最近在企业里面看了一些测试案例的数据准备,发现了一个共性问题:测试数据中存在大量冗余,这些冗余会给后续的测试案例及数据维护带来大量的成本。
为了便于大家理解,先举一个例子:
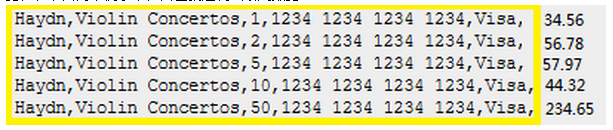
测试信用卡交易金额汇总,测试数据完全从csv中加载,每个测试案例根据csv中的数据,assert特定返回值(由于篇幅限制,这里只举了一个简单的例子。实际看到的情况是,csv完全没有字段名称信息,一行里面成百上千个数据,而且还有许许多多类似结构的csv文件作为测试数据)。
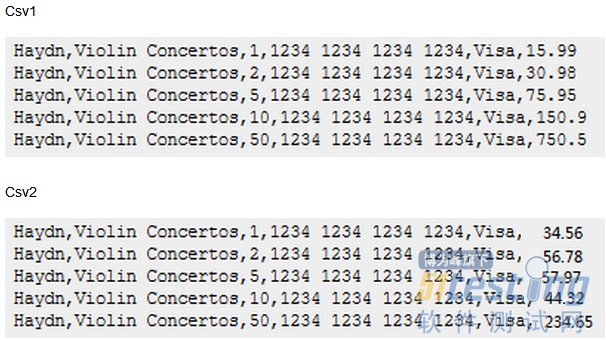
在这两个文件里面,我注意到有大量冗余。以csv格式的测试案例为例,想象一下如果未来这个表结构发生变化(增加或减少字段),那么需要修改所有这些csv文件,会是什么样的工作量!
在乔梁翻译的《持续交付:发布可靠软件的系统方法》一书,其实已经给出了解决思路,只不过由于没有具体实例,不是很容易理解。
经何勉提醒,发现在《实例化需求》一书中,也提到了类似思路,但同样都没有实例,:):
下面我们就以上面例子为基础,说明一下两本书中的思路如何具体应用:
应用程序引用数据(Application reference data)是测试无关数据,但它们是应用程序启动所必需的,这些数据往往是指一些基表和基础数据;
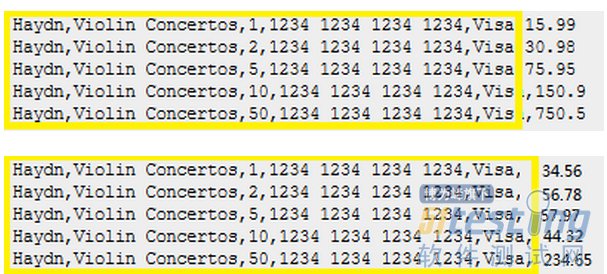
测试引用数据(Test reference data)是那些和测试相关,但是对测试行为没有多大影响的数据,在下面两个例子中,黄色就是测试引用数据