

ЎЎЎЎ3ЎўTeraSortөДФӯАн
ЎЎЎЎБЛҪвБЛОТГЗРиТӘЕЕРтөДКдИлКэҫЭКЗКІГҙСщБЛЈ¬ҪУПВАҙАҙБЛҪвTeraSortЎЈ
ЎЎЎЎФЛРРTeraSortөДГьБоКЗХвСщөДЈә
| $ bin/hadoop jar hadoop-0.19.2-examples.jar terasort /terasort/input1TB /terasort/output1TB |
ЎЎЎЎФЛРРәуЈ¬ОТГЗҝЙТФҝҙөҪ»бЖрmёцmapperЈЁИЎҫцУЪКдИлОДјюёцКэЈ©әНrёцreducerЈЁИЎҫцУЪЙиЦГПоЈәmapred.reduce.tasksЈ©Ј¬ЕЕәГРтөДҪб№ыҙж·ЕФЪ/terasort/output1TBДҝВјЎЈ
ЎЎЎЎІйҝҙTeraSortөДФҙҙъВлЈ¬Дг»б·ўПЦХвёцЧчТөН¬КұГ»УРЙиЦГmapperәНreducerЈ»ТІҫНКЗТвО¶ЧЕЛьК№УГБЛHadoopД¬ИПөДIdentityMapperәНIdentityReducerЎЈIdentityMapperәНIdentityReducer¶ФЛьГЗөДКдИлІ»ЧцИОәОҙҰАнЈ¬Ҫ«КдИлkЈ¬vЦұҪУКдіцЈ»ТІҫНКЗЛөКЗНкИ«КЗОӘБЛЧЯҝтјЬөДБчіМ¶шҝХЕЬЎЈ
ЎЎЎЎХвХэКЗHadoopөДTeraSortөДЗЙГоЛщФЪЈ¬ЛьГ»УРОӘЕЕРт¶шКөПЦЧФјәөДmapperәНreducerЈ¬¶шКЗНкИ«АыУГHadoopөДMap ReduceҝтјЬДЪөД»ъЦЖКөПЦБЛЕЕРтЎЈ
ЎЎЎЎОТГЗРиТӘПИАҙБЛҪвПВHadoopөДMap Reduce№эіМЈ¬ПВНјҪПЗеіюөДЛөГчБЛХвёц№эіМЎЈ
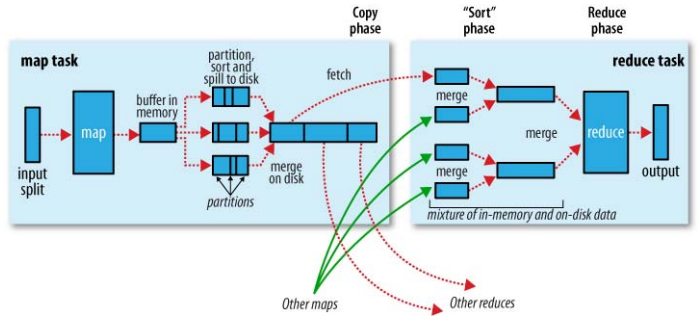
ЈЁХвёцНј·ЗіЈҫӯөдЈ¬ҪШЧФЈәHadoopЈәThe Definitive GuideЈ©
ЎЎЎЎЗЎәГіГХвёц»ъ»бЈ¬°СЧФјә¶ФMapReduce№эіМөДАнҪвјтТӘөДХыАнТ»ПВЈә
ЎЎЎЎЎс Т»°гЗйҝцПВЈ¬ЧчТө»бРиТӘЦё¶ЁinputДҝВјәНoutputДҝВј
ЎЎЎЎЎс ЧчТөөДMapperёщҫЭЙиЦГөДInputFormatАҙҙУinputДҝВј¶БИЎКдИлКэҫЭЈ¬·ЦіЙ¶аёцsplitsЈ» ГҝТ»ёцsplitҪ»ёшТ»ёцmapperҙҰАн
ЎЎЎЎЎс mapperөДКдіц»б°ҙХХpartions·ЦЧйЈ¬ГҝТ»ёцpartion¶ФУҰЧЕТ»ёцreducerөДКдИлЈ» ФЪГҝёцpartionДЪЈ¬»бУРТ»ёц°ҙkeyЕЕРтөД№эіМЈ¬ТІҫНКЗЛөЈ¬ГҝТ»ёцpartionДЪөДКэҫЭКЗУРРтөДЎЈ
ЎЎЎЎЎс өұҙҰАнНкcombinerәНС№ЛхәуЈЁИз№ыУРЙиЦГЈ©Ј¬mapөДКдіц»бРҙөҪУІЕМЙПЎЈmapҪбКшәуЈ¬ЛщФЪөДTT»бФЪПВТ»ёцРДМшНЁЦӘөҪJTЎЈ
ЎЎЎЎЎс ГҝТ»ёцreducerІйСҜJTБЛҪвөҪКфУЪЧФјә¶ФУҰpartitionөДmapoutputКэҫЭөД¶ФУҰөДTTО»ЦГЈ¬И»әуИҘДЗcopyөҪұҫөШЈЁHTTPРӯТйЈ©ЎЈ
ЎЎЎЎЎс CopyІўұЈҙжөҪұҫөШҙЕЕМөД№эіМН¬mapper¶ЛөДКдіцұЈҙж№эіМ·ЗіЈПаЛЖЎЈөИөҪreducer»сИЎөҪКфУЪЛьөДЛщУРmapoutputКэҫЭәуЈ¬Ль»бұЈіЦЦ®З°mapper¶ЛөДsortЛіРтЈ¬°СХвР©mapoutputәПІўіЙҪПјҜЦРөДЦРјдОДјюЈЁёцКэИЎҫцУЪКэҫЭҙуРЎәНЙиЦГЈ©ЎЈОӘБЛҪЪКЎioөДҝӘПъЈ¬merge»бұЈЦӨЧоәуТ»ВЦКЗВъёәәЙәПІўЈ»ІўЗТЈ¬mergeөДЧоәуТ»ВЦКдіц»бЦұҪУФЪДЪҙжКдИлёшreducerЎЈ
ЎЎЎЎЎс reducerөДКдіц°ҙХХOutputFormatАҙұЈҙжөҪoutputДҝВјЎЈ
ЎЎЎЎИз№ыОТГЗЧўТвөҪЙПКц№эіМөДА¶Й«јУҙЦІҝ·ЦЈ¬ҫНҝЙТФІВІвөҪTeraSortКЗИзәОАыУГhadoopөДmap reduce»ъЦЖАҙҙпөҪЕЕРтДҝөДөДЎЈ»тРнОТГЗҝЙТФ»іТЙЈ¬hadoopөДMap Reduce»ъЦЖҫНКЗОӘБЛTeraSort¶шЙијЖөДЈ¬ЈәЈ© ЎЈ
ЎЎЎЎјИИ»HadoopҝЙТФұЈЦӨГҝТ»ёцpartitionДЪөДКэҫЭУРРтЈ¬TeraSortЦ»РиТӘЧцТ»јюКВЗйЈәұЈЦӨpartitionЦ®јдТІКЗУРРтөДЎЈ












