

ЁЁЁЁвЛЁЂSeleniumМђНщ
ЁЁЁЁ1ЁЂЪВУДЪЧseleniumЃП
ЁЁЁЁЃЈ2ЃЉSelenium ВтЪджБНгдЫаадкфЏРРЦїжаЃЌОЭЯёеце§ЕФгУЛЇдкВйзївЛбљЁЃ
ЁЁЁЁЃЈ3ЃЉжЇГжЭЈЙ§ИїжжdriverЃЈFirfoxDriverЃЌIternetExplorerDriverЃЌOperaDriverЃЌChromeDriverЃЉЧ§ЖЏецЪЕфЏРРЦїЭъГЩВтЪдЁЃ
ЁЁЁЁЃЈ4ЃЉseleniumвВЪЧжЇГжЮоНчУцфЏРРЦїВйзїЕФЁЃ
ЁЁЁЁФЃФтфЏРРЦїЙІФмЃЌздЖЏжДааЭјвГжаЕФjsДњТыЃЌЪЕЯжЖЏЬЌМгдиЁЃ
ЁЁЁЁ2ЁЂЮЊЪВУДЪЙгУselenium
ЁЁЁЁЮвУЧДђПЊОЉЖЋЃЌПДЕНгавЛИіУыЩБЕФФЃПщЃЌДгЭјвГдДТыжавВПЩвдЖЈЮЛЕНЃК
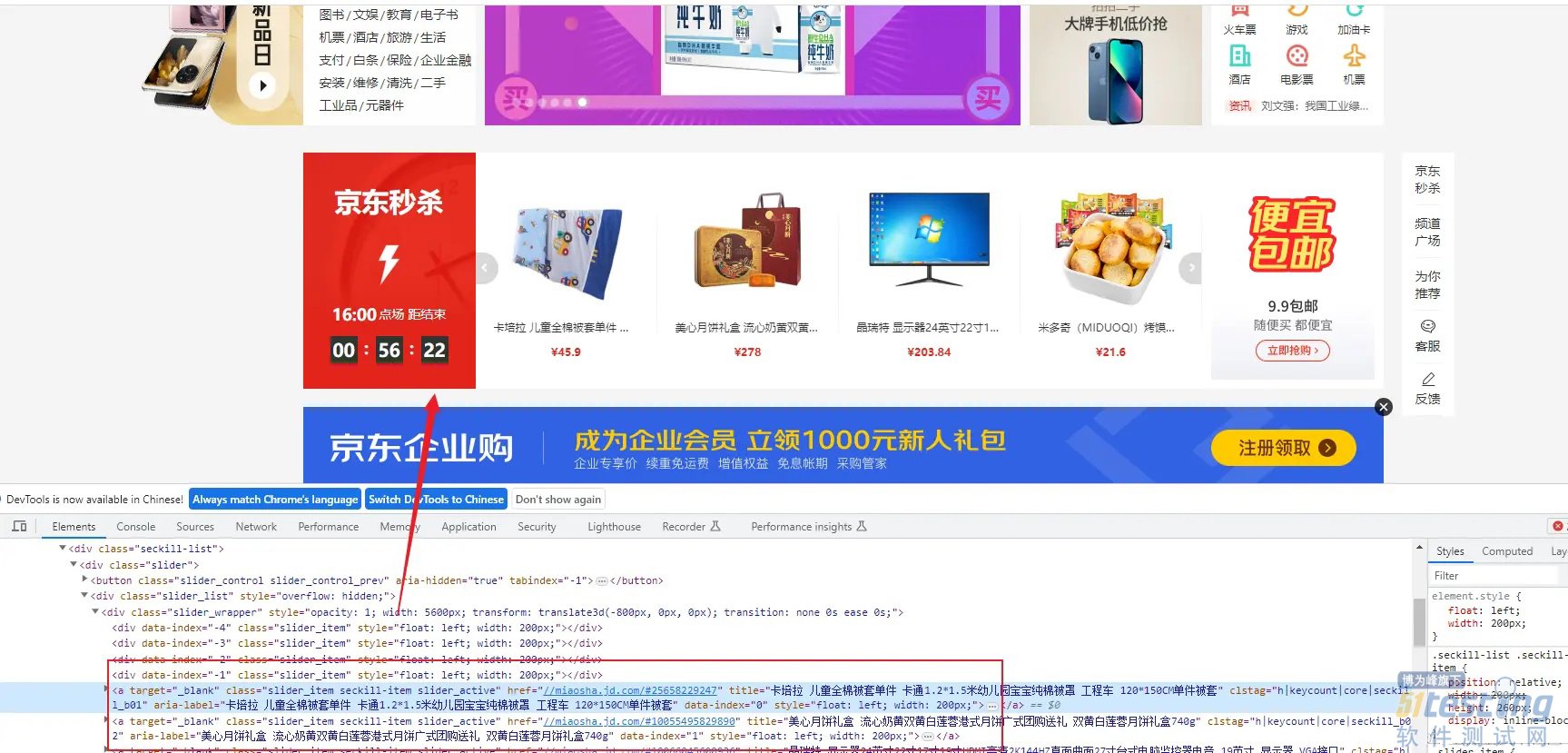
ЁЁЁЁЕЋЪЧЮвУЧЪЙгУurllibХРШЁЃК
ЁЁЁЁimport urllib.request
ЁЁЁЁurl = 'https://www.jd.com/'
ЁЁЁЁurllib.request.urlretrieve(url,'jd.html')
ЁЁЁЁХРШЁЕФЭјвГЃЌЮвУЧШЋОжЫбЫїЗЂЯжЃЌВЂУЛгаУыЩБетВПЗжФкШнЁЃ
ЁЁЁЁвђЮЊУыЩБетВПЗжФкШнЃЌЪЧдкjsжаЖЏЬЌМгдиЕФЃЌЖјseleniumОЭПЩвдФЃФтфЏРРЦїЙІФмЃЌздЖЏжДааЭјвГжаЕФjsДњТыЃЌЪЕЯжЖЏЬЌМгдиЁЃ
ЁЁЁЁ3ЁЂАВзАselenium
ЁЁЁЁЃЈ1ЃЉЙШИшфЏРРЦїЧ§ЖЏЯТдиАВзА
ЁЁЁЁВщПДЙШИшфЏРРЦїЕФАцБОЃКАяжњ->Йигкgoogle chromeЃЌВщПДАцБОЁЃ
ЁЁЁЁИљОнАцБОВщевЖдгІЕФchromedriverЃЌДѓАцБОЖдгІОЭПЩвдЃЌаЁАцБОВЛашвЊЙиаФЃЌЯТдиЕижЗЃЈЕквЛИіЭјЫйБШНЯТ§ЃЉЃЌ32ЮЛКЭ64ЮЛЖМФмгУЃК
ЁЁЁЁhttp://chromedriver.storage.googleapis.com/index.html
ЁЁЁЁhttps://registry.npmmirror.com/binary.html?path=chromedriver/
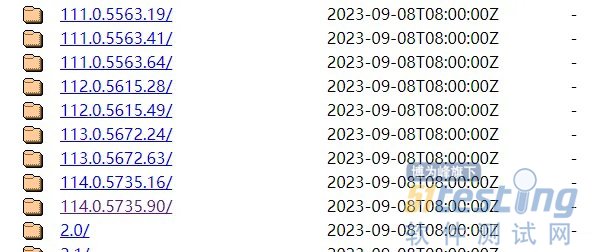
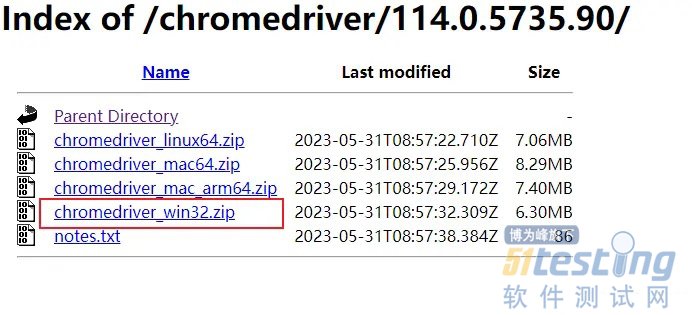
ЁЁЁЁШчЙћЪЧзюаТАцЕФЙШИшфЏРРЦїЃЌвдЩЯПЩФмУЛгаЭЌВНИќаТЃЌЪдЪдЯТУцЕФЭјеОЃК
ЁЁЁЁhttps://googlechromelabs.github.io/chrome-for-testing/
ЁЁЁЁЯТдижЎКѓЪЧвЛИібЙЫѕЮФМўЁЃ

ЁЁЁЁНЋНтбЙГіРДЕФexeЮФМўЃЌЗХЕНpythonЯюФПЕФИљФПТМЯТЃЈЮЊСЫЗНБуЪЙгУЃЌВЛетбљзіЕФЛАЃЌЪЙгУЪБжИЖЈТЗОЖвВПЩЃЉЁЃ
ЁЁЁЁЃЈ2ЃЉАВзАselenium
ЁЁЁЁ# НјШыЕНpythonАВзАФПТМЕФScriptsФПТМ
ЁЁЁЁd:
ЁЁЁЁcd D:\python\Scripts
ЁЁЁЁ# АВзА
ЁЁЁЁpip install selenium -i https://pypi.douban.com/simple
ЁЁЁЁЖўЁЂSeleniumЪЙгУ
ЁЁЁЁ1ЁЂМђЕЅЪЙгУ
ЁЁЁЁМђЕЅШ§ВНЃЌЧсЫЩЪЙгУЃЌЛёШЁЭјвГЕФШЋВПФкШнЃЈЭјвГЭъШЋМгдиЭъБЯжЎКѓЕФЃЉЁЃ
ЁЁЁЁ# ЃЈ1ЃЉЕМШыselenium
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁ# (2) ДДНЈфЏРРЦїВйзїЖдЯѓЃЌОЭЪЧжИЖЈЮвУЧЧ§ЖЏЕФТЗОЖ
ЁЁЁЁpath = 'chromedriver.exe'
ЁЁЁЁbrowser = webdriver.Chrome(path)
ЁЁЁЁ# ЃЈ3ЃЉЗУЮЪЭјеО
ЁЁЁЁurl = 'https://www.jd.com/'
ЁЁЁЁbrowser.get(url)
ЁЁЁЁ# page_sourceЛёШЁЭјвГдДТы
ЁЁЁЁcontent = browser.page_source
ЁЁЁЁwith open('jd.html','w',encoding='utf-8') as fp:
ЁЁЁЁ fp.write(content)
ЁЁЁЁ2ЁЂдЊЫиЖЈЮЛ
ЁЁЁЁдЊЫиЖЈЮЛЃКздЖЏЛЏвЊзіЕФОЭЪЧФЃФтЪѓБъКЭМќХЬРДВйзїРДВйзїетаЉдЊЫиЃЌЕуЛїЁЂЪфШыЕШЕШЁЃВйзїетаЉдЊЫиЧАЪзЯШвЊевЕНЫќУЧЃЌWebDriverЬсЙЉКмЖрЖЈЮЛдЊЫиЕФЗНЗЈЁЃ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.common.by import By
ЁЁЁЁpath = 'chromedriver.exe'
ЁЁЁЁbrowser = webdriver.Chrome(path)
ЁЁЁЁurl = 'https://www.baidu.com'
ЁЁЁЁbrowser.get(url)
ЁЁЁЁ# дЊЫиЖЈЮЛ
ЁЁЁЁ# ИљОнidРДевЕНЖдЯѓ id = su
ЁЁЁЁbutton = browser.find_element(by = By.ID, value = 'su')
ЁЁЁЁprint(button)
ЁЁЁЁ# ИљОнБъЧЉЪєадЕФЪєаджЕРДЛёШЁЖдЯѓЕФ name = wd
ЁЁЁЁbutton = browser.find_element(by = By.NAME, value = 'wd')
ЁЁЁЁprint(button)
ЁЁЁЁ# ИљОнxpathгяОфРДЛёШЁЖдЯѓ xpathгяЗЈ
ЁЁЁЁbutton = browser.find_element(by = By.XPATH, value = '//input[@id="su"]')
ЁЁЁЁprint(button)
ЁЁЁЁ# ИљОнБъЧЉЕФУћзжРДЛёШЁЖдЯѓ
ЁЁЁЁbutton = browser.find_element(by = By.TAG_NAME, value = 'input')
ЁЁЁЁprint(button)
ЁЁЁЁ# ЪЙгУЕФbs4ЕФгяЗЈРДЛёШЁЖдЯѓ
ЁЁЁЁbutton = browser.find_element(by = By.CSS_SELECTOR, value = '#su')
ЁЁЁЁprint(button)
ЁЁЁЁ# ЛёШЁСДНгЮФБО
ЁЁЁЁbutton = browser.find_element(by = By.LINK_TEXT, value = 'АйЖШвЛЯТ')
ЁЁЁЁprint(button)
ЁЁЁЁByВЮЪ§ АќКЌаэЖрПЩбЁЕФбЁЯюЃК

ЁЁЁЁ3ЁЂЛёШЁдЊЫиаХЯЂ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.common.by import By
ЁЁЁЁpath = 'chromedriver.exe'
ЁЁЁЁbrowser = webdriver.Chrome(path)
ЁЁЁЁurl = 'http://www.baidu.com'
ЁЁЁЁbrowser.get(url)
ЁЁЁЁinput = browser.find_element(by = By.ID, value = 'su')
ЁЁЁЁ# ЛёШЁБъЧЉЕФЪєад ЛёШЁclassЪєад
ЁЁЁЁprint(input.get_attribute('class'))
ЁЁЁЁ# ЛёШЁБъЧЉЕФУћзж
ЁЁЁЁprint(input.tag_name)
ЁЁЁЁ# ЛёШЁдЊЫиЮФБО
ЁЁЁЁa = browser.find_element(by = By.LINK_TEXT, value = 'аТЮХ')
ЁЁЁЁprint(a.text)
ЁЁЁЁ4ЁЂНЛЛЅ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.common.by import By
ЁЁЁЁ# ДДНЈфЏРРЦїЖдЯѓ
ЁЁЁЁpath = 'chromedriver.exe'
ЁЁЁЁbrowser = webdriver.Chrome(path)
ЁЁЁЁ# url
ЁЁЁЁurl = 'https://www.baidu.com'
ЁЁЁЁbrowser.get(url)
ЁЁЁЁ# анУп2Уы
ЁЁЁЁimport time
ЁЁЁЁtime.sleep(2)
ЁЁЁЁ# ЛёШЁЮФБОПђЕФЖдЯѓ
ЁЁЁЁinput = browser.find_element(by = By.ID, value = 'kw')
ЁЁЁЁ# дкЮФБОПђжаЪфШыжмНмТз
ЁЁЁЁinput.send_keys('жмНмТз')
ЁЁЁЁtime.sleep(2)
ЁЁЁЁ# ЛёШЁАйЖШвЛЯТЕФАДХЅ
ЁЁЁЁbutton = browser.find_element(by = By.ID, value = 'su')
ЁЁЁЁ# ЕуЛїАДХЅ
ЁЁЁЁbutton.click()
ЁЁЁЁtime.sleep(2)
ЁЁЁЁ# ЛЌЕНЕзВП
ЁЁЁЁjs_bottom = 'document.documentElement.scrollTop=100000'
ЁЁЁЁbrowser.execute_script(js_bottom)
ЁЁЁЁtime.sleep(2)
ЁЁЁЁ# ЛёШЁЯТвЛвГЕФАДХЅ
ЁЁЁЁnext = browser.find_element(by = By.XPATH, value = '//a[@class="n"]')
ЁЁЁЁ# ЕуЛїЯТвЛвГ
ЁЁЁЁnext.click()
ЁЁЁЁtime.sleep(2)
ЁЁЁЁ# ЛиЕНЩЯвЛвГ
ЁЁЁЁbrowser.back()
ЁЁЁЁtime.sleep(2)
ЁЁЁЁ# ЛиШЅ
ЁЁЁЁbrowser.forward()
ЁЁЁЁtime.sleep(3)
ЁЁЁЁ# ЭЫГі
ЁЁЁЁbrowser.quit()
ЁЁЁЁШ§ЁЂPhantomjsЪЙгУЃЈЭЃИќЃЉ
ЁЁЁЁ1ЁЂЪВУДЪЧPhantomjs
ЁЁЁЁЃЈ1ЃЉЪЧвЛИіЮоНчУцЕФфЏРРЦї
ЁЁЁЁЃЈ2ЃЉжЇГжвГУцдЊЫиВщевЃЌjsЕФжДааЕШ
ЁЁЁЁЃЈ3ЃЉгЩгкВЛНјааcssКЭguiфжШОЃЌдЫаааЇТЪвЊБШецЪЕЕФфЏРРЦївЊПьКмЖр
ЁЁЁЁPhantomjsвбОЙ§ЪБСЫЃЌЭЦМіЪЙгУChrome handlessЃЌИпАцБОЕФSeleniumвбОВЛжЇГжPhantomjsСЫ
ЁЁЁЁ2ЁЂЯТди
ЁЁЁЁЙйЭјЃКhttp://wenku.kuryun.com/docs/phantomjs/download.html

ЁЁЁЁНЋЯТдиЕФphantomjs.exeЮФМўПНБДЕНЯюФПФПТМЃЈЮЊСЫЗНБуЪЙгУЃЌВЛетбљзіЕФЛАЃЌЪЙгУЪБжИЖЈТЗОЖвВПЩЃЉЁЃ
ЁЁЁЁ3ЁЂЪЙгУPhantomjs
ЁЁЁЁЃЈ1ЃЉЛёШЁPhantomJS.exeЮФМўТЗОЖpath
ЁЁЁЁЃЈ2ЃЉbrowser = webdriver.PhantomJS(path)
ЁЁЁЁЃЈ3ЃЉbrowser.get(url)
ЁЁЁЁРЉеЙЃКБЃДцЦСФЛПьее:browser.save_screenshot(ЁЎbaidu.pngЁЏ)
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁpath = 'phantomjs.exe'
ЁЁЁЁbrowser = webdriver.PhantomJS(path)
ЁЁЁЁurl = 'https://www.baidu.com'
ЁЁЁЁbrowser.get(url)
ЁЁЁЁ# БЃДцПьее
ЁЁЁЁbrowser.save_screenshot('baidu.png')
ЁЁЁЁimport time
ЁЁЁЁtime.sleep(2)
ЁЁЁЁ# зюаТАцseleniumВЛжЇГжИУгяЗЈ
ЁЁЁЁinput = browser.find_element_by_id('kw')
ЁЁЁЁinput.send_keys('РЅСш')
ЁЁЁЁtime.sleep(3)
ЁЁЁЁbrowser.save_screenshot('kunling.png')
ЁЁЁЁЫФЁЂChrome handlessЮоНчУцФЃЪН
ЁЁЁЁ1ЁЂМђНщ
ЁЁЁЁChrome-headless ФЃЪНЃЌ Google еыЖд Chrome фЏРРЦї 59Ац аТдіМгЕФвЛжжФЃЪНЃЌПЩвдШУФуВЛДђПЊUIНчУцЕФЧщПіЯТЪЙгУ Chrome фЏРРЦїЃЌЫљвддЫаааЇЙћгы Chrome БЃГжЭъУРвЛжТЃЌадФмИќИпЁЃ
ЁЁЁЁЯЕЭГвЊЧѓЃК
ЁЁЁЁChromeЃКUnix\Linux ЯЕЭГашвЊ chrome >= 59ЁЂWindows ЯЕЭГашвЊ chrome >= 60
ЁЁЁЁPython3.6 +
ЁЁЁЁSelenium3.4.* +
ЁЁЁЁChromeDriver2.31 +
ЁЁЁЁ2ЁЂЛљБОЪЙгУ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.chrome.options import Options
ЁЁЁЁdef share_browser():
ЁЁЁЁ '''
ЁЁЁЁ ИУЗНЗЈЕФФкШнЃЌЖМВЛашвЊЖЏЃЌжЛашвЊаоИФздМКЕФchromeфЏРРЦїТЗОЖ
ЁЁЁЁ '''
ЁЁЁЁ chrome_options = Options()
ЁЁЁЁ chrome_options.add_argument('--headless')
ЁЁЁЁ chrome_options.add_argument('--disable-gpu')
ЁЁЁЁ # pathЪЧФуздМКЕФchromeфЏРРЦїЕФЮФМўТЗОЖ
ЁЁЁЁ path = r'C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe'
ЁЁЁЁ chrome_options.binary_location = path
ЁЁЁЁ browser = webdriver.Chrome(chrome_options=chrome_options)
ЁЁЁЁ return browser
ЁЁЁЁbrowser = share_browser()
ЁЁЁЁurl = 'https://www.baidu.com'
ЁЁЁЁbrowser.get(url)
ЁЁЁЁbrowser.save_screenshot('baidu.png')
ЁЁЁЁБОЮФФкШнВЛгУгкЩЬвЕФПЕФЃЌШчЩцМАжЊЪЖВњШЈЮЪЬтЃЌЧыШЈРћШЫСЊЯЕ51TestingаЁБр(021-64471599-8017)ЃЌЮвУЧНЋСЂМДДІРэ












