

ЎЎЎЎ¶юЎўІвКФ±Ёёж
ЎЎЎЎspymemcachedєНxmemcached¶јКµПЦБЛТ»ЦВРФ№юПЈЛг·ЁЈЁЖдКµОТКЗХХіµДЈ©Ј¬ХвАпТЄІвКФПВФЪК№УГТ»ЦВРФ№юПЈµДЗйїцПВЈ¬ФцјУЅЪµгЈ¬їґІ»Н¬ЙўБРєЇКэПВГьЦРВКєНКэѕЭ·ЦІјµД±д»ЇЗйїцЈ¬ХвёцІвКФЅб№ы¶ФУЪspymemcachedєНxmemcachedКЗТ»СщµДЈ¬ІвКФіЎѕ°Јє
ЎЎЎЎґУТ»ЖЄУўОДРЎЛµЈЁЎ¶»ЖЅрВЮЕМЎ·З°ИэХВЈ©ЅшРРµҐґКНіјЖЈ¬ІўЅ«ЧоєуµДНіјЖЅб№ыґжґўµЅmemcachedЈ¬ТФµҐґКОЄkeyЈ¬ТФґОКэОЄvalueЎЈµҐґКёцКэОЄ 3061Ј¬memcachedФАґЅЪµгКэОЄ10Ј¬ФЛРРФЪѕЦУтНшДЪН¬Т»МЁ·юОсЖчЙПµДІ»Н¬¶ЛїЪЈ¬ФЪґжґўНіјЖЅб№ыєуЈ¬ФцјУБЅёцmemcachedЅЪµгЈЁТІѕНКЗґУ10ёцЅЪµгФцјУµЅ12ёцЅЪµгЈ©Ј¬НіјЖґЛК±µД»єґжГьЦРВКІўІйїґКэѕЭµД·ЦІјЗйїцЎЈ
ЎЎЎЎЅб№ыИзПВ±нёсЈ¬ГьЦРВКТ»РР±нКѕФцјУЅЪµгєуµДГьЦРВКЗйїцЈЁФцјУЗ°ОЄ100%Ј©Ј¬єуРшµДРР±нКѕёчёцЅЪµгґжґўµДµҐґККэ,CRC32_HASH±нКѕІЙУГCRC32 ЙўБРєЇКэЈ¬KETAMA_HASHКЗ»щУЪmd5µДЙўБРєЇКэТІКЗД¬ИПЗйїцПВТ»ЦВРФ№юПЈµДНЖјцЛг·ЁЈ¬FNV1_32_HASHѕНКЗFNV 32О»ЙўБРєЇКэЈ¬NATIVE_HASHѕНКЗjava.lang.String.hashCode()·Ѕ·Ё·µ»ШµДlongИЎ32О»µДЅб№ыЈ¬MYSQL_HASHКЗxmemcachedМнјУµДґ«ЛµАґЧФУЪmysqlФґВлЦРµД№юПЈєЇКэЎЈ
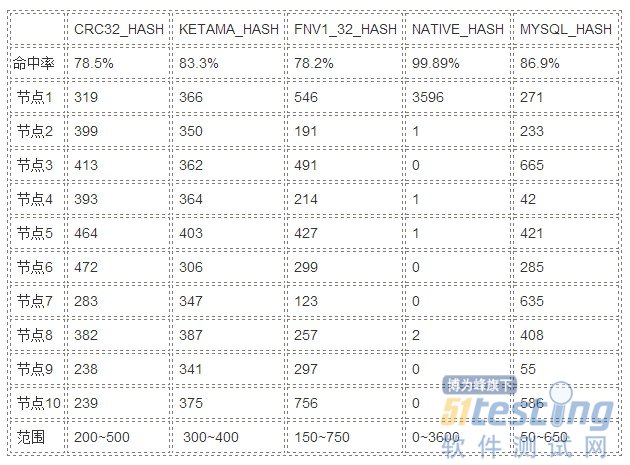
ЎЎЎЎЅб№ы·ЦОцЈє
ЎЎЎЎ1ЎўГьЦРВКЧоёЯїґЖрАґКЗNATIVE_HASHЈ¬И»¶шNATIVE_HASHЗйїцПВКэѕЭјЇЦРґжґўФЪµЪТ»ёцЅЪµгЈ¬ПФИ»Г»УРКµјКК№УГјЫЦµЎЈОЄКІГґ»бјЇЦРґжґўФЪµЪТ»ёцЅЪµгДШЈїХвКЗУЙУЪФЪІйХТґжґўµДЅЪµгµД№эіМЦРЈ¬»б±ИЅПhash(key)єНhash(ЅЪµгIPµШЦ·)Ј¬¶шФЪІЙУГБЛNATIVE_HASHµДЗйїцПВЈ¬ЛщУРБ¬ЅУµДhashЦµ»біКПЦТ»ёцµЭФцЧґїцЈЁТтОЄString.hashCodeКЗіЛ·ЁЙўБРєЇКэЈ©Ј¬ИзЈє
ЎЎЎЎ192.168.0.100:12000 736402923
ЎЎЎЎ192.168.0.100:12001 736402924
ЎЎЎЎ192.168.0.100:12002 736402925
ЎЎЎЎ192.168.0.100:12003 736402926
ЎЎЎЎИз№ыХвР©ЦµєЬґуµД»бЈ¬ДЗГґµҐґКµДhashCode()»бНЁіЈРЎУЪХвР©ЦµµДµЪТ»ёцЈ¬ДЗГґІйХТѕНѕіЈЦ»ХТµЅµЪТ»ёцЅЪµгІўґжґўКэѕЭЈ¬µ±И»Ј¬ХвАпУРІвКФµДѕЦПЮРФЈ¬ТтОЄmemcached¶јЕЬФЪТ»ёцМЁ»ъЖчЙПЦ»КЗ¶ЛїЪІ»Н¬ФміЙБЛhash(ЅЪµгIPµШЦ·)µДБ¬РшµЭФцЈ¬Ѕ«·ЦІјІ»ѕщФИµДОКМв·ЕґуБЛЎЈ
ЎЎЎЎ2ЎўґУЅб№ыЙПїґЈ¬KETAMA_HASHО¬іЦБЛТ»ёцЧојСЖЅєвЈ¬ФЪФцјУБЅёцЅЪµгєу»№ДЬ·ГОКµЅ83.3%µДµҐґКЈ¬ІўЗТКэѕЭ·ЦІјФЪёчёцЅЪµгЙПµДКэДїТІПа¶ФЖЅѕщЈ¬ДС№ЦЧчОЄД¬ИПЙўБРЛг·ЁЎЈ
ЎЎЎЎ3ЎўЧоєуЈ¬µҐґї±ИЅППВЙўБРєЇКэµДјЖЛгР§ВКЈє
ЎЎЎЎCRC32_HASH:3266
ЎЎЎЎKETAMA_HASH:7500
ЎЎЎЎFNV1_32_HASH:375
ЎЎЎЎNATIVE_HASH:187
ЎЎЎЎMYSQL_HASH:500
ЎЎЎЎNATIVE_HASH > FNV1_32_HASH > MYSQL_HASH > CRC32_HASH > KETAMA_HASH












