

ЁЁЁЁздМКаДвЛИіМђЕЅЕФЪ§ОнПтЃЌдРэДѓИХгавдЯТМИЕуЃК
ЁЁЁЁвЛЁЂЪ§ОнвдЮФБОаЮЪНБЃДц
ЁЁЁЁНЋЫљвЊБЃДцЕФЪ§ОнаДШыЮФБОЮФМўЃЌетИіЮФБОЮФМўОЭЪЧЪ§ОнПтЁЃ
ЁЁЁЁЮЊСЫЗНБуЖСШЁЃЌЪ§ОнБиаыЗжЮЊМЧТМЃЌУПвЛЬѕМЧТМЕФГЄЖШЙцЖЈЮЊЕШГЄЁЃ
ЁЁЁЁОйР§ЃКМйЖЈУПЬѕМЧТМЕФГЄЖШЪЧ800зжНкЃЌФЧУДЕк5ЬѕМЧТМЕФПЊЪМЮЛжУОЭдк3200зжНкЁЃ
ЁЁЁЁДѓЖрЪ§ЕФЪБКђЮвУЧВЛжЊЕРФГвЛЬѕМЧТМдкЕкМИИіЮЛжУЃЌжЛжЊЕРжїМќЕФжЕЁЃетЪБЮЊСЫЖСШЁЪ§ОнЃЌПЩвдвЛЬѕЬѕБШЖдМЧТМЁЃЕЋЪЧетбљзіЕФаЇТЪЬЋЕЭЁЃЪЕМЪгІгУжаЃЌЪ§ОнПтЭљЭљВЩгУBЪїИёЪНДцДЂЪ§ОнЁЃ
ЁЁЁЁЖўЁЂЙигкBЪї
ЁЁЁЁвЊРэНтBЪїЯШашвЊРэНтЖўВцВщевЪї
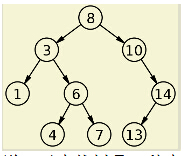
ЁЁЁЁЫЕЖўВцВщевЪїЪЧвЛжжВщеваЇТЪЗЧГЃИпЕФЪ§ОнНсЙЙЃЌЫќгаШ§ИіЬиЕуЃК
ЁЁЁЁ(1)УПИіНкЕузюЖржЛгаСНИізгЪїЁЃ
ЁЁЁЁ(2)зѓзгЪїЖМЮЊаЁгкИИНкЕуЕФжЕЃЌгвзгЪїЖМЮЊДѓгкИИНкЕуЕФжЕЁЃ
ЁЁЁЁ(3)дкnИіНкЕужаевЕНФПБъжЕЃЌвЛАужЛашвЊlog(n)ДЮБШНЯЁЃ
ЁЁЁЁЖўВцВщевЪїЕФНсЙЙВЛЪЪКЯЪ§ОнПтЃЌвђЮЊЫћЕФВщеваЇТЪгыВуЪ§гаЙиЁЃдНДІдкЯТВуЕФЪ§ОнЃЌОЭашвЊдНЖрДЮЕФБШНЯЁЃМЋЖЫЕФЧщПіЯТЃЌnИіЪ§ОнашвЊnДЮБШНЯВХФмевЕНФПБъжЕЁЃЖдгкЪ§ОнПтРДЫЕЃЌУПНјШывЛВуЃЌОЭвЊДггВХЬЖСШЁвЛДЮЪ§ОнЃЌетЗЧГЃжТУќЃЌвђЮЊгВХЬЕФЖСШЁЪБМфдЖдЖДѓгкЪ§ОнДІРэЪБМфЃЌЪ§ОнПтЖСШЁгВХЬЕФДЮЪ§дНЩйдНКУЁЃ
ЁЁЁЁBЪїЪЧЖдЖўВцВщевЪїЕФИФНјЁЃЫќЕФЩшМЦЫМЯыЪЧЃЌНЋЯрЙиЪ§ОнОЁСПМЏжадквЛЦ№ЃЌвдБувЛДЮЖСШЁЖрИіЪ§ОнЃЌМѕЩйгВХЬВйзїДЮЪ§ЁЃ

ЁЁЁЁBЪїЕФЬиЕуЃК
ЁЁЁЁ(1)вЛИіНкЕуПЩвдШнФЩЖрИіжЕЁЃ
ЁЁЁЁ(2)Г§ЗЧЪ§ОнвбОЬюТњЃЌЗёдђВЛЛсдіМгаТЕФВуЃЌвВОЭЪЧЫЕЃЌBЪїзЗЧѓЁАВуЁБдНЩйдНКУЁЃ
ЁЁЁЁ(3)згНкЕуЕФжЕЃЌгыИИНкЕужаЕФжЕгабЯИёЕФДѓаЁЖдгІЙиЯЕЁЃвЛАуРДЫЕЃЌШчЙћИИНкЕугаaИіжЕЃЌФЧУДОЭгаa+1ИізгНкЕуЁЃБШШчЩЯЭМжаЃЌИИНкЕугаСНИіжЕ(7КЭ16),ОЭгІЖдгІШ§ИізгНкЕуЃЌЕквЛИізгНкЕуЖМЪЧаЁгк7ЕФжЕЃЌзюКѓвЛИізгНкЕуЖМЪЧДѓгк16ЕФжЕЃЌжаМфЕФзгНкЕуОЭЪЧ7КЭ16жЎМфЕФжЕЁЃ
ЁЁЁЁетжжЪ§ОнНсЙЙЗЧГЃгаРћгкМѕЩйЖСШЁгВХЬЕФДЮЪ§ЁЃМйЖЈвЛИіНкЕуПЩвдШнФЩ100ИіжЕЃЌФЧУД3ВуЕФBЪїПЩвдШнФЩ100ЭђИіЪ§ОнЃЌШчЙћЛЛГЩЖўВцВщевЪїЃЌдђашвЊ20ВуЁЃМйЖЈВйзїЯЕЭГвЛДЮЖСШЁвЛИіНкЕуЃЌВЂЧвИљНкЕуБЃСєдкФкДцжаЃЌФЧУДBЪїдк100ЭђИіЪ§ОнжаВщевФПБъжЕЃЌжЛашвЊЖСШЁСНДЮгВХЬЁЃ












