

一、Woven Planet(丰田子公司)的方案:Urban Driver 2021
这篇文章是21年的,但一大堆新文章都拿它来做对比基线,因此应该也有必要来看看方法。
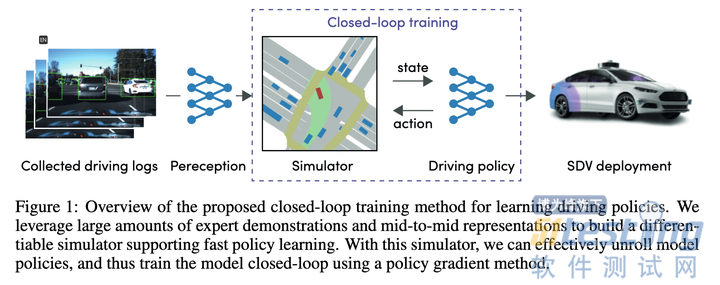

大概看了下,主要就是用Policy Gradients学习State->近期action的映射函数,有了这个映射函数,可以一步步推演出整个执行轨迹,最后loss就是让这个推演给出的轨迹尽可能的接近专家轨迹。
效果应该当时还不错,因此能成为各家新算法的基线。
二、南洋理工大学方案一 Conditional Predictive Behavior Planning with Inverse Reinforcement Learning 2023.04
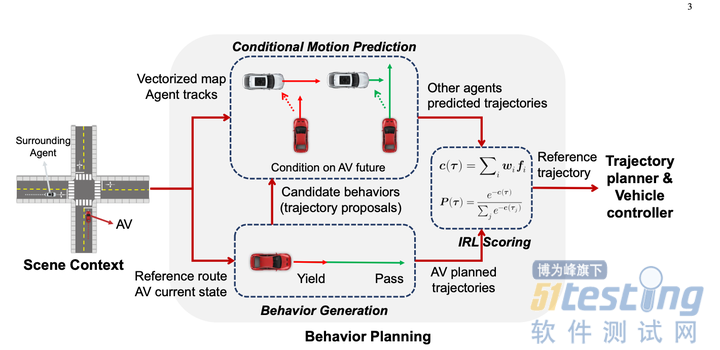
先使用规则枚举了多种行为,生成了10~30条轨迹。(未使用预测结果)
使用Condtional Prediction算出每条主车待选轨迹情况下的预测结果,然后使用IRL对待选轨迹打分。
其中Conditional Joint Prediction模型长这样:

这个方法基本上很赞的点就是利用了Conditional Joint Prediction可以很好的完成交互性的预测,使得算法有一定的博弈能力。
但我个人认为算法缺点是前边只生成了10~30条轨迹,而且轨迹生成时没考虑预测,而且最后会直接在IRL打分后,直接选用这些轨迹中的一条作为最终结果,比较容易出现10~30条在考虑预测后发现都不大理想的情况。相当于要在瘸子里边挑将军,挑出来的也还是瘸子。基于这个方案,再解决前边待选样本生成质量会是很不错的路子
三、英伟达方案:2023.02 Tree-structured Policy Planning with Learned Behavior Models
用规则树状采样,一层一层的往后考虑,对每一层的每个子结点都生成一个conditional prediction,然后用规则对prediction结果和主车轨迹打分,并用一些规则把不合法的干掉,然后,利用DP往后生成最优轨迹,DP思路有点类似于apollo里dp_path_optimizer,不过加了一个时间维度。
不过因为多了一个维度,这个后边扩展次数多了之后,还是会出现解空间很大计算量过大的情况,当前论文里写的方法是到节点过多之后,随机丢弃了一些节点来确保计算量可控(感觉意思是节点过多之后可能也是n层之后了,可能影响比较小了)
本文主要贡献就是把一个连续解空间通过这种树形采样规则转变一个马尔可夫决策过程,然后再利用dp求解。
四、南洋理工大学&英伟达联合 2023年10月最新方案:DTPP: Differentiable Joint Conditional Prediction and Cost Evaluation for Tree Policy Planning in Autonomous Driving
看标题就感觉很Exciting:
一、Conditional Prediction确保了一定博弈效果
二、可导,能够整个梯度回传,让预测与IRL一起训练。也是能拼出一个端到端自动驾驶的必备条件
三、Tree Policy Planning,可能有一定的交互推演能力
仔细看完,发现这篇文章信息含量很高,方法很巧妙。

主要基于英伟达的TPP和南洋理工的Conditional Predictive Behavior Planning with Inverse Reinforcement Learning进行糅合改进,很好的解决了之前南洋理工论文中待选轨迹不好的问题。
论文方案主要模块有:
一、Conditional Prediction模块,输入一条主车历史轨迹+提示轨迹 + 障碍车历史轨迹,给出主车接近提示轨迹的预测轨迹和与主车行为自洽的障碍车的预测轨迹。
二、打分模块,能够给一个主车+障碍车轨迹打分看这个轨迹是否像专家的行为,学习方法是IRL。
三、Tree Policy Search模块,用来生成一堆待选轨迹
使用Tree Search的方案来探索主车的可行解,探索过程中每一步都会把已经探索出来的轨迹作为输入,使用Conditional Prediction来给出主车和障碍车的预测轨迹,然后再调用打分模块评估轨迹的好坏,从而影响到下一步搜索扩展结点的方向。通过这种办法可以得到一些差异比较大的主车轨迹,并且轨迹生成时已经随时考虑了与障碍车的交互。
传统的IRL都是人工搞了一大堆的feature,如前后一堆障碍物在轨迹时间维度上的各种feature(如相对s, l和ttc之类的),本文里为了让模型可导,则是直接使用prediction的ego context MLP生成一个Weight数组(size = 1 * C),隐式表征了主车周围的环境信息,然后又用MLP直接接把主车轨迹+对应多模态预测结果转成Feature数组(size = C * N, N指的待选轨迹数),然后两个矩阵相乘得到最终轨迹打分。然后IRL让专家得分最高。个人感觉这里可能是为了计算效率,让decoder尽可能简单,还是有一定的主车信息丢失,如果不关注计算效率,可以用一些更复杂一些的网络连接Ego Context和Predicted Trajectories,应该效果层面会更好?或者如果放弃可导性,这里还是可以考虑再把人工设置的feature加进去,也应该可以提升模型效果。
在耗时方面,该方案采用一次重Encode + 多次轻量化Decode的方法,有效降低了计算时延,文中提到时延可以压到98ms。
在learning based planner中属于SOTA行列,闭环效果接近前一篇文章中提到的nuplan 排第一的Rule Based方案PDM。
总结
看下来,感觉这么个范式是挺不错的思路,中间具体过程可以自己想办法调整:
1. 用预测模型指导一些规则来生成一些待选ego轨迹。
2. 对每条轨迹,用Conditional Joint Prediction做交互式预测,生成agent预测。可以提升博弈性能。
3. IRL等方法做利用Conditional Joint Prediction结果对前边的主车轨迹打分,选出最优轨迹。

本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












