ЁЁЁЁ2. ЗЂВМадФмГЁОА
ЁЁЁЁадФмВтЪдЗНАИЃК
ЁЁЁЁЗЂВМЪБМфМфИєЪБМфЯожЦДг1minЕїећЮЊ3s, ИќПьЕФБЉТЖЮЪЬтЁЃ
ЁЁЁЁЪЙгУЕЅдЊВтЪдРрЭЦЫЭЗЂВМЯћЯЂЁЃ
ЁЁЁЁЗўЮёЦїshell НХБОЪеМЏЗЂВМФЃПщадФмЪ§ОнЁЃ
ЁЁЁЁЪЙгУnmonЪеМЏЗўЮёЦїадФмЪ§ОнЁЃ
ЁЁЁЁЪЙгУjconsoleЪеМЏJVMЪ§ОнЁЃ
ЁЁЁЁЭЈЙ§БъзМЃК
ЁЁЁЁJVM Perm ЧјФкЮоФкДцаЙТЖЃЌЮоФкДцвчГіЁЃGCЪБМфМфИє>10minЃЌднЭЃгІгУЪБМф<200ms.
ЁЁЁЁЗЂВМЪБМф<30S
ЁЁЁЁCPU<70%ЃЌ load < core*1.5ЁЃ
ЁЁЁЁ3.ЩЈУшЙ§ГЬжаЗЂВМадФмГЁОА
ЁЁЁЁадФмВтЪдЗНАИЃК
ЁЁЁЁЪЙгУjmeterНХБОНјааЗжВМЪНбЙВтЃЌЭЌЪБЬсНЛЗЂВМЧыЧѓНјааЗЂВМЁЃ
ЁЁЁЁЭЌЪБЪЙгУЩЈУшадФмГЁОАКЭЗЂВМадФмГЁОАЪеМЏЪ§ОнЙІФмЁЃ
ЁЁЁЁЭЈЙ§БъзМЃК
ЁЁЁЁRT < ЩЈУшадФмГЁОАНсЙћRT * 110%.
ЁЁЁЁTPS > ЩЈУшадФмГЁОАНсЙћTPS * 90%.
ЁЁЁЁЗЂВМЪБМф < 40sЁЃ
ЁЁЁЁd. ЗЂЯжЕФЮЪЬт
ЁЁЁЁ1. ЩЈУшадФмГЁОА
ЁЁЁЁAVG RT = 473msЃЌ CMS GC = 90ms, гІгУднЭЃЪБМф = 1s, вђДЫВтЪдЮДЭЈЙ§ЁЃ
ЁЁЁЁЮЪЬтЖЈЮЛЃК
ЁЁЁЁdumpФкДцЃЌЪЙгУibm memory analyzer ЗжЮіЁЃ
ЁЁЁЁШЗШЯcms gcЕФдвђЮЊdroolsв§ЧцЕФfinalizeЗНЗЈЁЃFinzlizeЗНЗЈВЛФме§ШЗЕФЪЭЗХЖдЯѓЕФв§гУЙиЯЕЃЌЕМжТв§гУЙиЯЕвЛжБДцдкЃЌЮоЗЈЪЭЗХЁЃ
ЁЁЁЁЕїгХЗНАИЃК
ЁЁЁЁИљОнdroolsЕФЩ§МЖЮФЕЕЃЌЩ§МЖdroolsв§ЧцКѓНтОіДЫЮЪЬт
ЁЁЁЁ2. ЗЂВМадФмГЁОА
ЁЁЁЁCMS GC ЛиЪеЪЇАмЃЌФкДцЮоЗЈБЛЪЭЗХЃЌгІгУхДЛњЁЃ
ЁЁЁЁЮЪЬтЖЈЮЛЃК
ЁЁЁЁGCЛиЪеБШР§ЮЊФЌШЯжЕ68%ЃЌOLDЧјФкДц1024MЃЌФЧУДЛиЪеЕФСйНчжЕЮЊ1024*0.68=696.32MЁЃЯЕЭГЕФJVMФкДцеМгУЮЊ500MЃЌЩЈУшВпТдЯрЙиЕФФкДцЮЊ120MЃЌдкЧаЛЛЕФЙ§ГЬжаЃЌвРРЕЖюЭтЕФ120MЃЌвђДЫжЛгадкПЩгУФкДцДѓгк740MЪБВХФме§ГЃЛиЪеЁЃ
ЁЁЁЁНтОіЗНАИЃК
ЁЁЁЁЕїећJVMВЮЪ§ЃЌРЉДѓGCЛиЪеБШР§ЁЃ
ЁЁЁЁКѓајММЪѕЗНАИИФдьЃЌЪЙгУдіСПЗЂВМНтОіДЫЮЪЬтЁЃ
ЁЁЁЁ3. ЩЈУшЙ§ГЬжаЗЂВМадФмГЁОА
ЁЁЁЁЮЪЬтЖЈЮЛЃК
ЁЁЁЁЩЈУшЦНЬЈЗЂВМСїГЬЃЌЕБЪзДЮЧыЧѓНјРДЪБжДааНХБОЖЏЬЌБрвыЙ§ГЬЃЌгЩгкНХБОНЯЖрЃЌвђДЫЫљгаНХБОЕФЖЏЬЌБрвыЪБМфНЯГЄЃЌдкДЫЙ§ГЬжаЃЌНјРДЕФЫљгаЧыЧѓЖМЛсБЛhandзЁЃЌдьГЩДѓСПГЌЪБ
ЁЁЁЁНтОіЗНАИЃК
ЁЁЁЁАбНХБОЕФЖЏЬЌБрвыЬсЧАЕНЪзДЮЧыЧѓЕїгУНјРДжЎЧАЃЌБрвыЭЈЙ§КѓдйЧаЛЛЩЈУшв§ЧцЃЌБЃжЄЪзДЮЧыЧѓНјРДЧАвЛЧазМБИОЭаїЁЃ
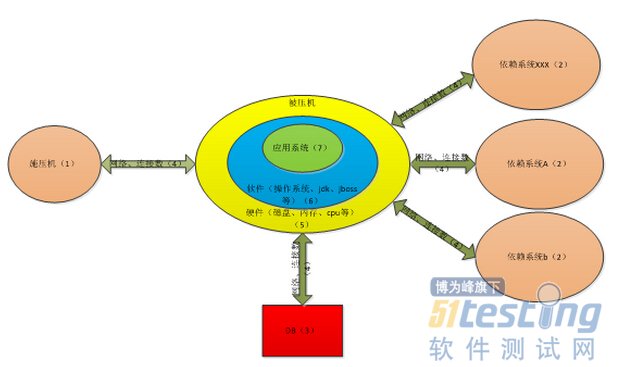
ЁЁЁЁШ§ЃКадФмВтЪдЕФжДааКЭНсЙћЪеМЏ
ЁЁЁЁ3.1адФмВтЪдЕФжДаа
ЁЁЁЁадФмВтЪдЕФжДааашвЊОпБИвдЯТМИИіЬѕМўЃКЪЉбЙЙЄОп,ВтЪдЛЗОГвдМАЖдВтЪдНсЙћЕФЪеМЏЙЄОпЁЃ
ЁЁЁЁ3.1.1 ЪЉбЙЙЄОп
ЁЁЁЁЮвУЧЯШРДЫЕЫЕЪЉбЙЙЄОпЃЌжЇИЖБІЪЙгУЕФжїСїЪЉбЙЙЄОпЪЧПЊдДЙЄОпApache JMeterЃЌжЇГжКмЖрРраЭЕФадФмВтЪдЃК
ЁЁЁЁWeb - HTTP, HTTPS
ЁЁЁЁSOAP
ЁЁЁЁDatabase via JDBC
ЁЁЁЁLDAP
ЁЁЁЁJMS
ЁЁЁЁШЮКЮгУjavaгябдБраДЕФНгПкЃЌЖМПЩЖўДЮПЊЗЂВЂЕїгУЁЃ
ЁЁЁЁжЇИЖБІДѓВПЗжНгПкЪЧwebserviceНгПкЃЌЛљгкsoapавщЃЌЧвЖМЪЧjavaПЊЗЂЃЌЫљвдЪЙгУjmeterЗЧГЃЗНБуЃЌМДЪЙjemterЙЄОпБОЩэУЛгаздДјжЇГжЕФавщЃЌвВПЩвдЭЈЙ§ПЊЗЂВхМўЕФЗНЪНжЇГжЁЃ
ЁЁЁЁ3.1.2ВтЪдЛЗОГ
ЁЁЁЁВтЪдЛЗОГАќРЈБЛбЙЛњКЭЪЉбЙЛњЛЗОГЃЌашвЊНјаагВМўХфжУКЭШэМўАцБОШЗШЯЃЌБЃжЄЯЕЭГИЩОЛЃЌЮоЦфЫћНјГЬИЩШХЃЌзюКУФмЬсЧАМрПиАыаЁЪБЕН1аЁЪБЃЌШЗШЯЯЕЭГИїЯюжИБъЖМЮовьГЃЁЃ
ЁЁЁЁСэЭтГ§СЫБЛбЙЛњКЭЪЉбЙЛњЃЌгаПЩФмгІгУЯЕЭГЛЙвРРЕЦфЫћЕФЯЕЭГЃЌЫљвдЮвУЧашвЊУїШЗЗўЮёЦїЕФЪ§СПКЭМмЙЙЃЌ1ЪЧЗНБуЮвУЧЗжЮібЙСІЕФСїГЬЃЌАяжњКѓУцЖЈЮЛКЭЗжЮіЦПОБЃЌ2ЪЧгЩгкЮвУЧЯпЯТДюНЈЕФЛЗОГдННгНќЯпЩЯЃЌВтЪдНсЙћдНзМШЗЁЃЕЋЪЧЭЈГЃгЩгкВтЪдзЪдДНєеХЛђепашвЊвРРЕЭтЮЇЃЌР§ШчвјааЕФЛЗОГЃЌОЭЛсБШНЯТщЗГЃЌЭЈГЃЮвУЧЛсбЁдёЪЪЕБЕФНјааЛЗОГmockЁЃЕБШЛЃЌMockЕФЪБКђОЁСПКЭецЪЕЛЗОГБЃГжвЛжТЃЌОйИіМђЕЅЕФР§згЃЌШчЙћжЇИЖБІЖЫЯЕЭГКЭвјааНјааЭЈаХЃЌЯпЩЯвјааЕФЦНОљДІРэЪБМфЮЊ100msЃЌФЧУДШчЙћЮвУЧдкЯпЯТадФмВтЪдЪБашвЊmockвјааЕФЗЕЛиЃЌашвЊМгШы100msбгГйЃЌетбљВХФмБШНЯНгНќецЪЕЕФЛЗОГЁЃ
ЁЁЁЁСэЭтГ§СЫВтЪдЛЗОГЃЌЛЙгавРРЕЕФВтЪдЪ§ОнвВашвЊжиЕуЙизЂЃЌЪ§ОнашвЊЙизЂзмСПКЭРраЭЃЌР§ШчжЇИЖБІзіНЛвзЪБЃЌdbжаСїЫЎЭђМЖКЭвкМЖЕФадФмПЯЖЈЪЧВЛвЛбљЕФЃЛЛЙгаdbЪЧЗёЗжПтЗжБэЃЌашвЊБЃжЄЪ§ОнЗжВМЕФОљКтадЁЃвЛАуПМТЧЕНЯпЯТзМБИЪ§ОнЕФЪБГЄЃЌвЛАуадФмВтЪдвЊЧѓКЭЯпЩЯЕФЪ§ОнБЃГжвЛИіЪ§СПМЖЁЃ
ЁЁЁЁ3.1.3 ВтЪдНсЙћЪеМЏЙЄОп
ЁЁЁЁВтЪдНсЙћЪеМЏжївЊАќРЈвдЯТМИИіжИБъЃК
ЁЁЁЁЯьгІЪБМфЁЂtpsЁЂДэЮѓТЪЁЂcpuЁЂloadЁЂIOЁЂЯЕЭГФкДцЁЂjvmЃЈjavaащФтФкДцЃЉЁЃ
ЁЁЁЁЦфжаЯьгІЪБМфЁЂtpsКЭвЕЮёДэЮѓТЪЭЈЙ§jemterПЩвдЪеМЏЁЃ
ЁЁЁЁCpuЁЂloadЁЂioКЭЯЕЭГФкДцПЩвдЭЈЙ§nmonЛђlinuxздДјУќСюЕФЗНЪНРДМрПиЁЃ
ЁЁЁЁJvmПЩвдЭЈЙ§jdkздДјЕФjconsoleЛђепjvisualvmРДМрПиЁЃ
ЁЁЁЁзмЬхРДЫЕЃЌМрПиСЫетаЉжИБъЃЌЖдЯЕЭГЕФадФмОЭгаСЫеЦЮеЃЌЭЌбљетбљжИБъвВПЩвдЗДРЁЯЕЭГЕФЦПОБЫљдкЁЃ
ЁЁЁЁЫФЃЎадФмВтЪдЦПОБЭкОђгыЗжЮі
ЁЁЁЁЮвУЧдкЩЯУцвЛеТжаФУЕНадФмВтЪдНсЙћЃЌетУДЖрЪ§ОнЃЌдѕУДШЅЗжЮіЯЕЭГЕФЦПОБдкФФРяФиЃЌвЛАуЪЧАДееетбљЕФЫМТЗЃЌЯШПДвЕЮёжИБъЃКЯьгІЪБМфЁЂвЕЮёДэЮѓТЪЁЂКЭtpsЪЧЗёТњзуФПБъЁЃ
ЁЁЁЁШчЙћЦфжагавЛИігавьГЃЃЌПЩвдЯШХХГ§ЪЉбЙЛњКЭЭтЮЇвРРЕЯЕЭГЪЧЗёгаЦПОБЃЌШчЙћУЛгаЃЌЙизЂЭјТчЁЂdbЕФадФмКЭСЌНгЪ§ЃЌзюКѓЙизЂЯЕЭГБОЩэЕФжИБъЃК
ЁЁЁЁгВМўЃКДХХЬЪЧЗёаДТњЁЂФкДцЪЧЗёЙЛгУЁЂcpuЕФРћгУТЪЁЂЦНОљloadжЕ
ЁЁЁЁШэМўЃКВйзїЯЕЭГАцБОЁЂjdkАцБОЁЂjbossШнЦївдМАгІгУвРРЕЕФЦфЫћШэМўАцБО
ЁЁЁЁJvmФкДцЙмРэКЭЛиЪеЪЧЗёКЯРэ
ЁЁЁЁгІгУГЬађБОЩэДњТы
ЁЁЁЁЯШПДЯТЭМЃКЪЧвЛАуадФмВтЪдЛЗОГВПЪ№ЭМ
ЁЁЁЁ