数据库开发者在存储过程和脚本中使用局部变量是很常见的事情,但是,局部变量会影响查询的性能,接下来我们来证实这一点。
首先让我们创建一个表并插入一些测试数据:
- USE AdventureWorks
- GO
- CREATE TABLE TempTable
- (tempID UNIQUEIDENTIFIER,tempMonth INT, tempDateTime DATETIME )
- GO
- INSERT INTO TempTable (tempID, tempMonth, tempDateTime)
- SELECT NEWID(),(CAST(100000*RAND() AS INT) % 12) + 1 ,GETDATE()
- GO 100000
-
- CREATE NONCLUSTERED INDEX [IX_tempDateTime] ON [dbo].[TempTable]
- ([tempDateTime] ASC)
- INCLUDE ( [tempID]) WITH ( ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
- GO
|
然后我们做一个简单的查询:
- SET STATISTICS IO ON
- GO
- SELECT * FROM TempTable
- WHERE tempDateTime > '2012-07-10 03:18:01.640'
|
Table 'TempTable'. Scan count 1, logical reads 80, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
检查这个执行计划以及索引检索的属性,你会发现预估行数是实际行数的两倍,但并不会太影响执行计划,因为优化器选择了最合适的查询方法:
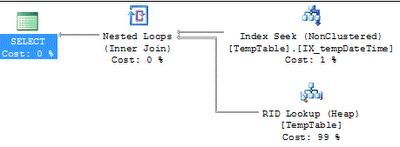

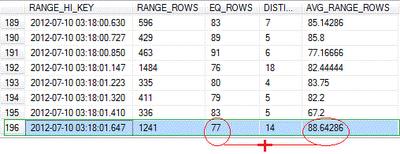
查询优化器根据基本统计直方图来预估数据行数,即:EQ_ROWS + AVG_RANGE_ROWS (77 + 88.64286) DBCC SHOW_STATISTICS ('dbo.TempTable', IX_tempDateTime)