

ЎЎЎЎЎ¶ұаіМЦйзбЎ·ЈЁөЪ¶ю°жЈ©Т»КйөЪЛДХВЦРМбј°№э100¶аГыЧЁТөіМРтФұК№УГБҪёцРЎКұөДідЧгКұјдұаРҙТ»ёцјтөҘөД¶ю·ЦІйХТіМРтЈ¬Ҫб№ы·ўПЦ90ЈҘөДИЛұаіцөДҙъВл¶јУРBUGЈ¬KnuthТІФЪЛыөДЎ¶Sorting and SearchingЎ·Т»КйЦРМб№эЈ¬өЪТ»ёц¶ю·ЦІйХТіМРтФЪ1946ДкТСҫӯ№«ІјЈ¬ө«КЗөҪБЛ1962ДкІЕіцПЦөЪТ»ёцГ»УРBUGөД¶ю·ЦІйХТіМРтЈ¬ЖЪјдҫӯАъБЛ16ДкөДКұјдЎЈДЗГҙОӘКІГҙТ»ёцјтөҘөД¶ю·ЦІйХТіМРт»бХвГҙИЭТЧіцҙнДШЈҝҝҙТ»ҝҙУРРтұнөДІйХТөДІвКФУГАэЙијЖТІРнДЬГч°ЧОӘКІГҙЎЈ
ЎЎЎЎТӘ¶ФУРРтұнІйХТҪшРРУГАэЙијЖЈ¬ОТГЗҝЙТФПИ·ЦОцКдИлУтЈ¬КөјКЙПУРБҪёцКдИлУтЈ¬Т»ёцКЗТӘІйХТөДКэҫЭЈ¬БнНвТ»ёцКЗУРРтұнЈ¬ҝЙТФПИ¶ФУРРтұнКэҫЭөДёцКэҪшРР·ЦАаЈ¬УРРтұнЦРҝЙДЬУР0Ј¬1Ј¬2Ј¬3Ј¬ЎӯёцКэҫЭЎЈТтҙЛОТГЗҝЙТФҪ«ДҝұкКэҫЭ·ЦОӘТФПВјёёцАаЈә

ЎЎЎЎНкіЙөЪ1ј¶·ЦАаәуЈ¬ОТГЗҝЙТФФЩ¶ФКэҫЭөДМШөгҪшРР·ЦАаЈ¬ТтОӘУРРтұнКЗТ»ёцУРЛіРтөДұнЈ¬КЗУРҙуРЎЛіРтөДЈ¬ТтҙЛҝЙТФёщҫЭКэҫЭМШөгФЩҪшРР·ЦАаЈ¬ТФ3ёцКэҫЭОӘАэҝЙТФҪшРРТФПВ·ЦАаЈә

ЎЎЎЎУРРтұнУР0Ўў1Ўў2Ўў4ёцТФЙПКэҫЭөДЗйҝц¶јҝЙТФ°ҙХХТФЙПөДАаЛЖөД·ҪКҪҪшРРФЩ·ЦАаЎЈөұ°ҙУРРтұнЦР·ЦАаәГәуЈ¬ҝЙТФФЩ°ҙТӘІйХТөДКэҫЭҪшРР·ЦАа

ЎЎЎЎөұ¶ФІйХТөДКэҫЭәНУРРтұн·Цұр·ЦәГАаәуЈ¬ҫНҝЙТФ°СХвБҪЦЦ·ЦАаЧйәПЖрАҙЈ¬ұИИзҪ«УРРтұнУР3ёцКэҫЭөД·ЦАаЗйҝцәНІйХТКэҫЭөД·ЦАаЗйҝцЧйәПЖрАҙҫНҝЙТФөГөҪТФПВөД·ЦАаЈә
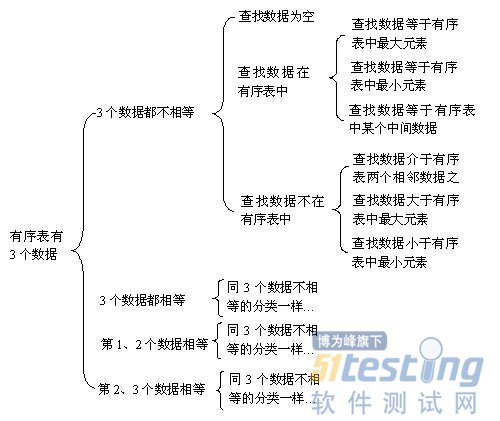
ЎЎЎЎЧйәПНкә󣬻№РиТӘҪ«Т»Р©І»ҝЙДЬ»тІ»РиТӘөДЧйәПЙҫіэөфЈ¬ұИИзФЪ3ёцКэҫЭ¶јПаөИөДЗйҝцПВЈ¬ІйХТКэҫЭҪйУЪјҜәПБҪёцПаБЪКэҫЭЦ®јдөДЗйҝцҫНІ»ҙжФЪЈ¬РиТӘЙҫіэөфХвЦЦЗйҝцЈ¬ІйХТКэҫЭФЪУРРтұнЦРөД3ЦЦ·ЦАаТІУЙУЪјҜәПЦРКэҫЭ¶јПаөИ¶шұдіЙБЛТ»ёц·ЦАаЈ¬ПВНјұгКЗ3ёцКэҫЭ¶јПаөИЗйҝцПВөДТ»ёц·ЦАаЈә













