

而关于Jdk版本的问题是和Hadoop的版本相匹配的,其它相关产品后续我们会分析,当然也大家可以自行从Hadoop官网上去查询,这里不赘述。
操作系统
为了方便演示,我会使用虚拟机跟大家讲解,当然,有兴趣的童鞋也可以自行下载虚拟机跟随我一步步来搭建这个平台,这里我选择的虚拟机为:VMware。
大家网上下载安装就可以了,过程很简单,没啥需要讲解的,当然你的PC配置是需要好一点的,至少8G以上,要不基本玩转不了虚拟机。
安装完成就是上面的样子了,相关资料大家网上查阅吧,这里就不在赘述。
然后,我们进行Liunx操作系统的安装,上面已经说过,我们选择的是CentOS操作,所以需要到CentOS官网进行下载安装就行,记住了:不用怕,不花钱!
这里在选择CentOS版本的时候需要记住了,如果不是公司要求,尽量不要选择最新的,而是要选择最稳定的,原因很简单,谁也不要当新版本的小白鼠。

然后选择要下载的稳定版本,这里我推荐选择CentOS6.8 64位操作系统。
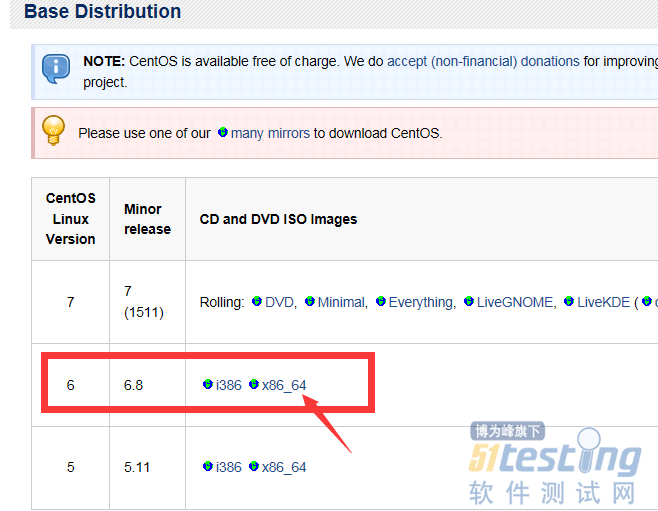
然后,点击找到下载包下载就行。
在安装各个节点之前,我们需要提前准备好相关节点的配置信息,比如计算机名、IP地址、安装角色、超级管理员账户信息,内存分配、存储等,所以我列举了一个表格供大家参考:
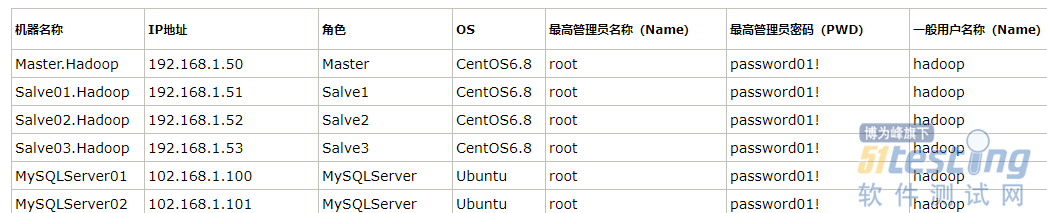
大家可以看到,我这里先提前规划处四台服务器用来搭建Hadoop集群,然后分别为其分配了机器名称、IP,IP需要设置为统一网段,然后为了搭建我们的Hadoop集群,我们需要为所有集群中的节点创建一个独立的用户,这里我起了一个名字,就叫做Hadoop,当然为了方便记忆我统一的将所有的密码设置为password01!.
当然,这里我们提前配置好内存和存储,因为我们知道我们使用的虚拟机这些信息是可以根据使用的情况,进行动态调整的。
另外,我又搭建了两台Ubuntu的服务器来单独安装MySQLServer,搭建了一个主从模式,我们知道Ubuntu是一个界面友好的操作系统,这里和Hadoop集群分离的目的是因为Mysql数据库是比较占内存资源的,所以我们单独机器来安装,当然,MySQL并不是Hadoop集群所需要的,两者没有必然的关系,这里搭建它的目的就为了后续安装Hive来分析数据应用的,并且我们可以在这个机器里进行开发调试,当然Window平台也可以,毕竟我们使用Windows平台是最熟练的。
结语
此篇篇幅已经有些长度了,先到此吧,关于Hadoop大数据集群的搭建后续依次介绍,比如利用Zookeeper搭建Hadoop高可用平台、Map-Reducer层序的开发、Hive产品的数据分析、Spark的应用程序的开发、Hue的集群坏境的集成和运维、Sqoop2的数据抽取等,有兴趣的童鞋可以提前关注。
本篇主要介绍了搭建一个Hadoop大数据集群需要提前准备的内容和一些注意项,关于开源的大数据产品生态链是非常的庞大,所以我们将花费很多的时间在应用的使用场景上,但是其最底层的支撑框架就是Hadoop的Yarn计算模型和HDFS分布式文件存储系统。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












