

4)对于大过程建模,影响因子太多,每个因子相关性都不大
如果是对于大的过程建模,则可能存在如下的问题:
● 影响因子多,每个因子的相关性都不是很大;
● 影响因子多,采集数据有难度,对每个数据都要求很准确;
● 影响因子之间彼此有交互叠加的作用,有相关性,建模困难。
5)样本量太少
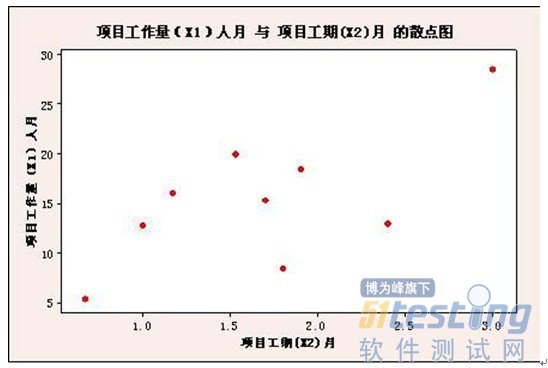
样本量太少,增加或删除一个样本对回归的结果影响很明显,则规律不具有典型性。比如,在下图中如果删除右上角的一个点,则两个变量之间就没有相关性了,如果删除了右下的2个点则两个变量之间就是相关的。之所以出现这种现象就是样本点太少而导致的。
6)样本不随机
比如有2个变量X1,X2与Y都应该是正相关的,但是在实际中存在的数据却是:
| 正相关 | 正相关 | |
| Y | x1 | x2 |
| 中 | 大 | 小 |
| 中 | 小 | 大 |
此时如果对这些类型的数据进行分析,则表现出来Y与X1,X2是不相关的。
以测试过程为例,我们的经验与常识:
假设或常识1:高水平的测试人员找出的BUG多, 低水平的测试人员找出的BUG少。
假设或常识2:高水平的开发人员犯的错误应该少,低水平的开发人员犯的错误应该多。
我们的实际数据:
在实践中常常采用的策略:
策略1:关键的模块应该由高水平的开发人员进行开发,非关键的模块由低水平的开发人员进行开发。
策略2:高水平的测试人员要测关键的模块,低水平的测试人员测试非关键的模块。
如果是这样,对于测试过程做了度量以后,数据无法证明假设1和2的成立。
以上六个原因就是最常见的原因,这些原因在实际中克服起来并非那么容易,这也是为什么4-5级需要比较长的实施周期的原因。












