

5.3 结果校验
在手工测试接口的时候,我们需要通过接口返回的结果判断本次测试是否通过,自动化测试也是如此。
对于本次的接口,我们搜索“q=刘德华”,我们需要判断返回的结果中是否含有“演职人员刘德华或片名刘德华”,搜索“tag=喜剧”时,需要判断返回的结果中电影类型是否为“喜剧”,结果分页时需要校验返回的结果数是否正确等。完整结果校验代码如下:
class check_response(): @staticmethod def check_result(response, params, expectNum=None): # 由于搜索结果存在模糊匹配的情况,这里简单处理只校验第一个返回结果的正确性 if expectNum is not None: # 期望结果数目不为None时,只判断返回结果数目 eq_(expectNum, len(response['subjects']), '{0}!={1}'.format(expectNum, len(response['subjects']))) else: if not response['subjects']: # 结果为空,直接返回失败 assert False else: # 结果不为空,校验第一个结果 subject = response['subjects'][0] # 先校验搜索条件tag if params.get('tag'): for word in params['tag'].split(','): genres = subject['genres'] ok_(word in genres, 'Check {0} failed!'.format(word.encode('utf-8'))) # 再校验搜索条件q elif params.get('q'): # 依次判断片名,导演或演员中是否含有搜索词,任意一个含有则返回成功 for word in params['q'].split(','): title = [subject['title']] casts = [i['name'] for i in subject['casts']] directors = [i['name'] for i in subject['directors']] total = title + casts + directors ok_(any(word.lower() in i.lower() for i in total), 'Check {0} failed!'.format(word.encode('utf-8'))) @staticmethod def check_pageSize(response): # 判断分页结果数目是否正确 count = response.get('count') start = response.get('start') total = response.get('total') diff = total - start if diff >= count: expectPageSize = count elif count > diff > 0: expectPageSize = diff else: expectPageSize = 0 eq_(expectPageSize, len(response['subjects']), '{0}!={1}'.format(expectPageSize, len(response['subjects']))) |
5.4 执行测试
对于上述测试脚本,我们使用nosetests命令可以方便的运行自动化测试,并可使用nose-html-reporting插件生成html格式测试报告。
运行命令如下:
nosetests -v test_doubanSearch.py:test_doubanSearch --with-html --html-report=TestReport.html
5.5 发送邮件报告
测试完成之后,我们可以使用smtplib模块提供的方法发送html格式测试报告。基本流程是读取测试报告 -> 添加邮件内容及附件 -> 连接邮件服务器 -> 发送邮件 -> 退出,示例代码如下:
import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart def send_mail(): # 读取测试报告内容 with open(report_file, 'r') as f: content = f.read().decode('utf-8') msg = MIMEMultipart('mixed') # 添加邮件内容 msg_html = MIMEText(content, 'html', 'utf-8') msg.attach(msg_html) # 添加附件 msg_attachment = MIMEText(content, 'html', 'utf-8') msg_attachment["Content-Disposition"] = 'attachment; filename="{0}"'.format(report_file) msg.attach(msg_attachment) msg['Subject'] = mail_subjet msg['From'] = mail_user msg['To'] = ';'.join(mail_to) try: # 连接邮件服务器 s = smtplib.SMTP(mail_host, 25) # 登陆 s.login(mail_user, mail_pwd) # 发送邮件 s.sendmail(mail_user, mail_to, msg.as_string()) # 退出 s.quit() except Exception as e: print "Exceptioin ", e |
6. 结果分析
打开nosetests运行完成后生成的测试报告,可以看出本次测试共执行了51条测试用例,50条成功,1条失败。
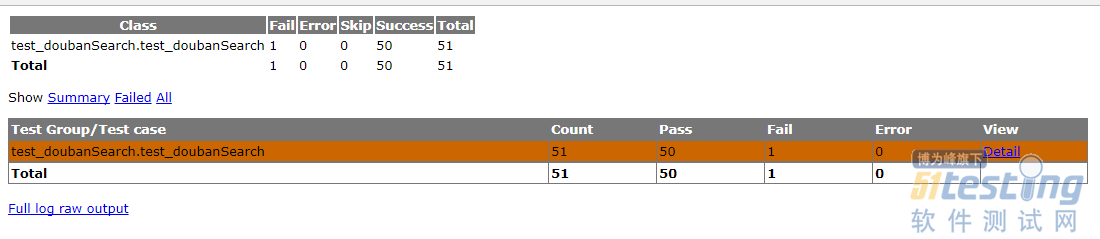
失败的用例可以看到传入的参数是:{"count": -10, "tag": "喜剧"},此时返回的结果数与我们的期望结果不一致(count为负数时,期望结果是接口报错或使用默认值20,但实际返回的结果数目是189。赶紧去给豆瓣提bug啦- -)

7. 完整脚本
豆瓣电影搜索接口的完整自动化测试脚本,我已上传到的GitHub。下载地址:https://github.com/lovesoo/test_demo/tree/master/test_douban
下载完成之后,使用如下命令即可进行完整的接口自动化测试并通过邮件发送最终的测试报告:
python test_doubanSearch.py
最终发送测试报告邮件,截图如下:
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












