

测试执行
测试验证 (总和是428.28)
这样做主要有两点好处:
测试案例可维护性:上面这些案例中,测试引用数据由于使用了INSERT语句,它其实会受到数据库表结构变化的影响,而测试专属数据准备由于使用UPDATE语句,不会受到数据库表结构变化的影响。我们通过统一测试引用数据准备程序,将这种变化的冲击大大降低,未来数据表结构变更,我们只需修改统一的测试引用数据准备程序而无需修改每一个案例,这其实暗合了DRY原则(Don’t repeat yourself)。
测试案例可读性:由于我们将测试引用数据准备从独立出来了,只要看测试案例本身,就可以明确地看到测试专属数据,被测行为和结果验证,让案例可读性大大提升。
为了便于大家理解,我们再举另一个例子,假设有一个测试汇率转换接口,测试输入是xml文件:

应用测试引用数据和测试专属数据分离原则,可以看到哪些是引用数据,哪些是专属数据
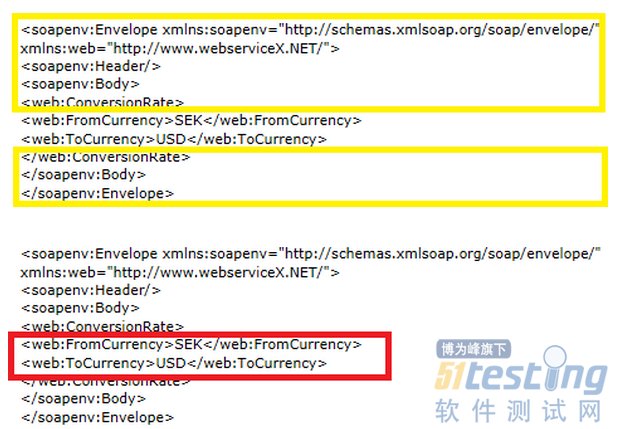
因此,在测试案例中,我们会先准备并加载一个基底XML文件,再设置测试专属数据,下面是利用Robot Framework编写的两个测试案例,可以看出,未来如果XML文件的结构有任何变更,我们都只需要修改基底XML文件即可,而不需要修改任何测试案例了
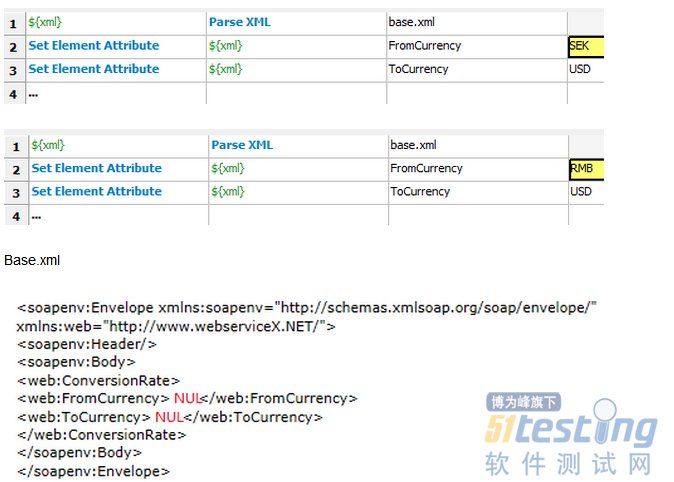
至此,我们想大家已经明白,对于测试数据准备这个步骤而言,将测试引用数据和测试专属数据分离,会非常有效地提升测试案例可维护性和可读性。











