在一些情况下,如要查询数据中的几个字段,此时就有可能产生重复记录,而重复的记录是不符合规范的,数据表是现实世界的客观反映,因此,空值的产生是不可避免。
1、查询时不显示重复记录
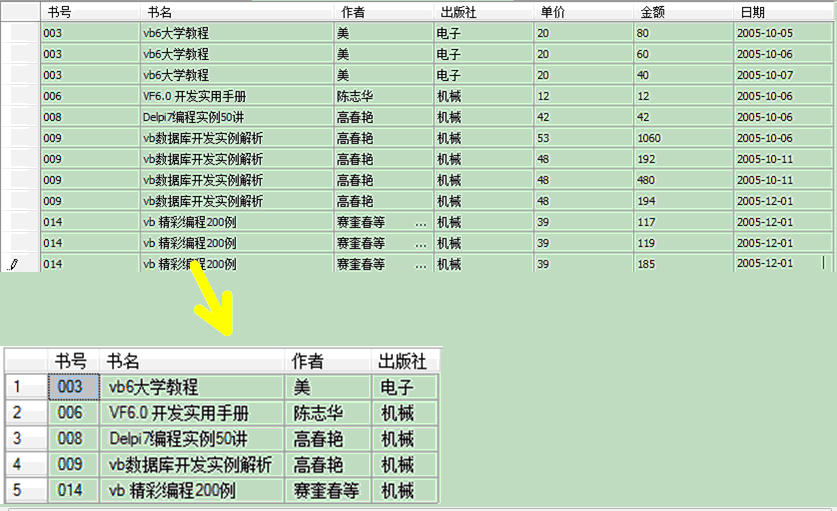
在实现查询操作时,如果查询的选择列表中包含一个表的主键,那么每个查询结果中的记录将是唯一的,如果主键不包含在查询结果中,就可能出现重复记录.使用Distinct关键字可以消除重复记录。
Distinct关键字可从SQL 语句结果中除去重复的行,如果没有指定DISTINCT关键字,那么将返回所有行,包括重复的行。
在使用DISTINCT关键字去除重复记录时,需将DISTINCT关键字放在第一个字段名之前。
DISTINCT的语法:Select [disinct|all]select_list
注意:
(1)在select列表中只能使用一次distinct关键字,不要在其后添加逗号。
(2)如果省略了distinct关键字,查询结果中不会消除重复的记录,也可以指定all关键字来明确保留重复记录,此项为默认的行为。
(3)distinct关键字并不是指某一行,而是指不重复select输出的所有列。
(4)distinct是sum,avg和count函数的可选关键字,如果使用distinct关键字,那么在计算总和,平均值或计数之前,先消除重复的值。
例如:显示不重复的内容
select distinct 书号,书名,作者,出版社 from tb_BookSell order by 书号
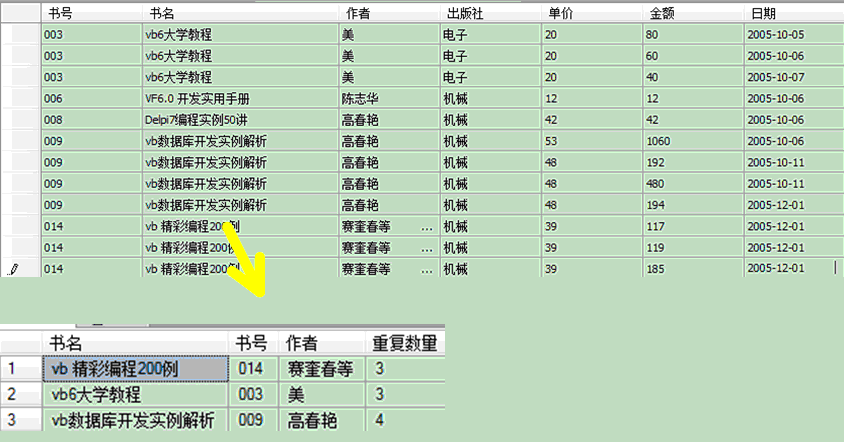
2、列出数据中的重复记录和记录条数
通过HAVING子句为组指定条件.通过作为一个整体的组指定条件,可限定查询中出现的组.在对数据进行分组和聚集后,将用到having 子句中的条件,中有符号条件的组才会出现在查询中。
例如:查询重复的书籍
select 书名,书号,作者,COUNT (书名) as 重复数量from tb_BookSell group by 书名,书号,作者 having count(书名)>=2