

ЁЁЁЁ3ЁЂЪЙгУГЁОАЕФвЛжТад
ЁЁЁЁЁё ЛљДЁЪ§ОнЕФвЛжТад
ЁЁЁЁАќРЈдЄВтЕФвЕЮёЪ§ОнСПЃЌвдМАЪ§ОнРраЭЕФЗжХфЁЃКмМђЕЅЕФвЛИіСазгЃЌвЛИіЯЕЭГЕФЪ§ОнПтжЛга10ЬѕЪ§ОнКЭвЛЬѕЪ§ОнПтРяМИЧЇЭђЬѕЪ§ОнЃЌЮвУЧдкЖдЦфНјааадФмВтЪдЪБЃЌЕУЕНЕФадФмжИБъПЩФмЛсгаЗЧГЃДѓЕФВюБ№ЁЃ
ЁЁЁЁЮЊСЫБЃжЄУПДЮВтЪдЛЗОГЕФИќМгвЛжТадЃЌДХХЬЕФЪЙгУЧщПівдМАДХХЬЕФЫщЦЌЧщПівВЛсЛђЖрЛђЩйЕФгАЯьЕФадФмЁЃ
ЁЁЁЁЁё ЪЙгУФЃЪНЕФвЛжТад
ЁЁЁЁОЁСПФЃФтецЪЕГЁОАЯТгУЛЇЕФЪЙгУЧщПіЃЌЦфЪЕЃЌЮвУЧдкзіадФмВтЪдЧАЦкЕФашЧѓЗжЮіЃЌЦфжївЊФПЕФвВОЭЪЧЮЊСЫИќецЪЕЕФФЃФтгУЛЇЕФЪЙгУЧщПіЁЃ
ЁЁЁЁадФмВтЪдЛЗОГЕФЪЕЪЉВпТд
ЁЁЁЁЩЯУцНВВтЪдЛЗОГгыЩњВњЛЗОГБЃГжвЛжТЫљашвЊзЂвтЕФФкШнЁЃЦфЪЕдкЪЕМЪЕФВтЪджаЃЌЮвУЧКмФбДюНЈГігыЩњВњЛЗОГЭъШЋвЛжТЕФвЛИіВтЪдЛЗОГЃЌГ§ЗЧЮвУЧднЭЃЩњВњЛЗОГгУЛЇгкНјааадФмВтЪдЃЌетЭљЭљЪЧВЛПЩФмЁЃвЛЗНУцФГаЉЩњВњЛЗОГЪЧВЛдЪаэБЛднЭЃЕФЃЌСэвЛЗНУцвВЮЊЩњВњЛЗОГЕФАВШЋадПМТЧЁЃ
ЁЁЁЁадФмВтЪдЛЗОГВЂВЛЯёЙІФмВтЪдЛЗОГЃЌЮЊСЫНкЪЁзЪдДПЩвдвЛЬЈЗўЮёЦїЩЯдЫааЖрИіЯЕЭГЁЃгЩгкадФмВтЪдЕФЬиЪтадЃЌећИіВтЪдЛЗОГашвЊдкбЯИёЕФЖРСЂМрПиЯТЙмРэЃЌдкКмЖрЧщПіЯТЃЌЮвУЧКмФбЩъЧыЕНзуЙЛЕФЧввЛжТЕФзЪдДЃЈЫЕАзСЫОЭЪЧРЯАхЪЧЗёдИвтГіЧЎИјФуТђЗўЮёЦїДюНЈЯЕЭГЃЉЁЃЖдгквЛИіВЂЮДЩЯЯпЕФЯюФПЃЌЦфЩњВњЛЗОГЕФХфжУвВЪєгкднЖЈзДЬЌЃЌадФмВтЪдЕФФПЕФОЭЪЧЮЊСЫШЗЖЈОпЬхЩњВњЛЗОГЕФгВМўХфжУЁЃетИіЪБКђИќВЛПЩФмгУЙ§ИпЕФХфжУРДДюНЈадФмЛЗОГЃЈГ§ЗЧЯжГЩЕФЛЗОГЗХзХВЛгУЃЉЁЃ
ЁЁЁЁЮвУЧвЛАуЭЈЙ§СНжжВпТдРДДюНЈадФмВтЪдЛЗОГЃЈдЄЙРЗНЪНОљгаЮѓВюЃЉ
ЁЁЁЁ1ЁЂЭЈЙ§НЈФЃЕФЗНЪНЪЕЯжЕЭЖЫгВМўЖдИпЖЫгВМўЕФФЃФт
ЁЁЁЁЭЈЙ§ХфжУВтЪдРДМЦЫуВЛЭЌХфжУЯТЕФгВМўадФмКЭЯЕЭГДІРэФмСІЕФЙиЯЕЃЌДгЖјЭЦЕМГіТњзуЯЕЭГадФмЕФецЪЕХфжУЧщПіЃЌетжжФЃФташвЊОЋШЗЕФНЈФЃЃЌФЃаЭЕФВЩбљЕудНЖрЃЌФЧУДЕУЕНЕФНсЙћдНОЋШЗЃЌДгЖјНЋдкЕЭЖЫХфжУЯТЕФадФмжИБъЭЈЙ§ИУФЃаЭзЊЛЏЮЊИпЖЫХфжУЯТЕФзюжедЄМЦадФмжИБъЁЃ
ЁЁЁЁР§ШчЃКДюНЈвЛИіЕЭЖЫЛЗОГЃЌЪзЯШашвЊЖдетИіЛЗОГЕФCPUКЭФкДцНјааЕЅЖРЕФадФмЛљзМВтЪдЃЌЭЌЙ§дкВЛЭЌЕФХфжУЕФадФмВтЪдЃЌЕУЕНвЛИіЛљзМаХЯЂСаБэЃЌЕБШЛЃЌдкНјааетИіадФмВтЪдЕФЙ§ГЬжаЃЌЮвУЧвЊШЗЖЈгВМўЪЧЯЕЭГЕФЦПОБЁЃШчЙћжЛгУвЛИіCUPЃЌдкадФмВтЪдЙ§ГЬжаЃЌЦфЪЙгУТЪКмЕЭЃЌЕЋЕУЕНЕФадФмЪ§ОнЖМЗЧГЃЕзЃЌетЦ№ТыЫЕУїCUPВЛЪЧЯЕЭГЕФЦНОВЃЌетжжЧщПіЯТОЭЮоЗЈЕУЕНЯывЊЕФЛљзМжЕЁЃ
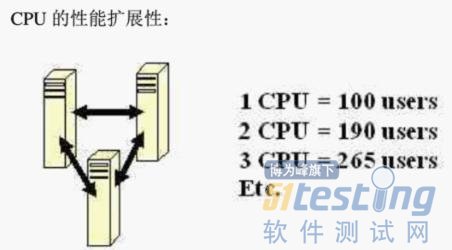
ЁЁЁЁШчЩЯЭМЃЌдквЛПХCPUЧщПіЯТЃЌдЫаа100ИігУЛЇЧвCUPЪЙгУТЪНгНќБЅКЭЃЈ100%ЃЉЁЃдкдіМгжССНПХCUPЕФЧщПіЯТЃЌПЩвддЫаа190ИігУЛЇЧвUPUЪЙгУТЪНгНќБЅКЭЃЈ100%ЃЉЃЌвдДЫзіМЧТМЃЌФЧУДЮвУЧОЭПЩвдЭЦЫуГідЫаа800ИігУЛЇашвЊЖрЩйПХCUPЁЃ
ЁЁЁЁШчЙћФудкЪЕМЪгІгУжаЪЙгУЕФCUPаЭКХМАЦфЦЕТЪВЂЗЧЭъШЋвЛбљЃЌетИіЪБКђПЩвдЪЙгУEVERESTЙЄОпМЦЫуУПжжCUPЕФЕУЗжЃЌЖдЦфадФмНјааЦРЙРЁЃ
ЁЁЁЁФкДцвВПЩвдЪЙгУДЫЗНЗЈНјааВтЪдЭЦЕМЃЌетРяашвЊЮвУЧЖрНјааЪдбщЃЌЖдгВМўЕФадФмвдМАЖдећИіЯюФПЕФНсЙЙЖМвЊзіЩюШыЕФСЫНтЃЌвдБуОЁСПМѕЩйЮѓВюЁЃ












