

ЎЎЎЎRational Performance TeserЈЁRPTЈ©КЗЧЁГЕХл¶Ф B/SјЬ№№әНЧЁУГПөНіЈЁSAPЈ¬Citrix өИЈ©ҪшРРС№БҰІвКФөД№ӨҫЯЎЈRPT »щУЪҝӘ·ЕөД TPTP ЖҪМЁәН Java УпСФЖдКө¶ФОТГЗөДІвКФМṩБЛәЬҙуөДА©Х№РФЎЈұҫОДҙУКэҫЭіШөДҪЗ¶Иіц·ўЈ¬ҪбәПКөјК»·ҫіЦРУцөҪөДТ»Р©ОКМвЈ¬АҙА©Х№ RPT өДКэҫЭЗэ¶ҜДЬБҰЎЈ
З°СФ
ЎЎЎЎФЪРФДЬІвКФЦРЈ¬ОТГЗНщНщУцөҪХвСщөДТ»Р©ОКМвЈ¬ұИИзРиТӘНЁ№эІ»Н¬өДУГ»§ҪшРРөЗВјІЩЧчЈ¬»тХЯРиТӘ¶ҜМ¬өДКдИлКэҫЭЈ¬ФЪІвКФ№ӨҫЯЦРНщНщОТГЗКЗНЁ№эКэҫЭіШАҙҪшРРНкіЙөДЎЈұИҪПИ«ГжөДКэҫЭіШөДЙијЖНщНщ»бҝјВЗУГ»§КэҫЭөДАҙФҙЈ¬ұИИзОДјюЈ¬КэҫЭҝвөИ¶аЦЦРОКҪЈ¬ө«ЖдКөИз№ыІЙУГЦұҪУУіЙдКэҫЭҝвЦРөДДіР©БРАҙҪшРРКөПЦЈ¬ЛдИ»ФЪІЩЧчЙП»бКЎПВәЬ¶аКэҫЭјУ№ӨөДКұјдЈ¬ө«ФЪКөјКФЛРР№эіЎЦР»бУРЦо¶аИұөгЈ¬ЦчТӘМеПЦФЪГҝёцУГ»§ГҝҙО»сИЎКэҫЭКұҫНРиТӘПыәДҙуБҝөДКұјдЈ¬ТтОӘНщНщКэҫЭҝвФЪФ¶іМөД·юОсЖчЙП¶ш·ЗұҫөШЈ¬Из№ыЖө·ұөДҪ»»Ҙ»бК№ХжХэРиТӘБЛҪвөДПмУҰКұјдҙуҙтХЫҝЫЎЈіцУЪІвКФҫЎҝЙДЬ·ҙУіХжКөөДУҰУГПмУҰКұјдөДҝјВЗЈ¬Rational Performance Tester ІЙУГБЛОДјюөД·ҪКҪАҙҪшРРКэҫЭөДөјИлЎЈ
Rational Performance Tester ДЪЦГөД DataPool өДКөПЦ»ъЦЖ
ЎЎЎЎRational Performance Tester ДЪЦГөДКэҫЭіШІЙУГБЛ TPTP өДЗ°Йн Hyades ІвКФҝтјЬөДКөПЦ·ҪКҪЈ¬ТІҫНКЗНЁ№э EMF ҪшРРКөПЦЎЈЖдЙијЖНјОӘЈә
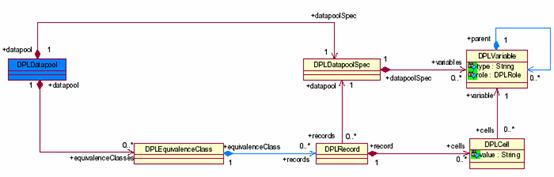
ЖдЦРұИҪПЦчТӘөДјёёцёЕДоКЗЈә
- VariableЈә
- ЦчТӘЦёТ»ёцБРЈ¬НЁіЈ°ьә¬Т»ёцГыЧЦәНҪЁТйөДАаРН
- RecordЈә
- РРЈ¬°ьә¬¶аБРөДКэҫЭ
- CellЈә
- КэҫЭҝйЈ¬¶ФУҰөДКЗДіРРДіБР
- EquivalenceClassЈә
- өИјЫАаЈ¬КэҫЭіШЦРјЗВјөДВЯјӯЧйәП
- DatapoolЈә
- КэҫЭіШ
ЎЎЎЎНщНщОТГЗФЪНЁ№э RPT өДҪзГжҪЁБўКэҫЭіШ»тХЯҙУ CSV ОДјюөјИлКэҫЭіШКұЈ¬»б·ўПЦФЪОТГЗөД workspaces ПоДҝөДёщДҝВјПВЦРЙъіЙБЛТ»ёц .datapool өДОДјюЈ¬°СОДјюНЁ№э winrar ҪвҝӘЈ¬ҝЙТФҝҙөҪКЗТ»ёц xmi ОДјюЈ¬ёсКҪИзПВЈә
|
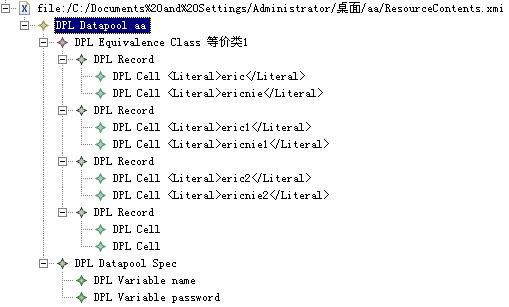
ЎЎЎЎІЙУГ EMF ЙијЖөДТ»ёцәЬЦұҪУөДәГҙҰКЗЈ¬ПөНіҝЙТФЧФ¶ҜөДёщҫЭДЈРНЙъіЙҙъВлЈ¬Н¬КұКөПЦБЛ UML ДЈРНЈ¬XML SchemaЈ¬ ЧўКН№эөД Java ҪУҝЪұнПЦДЈРНөДНіТ»ЎЈө«ФЪКөјК»·ҫіЦРЈ¬ІЙУГ Rational Performance Tester ДЪЦГөД DataPool »№КЗУРәЬ¶аІ»М«·ҪұгөДөШ·ҪЈ¬ұИИзЈә
- ТӘҫӯіЈ¶ФОДјюЦРөДКэҫЭҪшРРұд»ҜЈ¬И»әуФЩЦШРВІвКФКұ
әЬ¶аКұәтІвКФНкәуЈ¬КэҫЭҫНФЭКұГ»УГБЛЈ¬ТтОӘЧҙМ¬ТСҫӯёьРВБЛЈ¬ОӘҙЛРиТӘ¶ФІвКФКэҫЭҪшРРМж»»Ј¬ө«ФЪ RPT ДҝЗ°өДХвЦЦРтБР»Ҝ·ҙРтБР»ҜөД»ъЦЖЦРЈ¬ТӘКөПЦХвТ»өгІўІ»ИЭТЧЈ¬ЛщТФМеПЦФЪҪзГжЦРөДІЩЧчКөјКЙПКЗұИҪП·ұЛцөДЈ¬ұнПЦОӘЈә
- ТӘЦШРВјУИлТ»ёцРВөД Pool
- РиТӘ¶ФФӯАҙөДұдБҝИҘөф№ШБӘ
- №ШБӘРВөД Pool ЦРөДұдБҝ
Из№ыДгөДұдБҝұИҪП¶аЈ¬»№КЗ·ЗіЈ·ұЛцөДЈ¬¶шЗТІ»КЗТ»ЦЦЧоәГөДҪвҫц°м·ЁЎЈ
- өұІвКФКэҫЭәЬҙуЈ¬ұИИзОДјюҙуёЕ 50M »тёь¶аКұ
ХвКұәтДЪЦГөД»ъЦЖ»бІъЙъТ»Р©ОКМвЈ¬Ч°ФШКэҫЭКұұИҪПВэЎЈХвФЪФзЖЪөД 6.x °жұҫЦРҫӯіЈУцөҪЈ¬ө«ПЦФЪ 70 УРГ»УРХвёцОКМвө№КЗРиТӘҝҙҝҙөЧІг»ъЦЖКЗ·сУРёьёДЎЈ
ЎЎЎЎХэТтОӘЙПГжөДОКМвЈ¬Н¬Кұ»№Жө·ұФЪКөјКөДІвКФ№эіМЦРУцөҪЈ¬ТтҙЛХТөҪТ»ЦЦёьәГөДМжҙъ·Ҫ°ё¶ФУЪКөјКөДПоДҝёьјУЖИЗРЈ¬әГФЪ RPT ҪЁБўФЪ TPTP өДјЬ№№ЙПЈ¬ТІҫНТвО¶ЧЕҪЁБўФЪҙҝҙвөД Java өДКөПЦ»ъЦЖПВЈ¬ТтҙЛМṩБЛИГИЛәЬ·ҪұгөДІеИл Java ҙъВлөД·ҪКҪЈ¬К№өГәЬ¶аөДА©Х№әНФцЗҝіЙОӘҝЙДЬЎЈПВГжОТГЗҫНАҙМёМёИзәОҪвҫцХвБҪёцОКМвЎЈ












