLs only (e.g. web_url,web_submit_data)。
8、LoadRunner如何设置文本和网页图像的检查点。
通过 VuGen 可在网页上添加搜索文本字符串的检查。可以在录制期间或录制之后添加文本检查。
在创建文本检查时,需要定义检查的名称、检查范围、要检查的文本和搜索条件。
要在录制之后添加文本检查,请执行下列操作:
1.在 VuGen 主窗口中,右键单击与要对其执行检查的网页相应的步骤。从弹出菜单中选择“在之后插入”。将打开“添加步骤”对话框。
2.在“步骤类型”树中,展开“Web 检查”。
3.选择“文本检查”,然后单击“确定”。将打开“文本检查属性”对话框。请确保“规格”选项卡可见。
4.在“搜索”框中,键入要验证其存在与否的字符串。ABC 图标表示尚未为“搜索”框中的字符串分配参数。
5.要相对于邻近文本指定搜索字符串的位置,请选中“其右侧”或“其左侧”复选框。然后,在适当的字段中键入文本。例如,要验证字符串support@mercuryinteractive.com是否出现在单词“e-mail:”的右侧,请选中“其右侧”,然后在“其右侧”框中键入“e-mail:”。ABC 图标表示尚未为“其右侧”或“其左侧”框中的字符串分配参数。
6.命名文本检查。单击“常规”选项卡,然后在“步骤名”框中键入文本检查的名称。使用一个以后容易识别该检查的名称。
7. 属性表显示其他用于定义检查的属性。清除“仅查看活动属性”复选框可以查看活动和非活动属性。要启用某个属性,请单击该属性名左侧的单元格。在“值”列中为属性分配一个值。
8.单击“确定”接受设置。代表新文本检查的图标将被添加到脚本中的关联步骤中。在脚本视图中,“文本检查”图标显示为 web_find 函数。要在录制期间添加文本检查,请执行下列操作:
1.使用鼠标标记所需的文本。
2.单击录制工具栏上的“插入文本检查”图标。
除了使用 web_find 函数外,还可以使用两个其他的增强函数来搜索 HTML 页内的文本:
web_reg_find
web_global_verification
web_reg_find 函数是注册类型函数。它将注册对 HTML 页上的文本字符串进行的搜索。注册意味着它不会立即执行搜索 - 仅在执行下一个操作函数(如web_url)之后,才会执行检查。注意,如果正在使用并发函数组,则web_reg_find 函数仅在分组结束后才会执行。该函数与 web_find 函数的不同之处在于:它并不局限于基于 HTML 的脚本(请参见“录制选项” > “录制”选项卡)。该函数还具有其他属性(如实例)通过该属性可以确定文本出现的次数。在执行标准文本搜索时, web_reg_find是首选函数。通过 VuGen 可添加在网页上搜索图像的用户定义的检查。图像可以由 ALT 属性、SRC 属性或这两者来标识。可以在录制期间或录制之后添加用户定义的图像检查。录制之后,可以在脚本中编辑任何现有的图像检查。要添加图像检查,请执行下列操作:
1.在 VuGen 主窗口中,右键单击与要对其执行检查的网页相应的步骤。从弹出菜单中选择“在之后插入”。将打开“添加步骤”对话框。
2.在“步骤类型”树中,展开“Web 检查”。
3.选择“图像检查”,然后单击“确定”。将打开“图像检查属性”对话框。请确保“规格”选项卡可见。
4.选择一种标识图像的方法:
a)要使用图像的 ALT 属性来标识图像,请选中“替换图像名(ALT 属性)”复选框,然后键入 ALT 属性。在运行脚本时, Vuser 将搜索具有指定的 ALT 属性的图像。
b)要使用图像的 SRC 属性来标识图像,请选中“图像服务器文件名(SRC 属性)”复选框,然后键入 SRC 属性。在运行脚本时, Vuser 将搜索具有指定的 SRC属性的图像。ABC 图标表示尚未为 ALT 或 SRC 属性分配参数。
5.要命名图像检查,请单击“常规”选项卡。在“步骤名”框中,键入图像检查的名称。使用一个以后容易识别该检查的名称。
6.属性表显示其他用于定义检查的属性。清除“仅查看活动属性”复选框可以查看活动和非活动属性。要启用某个属性,请单击该属性名左侧的单元格。在“值”列中为属性分配一个值。
7.单击“确定”以接受设置。代表新图像检查的图标将被添加到 Vuser 脚本中的关联步骤中。可以指定插入到 Vuser 脚本中的每个 Web 检查的其他属性。在检查属性对话框的“常规”选项卡上的属性表中设置其他属性。 -
LoadRunner中的一个关联技巧
2007-10-25 22:53:06
LoadRunner中的一个关联技巧<转载>
众所周知,在LoadRunner中,关联是一个很重要的动作,大多数的脚本在录制完成后并不能直接回放,需要通过一定的关联才能成功回放。关联的技巧有很多,这里介绍的就是其中之一,以下用一个实际的例子来说明。
脚本的背景如下:
web_submit_data("classiLoanMaterial.jsf_2")(web_submit_data函数的其它部分省略,下同。)返回的页面上可能存在多条记录,可能一条,可能两条,也可能三条,等等。我们需要将这些记录逐个选中进行操作。注意:不是全部选中,而是要逐条记录进行操作。同时,每一条记录各有一个编号,这是需要进行关联的值。在下面的操作中web_url("directAdjust.jsf",
"URL=http://128.64.96.105:1158/clpmapp/bizprocess/loanservice/creditassetsriskclassi/
classiadjuststepbystep/directAdjust.jsf?approveFormNum=123456")需要使用到该编号,即黑体字部分的值。面对这样的目的,很自然地,我们会想到用一个循环语句来实现。首先,在classiLoanMaterial.jsf页面之前加一个关联如下:
web_reg_save_param("sor","LB=sor\" value=\"","RB=\"","Ord=ALL", LAST);将Ord参数值设定为ALL,则关联函数将自动把符合条件的关联值保存到参数数组里。在本例中,假设关联值返回三条记录,则LR分别将值保存到sor_1,sor_2,sor_3中,同时,LR还将自动创建一个sor_count变量来保存总的记录数,在这里sor_count值等于3。利用这些信息,我们就可以很方便地在循环语句中实现我们的目的了。步骤如下:
1、声明各变量:
int count;
int i;
char sor[50];
char sorvalue[50];
2、将返回的记录数保存到count变量里:
count=atoi(lr_eval_string("{sor_count}"));
3、使用for循环:
for(i=1;i<=count;i++)
{
sprintf(sor,"{sor_%d}",i); //分别将各个sor值保存到sor字符串中
sprintf(sorvalue,"%s",lr_eval_string(sor));//通过lr_eval_string函数将字符串赋给sorvalue变量
}
4、在循环体中使用关联值替换相关值:
web_url("directAdjust.jsf",
"URL=http://128.64.96.105:1158/clpmapp/bizprocess/loanservice/creditassetsriskclassi/
classiadjuststepbystep/directAdjust.jsf?approveFormNum={sorvalue}")
一切看起来似乎顺理成章,然而如果按照以上的步骤做下来,将会很遗憾地发现:我们定义的{sorvalue}值根本就不被LR认可并接受,于是它将无情地给我们抛出一个错误,说该值是非法的。怎么办?难道我们前面做的一切都白费了吗?
有句老话说得好:天无绝人之路。聪明而又善良的LR开发团队已经为我们考虑到了这个问题,给我们预备了一个很有用的函数:lr_save_string,它可以帮助我们解决这个问题。于是我们祭出lr_save_string这道最后的杀手锏:
5、在使用关联值之前进行字符串格式转换:
lr_save_string(sorvalue,"sorvalue1");
web_url("directAdjust.jsf",
"URL=http://128.64.96.105:1158/clpmapp/bizprocess/loanservice/creditassetsriskclassi/
classiadjuststepbystep/directAdjust.jsf?approveFormNum={sorvalue1}")
需要特别注意lr_save_string的用法,它是参数值在前(sorvalue),参数名在后("sorvalue1"),这和一般的习惯用法正好反过来(真是好奇怪!)。而且"sorvalue1"这个参数名称不需要事先声明,它只是一个字符串而已(这也比较奇怪!^_^)。
到此,我们总算大功告成!脚本回放成功,并且正确达到了预期的效果!打完收工!
总结:C的变量不能直接在LR的API里调用,所以必须用lr_save_string进行转换。
最后顺便说一下,lr_save_string这个函数真的很好用,这个例子中提到的方法也适用于另外一些情况,比如说有时候,通过关联函数出来的值我们不能直接使用,还需要做一些特殊的处理时,那么我们可以把关联得到的值取出来,赋给一个字符串,对其进行一番修剪加工后,再用 lr_save_string,就可以使用它来替代需要关联的值了。
后记:我的这篇文章发布在网上以后,在广大的测试同行中间引起了强烈的反响,他们纷纷发来贺电和表扬信,对我这种勇于探索、乐于分享的精神给予了充分的肯定。^_^当然,这中间也难免存在极个别的不和谐声音,例如Zee同学就对我的这篇文章提出了不同看法,他觉得我的做法是把简单的问题复杂化了,理由是可以只做一次关联,每次只取第一笔记录即可,当循环进行操作时,第一笔做完以后,第二笔记录自然会上升到第一笔记录的位置,因此没有必要使用关联数组。我认为他的疑问并非没有道理,而且是比较有代表性的,因此我在这里做一个补充说明。在我接触过的大多数应用系统中,确实都是按照Zee所说的方式进行处理,在这种情况下,脚本的处理的确没有必要像我以上所述的那样复杂。不过我在本例中谈到的例子比较特殊,在操作完成后,它只是把每笔记录的状态位由“未完成”修改为“已完成”,而原有的记录并没有消失,而是仍然停留在原有的位置,此时如果按照Zee所说的方法,那么在执行第二次循环时,LR将取到操作状态为“已完成”的第一笔记录,而不会取到下一笔未完成的记录,显然这是不符合我们的要求的,因此在这里我需要做以上这样复杂的一个处理。 -
如何对下拉框中的数据进行参数化的解决方法
2007-10-02 00:11:46
参数化下拉框选项的两个方法
1.通过下拉框对应项的实际值查找
Browser("****").Page("****").WebList("****").Select "****”
将select“****”的值参数化,可以将下拉框中的每一个选项都写到数据表中
2.通过下拉框对应项的索引号查找
Browser("****").Page("****").WebList("****").Select "#"&IndexNum
比如说下拉框有5个选项
IndexNum = Int((5- 1 + 1) * Rnd + 1) 或 IndexNum = RandomNumber(1,5)
以上代码生成1到5之间的随机数,5是上界,1是下界。 -
QTP中如何参数化link解决方法
2007-10-02 00:11:08
Dim eleLink
Dim i,j,Links()
Browser("Browser").Page("Page").Sync
Browser("Browser").Navigate "http://www.testage.net/bbs/"
Browser("Browser").Page("测试时代论坛").Sync
Set ōbjLinks=Browser("Browser").Page("测试时代论坛").Object.links
i=0
For Each eleLink In objLinks
If Ucase(eleLink.tagname)="A" Then
Links(i)=eleLink.InnerText
i=i+1
End If
Next
For j=0 To i
Browser("Browser").Page("测试时代论坛").Link("InnerText:=" & Links(j)).Click
Browser("Browser").Back
Next -
Windows资源监控工具大全
2007-09-18 23:32:51
在利用LoadRunner进行性能测试的时候,Windows服务器的资源是经常需要监控的对象。其实除了LoadRunner提供的计数器,似 乎Window服务器并不像Unix或者Linux提供众多的性能监控方法,比如Top或者vmstat等。另外有很多第三方的工具可以选用以增强 Windows服务器的监控途径,下面是一些工具的列表。
【监视类】
CPUMon v2.0
CPU性能监视工具。可以获取CPU计数器信息。该版本集成了Perfmon。
http://www.sysinternals.com/ntw2k/freeware/cpumon.shtmlDebugView v4.31
截取Win32设备驱动程序发出的消 息,允许通过本机或网络查看和录制调试信息而不打开一个活动的调试器。
http://www.sysinternals.com/ntw2k/freeware/debugview.shtmlDiskmon v2.01
显示硬盘的活动信息。
http://www.sysinternals.com/ntw2k/freeware/diskmon.shtmlFilemon v6.12
实时监视操作系统中活动的文件。
http://www.sysinternals.com/ntw2k/source/filemon.shtmlHandle v2.20
显示进程及其打开的文件等信息。
http://www.sysinternals.com/ntw2k/freeware/handle.shtmlListDLLs v2.23
列出当前系统加载的所有dll文件、调用它的执行程序及dll版本路径等详细信息。
http://www.sysinternals.com/ntw2k/freeware/listdlls.shtmlNTFSInfo v1.0
查看NTFS卷的详细信息,包括大小、文件分配表的大小起止位置,还有元数据文件的大小等。
http://www.sysinternals.com/ntw2k/source/ntfsinfo.shtmlPMon v1.0
监视进程的创建、删除,也包括显示多CPU机器或checked kernel 机器上的上下文交换信息。
http://www.sysinternals.com/ntw2k/freeware/pmon.shtmlPortmon v3.02
端口监视工具,监视端口收发的信息等。
http://www.sysinternals.com/ntw2k/freeware/portmon.shtmlProcess Explorer v8.52
查看进程所打开的文件,注册表和其他对象,并显示加载了那些dll。
http://www.sysinternals.com/ntw2k/freeware/procexp.shtmlPsTools v2.1
包含一套命令行工具,包括显示本机或远程机器上运行的进程,在远程机器上运行进程,重启机器,记录日志等。
http://www.sysinternals.com/ntw2k/freeware/pstools.shtmlRegmon v6.12
实时监视注册表的活动。
http://www.sysinternals.com/ntw2k/source/regmon.shtmlTCPView v2.34
监视本机TCP和UDP协议的活动情况,并显示使用该协议的进程,包括了dos版本。
http://www.sysinternals.com/ntw2k/source/tcpview.shtmlTDImon v1.01
通过网络API实时监视TCP和UDP协议的活动情况。
http://www.sysinternals.com/ntw2k/freeware/tdimon.shtmlTokenmon v1.01
令牌监视器,监视与信息安全相关的活动,比如登录,退出等。
http://www.sysinternals.com/ntw2k/source/tokenmon.shtmlWinobj v2.13
对象命令空间管理器。增强了用户界面,显示更多对象类型,并集成了NT的本地安全设置。
http://www.sysinternals.com/ntw2k/freeware/winobj.shtml【性能工具类】
CacheSet v1.0
缓存设置器。设置NT使用的缓存空间大小。
http://www.sysinternals.com/ntw2k/source/cacheset.shtmlContig v1.51
可以使文件变的连续,提高访问速度。
http://www.sysinternals.com/ntw2k/freeware/contig.shtmlFrob v1.6a
设置优先相应前台程序还是后台服务。
http://www.sysinternals.com/ntw2k/freeware/frob.shtmlPageDefrag v2.3
磁盘文件和注册表整理。
http://www.sysinternals.com/ntw2k/freeware/pagedefrag.shtml【实用工具类】
AccessEnum v1.2
可以查看哪个用户在访问本机上目录、文件和注册表。用此工具可以找出系统访问的漏洞。
http://www.sysinternals.com/ntw2k/source/accessenum.shtmlAutoruns v6.0
查看随系统一起启动的程序, dll及服务等等信息。
http://www.sysinternals.com/ntw2k/freeware/autoruns.shtmlBgInfo v4.08
生成本机的一些重要信息(ip地址、机器名、网卡等)并作为桌面的背景显示。
http://www.sysinternals.com/ntw2k/freeware/bginfo.shtmlCtrl2cap v2.0
按键功能转换。
http://www.sysinternals.com/ntw2k/source/ctrl2cap.shtmlDiskview v2.0
磁盘分析,可以查看文件在硬盘上存储的具体位置。
http://www.sysinternals.com/ntw2k/source/misc.shtmlFAT32 for Windows NT 4.0 v1.01
制作双重启动的工具,可以使用fat32分区。
http://www.sysinternals.com/ntw2k/freeware/fat32.shtmlFundelete v2.02
文件恢复工具,可以恢复从回收站中删除的文件或者被程序删除的文件。
http://www.sysinternals.com/ntw2k/source/fundelete.shtmlLDMDump v1.02
把磁盘上数据库中逻辑驱动器的内容保存到文件中,该文件描述了Windows 2000的动态磁盘信息。
http://www.sysinternals.com/ntw2k/freeware/ldmdump.shtmlLiveKd v2.11
使用Microsoft内核调试器检查系统。
http://www.sysinternals.com/ntw2k/freeware/livekd.shtmlNewSID v4.05
生成新的SID。
http://www.sysinternals.com/ntw2k/source/newsid.shtmlNTRecover v1.0
NT系统的数据救援工具,可以通过正常的操作系统来访问一个崩溃的NT系统,然后可以使用NT的命令来抢救数据。共享版只能读取。
http://www.sysinternals.com/ntw2k/freeware/ntrecover.shtmlNTFSCHK v1.0
把NT4格式转换为NT5格式。
http://www.sysinternals.com/ntw2k/freeware/ntfschk.shtmlNTFSDOS v3.02
通过dos系统只读访问NTFS分区。
http://www.sysinternals.com/ntw2k/freeware/ntfsdos.shtmlNTFSDOS Professional v4.01
可以在dos中完全访问NTFS分区。共享版只能读取。
http://www.sysinternals.com/ntw2k/freeware/ntfsdospro.shtmlNTFSFlp v1.0
创建可访问NTFS分区的软盘。
http://www.sysinternals.com/ntw2k/freeware/ntfsfloppy.shtmlNTFS for Windows 98 v2.0 Ready-Only
95/98系统下读取NTFS的工具。
http://www.sysinternals.com/ntw2k/freeware/ntfswin98.shtmlPsTools v2.1
包含一套命令行工具,包括显示本机或远程机器上运行的进程,在远程机器上运行进程,重启机器,记录日志等。
http://www.sysinternals.com/ntw2k/freeware/pstools.shtmlRemote Recover v2.0
远程救援工具。共享版只能读取。
http://www.sysinternals.com/ntw2k/freeware/remoterecover.shtmlSDelete v1.2
安全地覆盖敏感的文件。
http://www.sysinternals.com/ntw2k/source/sdelete.shtmlShareEnum v1.51
列举出网络中共享的文件夹并查看安全设置减少安全漏洞。
http://www.sysinternals.com/ntw2k/source/shareenum.shtmlSync v2.1
强制系统保存所有打开的文件。
http://www.sysinternals.com/ntw2k/source/misc.shtmlVolumeID v2.0
设置磁盘的ID。
http://www.sysinternals.com/ntw2k/source/misc.shtml【其他类工具】
Bluescreen v3.2
恶作剧的屏保。
http://www.sysinternals.com/ntw2k/source/misc.shtmlMiscellaneous
一系列小工具,许多都附带源码。AdRestore, Junction, DiskExt, EFSDump, Streams, UpTime, VolumeId, Sync, Sigcheck, AutoLogon, HostName, Strings.等。
PsTools v2.1http://www.sysinternals.com/ntw2k/freeware/pstools.shtml
包含一套命令行工具,包括显示本机或远程机器上运行的进程,在远程机器上运行进程,重启机器,记录日志等。(http://www.rickyzhu.com) -
转《LoadRunner没有告诉你的》之七——长时间数据库不重复
2007-09-16 23:46:42
有朋友开始投诉了,说我已经好长一段时间没有写技术类文章了。汗颜,积极改进。刚好今天在群里有同行遇到一个关于 LR 参数化的问题,其实这个问题以前也遇到过,所以就顺便把我的想法整理一下发上来。
当时我们要做的是使用性能测试工具模拟大量用户在线点播 Movie 的业务,这个点播 Movie 的业务在第一次点播成功后,如果同一用户再次点播同一 Movie,系统的处理流程与第一次点播是不同的。另外,我们在执行测试时,通常都会连续执行几个小时以获得尽可能多的样本数据。
那么问题就在于,一方面我们不能在一次测试中重复的读取同样的数据,另一方面准备几十万甚至上百万的数据工作量也太大,而且还涉及到相关的基础数据的准备。那么,我们该如何在使用 LoadRunner 连续长时间执行测试,保证参数化的数据充足而又不会重复呢?
其实方法很简单。无论上 LR 还是 JMeter,都提供了将多个参数的取值存放在同一个文件中,或者每个参数单独指定一个文件的功能,针对上面这个例子,我们只是简单的创建了两个文件和三个参数,第一个参数和第二个参数(用户账号和密码)存放在第一个文件中,有1000条记录;第三个参数(Movie 的 ID)存放在第二个文件中,有999条记录。然后在测试工具中设置参数取值的读取为顺序读取并且循环读取。通过这种简单的方法组合出了大量的数据。问题被解决了。
-
转《LoadRunner 没有告诉你的》之五——无所不在的性能测试 (已完稿)
2007-09-16 23:45:01
提到性能测试,相信大家可以在网上找到很多种不同的定义、解释以及分类方法。不过归根结底,在大多数情况下,我们所要做的性能测试的目的是“观察系统在一个给定的环境和场景中的性能表现是否与预期目标一致,评判系统是否存在性能缺陷,并根据测试结果识别性能瓶颈,改善系统性能”。
本文是《LoadRunner没有告诉你的》系列的第五篇,在这篇文章中,我希望可以跟大家一起来探讨“如何将性能测试应用到软件开发过程的各个阶段中,如何通过尽早的开展性能测试来规避因为性能缺陷导致的损失”。
因此,本文的结构也将依据软件开发过程的不同阶段来组织。
另外,建议您在阅读本文前先阅读本系列文章的第三篇《理发店模型》和第四篇《理解性能》。
需求阶段
我们不可能将一辆设计载重为0.75吨的皮卡改装成载重15吨的大型卡车,如果你面对的正是这样的问题,那么恐怕你只能重做一辆,而且客户不会为你之前那辆付钱。对于一个已经完成的应用系统来说也是如此。
如果我们在系统结构确定之前就能够了解到系统的将要面对的压力,用户的使用习惯和使用频度,我们就可以更早也更有效的提前解决或预防可能发生的性能缺陷,也将会极大的减少后期返工和反复调优所带来的工作量。如果我们预期到系统的容量将会不断的增长,我们还可以给出相应的解决方案来低成本的解决这类问题,就像上面那辆皮卡,也许你可以有办法把20辆皮卡捆在一起,或者把15吨的东西分由20辆来运。
分析设计阶段
系统性能的优化并不是要等待整个系统全部集成后才能开始的,早在分析设计阶段,我们就可以开始考虑系统的技术架构和数据库部分的优化。
数据库通常位于整个系统的最底层,如果直到系统上线前才发现因为数据库设计不合理而导致性能极差,通常使用任何一种方法来优化都已经于事无补了。要避免这类问题,最常见的做法是在数据库结构确定后,通过工具或脚本向数据库中注入大量的数据,并模拟各种业务的数据库操作。根据对数据库性能的观察和分析,对数据库表结构和索引进行调整以优化数据库性能。
在系统的技术架构方面,要明白先进的技术并不是解决问题的唯一方法,过于强调技术的作用反而会将你带入歧途。例如:某些业务虽然经常面临着巨大的压力,并且业务本身的复杂性决定了通过算法的优化来提高系统的性能收效甚微。但是我们知道用户对于该业务的实时性要求并不高,并且返回结果对于不同用户来说是相同的。那么我们完全可以考虑将每次请求都动态生成返回结果的方式改为每次用户请求都返回一个定期更新的静态页面。
另外,所谓“先进技术”通常都会在带来某一方面改进的同时带来另一方面的问题,未经试验就盲目的在系统中加入各种流行元素未必是最好的选择。例如ORM可以提供一些方便,但是它生成的SQL是未经优化的,有时甚至比人工编写的SQL效率更低。
最后,要知道不同厂家的设备性能是不同的,而且不同的硬件设备搭载不同的操作系统、数据库、中间件以及应用服务器,表现出来的性能也是不同的。如果有足够的资源,应当考虑提前进行软硬件平台的对比选型;如果没有足够的资源,可以考虑通过一些专业的组织或网站来获取或购买相关的评估报告。
编码阶段
一片树叶在哪里最难被发现?——当这片树叶落在一堆树叶里面的时候。
如果你只是在系统测试完成后才开始性能测试,那么即使发现系统存在性能缺陷,并且已经有了几个可供怀疑的对象,但是当一段因为使用了不当的算法而导致执行效率很低的代码藏身于一个庞大的系统中时,找出它是非常困难的。避免这种情况出现的方法是尽早开始核心业务代码的性能测试,重点集中在对算法和实现方法的优化上。
另外,及早开始的测试也可以帮你更容易找到内存泄漏的问题。
测试阶段
产品终于交到我们手上了,搭建测试环境,设计测试场景,执行测试,找到系统的最佳并发用户数和最大并发用户数,将系统进行分类,评判系统的性能表现是否满足需求中定义的目标——如果有需求的话 ^_^
如果发现系统的性能表现与预期目标相去甚远,则需要根据执行测试过程中收集到的数据来分析和识别性能瓶颈,优化系统性能。
在这个阶段还有很多值得我们深入思考和讨论的东西,在本系列后续的文章中,我们将会更多的关注这一部分的内容。
维护阶段
维护阶段通常遇到的问题是需要在实验室中模拟客户环境,重现在客户那里发现的缺陷并修复缺陷。相比功能缺陷,性能缺陷与某一具体环境和场景的关联更加密切,所以在测试前需要检查生产环境中各服务器的资源利用率、系统访问日志、应用服务器的日志、数据库的日志。如果客户使用了专门的系统来监测各个服务器的软硬件资源使用情况的话,检查该系统是否记录下了软硬件资源的异常或者警告。
与性能测试相关的其他测试
可靠性测试(Reliability Testing) 对于一个运营商级的系统来说,能够保证提供7×24的连续稳定的服务是非常重要的。当然,你可以通过一些“高可用性(High Availability)”技术方案来增强系统的可靠性,但是对于系统本身的可靠性测试是不能被忽略的。
常用的测试方法是使用一定的负载长时间向服务器加压,并观察随着加压时间的延长,响应时间、吞吐量以及资源利用率的变化。要注意的是,所使用的负载应当是系统的最佳并并发用户数,而不是最大并发用户数。
可伸缩性测试(Scalability Testing) 对于一个系统来说,在一个给定的环境下,它的最佳并发用户数和最大并发用户数是客观存在的,但是系统所面临的压力却有可能随上线时间的延长而增大。例如,一个在线购物站点,注册用户数量不断增多,访问站点查询商品信息和购买商品的人也不断的增多,我们应该用一种什么样的方案,在不影响系统继续为用户提供服务的前提下来实现系统的扩容?
一种常用的方案是使用负载均衡(Load Balance)和集群(Cluster)技术。但是在我们为客户提供这种方案之前,需要先自己进行测试,保证该技术的有效性——我们是否真的可以通过简单的增加服务器数据和修改某些参数配置,就能够使得系统的容量得到线性的增长?
可恢复性测试(Recoverability Testing) 虽然我们已经可以准确的估算出系统上线后将要面对的压力,并且可以保证系统的最佳并发用户数和最大并发用户数是足以应对这些压力的,但是这个世界上总是有些事情上我们所无法预料到的——例如9.11事件发生后,AOL的网站访问量在短时间内增长到了平时的数十倍。
我们无法保证系统可以在任何情况下都能为用户正确无误的提供服务,但是我们需要确保当意外过去后,系统可以恢复到正常的状态,并继续后来的用户提供服务——就像从未发生过任何事情一样。
如果要实现“可恢复性测试”,我们可以借助于测试工具或脚本来逐渐的增大并发用户数,直至并发用户数已经超过了系统所能承受的最大并发用户数,并导致软硬件资源利用率饱和,响应时间无限延长,大量的请求因为超过响应时间要求或无法获得响应而失败;之后,我们逐渐的减少并发用户数,并观察资源利用率、响应时间、吞吐量以及交易成功率的变化是否与预期目标一致。
当然,这一切的前提是在系统负载达到峰值前,Server一直在顽强的挣扎着而没有down掉 ^_^
性能测试,并非网络应用专属
软件的性能和性能测试都是伴随着网络应用的兴起而逐渐被重视起来的,但是软件性能和性能测试却并非网络应用的专属名词,因为单机版的应用同样需要考虑性能问题。下面举几个简单的例子来方便大家的理解:
1. 当使用Word来编辑一个500多页,并包含了丰富图表、图片和各种格式、样式信息的文档时,是否每次对大段的文字或表格的修改、删除或重新排版,都要等待系统花几秒钟的时间进行处理?
2. 当在Excel中使用嵌套的统计和数学函数对几万行记录进行统计分析时,是否每次都要两三分钟才能看到结果?
3. 杀毒软件是否每次都要花费两个小时才能完成一次对所有的分区的扫描?
4. 是否每次在手机的通讯簿中根据姓名搜索某个人的联系方式都要三四秒钟才有响应?
如果大家有兴趣,也可以通过Google搜索到更多的有关单机应用性能测试的资料。
-
转《LoadRunner 没有告诉你的》之三——理发店模型
2007-09-16 23:41:23
大概在一年前的一次讨论中,我的好友陈华第一次提到了这个模型的最初版本,经过几次讨论后,我们发现经过完善和扩展的“理发店模型”可以用来帮助我们理解很多性能测试的概念和理论,以及一些测试中遇到的问题。在最近的一次讨论后,我决定撰写一篇文章来专门讲述一下这个模型,希望可以帮助大家更好的理解性能测试有关的知识。
不过,在这篇文章中,我将会尽量的只描述模型本身以及相关的一些扩展,而具体如何将这个模型完全同性能测试关联起来,我不会全部说破,留下足够的空间让大家继续思考和总结,最好也一起来对这个模型做进一步的完善和扩展^_^ 我相信,当大家在思考的过程中有所收获并有所突破时,那种快感和收获的喜悦才真的是让人倍感振奋而且终生难忘的 ^_^
当然,我要说明的是,这个模型仅仅是1个模型,它与大家实际工作中遇到的各式各样的情况未必都可以一一对应,但是大的方向和趋势应该是一致的。
相信大家都进过或见过理发店,一间或大或小的铺面,1个或几个理发师,几张理发用的椅子和供顾客等待的长条板凳。

在我们的这个理发店中,我们事先做了如下的假设:
1. 理发店共有3名理发师;
2. 每位理发师剪一个发的时间都是1小时;
3. 我们顾客们都是很有时间观念的人而且非常挑剔,他们对于每次光顾理发店时所能容忍的等待时间+剪发时间是3小时,而且等待时间越长,顾客的满意度越低。如果3个小时还不能剪完头发,我们的顾客会立马生气的走人。
通过上面的假设我们不难想象出下面的场景:
1. 当理发店内只有1位顾客时,只需要有1名理发师为他提供服务,其他两名理发师可能继续等着,也可能会帮忙打打杂。1小时后,这位顾客剪完头发出门走了。那么在这1个小时里,整个理发店只服务了1位顾客,这位顾客花费在这次剪发的时间是1小时;
2. 当理发店内同时有两位顾客时,就会同时有两名理发师在为顾客服务,另外1位发呆或者打杂帮忙。仍然是1小时后,两位顾客剪完头发出门。在这1小时里,理发店服务了两位顾客,这两位顾客花费在剪发的时间均为1小时;
3. 很容易理解,当理发店内同时有三位顾客时,理发店可以在1小时内同时服务三位顾客,每位顾客花费在这次剪发的时间仍然是均为1小时;
从上面几个场景中我们可以发现,在理发店同时服务的顾客数量从1位增加到3位的过程中,随着顾客数量的增多,理发店的整体工作效率在提高,但是每位顾客在理发店内所呆的时间并未延长。
当然,我们可以假设当只有1位顾客和2位顾客时,空闲的理发师可以帮忙打杂,使得其他理发师的工作效率提高,并使每位顾客的剪发时间小于1小时。不过即使根据这个假设,虽然随着顾客数量的增多,每位顾客的服务时间有所延长,但是这个时间始终还被控制在顾客可接受的范围之内,并且顾客是不需要等待的。
不过随着理发店的生意越来越好,顾客也越来越多,新的场景出现了。假设有一次顾客A、B、C刚进理发店准备剪发,外面一推门又进来了顾客D、E、F。因为A、B、C三位顾客先到,所以D、E、F三位只好坐在长板凳上等着。1小时后,A、B、C三位剪完头发走了,他们每个人这次剪发所花费的时间均为1小时。可是D、E、F三位就没有这么好运,因为他们要先等A、B、C三位剪完才能剪,所以他们每个人这次剪发所花费的时间均为2小时——包括等待1小时和剪发1小时。
通过上面这个场景我们可以发现,对于理发店来说,都是每小时服务三位顾客——第1个小时是A、B、C,第二个小时是D、E、F;但是对于顾客D、E、F来说,“响应时间”延长了。如果你可以理解上面的这些场景,就可以继续往下看了。
在新的场景中,我们假设这次理发店里一次来了9位顾客,根据我们上面的场景,相信你不难推断,这9位顾客中有3位的“响应时间”为1小时,有3位的“响应时间”为2小时(等待1小时+剪发1小时),还有3位的“响应时间”为3小时(等待2小时+剪发1小时)——已经到达用户所能忍受的极限。假如在把这个场景中的顾客数量改为10,那么我们已经可以断定,一定会有1位顾客因为“响应时间”过长而无法忍受,最终离开理发店走了。
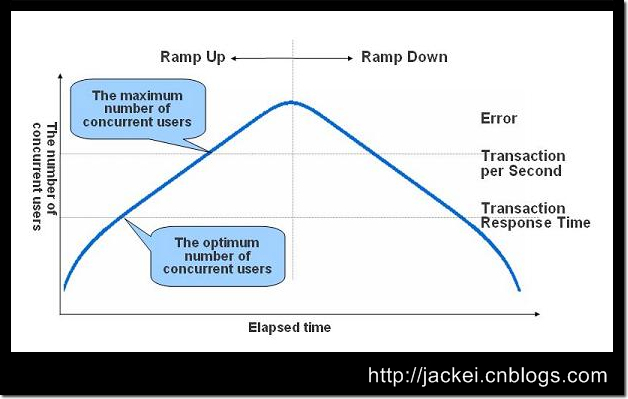
我想并不需要特别说明,大家也一定可以把上面的这些场景跟性能测试挂上钩了。如果你还是觉得比较抽象,继续看下面的这张图 ^_^

这张图中展示的是1个标准的软件性能模型。在图中有三条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。
在这张图中我们可以看到,最开始,随着并发用户数的增长,资源占用率和吞吐量会相应的增长,但是响应时间的变化不大;不过当并发用户数增长到一定程度后,资源占用达到饱和,吞吐量增长明显放缓甚至停止增长,而响应时间却进一步延长。如果并发用户数继续增长,你会发现软硬件资源占用继续维持在饱和状态,但是吞吐量开始下降,响应时间明显的超出了用户可接受的范围,并且最终导致用户放弃了这次请求甚至离开。
根据这种性能表现,图中划分了三个区域,分别是Light Load(较轻的压力)、Heavy Load(较重的压力)和Buckle Zone(用户无法忍受并放弃请求)。在Light Load和Heavy Load 两个区域交界处的并发用户数,我们称为“最佳并发用户数(The Optimum Number of Concurrent Users)”,而Heavy Load和Buckle Zone两个区域交界处的并发用户数则称为“最大并发用户数(The Maximum Number of Concurrent Users)”。
当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃;而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。
对应到我们上面理发店的例子,每小时3个顾客就是这个理发店的最佳并发用户数,而每小时9个顾客则是它的最大并发用户数。当每小时都有3个顾客到来时,理发店的整体工作效率最高;而当每小时都有9个顾客到来时,前几个小时来的顾客还可以忍受,但是随着等待的顾客人数越来越多,等待时间越来越长,最终还是会有顾客无法忍受而离开。同时,随着理发店里顾客人数的增多和理发师工作时间的延长,理发师会逐渐产生疲劳,还要多花一些时间来清理环境和维持秩序,这些因素将最终导致理发师的工作效率随着顾客人数的增多和工作的延长而逐渐的下降,到最后可能要1.5小时甚至2个小时才能剪完1个发了。
当然,如果一开始就有10个顾客到来,则注定有1位顾客剪不到头发了。
进一步理解“最佳并发用户数”和“最大并发用户数”
在上一节中,我们详细的描述了并发用户数同资源占用情况、吞吐量以及响应时间的关系,并且提到了两个新的概念——“最佳并发用户数(The Optimum Number of Concurrent Users)”和“最大并发用户数(The Maximum Number of Concurrent Users)”。在这一节中,我们将对“最佳并发用户数”和“最大并发用户数”的定义做更加清晰和明确的说明。
对于一个确定的被测系统来说,在某个具体的软硬件环境下,它的“最佳并发用户数”和“最大并发用户数”都是客观存在。以“最佳并发用户数”为例,假如一个系统的最佳并发用户数是50,那么一旦并发量超过这个值,系统的吞吐量和响应时间必然会 “此消彼长”;如果系统负载长期大于这个数,必然会导致用户的满意度降低并最终达到一种无法忍受的地步。所以我们应该 保证最佳并发用户数要大于系统的平均负载。
要补充的一点是,当我们需要对一个系统长时间施加压力——例如连续加压3-5天,来验证系统的可靠性或者说稳定性时,我们所使用的并发用户数应该等于或小于“最佳并发用户数”——大家也可以结合上面的讨论想想这是为什么 ^_^
而对于最大并发用户数的识别,需要考虑和鉴别一下以下两种情况:
1. 当系统的负载达到最大并发用户数后,响应时间超过了用户可以忍受的最大限度——这个限度应该来源于性能需求,例如:在某个级别的负载下,系统的响应时间应该小于5秒。这里容易疏忽的一点是,不要把顾客因为无法忍受而离开时店内的顾客数量作为理发店的“最大并发用户数”,因为这位顾客是在3小时前到达的,也就是说3小时前理发店内的顾客数量才是我们要找的“最大并发用户数”。而且,这位顾客的离开只是一个开始,可能有会更多的顾客随后也因为无法忍受超长的等待时间而离开;
2. 在响应时间还没有到达用户可忍受的最大限度前,有可能已经出现了用户请求的失败。以理发店模型为例,如果理发店只能容纳6位顾客,那么当7位顾客同时来到理发店时,虽然我们可以知道所有顾客都能在可容忍的时间内剪完头发,但是因为理发店容量有限,最终只好有一位顾客打道回府,改天再来。
对于一个系统来说,我们应该 确保系统的最大并发用户数要大于系统需要承受的峰值负载。
如果你已经理解了上面提到的全部的概念,我想你可以展开进一步的思考,回头看一下自己以往做过的性能测试,看看是否可以对以往的工作产生新的理解。也欢迎大家在这里提出自己的心得或疑惑,继续讨论下去。
理发店模型的进一步扩展
这一节中我会提到一些对理发店模型的扩展,当然,我依然是只讲述现实中的理发店的故事,至于如何将这些扩展同性能测试以及性能解决方案等方面关联起来,就留给大家继续思考了 ^_^
扩展场景1:有些顾客已经是理发店的老顾客,他们和理发师已经非常熟悉,理发师可以不用花费太多时间沟通就知道这位顾客的想法。并且理发师对这位顾客的脑袋的形状也很熟悉,所以可以更快的完成一次理发的工作。
扩展场景2:理发店并不是只有剪发一种业务,还提供了烫发染发之类的业务,那么当顾客提出新的要求时,理发师服务一位顾客的时间可能会超过标准的1小时。而且这时如果要计算每位顾客的等待时间就变得复杂了很多,有些顾客的排队时间会比原来预计的延长,并最终导致他们因为无法忍受而离开。
扩展场景3:随着烫发和染发业务的增加,理发师们决定分工,两位专门剪发,一位专门负责烫发和染发。
扩展场景4:理发店的生意越来越好,理发师的数量和理发店的门面已经无法满足顾客的要求,于是理发店的老板决定在旁边再开一家店,并招聘一些工作能力更强的理发师。
扩展场景5:理发店的生意变得极为火爆了,两家店都无法满足顾客数量增长的需求,并且有些顾客开始反映到理发店的路途太远,到了以后又因为烫发和染发的人太多而等太久。可是理发店的老板也明白烫发和染发的收入要远远高于剪发阿,于是他脑筋一转,决定继续改变策略,在附近的几个大型小区租用小的铺面开设分店,专职剪发业务;再在市区的繁华路段开设旗舰店,专门为烫发、染发的顾客,以及VIP顾客服务。并增设800电话,当顾客想要剪发时,可以拨打这个电话,并由服务人员根据顾客的居住地点,将其指引到距离最近的一家分店去。
这篇文章就先写到这里了,希望大家在看完之后可以继续思考一下,也写出自己的心得体会或者新的想法,记下自己的不解和疑惑,让我们在不断的交流和讨论中走的更远 ^_^
-
转《LoadRunner 没有告诉你的》之四——理解性能
2007-09-16 23:39:43
本文是《LoadRunner没有告诉你的》系列文章的第四篇,在这篇短文中,我将尽可能用简洁清晰的文字写下我对“性能”的看法,并澄清几个容易混淆的概念,帮助大家更好的理解“性能”的含义。
如何评价性能的优劣: 用户视角 vs. 系统视角
对于最终用户(End-User)来说,评价系统的性能好坏只有一个字——“快”。最终用户并不需要关心系统当前的状态——即使系统这时正在处理着成千上万的请求,对于用户来说,由他所发出的这个请求是他唯一需要关心的,系统对用户请求的响应速度决定了用户对系统性能的评价。
而对于系统的运营商和开发商来说,期望的是能够让尽可能多的用户在任意时刻都拥有最好的体验,这就要确保系统能够在同一时间内处理更多的用户请求。正如在《理发店模型》一文中所描述的:系统的负载(并发用户数)与吞吐量(每秒事务数)、响应时间以及资源利用率(包括软硬件资源)之间存在着一个“此消彼长”的关系。因此,从系统的运营商和开发商的角度来看,所谓的“性能”是一个整体的概念,是系统的负载与吞吐量、可接受的响应时间以及资源利用率之间的平衡。
换句话说,“好的性能”意味着更大的最佳并发用户数(The Optimum Number of Concurrent Users)和 最大并发用户数(The Maximum Number of Concurrent Users)。有关“最佳/最大并发用户数”的概念请参见《理发店模型》一文。
另外,从系统的视角来看,所需要关注的还包括三个与“性能”有关的属性:可靠性(Reliability),可伸缩性(Scalability)和 可恢复性(Recoverability)——我将会在本系列文章的第五篇“无处不在的性能测试”中专门讨论这三个属性的含义和相关的实践经验。
响应时间

上面这张图引自段念兄的一份讲义,不过我略作了些修改。从图中我们可以清楚的看到一个请求的响应时间是由几部分时间组成的,包括
C1:用户请求发出前在客户端需要完成的预处理所需要的时间;
C2:客户端收到服务器返回的响应后,对数据进行处理并呈现所需要的时间;
A1:Web/App Server 对请求进行处理所需要的时间;
A2:DB Server 对请求进行处理所需的时间;
A3:Web/App Server 对 DB Server 返回的结果进行处理所需的时间;
N1:请求由客户端发出并达到Web/App Server 所需要的时间;
N2:如果需要进行数据库相关的操作,由Web/App Server 将请求发送至DB Server 所需要的时间;
N3:DB Server 完成处理并将结果返回Web/App Server 所需的时间;
N4:Web/App Server 完成处理并将结果返回给客户端所需的时间;
从用户的角度来看,响应时间=(C1+C2)+(A1+A2+A3)+(N1+N2+N3+N4);但是从系统的角度来看,响应时间只包括(A1+A2+A3)+(N1+N2+N3+N4)。
在理解了响应时间的组成之后,可以帮助我们通过对响应时间的分析来更好的识别和定位系统的性能瓶颈。
吞吐量 vs. 吞吐量
在不同的测试工具中,对于吞吐量(Throughput)会有不同的解释。例如,在LoadRunner中,这个指标是以字节数为单位来衡量网络吞吐量的,而在JMeter中则是以事务数/秒为单位来衡量系统的响应能力的。不过在大多数英文的性能测试方面的书籍或资料中,吞吐量的定义使用的是后者。
并发用户数 ≠ 每秒请求数
这是两个容易让初学者混淆的概念。
简单说,当你在性能测试工具或者脚本中设置了100并发用户数后,并不能期望着一定会有每秒100个请求发给服务器。事实上,对于一个虚拟用户来说,每秒发出多少请求只跟服务器返回响应的速度有关。如果虚拟用户在0.5秒内就收到了响应,那么它会立即发出第二个请求;而如果要一直等待3秒才能得到响应,它将会一直等到收到响应后才发出第二个请求。也就是说,并发用户数的设置只是保证服务器在任一时刻都有100个请求需要处理,而并不一定是保证每秒中发送100个请求给服务器。
所以,只有当响应时间恰好是1秒时,并发用户数才会等于每秒请求数;否则,每秒请求数可能大于并发用户数或小于并发用户数。
-
转描述性统计与性能结果分析(续) ——《LoadRunner 没有告诉你的》之二
2007-09-16 23:38:33
数据统计分析的思路与分析结果的展示方式是同样重要的,有了好的分析思路,但是却不懂得如何更好的展示分析结果和数据来印证自己的分析,就像一个人满腹经纶却不知该如何一展雄才
^_^一图胜千言,所以这次我会用两张图表来说明“描述性统计”在性能测试结果分析中的其他应用。
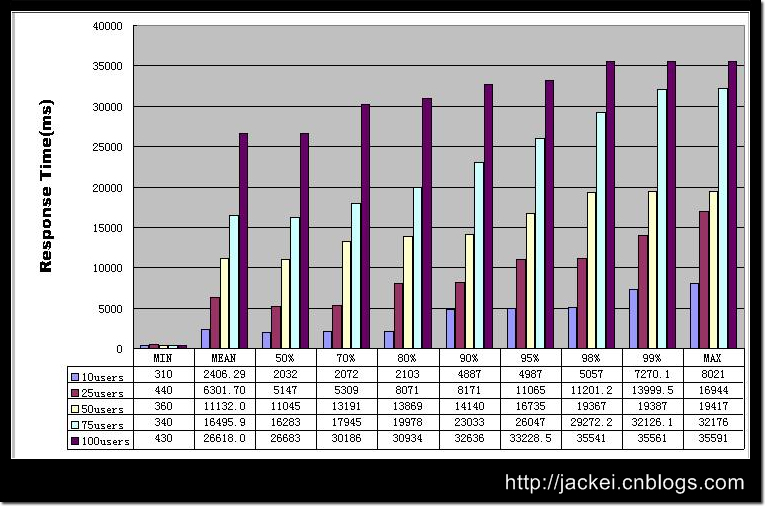
在这张图中,我们继续使用了上一篇文章——《描述性统计与结果分析》一文中的方法,对响应时间的分布情况来进行分析。上面这张图所使用的数据是通过对
Google.com 首页进行测试得来的,在测试中分别使用10/25/50/75/100 几个不同级别的并发用户数量。通过这张图表,我们可以通过横向比较和纵向比较,更清晰的了解到被测应用在不同级别的负载下的响应能力。
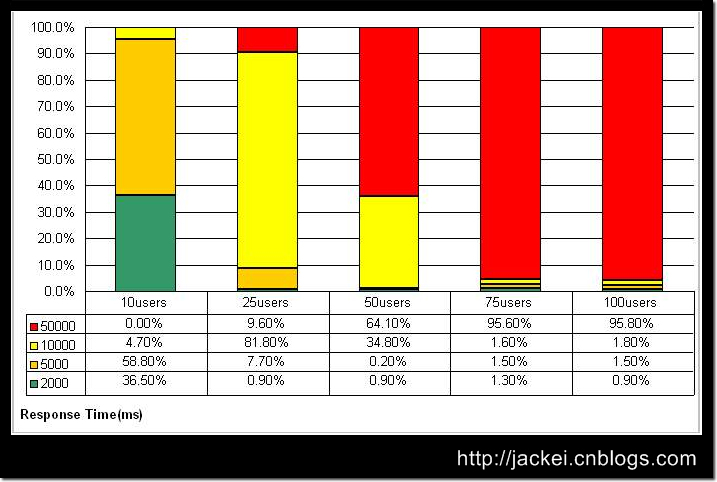
这张图所使用的数据与第一张图一样,但是我们使用了另外一个视角来对数据进行展示。表中最左侧的2000/5000/10000/50000的单位是毫秒,分别表示了在整个测试过程中,响应时间在0-2000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在2001-5000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在5001-10000毫秒范围内的事务数量占成功的事务总数的百分比,以及响应时间在10001-50000毫秒范围内的事务数量占成功的事务总数的百分比。
这几个时间范围的确定是参考了业内比较通行的“2-5-10原则”——当然你也可以为自己的测试制定其他标准,只要得到企业内的承认就可以。所谓的“2-5-10原则”,简单说,就是当用户能够在2秒以内得到响应时,会感觉系统的响应很快;当用户在2-5秒之间得到响应时,会感觉系统的响应速度还可以;当用户在5-10秒以内得到响应时,会感觉系统的响应速度很慢,但是还可以接受;而当用户在超过10秒后仍然无法得到响应时,会感觉系统糟透了,或者认为系统已经失去响应,而选择离开这个Web站点,或者发起第二次请求。
那么从上面的图表中可以看到,当并发用户数量为10时,超过95%的用户都可以在5秒内得到响应;当并发用户数量达到25时,已经有80%的事务的响应时间处在危险的临界值,而且有相当数量的事务的响应时间超过了用户可以容忍的限度;随着并发用户数量的进一步增加,超过用户容忍限度的事务越来越多,当并发用户数到达75时,系统几乎已经无法为任何用户提供响应了。
这张图表也同样可以用于对不同负载下事务的成功、失败比例的比较分析。
Note:上面两个图表中的数据,主要通过Excel 中提供的FREQUENCY,AVERAGE,MAX,MIN和PERCENTILE几个统计函数获得,具体的使用方法请参考Excel帮助手册。
-
转《LoadRunner 没有告诉你的》之一——描述性统计与性能结果分析
2007-09-16 23:36:41
LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。
为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。为什么这么说?你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求?
假如有两组测试结果,响应时间分别是 {1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想?
假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信?
为了解答上面的疑问,我们先来看一张表:

在上面这个表中包含了几个不同的列,其含义如下:
CmdID 测试时被请求的页面
NUM 响应成功的请求数量
MEAN 所有成功的请求的响应时间的平均值
STD DEV 标准差(这个值的作用将在下一篇文章中重点介绍)
MIN 响应时间的最小值
50 th(60/70/80/90/95 th) 如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。后面的60/70/80/90/95 th 也是同样的含义
MAX 响应时间的最大值
我想看完了上面的这个表和各列的解释,不用多说大家也可以明白我的意思了。我把结论性的东西整理一下:
1. 90%用户响应时间在 LoadRunner中是可以设置的,你可以改为80%或95%;
2. 对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导出到Excel中,并使用Excel中的PERCENTILE 函数很简单的算出不同百分比用户请求的响应时间分布情况;
3. 从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70%用户响应时间相一致。也就是说假如我们确定Home Page的响应时间应该在5秒内,那么从平均事务响应时间来看是满足的,但是实际上有10-20%的用户请求的响应时间是大于这个值的;对于Page 1也是一样,假如我们确定对于Page 1 的请求应该在3秒内得到响应,虽然平均事务响应时间是满足要求的,但是实际上有20-30%的用户请求的响应时间是超过了我们的要求的;
4. 你可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。这时候你也许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用户请求的响应时间都是在性能需求所定义的范围之内的;
5. 如果你想使用这种方法来评估系统的性能,一个推荐的做法是尽可能让你的测试场景运行的时间长一些,因为当你获得的测试数据越多,这个响应时间的分布曲线就越接近真实情况;
6. 在确定性能需求时,你可以用平均事务响应时间来衡量系统的性能,也可以用90%或95%用户响应时间来作为度量标准,它们并不冲突。实际上,在定义某些系统的性能需求时,一定范围内的请求失败也是可以被接受的;
7. 上面提到的这些内容其实是与工具无关的,只要你可以得到原始的响应时间记录,无论是使用LoadRunner还是JMeter或者OpenSTA,你都可以用这些方法和思路来评估你的系统的性能。
事实上,在性能测试领域中还有更多的东西是目前的商业测试工具或者开源测试工具都没有专门讲述的——换句话说,性能测试仅仅有工具是不够的。我们还需要更多其他领域的知识,例如数学和统计学,来帮助我们更好的分析性能数据,找到隐藏在那些数据之下的真相。
欢迎各位同行高手灌水拍砖 ^_^
-
转《LoadRunner没有告诉你的》之六——获取有效的性能需求
2007-09-13 23:33:12
本文是《LoadRunner没有告诉你的》系列的第六篇,我将继续保持“无废话”的原则,用尽可能简洁、明确的语句来表述我对性能测试的看法和经验。在这篇文章中,我们要讨论的是如何获取“有效的”性能需求。
一个实际的例子
为了便于大家的理解,我们先来看一个性能需求的例子,让大家有一个感性的认识,本文后面的讨论也会再次提到这个例子。
这是一个证券行业系统中某个业务的“实际需求”——实际上是我根据通过网络搜集到的数据杜撰出来的,不过看起来像是真实的 ^_^
l 系统总容量达到日委托6000万笔,成交9000万笔
l 系统处理速度每秒7300笔,峰值处理能力达到每秒10000笔
l 实际股东帐号数3000万
这个例子中已经包括几个明确的需求:
l 最佳并发用户数需求:每秒7300笔
l 最大并发用户数需求:峰值处理能力达到每秒10000笔
l 基础数据容量:实际股东帐号数3000万
l 业务数据容量:日委托6000万笔,成交9000万笔——可以根据这个推算出每周、每月、每年系统容量的增长模型
什么是“有效的”性能需求?
要想获得有效的性能需求,就要先了解什么样的需求是“有效的”。有效的性能需求应该符合以下三个条件。
1. 明确的数字,而不是模糊的语句。
结合上面的例子来看,相信这个应该不难理解。但是有的时候有了数字未必就不模糊。例如常见的一种需求是“系统需要支持5000用户”,或者“最大在线用户数为8000”。这些有数字的需求仍然不够明确,因为还需要考虑区分系统中不同业务模块的负载,以及区分在线用户和并发用户的区别。关于这方面的内容,在下面两篇文章中的留言内容中有精彩的讨论:
http://www.cnblogs.com/jackei/archive/2006/11/15/560578.html
http://www.cnblogs.com/jackei/archive/2006/11/16/561846.html
2. 有凭有据,合理,有实际意义。
通常来说,性能需求要么由客户提出,要么由开发方提出。对于第一种情况,要保证需求是合理的,有现实意义的,不能由着客户使劲往高处说,要让客户明白性能是有成本的。对于第二种情况,性能需求不能简单的来源于项目组成员、PM或者测试工程师的估计或者猜测,要保证性能需求的提出是有根据的,所使用的数据和计算公式是有出处的——本文后面的部分会介绍获得可用的数据和计算公式的方法。
3. 相关人员达成一致。
这 一点非常关键。如果相关人不能对性能需求达成一致,可能测了也白测——特别是在客户没有提出明确的性能需求而由开发方提出时。这里要注意“相关人员”的识 别,通常项目型的项目的需要与客户方的项目经理或负责人进行确认,产品型的项目需要与直属领导或者市场部进行确认。如果实在不知道该找谁确认,那就把这个 责任交给你的直属领导;如果你就是领导了,那这领导也白当了 ^_^
如何获得有效的性能需求
上面提到了“有效的”性能需求的一个例子和三个条件,下面来我们将看到有哪些途径可以帮助我们获得相关的数据——这些方法我在实际的工作中都用过,并且已经被证实是可行的。这几种方法由易到难排列如下:
1. 客户方提出
这是最理想的一种方式,通常电信、金融、保险、证券以及一些其他运营商级系统的客户——特别是国外的客户都会提出比较明确的性能需求。
2. 根据历史数据来分析
根据客户以往的业务情况来分析客户的业务量以及每年、每月、每周、每天的峰值业务量。如果客户有旧的系统,可以根据已有系统的访问日志,数据库记录,业务报表来分析。要特别注意的是,不同行业、不同应用、不同的业务是有各自的特点的。例如,购物网站在平时的负载主要集中在晚上,但是节假日时访问量和交易量会是平时的数倍;而地铁的售票系统面临的高峰除了周末,还有周一到周五的一早一晚上下班时间。
3. 参考历史项目的数据
如果该产品已有其他客户使用,并且规模类似的,可以参考其他客户的需求。例如在线购物网站,或者超市管理系统,各行业的进销存系统。
4. 参考其他同行类似项目的数据
如果本企业没有做过类似的项目,那么可以参考其他同行企业的公布出来的数据——通常在企业公布的新闻或者成功解决方案中会提到,包括系统容量,系统所能承受的负载以及系统响应能力等。
5. 参考其他类似行业应用的数据
如果无法找打其他同行的数据,也可以参考类似的应用的需求。例如做IPTV或者DVB计费系统的测试,可以参考电信计费系统的需求——虽然不能完全照搬数据,但是可以通过其他行业成熟的需求来了解需要测试的项目有哪些,应该考虑到的情况有哪些种。
6. 参考新闻或其他资料中的数据
最后的一招,特别是对于一些当前比较引人关注的行业,涉及到所谓的“政绩”的行业,通常可以通过各种新闻媒体找到一些可供参考的数据,但是需要耐心的寻找。例如我们在IPTV和DVB系统的测试中,可以根据新闻中公布的各省、各市,以及国外各大运营商的用户发展情况和用户使用习惯来估算系统容量和系统各个模块的并发量。
又一块砖抛出来了,希望大家在看完之后也有更多的玉丢过来 ^_^
-
LR安装卸载
2007-09-13 23:13:54
loadrunner安装的问题很多,各个网站的帖子也很多,51test中就有很多。安装的时候基本上的问题就是安装包所在路径为汉字名称或者别的什么。
主要说一下自己遇到的问题,和解决的方法,希望遇到的人可以绕过而行,不用在走弯路了。
安装的问题:
整个装的过程都是OK的,完成后,提示需要重启系统丢失system32下的 BHOManager.dll DLLRegisterServer return error 8007007e”(我的系统是番茄花园的xp系统),当你确定以后,lr安装目录下bin中的所有dll文件都不能注册了,所以安装就失败,就这个问 题,刚开始我一直没有定位好,等看了一段时候之后发现,BHOManager虽然在system32下,但是不是系统本身的dll,而是lr自己写入的 (因为以前装好的lr中IE加载项中,印象是见过的), DLLRegisterServer return error 8007007e 意味着没有找到BHOManager这个dll文件,或者这个dll没有注册,但是手动去注册却是报错,那现在问题基本上已经可以看出端倪了,所有的不能 成功的因素,全都是BHOManager.dll没有成功注册的缘故,(找到根源就可以迎刃而解了)。在百度中搜索,发现如下内容:
你问题的解决方法,我今天也遇到同样的问题,给你做回答,呵呵,这个跟双核没关系,可能是你用的也是番茄花园的xp系统把,它的atl.dll是没有注册的,导致lr的BHOManager。dll无法成功注册!!!(原理就是这些),方法如下:
附:
我再重新安装时遇到的另一个问题。可能遇到的朋友并不多,放上来给大家参考吧。
在安装到最后的时候遇到这样一个报错:BHOManager.dll 注册失败。
于是在提示重启时未重启,而是去手动注册该dll文件,却弹出了另一个提示,"DLLRegisterServer in BHOManager.dll failed
Return code was 0x8007007e"于是到网上搜了下,终于找到了解决方法。
1. 需要IE 6.0 及以上版本支持, 请检查你的IE浏览器是否为 6.0 以上版本。
2. 请检查Windows系统目录中是否存在以下三个文件: msvcp60.dll, mfc42.dll, msvcrt.dll 文件, 如果有缺少,请下载并拷贝到Windows系统目录中去即可。
3. 请查看您的系统中是否缺少 atl.dll 文件, 如果没有, 请从其他相同操作系统的机器上拷贝这个文件到Windows系统目录, 然后打开命令行窗口并在该目录下运行命令:
regsvr32 atl.dll
看到成功提示后,再次手动注册BHOManager.dll(注册方法:打开命令行窗口并在该目录下运行命令regsvr32 c:\windows\system32\BHOManager.dll),提示注册成功。
全部完成后重启电脑,该问题就解决拉 :)
LR终于装好了。
那就意味这,BHOManager.dll的注册是和atl.dll的注册有关,前者调用后者中的东西,只要后者成功注册,前者就可以OK解决了!呵呵~~~~世界清净了许多!!哈哈!!
卸载:
因为之前一直没有分析正确问题的所在,所以卸载和重新安装loadrunner好几次,关于卸载的一些问题,及时你按照卸载工具卸载了 loadrunner,下次装的时候还是会包license失效,解决方法,要登录到注册表regedit中(当发现报错后,立即去注册表删除下边的内 容,只要有相同的就删除,这样注册码就可以再次使用了,并不会报错,呵呵)。
删除如下内容:
HKEY_CLASSES_ROOT\Mercury.Lm70Control
HKEY_CLASSES_ROOT\Mercury.Lm70Control.1
同时删除
Mercury.Lm70ControlMgr
Mercury.Lm70ControlMgr.1然后就使用查找功能,搜索“Mercury”,发现有Lm70Contro字样的东西都要删除掉。
最后删除下面内容:
HKEY_CURRENT_USER\Software\Mercury Interactive
HKEY_LOCAL_MACHINE\SOFTWARE\Mercury Interactive删除完成后,继续填入license,下一步,如果还是不行,继续去注册表中删除上边内容,知道没有了,就OK了。
这些都是自己做过实际操作的内容,希望对大家有帮助。 -
LR里组 vusers 进程 线程的关系
2007-09-13 23:07:27
如果是线程安全的协议,在一个组(进程)里并发多个vusers,可以不用开那么进程。这可以减少系统的开销。
如果不是线程安全的协议,我们需要开多个进程来处理Vusers。这样势必增加系统的开销。
其实对现在的硬件来说,基本上客户端成为瓶颈的机会不是很大。(除非这公司太穷了)
^_^
这里我做了个实验,画了一张表,来形象的说明一下组/vusers/线程/进程的关系。
注:这里,我假定的是10vsuers:
我这里脚本都是一样的。设置vusers按进程还是线程运行Vusers(个/组)组(个)mmdrv.exe中的线程数(个/组)Mmdrv.exe进程(个)平均每个进程占的内存(k)Mmdrv.exe占有内存总数(k)线程1011217,5007,500线程1103105,15051,500进程1011104,67646,760进程1101105,15051,500
大家如果自己做实验,内存可能会不一样。
在表里,我们可以很清楚的看到,进程多的时候,占用内存肯定是多的。
如果在同一组里开多个线程,占用内存就少得多。
我们还要注意一个细节就是在用线程来运行vusers的时候,每个进程中会多出几个线程来。
这多出来的很个进程在做什么,我没有查它的API,我想可能是维护进程之间的运行。
很显然的,还有个问题,就是哪个压力更大。
这个问题也有些人在问,我想这个应该是很明显的吧。
其实对服务器来说,只要是10个用户都在正常工作,而速度不会受到本地硬件的影响。
对服务器的压力是一样的。
这么来思考:
假设来说。
我们是从客户端来发数据库的,10个用户,如果一秒钟发20个数据包。
那对服务器来说,收到的数据包都是一样多的。所以压力也会是一样的。
那会不会存在在同一个进程里开10个线程速度更慢呢。
这个,我以为不会的。
所以我认为压力是一样的。
标题搜索
我的存档
数据统计
- 访问量: 58111
- 日志数: 103
- 图片数: 4
- 文件数: 2
- 建立时间: 2007-05-20
- 更新时间: 2010-11-23
