3、乱码了还能恢复?
问题如下:
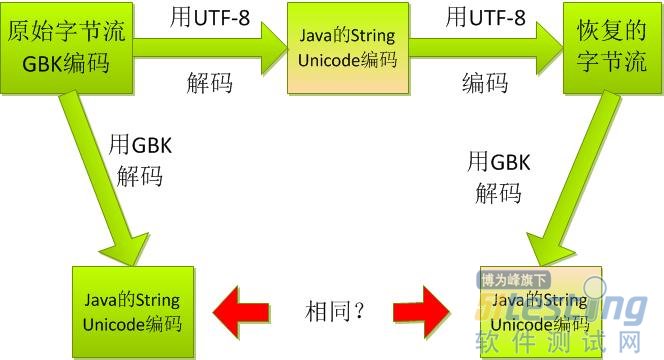
貌似图中的utf-8改成iso8859-1是可以的,utf-8在字符串中有中文时不行(但英文部分仍可正确解析)!!!毕竟GBK的字节流对于utf-8可能是无效的,碰到无效的字符怎么解析,是否可逆那可不好说啊。
测试代码如下:
- package tests;
-
- import java.io.UnsupportedEncodingException;
- import java.net.URLEncoder;
-
-
-
-
-
- public class TestEncoding {
- static String utf8 = "utf-8";
- static String iso = "iso-8859-1";
- static String gbk = "GBK";
-
- public static void main(String[] args) throws UnsupportedEncodingException {
- String str = "hi好啊me";
-
-
-
- System.out.println("原始字符串:\t\t\t\t\t\t" + str);
- String utf8_encoded = URLEncoder.encode(str, "utf-8");
- System.out.println("用URLEncoder.encode()方法,并用UTF-8编码后:\t\t" + utf8_encoded);
- String gbk_encoded = URLEncoder.encode(str, "GBK");
- System.out.println("用URLEncoder.encode()方法,并用GBK编码后:\t\t" + gbk_encoded);
- testEncoding(str, utf8, gbk);
- testEncoding(str, gbk, utf8);
- testEncoding(str, gbk, iso);
- printBytesInDifferentEncoding(str);
- printBytesInDifferentEncoding(utf8_encoded);
- printBytesInDifferentEncoding(gbk_encoded);
- }
-
-
-
-
-
-
-
-
-
-
-
-
- public static void testEncoding(String str, String encodingTrue,
- String encondingMidian) throws UnsupportedEncodingException {
- System.out.println();
- System.out
- .printf("%s编码的字节数据->用%s解码并转为Unicode编码的JavaString->用%s解码变为字节流->读入Java(用%s解码)后变为Java的String\n",
- encodingTrue, encondingMidian, encondingMidian,
- encodingTrue);
- System.out.println("原始字符串:\t\t" + str);
- byte[] trueEncodingBytes = str.getBytes(encodingTrue);
- System.out.println("原始字节流:\t\t" + bytesToHexString(trueEncodingBytes)
- + "\t\t//即用" + encodingTrue + "编码后的字节流");
- String encodeUseMedianEncoding = new String(trueEncodingBytes,
- encondingMidian);
- System.out.println("中间字符串:\t\t" + encodeUseMedianEncoding + "\t\t//即用"
- + encondingMidian + "解码原始字节流后的字符串");
- byte[] midianBytes = encodeUseMedianEncoding.getBytes("Unicode");
- System.out.println("中间字节流:\t\t" + bytesToHexString(midianBytes)
- + "\t\t//即中间字符串对应的Unicode字节流(和Java内存数据一致)");
- byte[] redecodedBytes = encodeUseMedianEncoding
- .getBytes(encondingMidian);
- System.out.println("解码字节流:\t\t" + bytesToHexString(redecodedBytes)
- + "\t\t//即用" + encodingTrue + "解码中间字符串(流)后的字符串");
- String restored = new String(redecodedBytes, encodingTrue);
- System.out.println("解码字符串:\t\t" + restored + "\t\t和原始数据相同? "
- + restored.endsWith(str));
- }
-
-
-
-
-
-
-
- public static void printBytesInDifferentEncoding(String str)
- throws UnsupportedEncodingException {
- System.out.println("");
- System.out.println("原始String:\t\t" + str + "\t\t长度为:" + str.length());
- String unicodeBytes = bytesToHexString(str.getBytes("unicode"));
- System.out.println("Unicode bytes:\t\t" + unicodeBytes);
- String gbkBytes = bytesToHexString(str.getBytes("GBK"));
- System.out.println("GBK bytes:\t\t" + gbkBytes);
- String utf8Bytes = bytesToHexString(str.getBytes("utf-8"));
- System.out.println("UTF-8 bytes:\t\t" + utf8Bytes);
- String iso8859Bytes = bytesToHexString(str.getBytes("iso-8859-1"));
- System.out.println("iso8859-1 bytes:\t" + iso8859Bytes + "\t\t长度为:"
- + iso8859Bytes.length() / 3);
- System.out.println("可见Unicode在之前加了两个字节FE FF,之后则每个字符两字节");
- }
-
-
-
-
-
-
-
-
- public static final String bytesToHexString(byte[] bytes) {
- StringBuilder sb = new StringBuilder(bytes.length * 2);
- for (int i = 0; i < bytes.length; i++) {
- String hex = Integer.toHexString(bytes[i] & 0xff);
- if (hex.length() == 1)
- sb.append('0');
- sb.append(hex);
- sb.append(" ");
- }
- return sb.toString().toUpperCase();
- }
- }
|













