
-
ant配置文件标准模板(测试通过)
2009-02-15 20:56:20
<?xml version="1.0" encoding="UTF-8"?>
<project name="MultiLogin" default="compile" basedir=".">
<property name="webapp.name" value="MultiLogin" />
<!-- tomcat的安装路径-->
<property name="catalina.home" value="D:\MySoft\Tomcat 6.0" />
<!--src.dir :原文件路径 -->
<property name="src.dir" value="src" />
<!-- 编译所需要的jar包的存放目录-->
<property name="lib.dir" value="${basedir}/WEB-INF/lib" />
<!--build.classes:class 文件 存放目录 -->
<property name="class.dir" value="${basedir}/WEB-INF/classes" />
<!-- tomcat 的应用发布路径-->
<property name="webapps.dir" value="${catalina.home}/webapps" />
<!-- jsp 页面文件-->
<property name="ui.dir" value="admin" />
<!-- **********************************set classpath********************************** -->
<!-- 设置环境变量,把编译所需要的jar包引入-->
<path id="compile.classpath">
<fileset dir="${catalina.home}/lib">
<include name="*.jar" />
</fileset>
<fileset dir="${lib.dir}">
<include name="*.jar" />
</fileset>
</path>
<!-- **********************************init********************************** -->
<!-- 初始化,创建各种目录 -->
<target name="init">
<mkdir dir="${src.dir}" />
<mkdir dir="${lib.dir}" />
<mkdir dir="${ui.dir}" />
</target><!-- **********************************clean class********************************** -->
<!-- 清除 编译的文件 -->
<target name="clean" description="Delete old build and dist directories">
<delete dir="${class.dir}" includes="**/*.class" />
</target><!-- **********************************compile java********************************** -->
<!-- 编译java文件 -->
<target name="compile" description="Compile Java sources" depends="clean">
<mkdir dir="${class.dir}" />
<javac srcdir="${src.dir}" destdir="${class.dir}">
<classpath refid="compile.classpath" />
</javac><copy todir="${class.dir}">
<fileset dir="${src.dir}" excludes="**/*.java" />
</copy>
</target><!-- 打成jar包 -->
<target name="jar" depends="compile">
<jar jarfile="${src.dir}/test.jar" basedir="${class.dir}" excludes="**/*Test.class" />
</target>
<!-- **********************************deploy webapp********************************** -->
<!-- 部署到tomcat-->
<target name="deploy" description="Install application to servlet container" depends="compile">
<delete dir="${webapps.dir}/${webapp.name}" />
<war destfile="${webapps.dir}/${webapp.name}.war" webxml="${basedir}/WEB-INF/web.xml">
<fileset dir="${ui.dir}" />
<lib dir="${lib.dir}" />
<classes dir="${class.dir}" />
</war>
</target><!-- **********************************start web server********************************** -->
<!-- 启动tomcat -->
<target name="startserver" description="Start web server">
<exec dir="${catalina.home}/bin" executable="cmd.exe">
<env key="CATALINA_HOME" path="${catalina.home}" />
<arg value="/c startup.bat" />
</exec>
</target><!-- **********************************stop web server********************************** -->
<!-- 停止tomcat-->
<target name="stopserver" description="Stop web server">
<exec dir="${catalina.home}/bin" executable="cmd.exe">
<env key="CATALINA_HOME" path="${catalina.home}" />
<arg value="/c shutdown.bat" />
</exec>
</target><!-- **********************************start work********************************** -->
<target name="start" description="Clean build and dist directories, then compile">
<ant target="deploy" />
<ant target="startserver" />
</target><!-- **********************************reload web server********************************** -->
<!-- 重启tomcat -->
<target name="reload" description="reload web server">
<ant target="stopserver">
</ant>
<sleep seconds="2">
</sleep>
<ant target="start">
</ant>
</target>
</project> -
主题:ant 部署web工程模板
2009-02-12 16:25:48
- <?xml version="1.0" encoding="UTF-8"?>
- <project name="zkProject" default="compile" basedir=".">
- <property name="webapp.name" value="zkproject"/>
- <property name="catalina.home" value="D:\Program Files\apache-tomcat-6.0.16"/>
- <property name="src.dir" value="${basedir}/WEB-INF/src"/>
- <property name="lib.dir" value="${basedir}/WEB-INF/lib"/>
- <property name="class.dir" value="${basedir}/WEB-INF/classes"/>
- <property name="webapps.dir" value="${catalina.home}/webapps"/>
- <property name="ui.dir" value="ui"/>
- <!-- **********************************set classpath********************************** -->
- <path id="compile.classpath">
- <fileset dir="${catalina.home}/lib">
- <include name="*.jar"/>
- </fileset>
- <fileset dir="${lib.dir}">
- <include name="*.jar"/>
- </fileset>
- </path>
- <!-- **********************************init********************************** -->
- <target name="init">
- <mkdir dir="${src.dir}"/>
- <mkdir dir="${lib.dir}"/>
- <mkdir dir="${ui.dir}"/>
- </target>
- <!-- **********************************clean class********************************** -->
- <target name="clean" descrīption="Delete old build and dist directories">
- <delete dir="${class.dir}" includes="**/*.class"/>
- </target>
- <!-- **********************************compile java********************************** -->
- <target name="compile" descrīption="Compile Java sources" depends="clean">
- <mkdir dir="${class.dir}"/>
- <javac srcdir="${src.dir}"
- destdir="${class.dir}">
- <classpath refid="compile.classpath"/>
- </javac>
- <copy todir="${class.dir}">
- <fileset dir="${src.dir}" excludes="**/*.java"/>
- </copy>
- </target>
- <!-- **********************************deploy webapp********************************** -->
- <target name="deploy" descrīption="Install application to servlet container" depends="compile">
- <delete dir="${webapps.dir}/${webapp.name}"/>
- <war destfile="${webapps.dir}/${webapp.name}.war" webxml="${basedir}/WEB-INF/web.xml">
- <fileset dir="ui"/>
- <lib dir="${lib.dir}"/>
- <classes dir="${class.dir}"/>
- </war>
- </target>
- <!-- **********************************start web server********************************** -->
- <target name="startserver" descrīption="Start web server" >
- <exec dir="${catalina.home}/bin" executable="cmd.exe">
- <env key="CATALINA_HOME" path="${catalina.home}"/>
- <arg value="/c startup.bat"/>
- </exec>
- </target>
- <!-- **********************************stop web server********************************** -->
- <target name="stopserver" descrīption="Stop web server" >
- <exec dir="${catalina.home}/bin" executable="cmd.exe">
- <env key="CATALINA_HOME" path="${catalina.home}"/>
- <arg value="/c shutdown.bat"/>
- </exec>
- </target>
- <!-- **********************************start work********************************** -->
- <target name="start" descrīption="Clean build and dist directories, then compile">
- <ant target="deploy"/>
- <ant target="startserver"/>
- </target>
- <!-- **********************************reload web server********************************** -->
- <target name="reload" descrīption="reload web server">
- <ant target="stopserver"></ant>
- <sleep seconds="2"></sleep>
- <ant target="start"></ant>
- </target>
- </project>
-
持续集成服务器(CruiseControl)安装和配置
2009-02-11 09:25:29
【IT168 技术文章】
我使用的是CruiseControl-2.7.1
CruiseControl:http://cruisecontrol.sourceforge.net/
SVN:http://subversion.tigris.org/
首先安装你的CruiseControl,你可以选择exe的文件下载,直接安装就可以,
然后设置你的环境变量,将svn添加到你的环境变量的path中。
CruiseControl安装后的目录结构是:
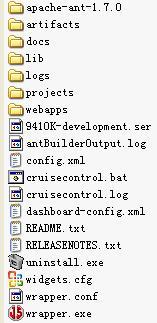
其中CruiseControl(以下简称CC)自带ant1.7.0;文档在docs目录下,这里面包括config.xml的相关的参数设置说明;logs下面包括日志信息,可以通过在config.xml中指定日志路径和名称;projects下面放的是需要进行持续集成的项目,lib目录中放有cruisecontrol.jar和其他运行需要的jar;webapps下是cruisecontrol build结果的网站,可以通过访问 http://127.0.0.1:8080/dashboard来进行对你的项目进行编译发布到你指定的web容器上。
以下是我的一个项目的config.xml文件的配置:
xml 代码
1.<cruisecontrol>
2.<!--这个地方的项目名称要和你的projects目录下的项目名称一样-->
3. <project name="potato">
4. <listeners>
5. <currentbuildstatuslistener file="logs/${project.name}/status.txt"/>
6. </listeners>
7.
8. <bootstrappers>
9. <svnbootstrapper localWorkingCopy="projects/${project.name}" username="test" password="test" />
10. </bootstrappers>
11.
12. <modificationset quietperiod="60">
13. <svn localWorkingCopy="projects/${project.name}" username="test" password="test" />
14. </modificationset>
15.
16. <schedule interval="3600">
17.<!--这个地方配置的是使用ant来进行编译,后面的target是调用ant的那个任务,最后面的属性文件是我用来配置我的tomcat目录的,build.xml文件就是你工程下面的build文件-->
18. <ant anthome="apache-ant-1.7.0" time="0400" buildfile="projects/${project.name}/build.xml" target="deploy" propertyfile="projects/${project.name}/ant.properties"/>
19. </schedule>
20.
21. <log>
22. <!--merge dir="projects/${project.name}/target/test-results"/-->
23. <!--merge file="projects/${project.name}/dist/checkstyle.xml"/-->
24. </log>
25.
26. <publishers>
27. <onsuccess>
28. <artifactspublisher dest="artifacts/${project.name}" file="projects/${project.name}/dist/i941ok.war"/>
29. </onsuccess>
30. <htmlemail mailhost="inc-mx2"
31. returnaddress="zhangjf1@gmail.com"
32. skipusers="true"
33. subjectprefix="[admin.Build.Server]"
34. buildresultsurl="http://asd1-server:6636/dashboard"
35. username="admin"
36. password="admin"
37. charset="UTF-8">
38.<!--编译成功和失败发送的邮件地址-->
39. <failure address="zhangjf1@gmail.com" />
40. <success address="zhangjf1@gmail.com" />
41. </htmlemail>
42. </publishers>
43.
44. </project>
45.</cruisecontrol>把你的工程从svn上取下来放到你的projects目录下,启动的CruiseControl服务,在地址浏览器中输入http://127.0.0.1:8080/dashboard就可以看到你的项目的管理界面,你可以设置什么时候进行编译,也可以进行强制编译。
1 -
CruiseControl使用笔记
2009-02-11 09:21:39
本文所用cruisecontrol版本是2.8。
1. 日构建配置
日构建是指在每天指定的时间进行构建。
1.1. <Project>
requireModification 设为 false,含义是无论有没有变化,都要进行构建。
1.2. <Listener>
<listeners>
<currentbuildstatuslistener file="logs/${project.name}/status.txt"/>
</listeners>
如果没有设置, 那么dashboard上的status将是空,但并不影响大局,一般就如上配置。
1.3. <bootstrappers>
Bootstrappers配置了检查变更前的任务,也在Schedule中的任务之前。这里要完成schedule中任务所依赖的文件的更新。
比如
<bootstrappers>
<tfsbootstrapper itemSpec=“[vstsworkspace]\[setuppath]\build.xml />
</bootstrappers>
而cruisecontol给出的connectfour例子:
<bootstrappers>
<antbootstrapper anthome="apache-ant-1.7.0" buildfile="projects/${project.name}/build.xml" target="clean" />
</bootstrappers>
实际上没有必要,大可放到 schedule中的任务中。
1.4. <modificationset>
对于日构建,这其实是不需要的,但由于cc必须要1个mondification,可以配一个无效。两个建议:
1,配成检查本机某个目录,这个目录不需要变化;
<modificationset >
<filesystem folder="D:\WWS\JJJ"/>
</modificationset>
2,配成timebuild
<modificationset >
<timebuild time="1200" />
</modificationset>
这与schedule中的time配置有所冲突,shedule中任务的time设置后,此设置无效。
1.5. <schedule >
属性interval 是设置检查更新的间隔秒数。如果下面的任务配置了 time,这个属性会变得无效。
对于日构建任务,建议只设置一个,首选ant任务,全部要完成的动作在ant的build.xml中。
例:
<schedule interval="300">
<ant anthome="apache-ant-1.7.0" buildfile="projects/${project.name}/build.xml" time="2112" />
</schedule>
Build.xml中处理了获取代码、编译、测试、打包、发布等等任务。
1.6. <log>
如果采用了ant中junit任务,可以用下面语句合并日志。
<log>
<merge dir="projects/${project.name}/target/test-results"/>
</log>
1.7. <publishers>
主要配置email通知。配置简单,按说明即可。要注意的是,在force build时,缺省地存在名为"User"的用户,在发送列表中,但"User"不是一个有效的email,因此加入"User"的别名来解决这个问题。示例如下:
<publishers>
<htmlemail buildresultsurl="http://xx" mailhost="smtphost" username="xxx" password="xxx" returnaddress="xxx@yyy.com">
<map alias="User" address="xxxuser@gmail.com" />
<always address="xxxxx@hotmail.com" />
</htmlemail>
</publishers>
对于项目群汇总报告,建议采用 <http>
也可以将build.xml中最后的发布任务放到这里。比如
<publishers>
<onsuccess>
<antpublisher antscrīpt="C:\Java\apache-ant-1.6.1\bin\ant.bat"
antworkingdir="D:\workspace\MyProject"
buildfile="build.xml"
target="publish">
</antpublisher>
</onsuccess>
</publishers>
-
持续集成:什么应该自动化?
2009-02-06 15:16:39
一、什么是持续集成(Continuous Integration)?
这个名词已经在软件开发领域持续了N年,一个比较简单的定义如下:
持续集成(CI)是一种实践,可以让团队在持续的基础 上收到反馈并进行改进,不必等到开发周期后期才寻找和修复缺陷。通俗一点儿说,就是指对于开发人员的每一次代码提交,都自动地把Repository中所有代码Check out到一个空目录,并且自动运行所有Test Case。如果成功则接受这次提交,否则告诉所有人,这是一个失败的Revision。更具体的解释可以参考Martin fowler的Continuous Integration 。二、持续集成的价值与成本
有句时髦的话,叫做“存在即为合理”。既然持续集成已经存在了这么长的时间,而且没有消失的迹象,那就是有价值的东西。那么它的价值何在?有人概括如下:(1) 减小风险;(2) 减少手动过程;(3) 生成构建结果;(4) 安全感。
而持续集成的成本在于对持续集成代码的维护成本和集成的时间成本。因为随着项目进行,软硬件环境会越来越复杂,成品代码也会不断膨胀。此时,需要团队而修改或增加原有的测试代码,以适应这些变化,同时,每次集成所需时间也会变长,这就是持续集成的成本。某个blog中提道:“这种集成是如此的频繁,多少次的代码Commit就有多少次持续集成。前提是集成的成本很低,或者说是完全自动化的。”三、持续集成应该自动化什么呢?
我们要以尽可能少的成本来获得尽可能多的价值。这就要考虑哪些自动化是必要的啦。Jez Humble提到至少有六点要做到自动化,它们分别是(1)自动化的运行测试;(2) 自动产生可部署的二进制成品;(3) 自动将成品自动部署到近似生产环境;(4) 自动为CodeBase打上标签;(5) 自动运行回归测试;(6)自动生成度量报告。
四、持续集成服务器的选择
在进行持续集成实践前,应当正确的选择并配置持续集成服务器。比较成熟的持续集成服务器包括:CruiseControl, Anthill, Bamboo, TeamCity, Continuum 等。CruiseControl作为开源产品,以其对于各种SCM以及构建工具的广泛支持而被许多开发团队所接受。而开发自动化专家 Duvall 采用一致的评估标准和很多说明性示例,介绍了一些开源 CI 服务器,包括 Continuum、CruiseControl 和 Luntbuild。并指出“要根据 自己的 具体技术和政策需求对工具进行分析”。并用以下五个指标来评估CI工具,它们分别是:(1) 特性;(2) 可靠性;(3) 寿命;(4) 目标环境;(5) 易用性。结果如下表:

而CruiseControl是我唯一真正用过的持续集成工具,它现在灵活而又强大功能也让我瞠目,而且配置与管理也较两年前容易得多啦。为什么说它强大呢?因为你只要想得到的问题,它也都会有所考虑。朋友的Blog上有些CruiseControl的最佳实践足以证明这一点,只要你肯去实践。
五、只有持续集成服务器是远远不够的
正如Jez Humble所说,CruiseControl和其它的CI工具本质上只不过是一个定时器,时间一到,做你让它做的事情。所以,必然要有其它工具与其结合,方显持续集成的本色。这些工具又是什么呢?想测试的话,你就要用一些测试工具,如JUnit,JWebUnit,Selenium等等;想检查代码标准的话,你就要用checkstyle等代码规范检查工具;想要了解测试覆盖率的话,你可能就要用到JCoverage啦。当然,想得到二进制文件,就要用到Ant,Make之类的工具啦。
六、最重要的事:实践与反思
也许这些东西大家都知道,而且有些人可能已经实践过啦。无论这些实践的结果是怎样的,一定不要忘记总结和反思。如果这些实践成功了,不要把它归功于这个工具,而是要总结一下为什么会成功,如果你愿意的话,还可以和大家分享一下。如果这些实践失败了,也不要把它归功于这个工具,而是要反思一下,是否正确地使用了这个工具,团队成员是否都喜欢这个工具,为什么?
-
如何根据需要搭建软件测试环境
2009-02-06 13:53:22
去搭建测试环境是软件测试实施的一个重要阶段,测试环境适合与否会严重影响测试结果的真实性和正确性。测试环境包括硬件环境和软件环境,硬件环境指测试必需的服务器、客户端、网络连接设备,以及打印机/扫描仪等辅助硬件设备所构成的环境;软件环境指被测软件运行时的操作系统、数据库及其他应用软件构成的环境
一 确定测试环境的组成:
1.所需要的计算机的数量,以及对每台计算机的硬件配置要求,包括CPU的速度、内存和硬盘的容量、网卡所支持的速度、打印机的型号等;
2. 部署被测应用的服务器所必需的操作系统、数据库管理系统、中间件、WEB服务器以及其他必需组件的名称、版本,以及所要用到的相关补丁的版本;
3. 用来保存各种测试工作中生成的文档和数据的服务器所必需的操作系统、数据库管理系统、中间件、WEB服务器以及其他必需组件的名称、版本,以及所要用到的相关补丁的版本;
4. 用来执行测试工作的计算机所必需的操作系统、数据库管理系统、中间件、WEB服务器以及其他必需组件的名称、版本,以及所要用到的相关补丁的版本;
5. 是否需要专门的计算机用于被测应用的服务器环境和测试管理服务器的环境的备份;
6. 测试中所需要使用的网络环境。例如,如果测试结果同接入Internet的线路的稳定性有关,那么应该考虑为测试环境租用单独的线路;如果测试结果与局域网内的网络速度有关,那么应该保证计算机的网卡、网线以及用到的集线器、交换机都不会成为瓶颈;
二、管理测试环境
1. 设置专门的测试环境管理员角色
每个测试项目或测试小组都应当配备一名专门的测试环境管理员,其职责包括:测试环境的搭建。包括操作系统、数据库、中间件、WEB服务器等必须软件的安装,配置,并做好各项安装、配置手册的编写;记录组成测试环境的各台机器的硬件配置、IP地址、端口配置、机器的具体用途,以及当前网络环境的情况;测试环境各项变更的执行及记录;测试环境的备份及恢复;操作系统、数据库、中间件、WEB服务器以及被测应用中所需的各用户名、密码以及权限的管理;
2. 记录好测试环境管理所需的各种文档:
测试环境的各台机器的硬件环境文档,测试环境的备份和恢复方法手册,并记录每次备份的时间、备份人、备份原因以及所形成的备份文件的文件名和获取方式;用户权限管理文档,记录访问操作系统、数据库、中间件、WEB服务器以及被测应用时所需的各种用户名、密码以及各用户的权限,并对每次变更进行记录
3. 测试环境访问权限的管理
为每个访问测试环境的测试人员和开发人员设置单独的用户名和密码。访问操作系统、数据库、WEB服务器以及被测应用等所需的各种用户名、密码、权限,由测试环境管理员统一管理;测试环境管理员拥有全部的权限,开发人员只有对被测应用的访问权限和查看系统日志(只读),测试组成员不授予删除权限,用户及权限的各项维护、变更,需要记录到相应的“用户权限管理文档”中
4. 测试环境的备份和恢复
测试环境必须是可恢复的,否则将导致原有的测试用例无法执行,或者发现的缺陷无法重现,最终使测试人员已经完成的工作失去价值。因此,应当在测试环境(特别是软件环境)发生重大变动时进行完整的备份,例如使用Ghost对硬盘或某个分区进行镜像备份。 -
java.lang.OutOfMemoryError: PermGen space及其解决方法
2009-02-05 17:37:02
这个问题是我的工程中加入了Birt报表在Linux环境下运行出现的问题,从网上搜索了一下看到这文章发现并不是由于Birt的原因造成的
引用
1、
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域OutOfMemoryError: PermGen space从表面上看就是内存益出,解决方法也一定是加大内存。说说为什么会内存益出:这一部分用于存放Class和Meta的信息,Class在被 Load的时候被放入PermGen space区域,它和和存放Instance的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的APP会LOAD很多CLASS的话,就很可能出现PermGen space错误。这种错误常见在web服务器对JSP进行pre compile的时候。
改正方法:-Xms256m -Xmx256m -XX:MaxNewSize=256m -XX:MaxPermSize=256m
2、
在tomcat中redeploy时出现outofmemory的错误.
可以有以下几个方面的原因:
1,使用了proxool,因为proxool内部包含了一个老版本的cglib.
2, log4j,最好不用,只用common-logging
3, 老版本的cglib,快点更新到最新版。
4,更新到最新的hibernate3.2
3、
这里以tomcat环境为例,其它WEB服务器如jboss,weblogic等是同一个道理。
一、java.lang.OutOfMemoryError: PermGen space
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域,
这块内存主要是被JVM存放Class和Meta信息的,Class在被Loader时就会被放到PermGen space中,
它和存放类实例(Instance)的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对
PermGen space进行清理,所以如果你的应用中有很多CLASS的话,就很可能出现PermGen space错误,
这种错误常见在web服务器对JSP进行pre compile的时候。如果你的WEB APP下都用了大量的第三方jar, 其大小
超过了jvm默认的大小(4M)那么就会产生此错误信息了。
解决方法: 手动设置MaxPermSize大小
修改TOMCAT_HOME/bin/catalina.sh
在“echo "Using CATALINA_BASE: $CATALINA_BASE"”上面加入以下行:
JAVA_OPTS="-server -XX:PermSize=64M -XX:MaxPermSize=128m
建议:将相同的第三方jar文件移置到tomcat/shared/lib目录下,这样可以达到减少jar 文档重复占用内存的目的。
二、java.lang.OutOfMemoryError: Java heap space
Heap size 设置
JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置Heap size的值,
其初始空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1/4。可以利用JVM提供的-Xmn -Xms -Xmx等选项可
进行设置。Heap size 的大小是Young Generation 和Tenured Generaion 之和。
提示:在JVM中如果98%的时间是用于GC且可用的Heap size 不足2%的时候将抛出此异常信息。
提示:Heap Size 最大不要超过可用物理内存的80%,一般的要将-Xms和-Xmx选项设置为相同,而-Xmn为1/4的-Xmx值。
解决方法:手动设置Heap size
修改TOMCAT_HOME/bin/catalina.sh
在“echo "Using CATALINA_BASE: $CATALINA_BASE"”上面加入以下行:
JAVA_OPTS="-server -Xms800m -Xmx800m -XX:MaxNewSize=256m"
三、实例,以下给出1G内存环境下java jvm 的参数设置参考:
JAVA_OPTS="-server -Xms800m -Xmx800m -XX:PermSize=64M -XX:MaxNewSize=256m -XX:MaxPermSize=128m -Djava.awt.headless=true "
三、相关资料
http://www.tot.name/show/3/7/20061112220131.htm
http://www.tot.name/show/3/7/20061112220054.htm
http://www.tot.name/show/3/7/20061112220201.htm
题外话:经常看到网友抱怨tomcat的性能不如...,不稳定等,其实根据笔者几年的经验,从"互联星空“到现在的房产门户网,我们
均使用tomcat作为WEB服务器,每天访问量百万多,tomcat仍然运行良好。建议大家有问题多从自己程序入手,多看看java的DOC文档
并详细了解JVM的知识。这样开发的程序才会健壮。
JVM 性能调整的一些基本概念
http://www.wujianrong.com/archives/2007/02/jvm_1.html#more
apache+Tomcat负载平衡设置详解
http://www.wujianrong.com/archives/2006/11/apachetomcat.html
java - the Java application launcher
http://java.sun.com/j2se/1.3/docs/tooldocs/linux/java.html
JVM调优
http://www.wujianrong.com/archives/2006/11/jvm.html -
JMeter 中的如何区分 Server Time 和 Network Time
2009-02-05 17:35:17
在 LR 中是有一个“网页细分图”的,通过这个图,你可以比较容易的区分哪些请求的响应时间最长,如果响应时间过程,是消耗在server处理的时候,还是消耗在网络传输过程中——也就是所谓的 Server time 和 Network time。
JMeter\" href="http://jakarta.apache.org/jmeter/" target=_blank>JMeter 并没有提供这么详细的区分——至少目前尚未发现,但是在 JMeter 的执行结果中也有一个字段可以利用一下。如果想看到这一项,首先要设置将 JMeter 运行结果保存到 XML 格式。
在 JMeter.properties 中找到
JMeter.save.saveservice.output_format=csv 改为
JMeter.save.saveservice.output_format=xml
重新启动 JMeter ,执行一个脚本并保存测试结果。
使用任何一个文本编辑工具打开 .jtl 文件,内容如下:
1 <?xml version="1.0" encoding="UTF-8"?>
2 <testResults version="1.2">
3 <httpSample t="2969" lt="1906" ts="1159349557390" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-1" dt="text" ng="5" na="5"/>
4 <httpSample t="2797" lt="1719" ts="1159349557609" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-2" dt="text" ng="5" na="5"/>
5 <httpSample t="2625" lt="1594" ts="1159349558015" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-4" dt="text" ng="5" na="5"/>
6 <httpSample t="2843" lt="1812" ts="1159349557812" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-3" dt="text" ng="5" na="5"/>
7 <httpSample t="2687" lt="1110" ts="1159349558218" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-5" dt="text" ng="5" na="5"/>
8 <httpSample t="844" lt="391" ts="1159349560374" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-1" dt="text" ng="5" na="5"/>
9 <httpSample t="843" lt="437" ts="1159349560406" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-2" dt="text" ng="4" na="4"/>
10 <httpSample t="781" lt="422" ts="1159349560640" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-4" dt="text" ng="3" na="3"/>
11 <httpSample t="782" lt="391" ts="1159349560905" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-5" dt="text" ng="2" na="2"/>
12 <httpSample t="1188" lt="485" ts="1159349560655" s="true" lb="http://jackei.cnblogs.com/" rc="200" rm="OK" tn="Thread Group 1-3" dt="text" ng="1" na="1"/>
13
14 </testResults>
15
找到 lt 这一项。
结合 JMeter 的几篇文章和 email,解释一下 lt 的意思。
lt = latency time (ms)
在 JMeter 中执行一个脚本时,大概的过程如下:Start timer
Send Request
Wait for data
Initial (first) response packet occurs - this is latency
more data
...
end of response
Stop timer - this is the response time
而上面的 XML 文件中,t 这一项表示的是 elapsed time。也就是一个请求从发出到收到完整的响应的时间。
这里可以看到 lt 是接收到响应的第一个包的时间。
那么 lt 就相当于 LR 中的 Server time,而 t-lt 就相当于 LR 中的 Netwrok time。 -
MySQL数据库中Show命令的用法
2009-02-02 16:15:10
MySQL中有很多的基本命令,show命令也是其中之一,在很多使用者中对show命令的使用还容易产生混淆,
本文主要介绍了show命令的主要用法。
a. show tables或show tables from database_name; -- 显示当前数据库中所有表的名称。
b. show databases; -- 显示mysql中所有数据库的名称。
c. show columns from table_name from database_name; 或show columns from database_name.table_name; -- 显示表中列名称。
d. show grants for user_name; -- 显示一个用户的权限,显示结果类似于grant 命令。
e. show index from table_name; -- 显示表的索引。
f. show status; -- 显示一些系统特定资源的信息,例如,正在运行的线程数量。
g. show variables; -- 显示系统变量的名称和值。
h. show processlist; -- 显示系统中正在运行的所有进程,也就是当前正在执行的查询。大多数用户可以查看他们自己的进程,但是如果他们拥有process权限,就可以查看所有人的进程,包括密码。
i. show table status; -- 显示当前使用或者指定的database中的每个表的信息。信息包括表类型和表的最新更新时间。
j. show privileges; -- 显示服务器所支持的不同权限。
k. show create database database_name; -- 显示create database 语句是否能够创建指定的数据库。
l. show create table table_name; -- 显示create database 语句是否能够创建指定的数据库。
m. show engies; -- 显示安装以后可用的存储引擎和默认引擎。
n. show innodb status; -- 显示innoDB存储引擎的状态。
o. show logs; -- 显示BDB存储引擎的日志。
p. show warnings; -- 显示最后一个执行的语句所产生的错误、警告和通知。
q. show errors; -- 只显示最后一个执行语句所产生的错误。
r. show [storage] engines; --显示安装后的可用存储引擎和默认引擎。
-
理解 JMeter 聚合报告(Aggregate Report)
2009-02-02 11:57:45
版权声明:本文可以被转载,但是在未经本人许可前,不得用于任何商业用途或其他以盈利为目的的用途。本人保留对本文的一切权利。如需转载,请在转载是保留此版权声明,并保证本文的完整性。也请转贴者理解创作的辛劳,尊重作者的劳动成果。
作者:陈雷 (Jackei)
邮箱:jackeichan@gmail.com
Blog:http://jackei.cnblogs.com
Aggregate Report 是 JMeter 常用的一个 Listener,中文被翻译为“聚合报告”。今天再次有同行问到这个报告中的各项数据表示什么意思,顺便在这里公布一下,以备大家查阅。
如果大家都是做Web应用的性能测试,例如只有一个登录的请求,那么在Aggregate Report中,会显示一行数据,共有10个字段,含义分别如下。
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50%用户的响应时间
90% Line:90%用户的响应时间
Note:关于 50%和 90%并发用户数的含义,请参考下文
http://www.cnblogs.com/jackei/archive/2006/11/11/557972.html
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
另外,如果大家在使用 JMeter 的过程中遇到问题,建议先参考下面这篇文章
http://www.cnblogs.com/jackei/archive/2006/11/06/551921.html
其他有关 JMeter 和 性能测试的文章请参见下面的链接
http://www.cnblogs.com/jackei/archive/2006/11/13/558720.html -
Windows Media Load Simulator使用步骤
2009-01-21 16:36:12
1 安装Windows Media Load Simulator
2配置windows media service
3C:\wmpub\WMRoot下放置WMLoad.asf
-
教你用专业软件测试媒体服务器--设定Windows Media Load Simulator
2009-01-21 16:17:02
设定Windows Media Load Simulator
设定Windows Media Load Simulator,要指定将要测试的服务器,要作为流的内容的来源和用户的配置。这一节对于如何配置Windows Media Load Simulator提供了一个总览;要了解全部的细节,请浏览Windows Media Load Simulator帮助。
1.开启Windows Media server下载测试
运行Windows Media Load Simulator,你必须复制一个名为WMLoad.asf的文件到服务器的Windows系统的%systemdrive%\Wmpub\Wmroot根目录下。这个文件提供了一个机制来帮助保护你的计算机不受未被授权的下载模拟的测试。在你完成运行下载模拟器测试后,简单的移动这个文件来防止恶意用户运行下载测试在你的服务器上。假如没有这个机制的保护,举个例子,一个因特网上的用户,向你的服务器模仿成千上万的用户连接,那个可以防止其他的连接到这个流和潜在的过载到你的系统。如果你想用Windows Media Load Simulator作为在线监控,那么将这个文件放在根目录下并且要通过发布点安全来限制对它的访问。
要创建这个文件,用任意一个小文件只要扩展名是.asf的文件然后重命名为WMLoad.asf。同样的,要确保允许新的单一投放(unicast)连接在Windows媒体设备中对于默认的发布点是可用的。
2.指定一个要进行测试的Windows媒体服务器
无论是Configuration Wizard或是Load Test Configuration(Advanced)对话框,选择你想测试的Windows媒体服务器或服务器群的静态IP地址或fully qualified domain name(FQDN)类型。
3.指定源内容
添加源内容到Stream目录。这个列表包括了文件或者是动态流,你可以指定Windows Media Load Simulator是连续的或是随机的播放这些条目。
你也必须要指定模拟器是否要使用微软媒体服务器(MMS)草案来流向,实时流草案(RTSP),超文本传输草案(HTTP),或者联合的草案。如果你只想通过应用Transport Control协议(TCP)来测试流动,指定MMST,RTSPT,或者两者。如果你应用MMS或RTSP作为协议,模仿用户可以使用协议rollover。这意味着如果一个用户不能通过MMS连接,还可以“滚动越过”去使用RTSPU来代替。另外,如果一个用户不能用RTSP来连接,也可以滚动越过去使用RTSPU。
4. 创建用户信息
一个用户的情况决定了一个模拟的用户回放行为。对于每种情况的用户键入一系列用户来创造一个全面的用户情况。你所键入的全部用户的数量不能超过在计算机上运行着的Windows Media Load Simulator的容量。全部的从所有模拟计算机连接到你的服务器的用户数需要和所有的你所估计的典型峰值客户下载的并发连接数目相等。下面的表格描述了每种信息:
播放。模拟用户播放,停止或重启流
长时播放。模拟用户连续播放一个流。如果内容是一个文件,用户就在文件结束时重复回放
打开/关闭。模拟用户打开一个流但是播放前关闭它
寻找。模拟用户向前或向后寻找一个流,或者如果这个内容是一个服务器面的播放列表,则跳过不同的播放列表条目。如果这个内容是一个活动的流或者是一个没有在索引里的文件,则客户无须寻找就可以播放它
选择。模拟用户打开一个流,然后或者是用随机选择的一个比特速率(如果内容是多比特率内容)或者是用编码比特率(如果内容是单一比特率内容)来播放它
随机。模拟用户可以浏览内容,在随意的时间长度里播放内容在内容中寻找,停止回放,暂停回放或有时关闭。
如果你已经把所有的估计用户下载定为100,并且希望客户一直按照一种方式播放,你就可以,比如说,键入下面这些客户情况设置:
Client Type
Setting
Play
5
Long play
90
Open/Close
5
如果你的典型内容是短新闻或者歌曲片断并且所有的并发用户下载预期为800,你就可以键入下面的客户情况设置:
Client Type
Setting
Play
60
Long play
40
Seek
60
Open/close
40
5. 添加验证
用户可以被设置验证来获得对服务器上被Windows Media publishing point security保护的内容的访问权。要测试验证,你可以在每一个文件或publishing points上设置访问权,然后模拟用户试图访问内容。你必须要把Windows Media server和在计算机上运行的用作验证测试的Windows Media Load Simulator都做设置。如果你想可以在服务器上运行WMS Digest验证,你需要设置Windows Media Load Simulator使用适当的用户名和密码。要了解更多的关于publishing point security的信息,请参见Windows Media Services帮助。
6. 键入测试的持续时间和可用的记录
你可以在小时,分钟和秒中指定一个时间间隔,或者你可以指定Windows Media Load Simulator在一定数量的错误后有一个停顿。你也可以无限期的运行这个测试。
你可以装置Windows Media Load Simulator来创建两个日志,一个Windows Media Load Simulator日志文件和一个服务器性能表现日志文件,并且指定这两个文件的位置。在大多数情况里,你需要创建全部的日志。通过使用这两个日志和Windows Media Server日志来相互参照信息,你可以很好的理解在一个测试运行时系统是如何工作的。记下为了用户计算机从Windows Media server收集数据,被用户计算机记录下的用户必须在这个服务器上有管理权和许可。
小结:
本文到这里暂时告一段落,在下次的文章中我们将针对运行测试、设置在线镜像及一些常见问题进行整理,欢迎对Windows媒体服务器测试感兴趣的用户继续关注服务器频道近期的文章。
-
TOMCAT数据库连接池:未释放connection资源造成的错误[转]
2009-01-15 11:13:26
来源: ChinaUnix博客 日期: 2008.04.27 23:26 (共有0条评论) 我要评论 ----ruixj
问题描述:
有一个系统的功能很简单,就是几个表单的提交和几个页面的显示。但是这个网站的访问量很大,一周时间累计至少10万次访问,高峰时间可能每秒的 点击数会达到500次。OS为Redhat Linux 9 , Database为Oracle 8i,JSP容器为Tomcat 4,使用Struts框架。当使用工具进行压力测试时,如果连接数到100个,2、3分钟后几乎所有访问都出现404错误,无法访问此页面。这就是我接到 问题时候的状况。
问题解决:
首先我们需要知道产生瓶颈的地方,分析后可能影响效率的地方有如下几处:
- Struts产生的瓶颈
- 数据库的设置,最大连接数问题
- Tomcat服务器的配置问题
- Linux OS的配置问题
- 服务器的机器硬件配置问题
- 服务器的带宽不够
测试是否是Struts瓶颈问题很容易,我们用压力测试工具中设置只访问index.jsp这个页面,此页面和Struts没有一点关系,在每 秒点击在100次左右的时候,网站访问速度只是稍微有些慢,但是到200个访问数后,错误404再次发生。说明不是Struts产生的瓶颈,或者说 Struts的瓶颈不是主要影响我们效率的问题所在。
然后我们写了一个很简单的JSP测试页面,使用和在ActionServlet中调用数据库相同的方法进行一个Select操作,并且把那个结果显示到JSP页面中,针对这个test的页面,进行100次同时连接,错误出现了。此时还是不能判断什么是瓶颈所在。
然后登录上服务器,察看Tomcat的配置文件server.xml,发现允许最大的并发连接数设置项maxProcessors= "75",说明Tomcat允许的同时连接最大为75,这个肯定是一个tomcat的配置失误。把它改为maxProcessors="1000",重新 启动服务器,进行测试。对index.jsp文件测试的时候,同时连接500人的时候没有出现问题,但是测试test页面的数据库查询时,仍然是到100 个左右的连接数的时候出现404错误。这两个测试说明了tomcat服务器配置的问题基本解决了,问题已经不在tomcat的设置上了,很有可能是在数据 库中。
检查Oracle的设置,把最大连接数改成1000,再次测试test页面,仍然是错误。
在Linux下使用[root@NetCom51 bin]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
file size (blocks, -f) unlimited
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
stack size (kbytes, -s) 8192
cpu time (seconds, -t)
发现允许使用的open files都达到了要求了。
服务器的硬件问题和带宽不是我们能解决的,暂时不管。现在把我们能做的事情定位在优化程序和优化服务器上。
Tomcat本身不能直接在计算机上运行,需要依赖于硬件基础之上的操作系统和一个java虚拟机。Sun公司和其它一些公司一直 在为提高性能而对java虚拟机做一些升级改进,一些报告显示JDK1.4在性能上比JDK1.3提高了将近10%到20%。我们使用java -version命令查看JRE的版本,发现已经是1.4了。
Tomcat默认可以使用的内存为128MB,在较大型的应用项目中,这点内存是不够的,需要调大。在linux下,修改{tomcat_home}/bin/catalina.sh文件,在
echo "Using CATALINA_BASE: $CATALINA_BASE"
echo "Using CATALINA_HOME: $CATALINA_HOME"
echo "Using CATALINA_TMPDIR: $CATALINA_TMPDIR"
echo "Using JAVA_HOME: $JAVA_HOME"
后加上
JAVA_OPTS='-Xms256m -Xmx512m'
JAVA_OPTS='-Xms【初始化内存大小】 -Xmx【可以使用的最大内存】'
这两个值的大小一般根据需要进行设置。初始化堆的大小执行了虚拟机在启动时向系统申请的内存的大小。一般而言,这个参数不重要。但是有的应用 程序在大负载的情况下会急剧地占用更多的内存,此时这个参数就是显得非常重要,如果虚拟机启动时设置使用的内存比较小而在这种情况下有许多对象进行初始 化,虚拟机就必须重复地增加内存来满足使用。由于这种原因,我们一般把-Xms和-Xmx设为一样大,而堆的最大值受限于系统使用的物理内存。一般使用数 据量较大的应用程序会使用持久对象,内存使用有可能迅速地增长。当应用程序需要的内存超出堆的最大值时虚拟机就会提示内存溢出,并且导致应用服务崩溃。因 此一般建议堆的最大值设置为可用内存的最大值的80%。
重新启动服务器进行测试,发现服务器启动速度变慢,但是启动后服务器效率确实有提高,但是仍然未能达到我们要求的每秒500访问数的要求。
重新检查程序,试着使用tomcat的数据库连接池,修改tomcat配置文件server.xml,在context标签中加上
factory
org.apache.commons.dbcp.BasicDataSourceFactory
driverClassName
oracle.jdbc.driver.OracleDriver
url
jdbc:oracle:thin:@10.11.6.1:1521:dbname
username
yourname
password
yourpasswd
maxActive
1000
maxIdle
20
maxWait
-1
maxActive 是最大激活连接数,这里取值为1000,表示同时最多有1000个数据库连接。maxIdle是最大的空闲连接数,这里取值为20,表示即使没有数据库连 接时依然可以保持20空闲的连接,而不被清除,随时处于待命状态。MaxWait是最大等待秒钟数,这里取值-1,表示无限等待,直到超时为止,也可取值 9000,表示9秒后超时。
修改web.xml文文件,加入
Oracle
Datasource example
jdbc/OracleDB
javax.sql.DataSource
Container
将Oracle的JDBC驱动classes12.jar拷贝到Tomcat安装目录的common/lib下。建立简单的测试页面test2.jsp:
Context initCtx = new InitialContext();
Context envCtx = (Context) initCtx.lookup("java:comp/env");
ds = (DataSource)envCtx.lookup("jdbc/OracleDB");
Connection cn=ds.getConnection();
进行测试,发现问题还没有解决,在同时连接100人的时候再次出错。
最后仔细检查后,发现是未释放connection资源,使用cn.close()方法,可以同时连接500个用户了。
本文来自ChinaUnix博客,如果查看原文请点:http://blog.chinaunix.net/u/10047/showart_602262.html - Struts产生的瓶颈
-
测试浮躁论
2009-01-13 10:14:53
目前来说软件测试人员都有这么些问题吧,这大概已经成为中国目前测试的瓶颈了。人心浮躁大概不是某些职业人特有的,其实是我们这些年轻人的通病了。但身为测试人员,当你在应聘找工作的时候是否发现过自己的不足呢?浮躁的测试人还是占大多数。一、根基不牢
问题:利用等价类划分的方法,对某问题设计测试用例。
分析:98%以上的应聘者只知道按照有效等价类和无效等价类进行划分,殊不知此种分类方法只是等价类划分的一个典型应用而已,等价类划分远非只能划分为有效和无效两类。根据种种划分依据,还可以进一步划分很多其他类别。
问题:根据事件描述,画出对应的因果图。
分析:标准答案中只画了“两条恒等,两条非,一个与,一个或”。如此简单的问题,上百名应聘者中竟然无一人答对,痛心啊。黑盒测试方法就那么几种,既然你已知这个名,怎么就不知道多看几眼。
小结:
上面提到的是软件测试的最基本的方法,作为从业测试实际工作已经有1-2年的应聘人员,未能真正领悟,实属不应该,心浮气躁,忽视了你身边最简单,也是最厉害的技能。根基不牢,怎么可能把测试做深。
二、专业不精
问题:音视频文件都有哪些格式,这些格式之间有什么差别?
分析:此问题是问那些做过多媒体方面测试的,但是我们的应聘者向来都是拿来主义,别人给我什么媒体文件我就用什么做测试,而根本不管不问。“为什么 MIDI文件比WAV文件小那么多?我们如何知道扩展名是.Mpeg的文件是Mpeg1格式的还是Mpeg2格式的?”,面对这些问题,应聘者默默无语,只是无奈的笑笑。不去看别人,想想自己测试涉及的专业,是否把那个行业知识搞清楚了呢?
问题:测试脚本运行不畅如何调试?
分析:此问题是问那些标明自己熟练掌握WinRunner、Robot、QTP等测试工具的应聘人员,但是当真正问到他们关于脚本的具体调试时,有7成以上人员表示他们只是参加测试培训时老师讲过,或者自己在网上看过相关资料,另外有2成以上人员表示他们虽然用过,但是只是简单的录制回放,根本不会自己调试。可能是迫于无奈吧,简历里面什么都不写,可能面试的机会都没有,但是简历如此夸大的来写,终归是浪费自己的面试时间和路费。
小结:
从事测试仅1-2年时间,要想测试也精通,专业也精通确实不易,但是不说精通,至少也该知道个60%才对的起你的测试工作。一两年时光如此荒废,静下心来反思一下,身边还有哪些技能我们应该掌握扎实一点呢。
三、无测试体系概念,忽视理论
问题:请说出软件测试的定义,BUG的定义。
分析:99%的人不能说出这两个测试名词的定义,只是在给我解释测试是为了发现bug之类的片面理解,残留的几个人也说得不够准确。这两个词目前尚不能说业内已经有了成熟统一的定义,但是无论是对是错,身为测试人员已经数年,自己竟然说不出这两个词的概念,多少也说不过去啊。有些人和我说,理论名词概念不重要,我会做测试就是了。想想金庸老先生早就告诉我们,武功仅有招式是不够的,必须配合上什么心法口诀才能行。你只会测试执行的招式,却不懂测试理论的心法,怎么能够修炼成上乘的软件测试呢?
问题:请介绍一下你们的测试流程,流程和过程有什么不同,为什么好的测试需要好的流程?
分析:但凡做过1、2年测试的人都能给我说出他们先做什么后做什么,但是当我继续问“这是否可以叫做过程?流程和过程有什么差别”,应聘者一棒子被打晕,继续追问“为什么好的测试需要好的流程”的时候,早已经找不到东南西北了。每天公司各项制度叫你做什么你就做什么,让你怎么做你就怎么做,完全不管不顾为什么,那么自己岂不成了没头脑的工具。这样你能干的工作别人也能做,自己的优势不就没有了吗。
小结:
目前测试业内流传着学院派和实践派的说法,学院派的理论给人的感觉往往是好听但不实用,而实践派的知识,往往能够立即见效。所以眼下测试培训往往实践派的更受欢迎。继续引用金庸先生的观点,练武分练内气宗,练外剑宗,但是真正的高手是内外兼修。如果我们不想只做普通的测试小弟子的话,就要理论实践并重,方能有所作为。
四、周边知识知之甚少
问题:能给我介绍一下软件工程中的瀑布模型吗?
分析:又是8成应聘者不会回答,都是曾在遥远的学生时代有所耳闻,现今早已忘得一干二净了。软件测试因何而生——软件危机,软件危机导致软件工程的兴起,软件工程中又包含软件测试,就好像鱼儿活在水里,如果没有软件工程这个水,哪里能够养活这软件测试的鱼,如果我们对于身边的软件工程不够了解,怎么可能在里面自由的畅游呢。
问题:用你最熟悉的开发语言实现sum=1+2+3+…+100
分析:保守统计7成以上的应聘者写出来的程序无法执行或者运行结果错误,更少有人能够一气呵成,而且精准。这道编程题难吗?肯定不难,那么为何答错,自己没有真正写过程序,即使写过几行,也早就是如烟往事了。做测试一定需要懂开发吗?这个问题讨论以久,当然不一定,但是如果要做好测试,做深测试,分析问题原因,提出问题解决方案,编写测试脚本或工具,哪一个又能离开软件开发呢?
小结:
我们学习测试也应该有个先后顺序,有步骤。掌握周边知识的紧迫程度可能不如测试知识和行业知识。但是对于我们已经从业1-2年的测试人员来说,学校里面学到的知识不应该丢,之后的发展中,周边知识的学习也应该开始了。周边知识的范畴其实很广,还包括各种其他测试理念的学习,机械工业出版社翻译的那套测试丛书就很不错,观点众多而新颖,博众家之长,集大成,向来都是大家风范。
五、缺乏必要的责任心、细心、耐心、虚心等
问题:请数出下图中三角形的个数(平面图,有几根弧线做干扰)
分析:我总是问自己,这道题真有这么难吗?连中小学生都能数对的十几个三角形,到了我们这二十几岁的年轻人手中,正确率才1%,为什么?其实就是现在我们已经很少有人能够静下心来,耐心细致的去做事情了。很多应聘者告诉我她的优点就是“踏实,坐的住,正适合这繁琐的测试工作”。我需要的不是坐在那里不做事或者做错事的人,而是需要能够按时保质量完成测试工作的测试人员。
问题:你离职的原因?
分析:这是面试中最常见的问题了。应聘者往往也是充分准备,理由多种多样,但是看看应聘者的工作记录统计,70%应聘者平均跳槽频率是1年/次(实习情况除外),不会都那么凑巧吧,赶上什么公司倒闭,每隔一年就会想一次自己学不到东西,需要去外面看看。而在我看来,真正的原因更多的应该是希望通过跳槽提高工资,或者因为自身水平不足被公司炒鱿鱼吧。
小结:
我并不认为所有的人都适合做测试。非技术素质方面,这点或者那点不足够优秀也很正常,心浮气躁也可以理解。但是作为用人单位,理解归理解,却也不会用不胜任岗位,或性价比不高的人员。那么对于此类应聘者,我的忠告就是,要么你另谋高就,要么你就放低姿态,培养好你必备的素质后再谈。
六、缺乏诚信
这一点本应该被归在上一条素质中,但是这点的重要性我认为远超过了上一条所列各项,因此单独提出。相关表现主要体现在:1、虚报自己历史工薪;2、笔试题目作弊;3、编造离职原因;4、虚报学历,工作经验;5、夸大自己工作技能等。对于严重缺乏诚信的,一旦发现,其他表现再好,也无济于事了。
另外其实还有个大家都爱犯的通病,不知道如何问问题,言之无物,有的时候自己都不知道想问什么,但却心里总觉得自己是好学的是在请教,殊不知你并没有真正的在做事情,你并没有搞清楚事物的根本。
想学好一个东西,首要的就是要学好如何问问题。
最近在繁忙而复杂的找工作过程中,遇到问题无数,今日阅读若干文章感触颇深。自己的成败荣辱仿佛一瞬间集中在眼前。自己审视自己,真的,我还差的很多。
-
如何使用Nikto漏洞扫描工具检测网站安全
2009-01-12 09:19:52
http://netsecurity.51cto.com/art/200712/62159.htm【51CTO.com 独家特稿】随着信息技术的发展,网络应用越来越广泛,很多企业单位都依靠网站来运营,正因为业务的不断提升和应用,致使网站的安全性显得越来越重要。另一方面,网络上的黑客也越来越多,而且在利益驱使下,很多黑客对网站发起攻击,并以此谋利。作为网站的管理人员,应该在黑客入侵之前发现网站的安全问题,使网站能更好的发挥作用。那么究竟如何检查网站的安全隐患和漏洞呢?下面我们介绍一款开放源代码的Web漏洞扫描软件,网站管理员可以用它对WEB站点进行安全审计,尽早发现网站中存在的安全漏洞。Nikto是一款开放源代码的、功能强大的WEB扫描评估软件,能对web服务器多种安全项目进行测试的扫描软件,能在230多种服务器上扫描出 2600多种有潜在危险的文件、CGI及其他问题,它可以扫描指定主机的WEB类型、主机名、特定目录、COOKIE、特定CGI漏洞、返回主机允许的 http模式等等。它也使用LibWhiske库,但通常比Whisker更新的更为频繁。Nikto是网管安全人员必备的WEB审计工具之一。Nikto最新版本为2.0版,官方下载网站:http://www.cirt.net/Nikto是基于PERL开发的程序,所以需要PERL环境。Nikto支持Windows(使用ActiveState Perl环境)、Mac OSX、多种Linux 或Unix系统。Nikto使用SSL需要Net::SSLeay PERL模式,则必须在Unix平台上安装OpenSSL。具体的可以参考nikto的帮助文档。从官方网站上下载nikto-current.tar.gz文件,在Linux系统解压操作:tar -xvf nikto-current.tar.gz
gzip -d nikto-current.tar解压后的结果如下所示:
Config.txt、docs、kbase、nikto.pl、plugins、 templatesNikto的使用说明:Nikto扫描需要主机目标IP、主机端口。默认扫描的是80端口。扫描主机目标IP地址可以使用选项-h(host)。下面将扫描IP为192.168.0.1的TCP 80端口,如下所示:perl nkito.pl –h 192.168.0.1也可以自定义扫描的端口,可以使用选项-p(port),下面将扫描IP为192.168.0.1的TCP 443端口,如下所示:perl nikto.pl –h 192.168.0.1 –p 443Nikto也可以同时扫描多个端口,使用选项-p(port),可以扫描一段范围(比如:80-90),也可以扫描多个端口(比如:80,88,90)。下面扫描主机的80/88/443端口,如下所示:Perl nikto.pl –h 192.168.0.1 –p 80,88,443如果运行Nikto的主机是通过HTTP proxy来访问互联网的,也可以使用代理来扫描,使用选项-u(useproxy)。下面将通过HTTP proxy来扫描,如下所示:Perl nikto.ph –h 192.168.0.1 –p 80 –uNikto的更新:Nikto的升级可以通过-update的命令来更新插件和数据库,如下所示:Perl nikto.ph –update也可以通过从网站下载来更新插件和数据库:http://updates.cirt.net/Nikto的选项说明:-Cgidirs
扫描CGI目录。-config
使用指定的config文件来替代安装在本地的config.txt文件-dbcheck
选择语法错误的扫描数据库。-evasion
使用LibWhisker中对IDS的躲避技术,可使用以下几种类型:
1.随机URL编码(非UTF-8方式)
2.自选择路径(/./)
3.虚假的请求结束
4.长的URL请求
5.参数隐藏
6.使用TAB作为命令的分隔符
7.大小写敏感
8.使用Windows路径分隔符\替换/
9.会话重组-findonly
仅用来发现HTTP和HTTPS端口,而不执行检测规则-Format
指定检测报告输出文件的格式,默认是txt文件格式(csv/txt/htm)-host
目标主机,主机名、IP地址、主机列表文件。-id
ID和密码对于授权的HTTP认证。格式:id:password-mutate
变化猜测技术
1.使用所有的root目录测试所有文件
2.猜测密码文件名字
3.列举Apache的用户名字(/~user)
4.列举cgiwrap的用户名字(/cgi-bin/cgiwrap/~user)-nolookup
不执行主机名查找-output
报告输出指定地点-port
扫描端口指定,默认为80端口。-Pause
每次操作之间的延迟时间- Display
控制Nikto输出的显示
1.直接显示信息
2.显示的cookies信息
3.显示所有200/OK的反应
4.显示认证请求的URLs
5.Debug输出-ssl
强制在端口上使用SSL模式-Single
执行单个对目标服务的请求操作。-timeout
每个请求的超时时间,默认为10秒-Tuning
Tuning 选项控制Nikto使用不同的方式来扫描目标。
0.文件上传
1.日志文件
2.默认的文件
3.信息泄漏
4.注射(XSS/scrīpt/HTML)
5.远程文件检索(Web 目录中)
6.拒绝服务
7.远程文件检索(服务器)
8.代码执行-远程shell
9.SQL注入
a.认证绕过
b.软件关联
g.属性(不要依懒banner的信息)
x.反向连接选项-useproxy
使用指定代理扫描-update
更新插件和数据库例子:使用Nikto扫描目标主机10.0.0.12的phpwind论坛网站。Perl nikto.pl –h 10.0.0.12 –o test.txt查看test.txt文件,如下图所示:
图1 通过上面的扫描结果,我们可以发现这个Phpwind论坛网站,是在windows操作系统上,使用Apache/2.2.4版本,Php/5.2.0版本,以及系统默认的配置文件和路径等。综上所述,Nikto工具可以帮助我们对Web的安全进行审计,及时发现网站存在的安全漏洞,对网站的安全做进一步的扫描评估。 -
oracle内存调优参数详解
2009-01-06 10:12:18
来源:
Oracle内存参数调优技术详解
前言
近来公司技术,研发都在问我关于内存参数如何设置可以优化oracle的性能,所以抽时间整理了这篇文档,以做参考.
目的
希望通过整理此文档,使大家对oracle内存结构有一个全面的了解,并在实际的工作中灵活应用,使oracle的内存性能达到最优配置,提升应用程序反应速度,并进行合理的内存使用.
内容
实例结构
oracle实例=内存结构+进程结构
oracle实例启动的过程,其实就是oracle内存参数设置的值加载到内存中,并启动相应的后台进程进行相关的服务过程。
进程结构
oracle进程=服务器进程+用户进程
几个重要的后台进程:
DBWR:数据写入进程.
LGWR:日志写入进程.
ARCH:归档进程.
CKPT:检查点进程(日志切换;上一个检查点之后,又超过了指定的时间;预定义的日志块写入磁盘;例程关闭,DBA强制产生,表空间offline)
LCKn(0-9):封锁进程.
Dnnn:调度进程.
内存结构(我们重点讲解的)
内存结构=SGA(系统全局区)+PGA(程序全局区)
SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,它是在Oracle服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写
我们重点就是设置SGA,理论上SGA可占OS系统物理内存的1/2——1/3
原则:SGA+PGA+OS使用内存<总物理RAM
SGA=((db_block_buffers*blocksize)+(shared_pool_size+large_pool_size+java_pool_size+log_buffers)+1MB
1、SGA系统全局区.(包括以下五个区)
A、数据缓冲区:(db_block_buffers)存储由磁盘数据文件读入的数据。
大小: db_block_buffers*db_block_size
Oracle9i设置数据缓冲区为:Db_cache_size
原则:SGA中主要设置对象,一般为可用内存40%。
B、共享池:(shared_pool_size):数据字典,sql缓冲,pl/sql语法分析.加大可提速度。
原则:SGA中主要设置对象,一般为可用内存10%
C、日志缓冲区:(log_buffer)存储数据库的修改信息.
原则:128K ---- 1M 之间,不应该太大
D 、JAVA池(Java_pool_size)主要用于JAVA语言的开发.
原则:若不使用java,原则上不能小于20M,给30M通常就够了
E、 大池(Large_pool_size) 如果不设置MTS,主要用于数据库备份恢复管理器RMAN。
原则:若不使用MTS,5---- 10M 之间,不应该太大
SGA=. db_block_buffers*db_block_size+ shared_pool_size+ log_buffer+Java_pool+size+large_pool_size
原则: 达到可用内存的55-58%就可以了.
2、PGA程序全局区
PGA:包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA 正相反PGA 是只被一个进程使用的区域,PGA 在创建进程时分配在终止进程时回收.
A、Sort_area_size 用于排序所占内存
B、Hash_area_size 用于散列联接,位图索引
这两个参数在非MTS下都是属于PGA ,不属于SGA,是为每个session单独分配的,在我们的服务器上除了OS + SGA,一定要考虑这两部分
原则:OS 使用内存+SGA+并发执行进程数*(sort_area_size+hash_ara_size+2M) < 0.7*总内存
实例配置
一:物理内存多大
二:操作系统估计需要使用多少内存
三:数据库是使用文件系统还是裸设备
四:有多少并发连接
五:应用是OLTP 类型还是OLAP 类型
基本掌握的原则是, db_block_buffer 通常可以尽可能的大,shared_pool_size 要适度,log_buffer 通常大到几百K到1M就差不多了
A、如果512M RAM 单个CPU db_block_size 是8192 bytes
SGA=0.55*512M=280M左右
建议 shared_pool_size = 50M, db_block_buffer* db_block_size = 200M
具体: shared_pool_size =52428800 #50M
db_block_buffer=25600 #200M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size=7864320 #7.5M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
B、如果1G RAM 单个CPU db_block_size 是8192 bytes
SGA=0.55*1024M=563M左右
建议 shared_pool_size = 100M , db_block_buffer* db_block_size = 400M
具体: shared_pool_size=104857600 #100M
db_block_buffer=51200 #400M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size=15728640 #15M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
C、如果2G 单个CPU db_block_size 是8192 bytes
SGA=0.55*2048M=1126.4M左右
建议 shared_pool_size = 200M , db_block_buffer *db_block_size = 800M
具体: shared_pool_size=209715200 #200M
db_block_buffer=103192 #800M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size= 31457280 #30M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
假定64 bit ORACLE
内存4G
shared_pool_size = 200M , data buffer = 2.5G
内存8G
shared_pool_size = 300M , data buffer = 5G
内存 12G
shared_pool_size = 300M-----800M , data buffer = 8G
参数更改方式
oracle8i:
主要都是通过修改oracle启动参数文件进行相关的配置
参数文件位置:
d:\oracle\admin\DB_Name\pfile\init.ora
按以上修改以上参数值即可。
Oracle9i:
两种方式:第一种是修改oracle启动参数文件后,通过此参数文件再创建服务器参数文件
第二种是直接运行oracle修改命令进行修改。
SQL>alter system set db_cache_size=200M scope=spfile;
SQL>alter system set shared_pool_size=50M scope=spfile; -
Tomcat相关的内存设置和优化
2009-01-06 10:10:54
1、JDK内存优化:
Tomcat默认可以使用的内存为128MB,Windows下,在文件{tomcat_home}/bin/catalina.bat,Unix下,在文件{tomcat_home}/bin/catalina.sh的前面,增加如下设置:
JAVA_OPTS='-Xms[初始化内存大小] -Xmx[可以使用的最大内存]
参数
描述
-Xms
JVM初始化堆的大小
-Xmx
JVM堆的最大值,一般说来,你应该使用物理内存的80% 作为堆大小。
有三种方法:
1)就需要在环境变量中加上TOMCAT_OPTS, CATALINA_OPTS两个属性, 如 SET CATALINA_OPTS= -Xms64m -Xmx512m; ms是最小的,mx是最大,64m, 512m分别是指内存的容量.
2)修改Catalina.bat文件 在166行“rem Execute Java with the applicable properties ”以下每行 %_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR %" %MAINCLASS% %CMD_LINE_ARGS% %ACTION% 中的%CATALINA_OPTS% 替换成 -Xms64m -Xmx512m
3)编辑%CATALINA_HOME%\bin下面的catalina.bat文件,在最上面第一行前面写上 set CATALINA_OPTS=-Xms512m -Xmx1024m set JAVA_OPTS=-Xms512m -Xmx1024m
其中-Xms表示jvm最小内存数,-Xmx表示最大内存数 比如我这里都设置成最小512,最大1024 当然,这个最小最大并不是只能使用1024的意思,其实这个设置是对系统来设置的,因为这个jvm占用内存数实际上是针对虚拟内存来说,这个设置表示,无 论系统怎么占用虚拟内存,都要保证最小512M的虚拟内存共给jvm使用,当然,就算我jvm占用再大,也不会超过1024,来威胁系统的内存使用
2、连接器优化:
在tomcat配置文件server.xml中的配置中,和连接数相关的参数有:
maxThreads:
Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可创建的最大的线程数。默认值200。
acceptCount:
指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理。默认值10。
minSpareThreads:
Tomcat初始化时创建的线程数。默认值4。
maxSpareThreads:
一旦创建的线程超过这个值,Tomcat就会关闭不再需要的socket线程。默认值50。
enableLookups:
是否反查域名,默认值为true。为了提高处理能力,应设置为false
connnectionTimeout:
网络连接超时,默认值60000,单位:毫秒。设置为0表示永不超时,这样设置有隐患的。通常可设置为30000毫秒。
maxKeepAliveRequests:
保持请求数量,默认值100。
bufferSize:
输入流缓冲大小,默认值2048 bytes。
compression:
压缩传输,取值on/off/force,默认值off。
其中和最大连接数相关的参数为maxThreads和acceptCount。如果要加大并发连接数,应同时加大这两个参数。web server允许的最大连接数还受制于操作系统的内核参数设置,通常Windows是2000个左右,Linux是1000个左右。
3、tomcat中如何禁止和允许列目录下的文件
在{tomcat_home}/conf/web.xml中,把listings参数设置成false即可,如下:
xml 代码
<servlet>
...
<init-param>
<param-name>listingsparam-name>
<param-value>falseparam-value>
<init-param>
...
<servlet>
<servlet>
...
<init-param>
<param-name>listingsparam-name>
<param-value>falseparam-value>
<init-param>
...
<servlet> 4、tomcat中如何禁止和允许主机或IP地址访问
view plaincopy to clipboardprint?
<Host name="localhost" ...>
...
<Valve className="org.apache.catalina.valves.RemoteHostValve"
allow="*.mycompany.com,www.yourcompany.com"/>
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
deny="192.168.1.*"/>
...
<Host>
<Host name="localhost" ...>
...
<Valve className="org.apache.catalina.valves.RemoteHostValve"
allow="*.mycompany.com,www.yourcompany.com"/>
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
deny="192.168.1.*"/>
...
<Host>
JAVA_OPTS='-server -Xms512m -Xmx768m -XX:NewSize=128m -XX:MaxNewSize=192m -XX:SurvivorRatio=8'
一般说来,我们启动Tomcat是在Windows服务里,所以修改内存和堆栈等参数应该在注册表里,在bat文件里修改不会起作用。
-
网管经验谈:远程桌面中断巧解决
2009-01-05 11:51:16
远程桌面的使用非常简单,通过远程桌面连接程序访问目标计算机,输入用户名和密码后登录成功后就和使用自己的计算机一模一样了。不过最近笔者在对一台XP系统计算机进行管理时,却出现了无法正常连接的问题。最后通过查询资料解决了此问题,在此写出来给各位读者,希望大家在遇到同样问题时能够快速解决。一、远程桌面连接故障现象
笔者刚刚安装完一台员工计算机,该计算机操作系统是windows XP,领导决定以后这台计算机就担任公司数据存放工作,所以日后需要对其进行远程管理操作。所以笔者也像往常一样,开启了该系统的远程桌面连接功能。谁知道在网络中的其他计算机通过远程桌面连接程序访问时却出现了“中断远程桌面连接,远程计算机已结束连接”的提示,也就是说能够连接上但是马上中断,根本没有给予输入管理员用户名和密码的时间。
二、解决问题
既然可以连接到该计算机,只是马上中断。笔者怀疑是否在远程桌面登录时是默认使用当前帐户的,所以将自己的计算机帐户和密码设置为和远程那台计算机一致,谁知道问题依旧。看来故障应该是该计算机远程桌面服务本身的设置问题。笔者在网上寻求帮助,终于发现了问题的所在。
第一步:通过“开始->运行->输入regedit”,打开注册表编辑器。
第二步:打开注册表后找到[HKEY_LOCAL_MACHINESYSTEMControlSet001EnumRootRDPDR键值,在左侧的RDPDR上点鼠标右键,选择“权限”。
第三步:在弹出的对RDPDR设置权限窗口后,将everyone组添加到完全控制权限,如果你只想让某个特定的用户远程管理该计算机的话,将该帐户添加到权限设置窗口中即可,记住一定要给予“完全控制”权限。
第四步:接下来将如下内容复制到一个记事本txt文件中,并保存成后缀为.reg的文件。例如笔者保存成111.reg。
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESYSTEMControlSet001EnumRootRDPDR000]
"ClassGUID"="{4D36E97D-E325-11CE-BFC1-08002BE10318}"
"Class"="System"
"HardwareID"=hex(7):52,00,4f,00,4f,00,54,00,5c,00,52,00,44,00,50,00,44,00,52,
00,00,00,00,00
"Driver"="{4D36E97D-E325-11CE-BFC1-08002BE10318}030"
"Mfg"="(标准系统设备)"
"Service"="rdpdr"
"DeviceDesc"="终端服务器设备重定向器"
"ConfigFlags"=dword:00000000
"Capabilities"=dword:00000000
第五步:接下来我们双击运行保存后的注册表文件111.reg,当出现“注册表导入成功”的提示后说明我们操作正确。
第六步:再通过“开始->运行->输入services.msc”,打开服务管理窗口,找到名为“Remote Desktop Help Session Manager ”和“Telnet”的服务。
第七步:在这两个服务名称上点鼠标右键选择“启动”,将服务开启。
第八步:重新启动计算机后我们再通过远程桌面连接程序访问此台计算机就不会再出现任何问题了,程序自动进入输入管理员帐号和密码的步骤。
至此我们通过启动服务和导入注册表,以及修改注册表键值使用权限三个步骤完成了解决一连接远程桌面程序就中断的故障,我们又可以轻松正常的使用远程管理程序操纵网络另一端的计算机了。
总结
这个故障实际上是因为在安装操作系统时,使用了精简版XP GHOST或网络流传的XP万能GHOST造成的,在这些GHOST中默认将远程桌面程序关闭了,并对一些必要的注册表键值使用权限进行了修改。虽然对于普通家庭个人用户来说能够提高安全,防止非法用户通过远程桌面连接计算机,但是对企业来说则会带来一定的不方便。所以笔者建议各位网络管理员在以后安装员工计算机操作系统时,尽量选择那些没有精简过的XP GHOST或者直接使用系统光盘进行安装,毕竟GHOST在使用上或多或少存在一定的问题。
-
如何判断URL格式是否符合规范?
2009-01-05 10:36:26
<%
function checkisUrl(tmpString)
dim c,i
checkisUrl = true
tmpString=Lcase(trim(tmpString))
if left(tmpString,7)<>"http://" then tmpString="http://"&tmpString
for i = 8 to Len(checkisUrl)
c = Lcase(Mid(tmpString, i, 1))
if InStr("abcdefghijklmnopqrstuvwxyz_-./\", c) <= 0 and not IsNumeric(c) then
checkisUrl = false
exit function
end if
next
if Left(tmpString, 1) = "." or Right(tmpString, 1) = "." then
checkisUrl = false
exit function
end if
if InStr(tmpString, ".") <= 0 then
checkisUrl = false
response.Write "f3"
exit function
end if
if InStr(checkisUrl, "..") > 0 then
checkisUrl = false
end if
end function
%>
<%
if checkisUrl(request("u"))=true then
%>恭喜,你的URL通过!
<%
else
%>对不起,你的URL不合乎规范,请重新检查!
<%end if%>
本文来自: 脚本之家(www.jb51.net) 详细出处参考:http://www.jb51.net/article/4807.htm -
测试网站各项性能的31 个免费在线工具(转帖)
2009-01-05 10:28:03
你是否肯定你的网站完全兼容各大浏览器?是否知道多少秒可以打开你的网站? 是否可以自信地说你的网站根本就没有打不开的时候? 是否……
虽然它看似不重要,但这些在一定程度上也对你的网站的访问量产生了影响 。这里列出了一份31 个免费在线测试工具,你可以通过这些工具来测试你的网站,并根据结果对你的网站进行修改。
网站代码验证 没人可以细致到保证自己的网站代码都是正确的,你可以通过以下测试来验证网站代码是否正确。
1 . WDG HTML Validator 一个很好的工具,能找出网站语法错误的地方,并标注出来,也可选择对网站上单独的每一页进行单页分析。( 强烈推荐 )
2 . W3C Markup Validation Service 对 HTML 和 XHTML 都能进行代码测试,自称是互联网络上第一个(也是使用者最多的)的 HTML 验证工具。
3 . W3C CSS Validation Service 用于验证 css 源代码,能够标注出不好的 css 代码设计。例如:“Same colors for color and background-color in two contexts”。
4 . RUWF XML Syntax Checker 用于查找 XML 文件的错误。
5 . W3C Feed Validation Service 用于查找 Atom 和 RSS feed 中的错误语法。( 这个我经常用到 )
6 . W3C Link Checker 用于搜寻查明你网站内的所有链接里是否有断链。( 强烈推荐 )
7 . Juicy Studio Link Analyser 测试网站内的链接的 URL 是否存在死链,与 W3C Link Checker 很类似。
网站的使用性
我们常常看到网站设计者把重点放在怎网站的吸引力上,而完全不考虑会不会影响来访者的使用,一个浏览难度很大的网页是注定要失败,要让你的来访者方便的得到他要的信息(从而成为重复访客),你的网站应当遵循 WCAG section 508 易用性规则。
8 . Watchfire WebXACT 所有严谨的设计师和开发者都必须使用的工具,它会生成一个非常详尽的报告书,包括:网站质量,易用性和隐私等。( 强烈推荐 )
9 . ATRC Web Accessibility Checker 测试网站的 WCAG 2.0 Level2 兼容性,它会生成一份报告,提出一系列建议,如:如何提升页头,链接,数据,图表和文字的访问速度。
10 . WAVE 3.0 Web Accessibility Tool 高度可定制的工具,它采用了图形化模型展示网站兼容性问题( WCAG 1.0 and section 508 )。( 强烈推荐 )
11 . TAW Web Accessibility Test 测试网页是否存在冲突( WCAG 1.0 兼容性 ),通过图形模式生成一份依据 wcag 优先模式为基础的网站修改建议。
12 . HiSoftware CynthiaSays portal 采用了非常严格的规则来测试网页( 根据 section 508 和 WCAG 1.0 规则 ),生成的报告也极为详细( 详细到很难看懂 )。
13 . HERA Accessibility testing with Style 使用一种极为复杂但容易理解方式指出网页的 wcag1.0 兼容性问题。
14 . Juicy Studio CSS Analyser 进行了色彩对比测试,以确保你的网站的色调会符合 WCAG 1.0 的要求。
15 . Juiciy Studio Readability Test 分析你网站上的文字是否有语法错误或拼写错误等问题,容易让人理解不( 根据 the Flesch Reading Ease 和 Flesch-Kincaid grade level algorithms 规则 )。( 适合英文网站使用 )
网站的速度
打开你的网站的速度快慢,是来访者会不会再次访问网站的关键因素,在一般情况下,一个网络不是很快的来访者是不愿意访问一个充满着图片、flash 动画、多媒体文件的网站。为了使你的网站覆盖人群的范围最大化,你必须优化你的网站,使它的打开速度尽可能的快。
16 . Web Page Analyzer from Website Optimization 一个很好的工具,它在分析完一个网页后,会为减少加载时间提出优化建议,着重优化物体的数目,图片和网站的总体大小。( 强烈推荐 )
17 . WebSitePulse Test Tools 有一系列的工具来确定网站的加载速度和主机信息。
18 . Internet Supervision Url Check 从世界各地不同的服务器来测试你的网站的加载时间,用于确定是不是各地的来访者都能顺利快速的打开你得网站。
浏览器模拟工具
这是一个普遍的问题,因为现在有着很多的操作系统和浏览器,你得网站必须得兼容它们,但这绝不是一件容易的事。通过下列工具,你可以了解你得网站在各种浏览器上的显示效果。
19 . Browsershots 能给出你的网站在不同浏览器下显示效果的截图,包括:Firefox 和 Internet Explorer ( Windows )、Firefox 和 Safari ( Mac OS X )、Iceweasal 和 Konqueror ( Linux ),但是结果要在 1 - 3 小时后才能出来。
20 . IE NetRenderer 实时生成你的网站在 Internet Explorer 5.5 、6.0 和 7.0 下的截图。
21 . MobiReady Report 分析使用手机访问网页的兼容性问题,会生成一份详细的报告,并提供了在两种不同类型的手机浏览器上你得网站可能显示的样子。
搜索引擎优化 (SEO)
一个网站,如果对搜索引擎有着比较好的友好度,一定会比较有竞争力。
22 . UrlTrends 会显示网站的访客是如何通过搜索引擎来到你的网站,还有各个流量是多少。这些数据是包括 Google, Yahoo, MSN, Alexa, AlltheWeb, AltaVista 和其他一些网站。( 强烈推荐 )
23 . iWEBTOOL Backlink Checker 一个很好的工具,它能找出有什么站点链接到你的站点,那些站点是什么类型的站点。
24 . iWEBTOOL Multi-Rank Checker 显示你网站的 Alexa 和 Google PageRank 数值。
25 . Microsoft adCenter Labs: Advertising and Keyword Research Tools 一个极好的工具,用于分析和预测你网站的来访者和市场。( 强烈推荐 )
26 . Domain Tools Whois lookup 一个 WHOIS 网络工具。
27 . SEO-Browser 可以让你看到在搜索引擎眼里一样的网站( 去掉所有的”美丽”配件 )。
28 . SEO Workers SEO Analysis Tool 非常有用的工具,分析了网站上的各种分类特征,包括 meta 标签、关键字密度及加载时间。( 强烈推荐 )
29 . Seekport Seekbot 可以分析网站的数据和内容,以得出搜索引擎会如何有效的解释分析的网站。
30 . SEO Chat SEO Tools 用以分析网站 Google adsense 盈利潜力,关键字密度,Meta tag 等等……
31 . Marketleap Search Engine Marketing Tools 用来分析网页,让你知道你的网站检索、设定的关键字好不好。
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 84000
- 日志数: 144
- 建立时间: 2008-10-07
- 更新时间: 2013-06-01
