

一、概述
1.1 接口自动化概述
众所周知,接口自动化测试有着如下特点:
低投入,高产出。
比较容易实现自动化。
和UI自动化测试相比更加稳定。
如何做好一个接口自动化测试项目呢?
我认为,一个“好的”自动化测试项目,需要从“时间”、“人力”、“收益”这三个方面出发,做好“取舍”。
不能由于被测系统发生一些变更,就导致花费了几个小时的自动化脚本无法执行。同时,我们需要看到“收益”,不能为了总想看到100%的成功,而少做或者不做校验,但是校验多了维护成本一定会增多,可能每天都需要进行大量的维护。
所以做好这三个方面的平衡并不容易,经常能看到做自动化的同学,做到最后就本末倒置了。
1.2 提高ROI
想要提高ROI(Return On Investment,投资回报率),我们必须从两方面入手:
减少投入成本。
增加使用率。
针对“减少投入成本”
我们需要做到:
减少工具开发的成本。尽可能的减少开发工具的时间、工具维护的时间,尽可能使用公司已有的,或是业界成熟的工具或组件。
减少用例录入成本。简化测试用例录入的成本,尽可能多的提示,如果可以,开发一些批量生成测试用例的工具。
减少用例维护成本。减少用例维护成本,尽量只用在页面上做简单的输入即可完成维护动作,而不是进行大量的代码操作。
减少用例优化成本。当团队做用例优化时,可以通过一些统计数据,进行有针对性、有目的性的用例优化。
针对“增加使用率”
我们需要做到:
手工也能用。不只是进行接口自动化测试,也可以完全用在手工测试上。
人人能用。每一个需要使用测试的人,包括一些非技术人员都可以使用。
当工具用。将一些接口用例当成工具使用,比如“生成订单”工具,“查找表单数据”工具。
每天测试。进行每日构建测试。
开发的在构建之后也能触发测试。开发将被测系统构建后,能自动触发接口自动化测试脚本,进行测试。
所以,我这边开发了Lego接口测试平台,来实现我对自动测试想法的一些实践。先简单浏览一下网站,了解一下大概是个什么样的工具。
首页:

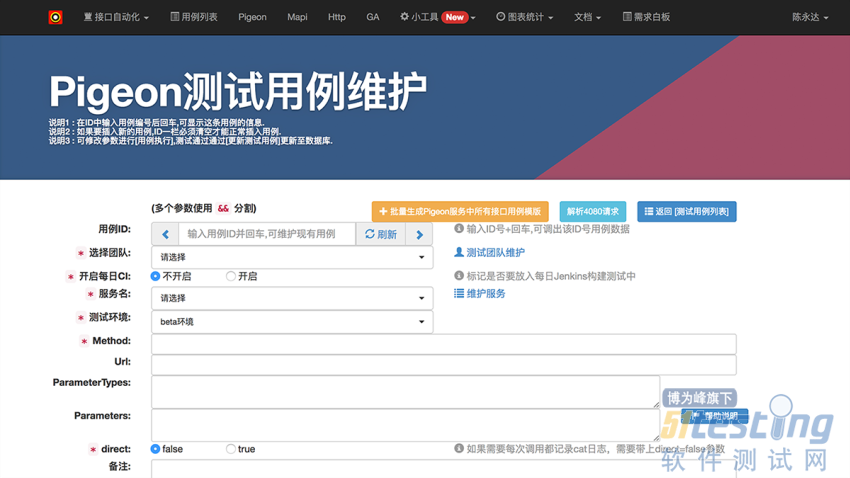
用例维护页面:
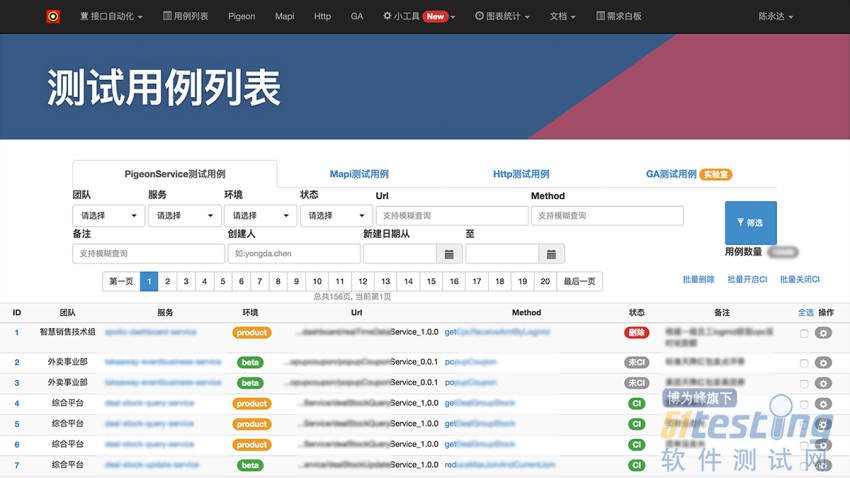
自动化用例列表:
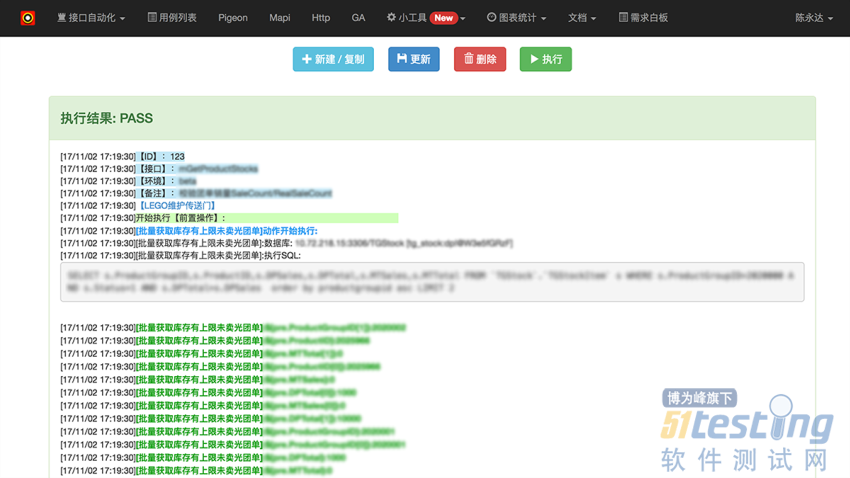
在线执行结果:
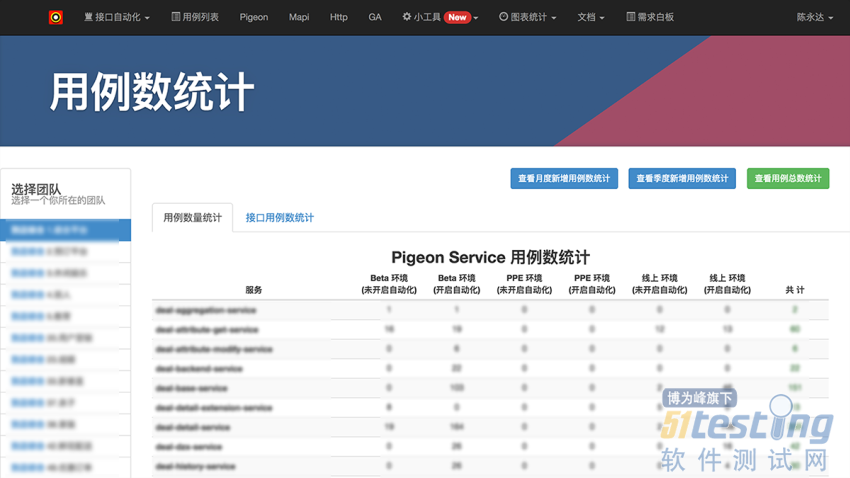
用例数量统计:
1.3 Lego的组成
Lego接口测试解决方案是由两部分组成的,一个就是刚刚看到的“网站”,另一个部分就是“脚本”。
下面就开始进行“脚本设计”部分的介绍。
二、脚本设计
2.1 Lego的做法
Lego接口自动化测试脚本部分,使用很常见的Jenkins+TestNG的结构。
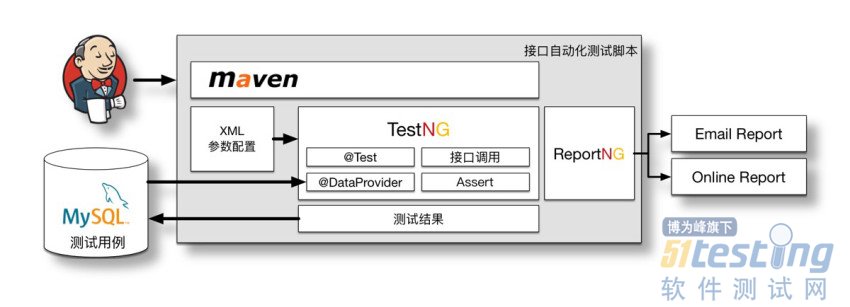
相信看到这样的模型并不陌生,因为很多的测试都是这样的组成方式。
很多团队也是使用这样的结构来进行接口自动化,沿用的话,那在以后的“推广”中,学习和迁移成本低都会比较低。
2.2 测试脚本
首先来简单看一下目前的脚本代码:
public class TestPigeon {
String sql;
int team_id = -1;
@Parameters({"sql", "team_id"})
@BeforeClass()
public void beforeClass(String sql, int team_id) {
this.sql = sql;
this.team_id = team_id;
ResultRecorder.cleanInfo();
}
/**
* XML中的SQL决定了执行什么用例, 执行多少条用例, SQL的搜索结果为需要测试的测试用例
*/
@DataProvider(name = "testData")
private Iterator<Object[]> getData() throws SQLException, ClassNotFoundException {
return new DataProvider_forDB(TestConfig.DB_IP, TestConfig.DB_PORT,
TestConfig.DB_BASE_NAME,TestConfig.DB_USERNAME, TestConfig.DB_PASSWORD, sql);
}
@Test(dataProvider = "testData")
public void test(Map<String, String> data) {
new ExecPigeonTest().execTestCase(data, false);
}
@AfterMethod
public void afterMethod(ITestResult result, Object[] objs) {...}
@AfterClass
public void consoleLog() {...}
}
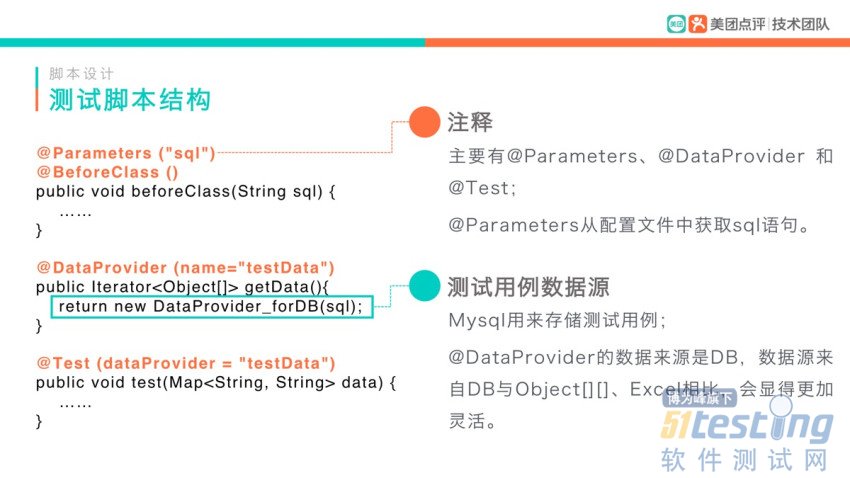
有一种做法我一直不提倡,就是把测试用例直接写在Java文件中。这样做会带来很多问题:修改测试用例需要改动大量的代码;代码也不便于交接给其他同学,因为每个人都有自己的编码风格和用例设计风格,这样交接,最后都会变成由下一个同学全部推翻重写一遍;如果测试平台更换,无法做用例数据的迁移,只能手动的一条条重新输入。
所以“测试数据”与“脚本”分离是非常有必要的。
网上很多的范例是使用的Excel进行的数据驱动,我这里为什么改用MySQL而不使用Excel了呢?
在公司,我们的脚本和代码都是提交至公司的Git代码仓库,如果使用Excel……很显然不方便日常经常修改测试用例的情况。使用MySQL数据库就没有这样的烦恼了,由于数据与脚本的分离,只需对数据进行修改即可,脚本每次会在数据库中读取最新的用例数据进行测试。同时,还可以防止一些操作代码时的误操作。
这里再附上一段我自己写的DataProvider_forDB方法,方便其他同学使用在自己的脚本上:
import java.sql.*;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
/**
* 数据源 数据库
*
* @author yongda.chen
*/
public class DataProvider_forDB implements Iterator<Object[]> {
ResultSet rs;
ResultSetMetaData rd;
public DataProvider_forDB(String ip, String port, String baseName,
String userName, String password, String sql) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.jdbc.Driver");
String url = String.format("jdbc:mysql://%s:%s/%s", ip, port, baseName);
Connection conn = DriverManager.getConnection(url, userName, password);
Statement createStatement = conn.createStatement();
rs = createStatement.executeQuery(sql);
rd = rs.getMetaData();
}
@Override
public boolean hasNext() {
boolean flag = false;
try {
flag = rs.next();
} catch (SQLException e) {
e.printStackTrace();
}
return flag;
}
@Override
public Object[] next() {
Map<String, String> data = new HashMap<String, String>();
try {
for (int i = 1; i <= rd.getColumnCount(); i++) {
data.put(rd.getColumnName(i), rs.getString(i));
}
} catch (SQLException e) {
e.printStackTrace();
}
Object r[] = new Object[1];
r[0] = data;
return r;
}
@Override
public void remove() {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
2.3 配置文件
上面图中提到了“配置文件”,下面就来简单看一下这个XML配置文件的脚本:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Pigeon Api测试" parallel="false">
<test name="xxx-xxx-service">
<parameter name="sql"
value="SELECT * FROM API_PigeonCases
WHERE team_id=2
AND isRun=1
AND service='xxx-xxx-service'
AND env='beta';"/>
<classes>
<class name="com.dp.lego.test.TestPigeon"/>
</classes>
</test>
<listeners>
<listener class-name="org.uncommons.reportng.HTMLReporter"/>
<listener class-name="org.uncommons.reportng.JUnitXMLReporter"/>
</listeners>
</suite>
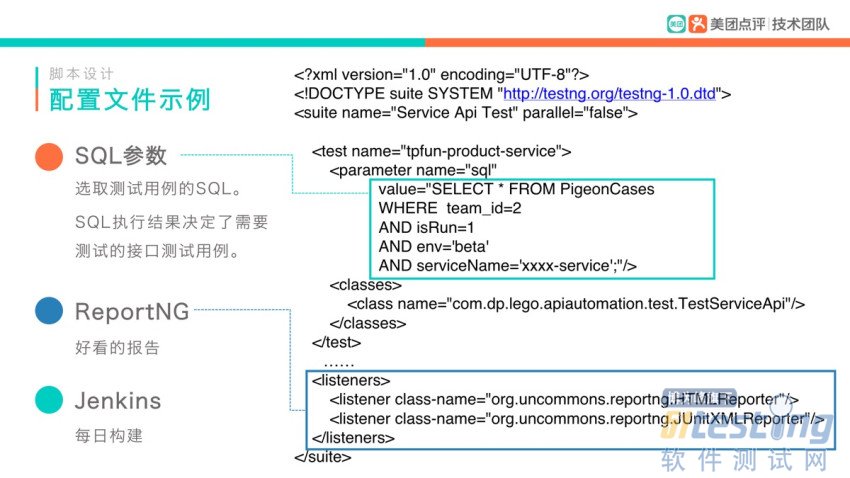
对照上图来解释一下配置文件:
SQL的话,这里的SQL主要决定了选取哪些测试用例进行测试。
一个标签,就代表一组测试,可以写多个标签。
“listener”是为了最后能够生成一个ReportNG的报告。
Jenkins来实现每日构建,可以使用Maven插件,通过命令来选择需要执行的XML配置。
这样做有什么好处呢?
使用SQL最大的好处就是灵活
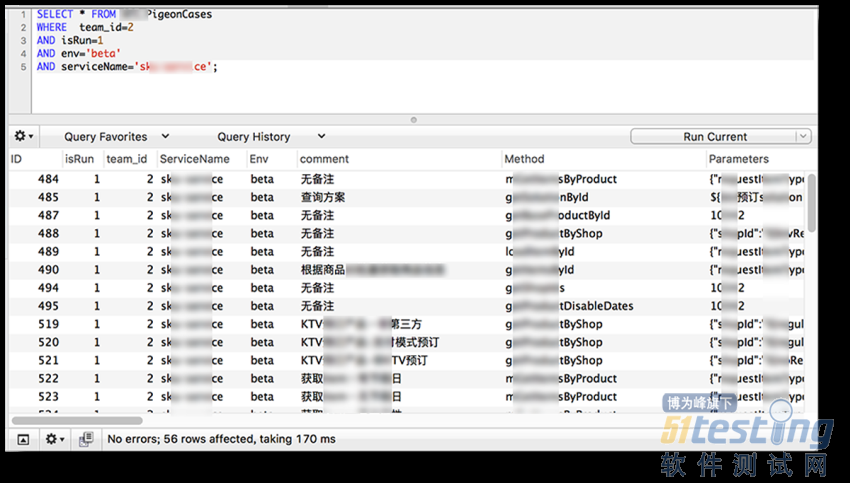
如上面的这个例子,在数据库中会查询出下面这56条测试用例,那么这个标签就会对这56条用例进行逐一测试。
多标签时,可以分组展示
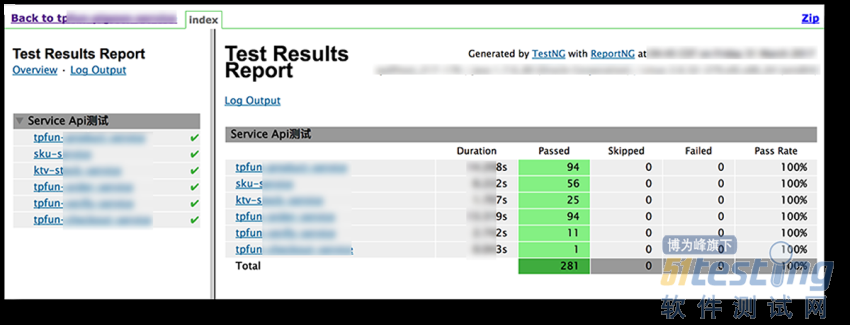
使用多个标签来区分用例,最大的好处就是也能在最后的报告上,达到一个分组展示的效果。
报告更美观丰富
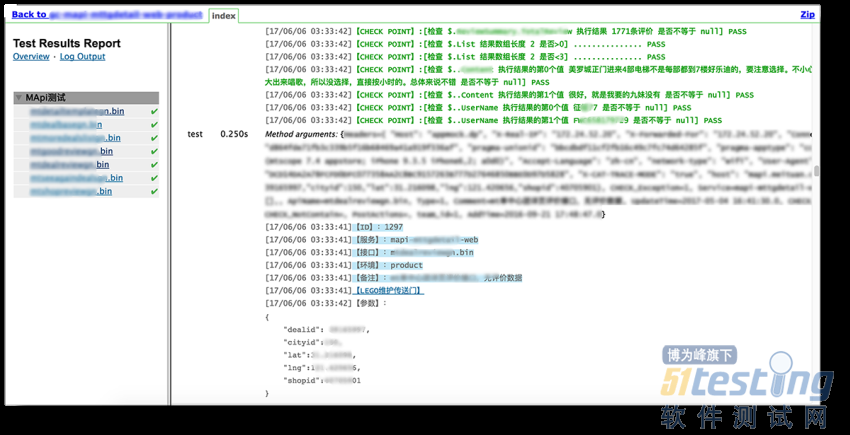
由于使用了ReportNG进行报告的打印,所以报告的展示要比TestNG自带的报告要更加美观、并且能自定义展示样式,点开能看到详细的执行过程。
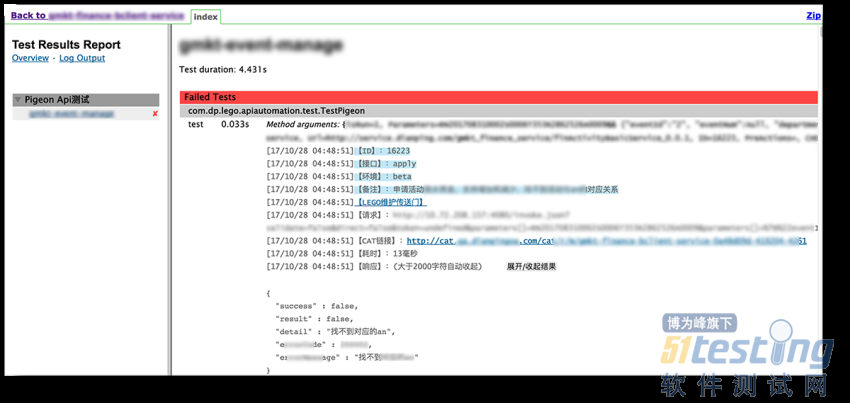
如果有执行失败的用例,通常报错的用例会在最上方优先展示。
支持多团队
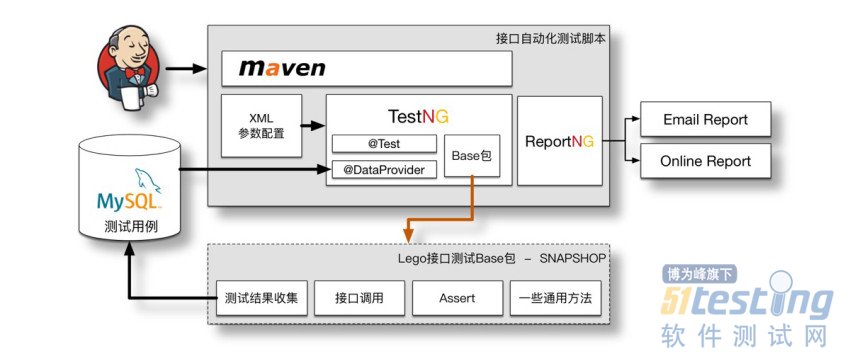
当两个团队开始使用时,为了方便维护,将基础部分抽出,各个团队的脚本都依赖这个Base包,并且将Base包版本置为“SNAPSHOT版本”。使用“SNAPSHOT版本”的好处是,之后我对Lego更新,各个业务组并不需要对脚本做任何改动就能及时更新。
当更多的团队开始使用后,比较直观的看的话是这个样子的:
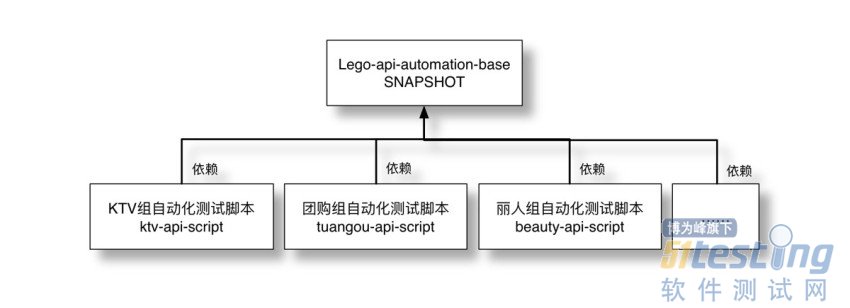
每个团队的脚本都依赖于我的这个Base包,所以最后,各个业务团队的脚本就变成了下面的这个样子:
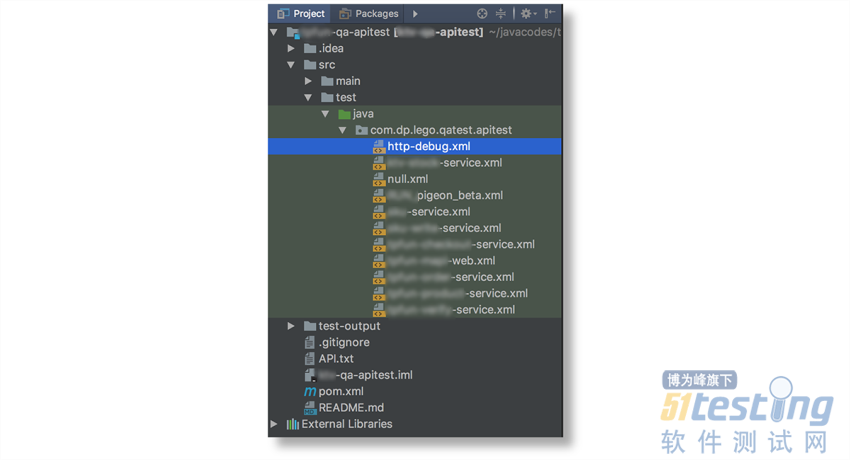
可以看到,使用了Lego之后:
没有了Java文件,只有XML文件
xml中只需要配置SQL。
执行和调试也很方便。
可以右键直接执行想要执行的测试配置。
可以使用maven命令执行测试:
mvn clean test -U -Dxml=xmlFileName 。
通过参数来选择需要执行的xml文件。
也可以使用Jenkins来实现定时构建测试。
由于,所有测试用例都在数据库所以这段脚本基本不需要改动了,减少了大量的脚本代码量。
有些同学要问,有时候编写一条接口测试用例不只是请求一下接口就行,可能还需要写一些数据库操作啊,一些参数可能还得自己写一些方法才能获取到啊之类的,那不code怎么处理呢?
下面就进入“用例设计”,我将介绍我如何通过统一的用例模板来解决这些问题。
三、用例设计
3.1 一些思考
我在做接口自动化设计的时候,会思考通用、校验、健壮、易用这几点。
通用
简单、方便
用例数据与脚本分离,简单、方便。
免去上传脚本的动作,能避免很多不必要的错误和维护时间。
便于维护。
模板化
抽象出通用的模板,可快速拓展。
数据结构一致,便于批量操作。
专人维护、减少多团队间的重复开发工作。
由于使用了统一的模板,那各组之间便可交流、学习、做有效的对比分析。
如果以后这个平台不再使用,或者有更好的平台,可快速迁移。
可统计、可拓展
可统计、可开发工具;如:用例数统计,某服务下有多少条用例等。
可开发用例维护工具。
可开发批量生成工具。
校验
在写自动化脚本的时候,都会想“细致”,然后“写很多”的检查点;但当“校验点”多的时候,又会因为很多原因造成执行失败。所以我们的设计,需要在保证充足的检查点的情况下,还要尽可能减少误报。
充足的检查点
可以检查出被测服务更多的缺陷。
尽量少的误报
可以减少很多的人工检查和维护的时间人力成本。
还要
简单、易读。
最好使用一些公式就能实现自己想要的验证。
通用、灵活、多样。
甚至可以用在其他项目的检查上,减少学习成本。
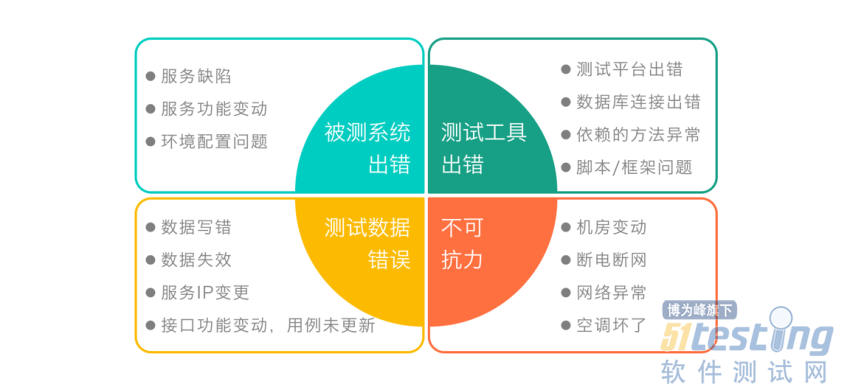
健壮
执行测试的过程中,难免会报失败,执行失败可能的原因有很多,简单分为4类:
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












