

ЎЎЎЎТлХЯЈәФӯКјОДХВУРөгРФДЬІвКФ№ӨҫЯИнОДөДёРҫхЈ¬ұПҫ№ОДХВАҙФҙУЪДі№ӨҫЯ№Щ·ҪІ©ҝНЎЈёЯКЦЗлВФ№эЎЈ
ЎЎЎЎ¶ФУЪОТХвЦЦРВКЦЈ¬ҙЛОД»№КЗёшОТҙшАҙТ»Р©ҫӘПІЈ¬ҙУЙПөҪПВөШЈ¬ҙУұнПуөҪёщФҙөШЈ¬¶ЁО»ЛыГЗУцөҪРФДЬОКМв-ПмУҰКұјд№эіӨ-өДёщұҫФӯТтЈ¬УРҫЯМеөДІҪЦиЈ¬ЛјҝјәНЕР¶ПТАҫЭЈ¬ХвҫНКЗТ»ёцұИҪПІ»ҙнРФДЬІвКФ·ЦОцКөАэЎЈҝЙТФёьЗеіюҝҙөҪРФДЬІвКФИзәО·ЦОц¶ЁО»Ј¬ҝЙТФС§П°ЖдЛјВ·ЎЈ№К·ЦПнЦ®ЎЈ
ЎЎЎЎФӯОДБ¬ҪУ:http://apmblog.compuware.com/2013/06/04/how-to-accurately-identify-impact-of-system-issues-on-end-user-response-time/
ЎЎЎЎТФПВОӘХэОД
ЎЎЎЎОТГЗПЈНыјмІвПВОТГЗЙзЗшНшХҫөДёәФШДЬБҰЈ¬ЛщТФОТГЗҝӘ·ўНЕ¶УҪшРРБЛТ»ёцИООсЈ¬СйЦӨЙъІъ»·ҫіөДПөНіКЗ·сДЬФЪПЦУРөДУІјю»щҙЎЙПҙҰАн10ұ¶УЪДҝЗ°өДёәФШЎЈОӘБЛҪ«НшХҫФЪёЯёәФШПВҝЙДЬөДұААЈУ°ПмҪөөҪЧоөНЈ¬ОТГЗҫц¶ЁФЪЦЬИХПВОзҪшРРөЪТ»ВЦІвКФЎЈФЪФЛРРІвКФЦ®З°Ј¬ОТГЗёшФЛО¬НЕ¶УМбБЛТ»ёцРСЈәЛыГЗҝЙДЬФЪХвҙОБҪРЎКұөДЖЪјд№ЫІмөҪГчПФөДёәФШұд»ҜЈ¬ҙУ¶шҝЙДЬУ°ПмөҪФЛРРФЪН¬Т»»·ҫіПВөДЖдЛыУҰУГіМРтЎЈ
ЎЎЎЎФЪІвКФ№эіМЦРЈ¬ФЛО¬НЕ¶УәНҝӘ·ўНЕ¶УТ»ЖрјаҝШКөКұРФДЬКэҫЭЈ¬өұҙпөҪТ»¶ЁөДёәФШЛ®ЖҪәуЈ¬ОТГЗҝҙөҪЧоЦХУГ»§өДПмУҰКұјдәНәДҫЎЧКФҙЎЈФЪұҫҙОІвКФЦР·ЗіЈУРИӨөДКЗЈ¬ҝӘ·ўНЕ¶УәНФЛО¬НЕ¶У¶јҝҙЧЕПаН¬өДКэҫЭЈ¬ө«КЗИҙҙУІ»Н¬өДҪЗ¶ИИҘЙуКУХвР©Ҫб№ыЎЈИ»¶шЈ¬ЛыГЗ¶јКЗТААөУЪЧоҪьІЕ№«ІјөДCompuwareөДPureStackјјКхЈ¬ХвКЗЎӘЎӘХыәПdynaTraceәНPurePathЎӘЎӘөДөЪТ»ёцҪвҫц·Ҫ°ёЈ¬ПФКҫіцФЪёЯёәФШПВЙъІъ»·ҫіөДУІјюКЗИзәОУ°ПмөҪ№ШјьТөОсУҰУГіМРтөДРФДЬЎЈ
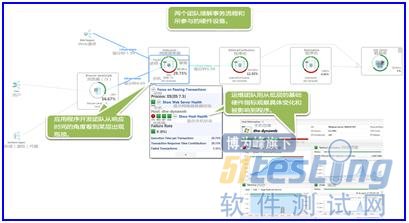
ЎЎЎЎЙППВОДОӘФЛО¬НЕ¶УәНҝӘ·ўНЕ¶УөДКэҫЭЦ®јдјЬЖрЗЕБәЈәХвХЕНјЖ¬ПФКҫ"әбПт"КВОсТФј°"ЧЭПт"ІгГжөДИИөгЗшУт(BridgingtheGapbetweenOpsandAppsDatabyaddingContext:OnepicturethatshowstheHotspotsof"Horizontal"Transactionaswellasthe"Vertical"Stack.)ЎЈ
ЎЎЎЎФЪОТГЗөДіЎҫ°ЦРұнПЦІ»јСөДёщұҫФӯТт-Т»ёцФЛРРЧЕWebәНУҰУГіМРт·юОсөДЦч·юОсЖчөДCPUұ»әДҫЎ-ҙУ¶шөјЦВҙпІ»өҪОТГЗөДёәФШДҝұкЎЈКВКөЦӨГчЈ¬ХвёцОКМвКЗёъУІјюЙиұёәНУҰУГіМРт¶јУР№ШПө(ThisturnedouttobebothanITprovisioningandanapplicationproblem)ЎЈИГОТҪвКНТ»ПВНЕ¶УөДІҪЦиТФј°ЛыГЗКЗИзәОөГіцЛыГЗөДРР¶ҜПоБРұнЈ¬ТФұгёДЙЖДҝЗ°өДПөНіРФДЬЈ¬ТФұгФЪөЪ¶юВЦІвКФЦРөГөҪёьәГөДҪб№ыЎЈ
ЎЎЎЎөЪ1ІҪЈәјаҝШәНК¶ұрУІјюҪЎҝөЧҙҝц
ЎЎЎЎФЛО¬НЕ¶УПЈНыДЬ№»ҝҙЧЕЛыГЗөД·юОсЖчБРұнЈ¬¶шЛщУР№ШјьЦёұкЈЁCPUЈ¬ДЪҙжЈ¬НшВзЈ¬ҙЕЕМөИЈ©¶јДЬәЬҝмөШіКПЦіцВМЙ«ЧҙМ¬(OperationsTeamslikehavingtheabilitytolookattheirlistofserversandquicklyseethatallcriticalindicators(CPU,Memory,Network,Disk,etc)aregreen)ЎЈө«КЗЈ¬өұОТГЗөДёәФШІвКФҙпөҪБЛ¶Ҙ·еКұЈ¬ЛыГЗҝҙПт·юОсЖчөДЧҙМ¬КұЈ¬ПФКҫіцАҙИҙКЗЈ¬ЛыГЗУР2МЁ»ъЖчХэіцПЦБЛТміЈЈә
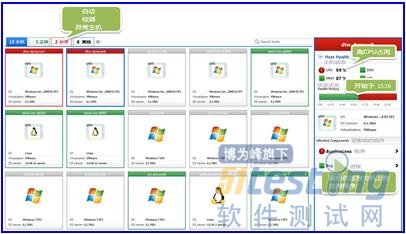
ЎЎЎЎОТГЗөДЙзЗшНшХҫәЛРД·юОсЖчіцПЦCPUПа№ШөДОКМвЈ¬ІўУ°ПмөҪБнТ»ФЛРРФЪХвМЁ·юОсЖчЙПөДУҰУГіМРтЎЈ
ЎЎЎЎІҪЦи2ЈәДДР©ФЛРРЦРөДУҰУГіМРтұ»ХжХэУ°ПмөҪБЛЈҝ
ЎЎЎЎөҘ»чКЬУ°ПмөДіМРтСЎПоҝЁЈ¬Ль»бПФКҫКЬУ°ПмөД»ъЖчЙПЛщУРФЛРРөДУҰУГіМРтЈ¬ТФј°ДҝЗ°КЬУ°ПмөДУҰУГіМРтЈә

ЎЎЎЎФцјУөДёәФШІ»ҪцУ°ПмөҪЙзЗшНшХҫЈ¬¶шЗТТІУ°ПмөҪОТГЗЦ§іЦНшХҫ
ЎЎЎЎХвҙОёәФШІвКФТСҫӯИГОТГЗГч°ЧЈәИз№ыОТГЗПЈНыОҙАҙөДЙзЗшНшХҫДЬ№»іРөЈёьёЯөДёәФШЈ¬ДЗОТГЗҝЙДЬРиТӘТЖ¶ҜЦ§іЦНшХҫөҪЖдЛыөД»ъЖчЈ¬ТФұЬГвІ»ұШТӘөДУ°ПмЎЈ












