

ЎЎЎЎөұБҪёцНЕ¶У№ВБўјмІйЈ¬ФЛО¬өјПтөДјаІвКЗІ»»бУРХвёцөДҪбВЫ(Whenexaminedindependently,operations-orientedmonitoringwouldnotbethattelling.)ЎЈө«КЗЈ¬өұЛьұ»·ЕөҪҫЯМеөДЙППВОДЦРЈ¬ІўЙжј°өҪ№ШБӘөДКэҫЭЈЁЧоЦХУГ»§ПмУҰКұјдЈ¬УГ»§МеСйЈ¬...Ј©Ј¬Хв¶ФҝӘ·ўНЕ¶УАҙЛөКЗ·ЗіЈЦШТӘөДЈ¬БҪёцНЕ¶УҪ«»сөГёь¶аөДБйёРәНКУҪЗЎЈХвКЗТ»ёцБјәГөДҝӘ¶ЛЈ¬ө«ИФИ»»№УРәЬ¶аРиТӘБЛҪвөДЎЈ
ЎЎЎЎІҪЦи3ЈәДДР©№ШјьКВОсұ»ХжХэУ°ПмөҪБЛЈҝ
ЎЎЎЎөг»чЙзЗшУҰУГіМРтөДБҙҪУЈ¬Ль»бПФКҫКөјККЬУІјюЧҙМ¬У°ПмөДКВОсәНТіГжЈ¬ө«ИФИ»ҙжФЪЧЕБҪёц№ШјьөДИҙУЦРь¶шОҙҫцөДОКМвЈә
ЎЎЎЎХвР©КВОсЈ¬КЗ·сКЗОТГЗіЙ№ҰФЛРРөД№ШјьЈҝ
ЎЎЎЎХвР©КВОсәНёцИЛУГ»§КЬРФДЬОКМвУ°ПмәуЈ¬УР¶аСПЦШөДәу№ыЈҝ
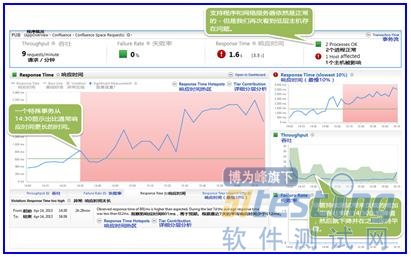
ЎЎЎЎЧФ¶Ҝ»щПЯёжЛЯОТГЗЈ¬ЙзЗшНшХҫЦчТӘТіГжөДПмУҰКұјдКЬөҪГчПФөДөДРФДЬУ°ПмЎЈТІ°ьАЁОТГЗөДКЧТіЈ¬ХвКЗОТГЗЧоУРјЫЦөөДТ»ёцТіГжЎЈ
ЎЎЎЎІҪЦи4ЈәҝЙКУ»ҜКЬУІјюОКМвУ°ПмөДКВОсБч
ЎЎЎЎКВОсБчНјұнКЗТ»ёцБоИЛВъТвөД·ҪКҪЈ¬ДЬК№өГФЛО¬НЕ¶УәНҝӘ·ўНЕ¶УҙпөҪТ»ёц»щұҫөД№ІК¶Ј¬ІўёщҫЭЖдНкХыөДЙППВОДІйҝҙ№ШјьөДКэҫЭЎЈЛьДЬПФКҫЙжј°өҪөДУҰУГІгЈ¬ХэФЪФЛРРөДОпАн»ъЖчәНРйДв»ъЖчЈ¬ТФј°ДДАпКЗИИөгЗшУтЎЈ

ЎЎЎЎФЛО¬НЕ¶УәНҝӘ·ўНЕ¶УУРПаН¬өДёЕТӘНјұнЈ¬ёжЛЯЛыГЗОЮВЫКЗФЪ"әбПт"КВОсәН"ЧЭПт"ІгГжөДИИөгЗшУтЎЈ
ЎЎЎЎОТГЗЦӘөАЈ¬ОТГЗөДНшТіДЪИЭ·ЗіЈ"·бё»"ЈЁНјПсЈ¬JavaScriptәНCSSЈ©Ј¬ёЯҙп80ЈҘөДКВОсКұјд»Ё·СФЪдҜААЖчЙПЎЈҝҙөҪИИөгЗшУтХвСщөДұнПЦЈ¬ПЦФЪХыМеТіГжјУФШКұјдПВҪөөҪ50ЈҘЈ¬ОТГЗВнЙПҫНЦӘөАёь¶аөДКВОсКұјдТСҫӯЧӘТЖөҪРВөДИИөгЗшУтЈә·юОсЖч¶ЛЎЈәГПыПўКЗЈ¬КэҫЭҝвКЗГ»УРОКМвөДЈЁЦ»УГБЛ1ЈҘөДПмУҰКұјдЈ©Ј¬ХыёцРФДЬИИөгЗшУтЛЖәхЧӘөҪWebәНУҰУГіМРт·юОсЖчЈ¬ЛьГЗ¶јФЛРРФЪН¬Т»МЁ»ъЖчЙП-јҙДЗМЁҙжФЪCPUОКМвөД»ъЖчЎЈ
ЎЎЎЎөЪ5ІҪЈәҫ«И·¶ЁО»ҙжФЪОКМвөД»ъЖчөДҪЎҝөОКМв
ЎЎЎЎөг»чЦч»ъҪЎҝөНјұн(HostHealthDashboard)Ј¬Ль»бПФКҫБЛДЗёцМШ¶ЁөД·юОсЖчіцБЛКІГҙОКМвЈә
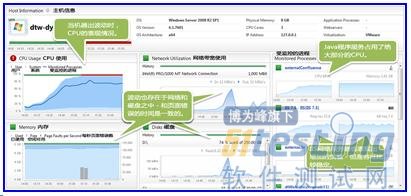
ЎЎЎЎФЛО¬НЕ¶УБўјҙҝҙөҪБЛCPUөДПыәДЦчТӘАҙЧФУЪТ»ёцJavaУҰУГ·юОсЖчЎЈНшВзЈ¬ҙЕЕМәНТіГжҙнОуФЪТ»Р©ДіР©МШ¶ЁөДКұјдТІ¶јҙжФЪІ»С°іЈөДІЁ¶ҜЎЈ












