

接下来,我们将分几篇文章来实现对图书的增删改查功能,主要的功能如下:
1.增:新增图书信息
2.删:图书下架
3.改:图书信息的修改
4.查:图书信息的获取
而在本篇中主要介绍图书信息的采集和展示,也就是增删改查中的查询功能。需要实现以下功能的开发:
1.豆瓣图书的爬取和存储
2.豆瓣图书展示功能的前端实现
3.豆瓣图书展示功能的后端实现
4.豆瓣图书展示功能的前端修改
(一). 你愿意手动造“轮子”吗?
首先来思考个问题,如果你是一个测试开发,某天要实现这样一个常规的功能,你会按部就班的手动去写代码吗?对于日常开发来说,时间无疑是非常紧迫的,在这样一个环境下,能手动拷贝的就不要手动去敲,所以正如我上文说的那样,能做CV工程师就做CV工程师,把更多的时间腾出来实现更具挑战性的工作。
我们选择去网上找,如果你打开gitee或者github,会看到非常多的豆瓣爬虫项目,这里面的选择空间很大,根据开发语言、star、以及你最终想要实现的效果来筛选,就让我们一步步开始吧。
(二). 爬虫工程的创建
1.在D盘下创建一个空的目录叫crawler,在这个目录下打开cmd,然后使用git clone
https://gitee.com/jykgl/python-crawler-django-project.git 将项目克隆下来。
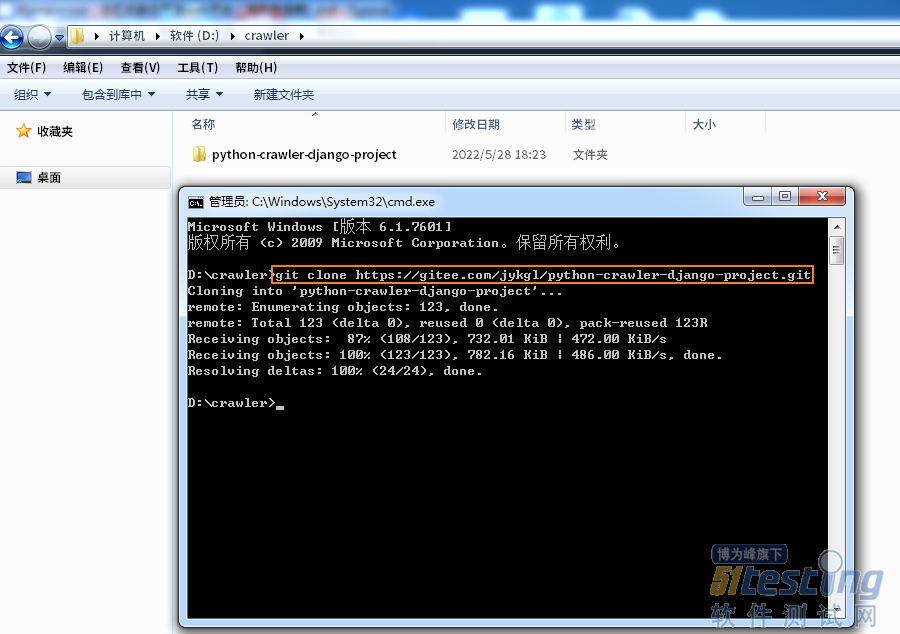
2.使用pycharm打开python-crawler-django-project这个目录,这个爬虫项目就加载出来了。

(三). 爬虫工程的介绍
1.topbook:这是一个django项目,它的结构主要是:
app:子应用,下面有模型类models,子路由urls,视图类views等
static:静态目录,主要存放css、js等静态文件
templates:模板目录,下面主要存放html页面
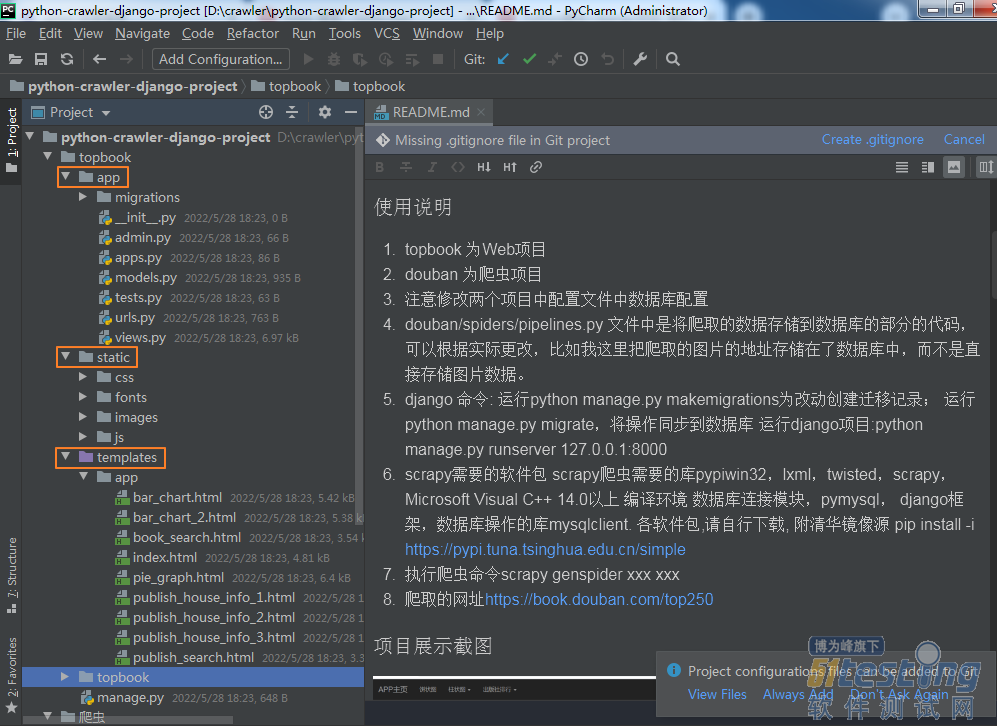
这是一个前段后不分离的项目,因此你会看到html文件里使用了很多模板变量。
对于这个项目,我们只需要使用到里面的模型类对象,其他我们用不到,因为我们自己的图书web系统会实现和它同样的功能。

2.douban:这是一个使用Scrapy框架实现的豆瓣爬虫项目,在这个项目里,我们只需要修改下pipelines.py中的数据库配置方式,将这里的数据库配置改为我们自己的图书web系统的数据库,然后执行后,爬取豆瓣的数据会落入对应的数据库。

(四). 爬虫工程依赖的安装
这里根据作者README.md里面的内容,依次安装好这些依赖:pypiwin32,lxml,twisted,scrapy,Microsoft Visual C++ 14.0以上 编译环境 数据库连接模块,pymysql, django框架,数据库操作的库mysqlclient,这里不做详述,但建议使用pipenv做好环境隔离,避免冲突。
本文源自第六十八期《51测试天地》
《django+vue:手把手教你开发web平台(五)—图书展示》一文
查看更多精彩内容,请点击下载:
版权声明:本文出自《51测试天地》第六十八期。51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。











