

进阶内容1:meta Region究竟在哪里?
meta Region的路由信息存放在ZooKeeper中,但meta Region究竟在哪个RegionServer中提供读写服务?
在1.0版本中,引入了一个新特性,使得Master可以”兼任”一个RegionServer角色(可参考HBASE-5487, HBASE-10569),从而可以将一些系统表的Region分配到Master的这个RegionServer中,这种设计的初衷是为了简化/优化Region Assign的流程,但这依然带来了一系列复杂的问题,尤其是Master初始化和RegionServer初始化之间的Race,因此,在2.0版本中将这个特性暂时关闭了。详细信息可以参考:HBASE-16367,HBASE-18511,HBASE-19694,HBASE-19785,HBASE-19828
客户端侧的数据分组“打包”
如果这条待写入的数据采用的是Single Put的方式,那么,该步骤可以略过(事实上,单条Put操作的流程相对简单,就是先定位该RowKey所对应的Region以及RegionServer信息后,Client直接发送写请求到RegionServer侧即可)。
但如果这条数据被混杂在其它的数据列表中,采用Batch Put的方式,那么,客户端在将所有的数据写到对应的RegionServer之前,会先分组”打包”,流程如下:
按Region分组:遍历每一条数据的RowKey,然后,依据meta表中记录的Region信息,确定每一条数据所属的Region。此步骤可以获取到Region到RowKey列表的映射关系。
按RegionServer”打包”:因为Region一定归属于某一个RegionServer(注:本文内容中如无特殊说明,都未考虑Region Replica特性),那属于同一个RegionServer的多个Regions的写入请求,被打包成一个MultiAction对象,这样可以一并发送到每一个RegionServer中。

数据分组与打包
Client发送写数据请求到RegionServer
类似于Client发送建表到Master的流程,Client发送写数据请求到RegionServer,也是通过RPC的方式。只是,Client到Master以及Client到RegionServer,采用了不同的RPC服务接口。

Client Send Request To RegionServer
single put请求与batch put请求,两者所调用的RPC服务接口方法是不同的,如下是Client.proto中的定义:

Client Proto定义
安全访问控制
如何保障UserA只能写数据到UserA的表中,以及禁止UserA改写其它User的表的数据,HBase提供了ACL机制。ACL通常需要与Kerberos认证配合一起使用,Kerberos能够确保一个用户的合法性,而ACL确保该用户仅能执行权限范围内的操作。
HBase将权限分为如下几类:
READ(‘R’)
WRITE(‘W’)
EXEC(‘X’)
CREATE(‘C’)
ADMIN(‘A’)
可以为一个用户/用户组定义整库级别的权限集合,也可以定义Namespace、表、列族甚至是列级别的权限集合。
RegionServer端处理:Region分发
RegionServer的RPC Server侧,接收到来自Client端的RPC请求以后,将该请求交给Handler线程处理。
如果是single put,则该步骤比较简单,因为在发送过来的请求参数MutateRequest中,已经携带了这条记录所关联的Region,那么直接将该请求转发给对应的Region即可。
如果是batch puts,则接收到的请求参数为MultiRequest,在MultiRequest中,混合了这个RegionServer所持有的多个Region的写入请求,每一个Region的写入请求都被包装成了一个RegionAction对象。RegionServer接收到MultiRequest请求以后,遍历所有的RegionAction,而后写入到每一个Region中,此过程是串行的:

Write Per Region
从这里可以看出来,并不是一个batch越大越好,大的batch size甚至可能导致吞吐量下降。
Region内部处理:写WAL
HBase也采用了LSM-Tree的架构设计:LSM-Tree利用了传统机械硬盘的“顺序读写速度远高于随机读写速度”的特点。随机写入的数据,如果直接去改写每一个Region上的数据文件,那么吞吐量是非常差的。因此,每一个Region中随机写入的数据,都暂时先缓存在内存中(HBase中存放这部分内存数据的模块称之为MemStore,这里仅仅引出概念,下一章节详细介绍),为了保障数据可靠性,将这些随机写入的数据顺序写入到一个称之为WAL(Write-Ahead-Log)的日志文件中,WAL中的数据按时间顺序组织:
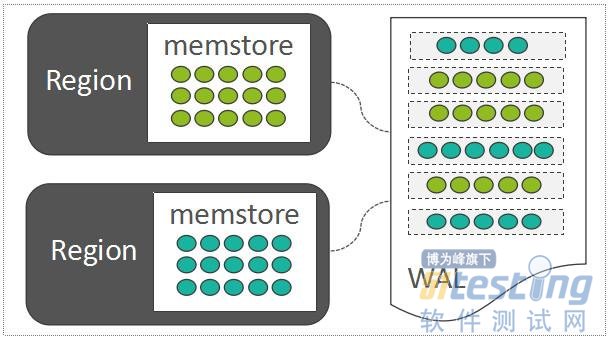
MemStore And WAL
如果位于内存中的数据尚未持久化,而且突然遇到了机器断电,只需要将WAL中的数据回放到Region中即可:

WAL Replay
在HBase中,默认一个RegionServer只有一个可写的WAL文件。WAL中写入的记录,以Entry为基本单元,而一个Entry中,包含:
WALKey 包含{Encoded Region Name,Table Name,Sequence ID,Timestamp}等关键信息,其中,Sequence ID在维持数据一致性方面起到了关键作用,可以理解为一个事务ID。
WALEdit WALEdit中直接保存待写入数据的所有的KeyValues,而这些KeyValues可能来自一个Region中的多行数据。
也就是说,通常,一个Region中的一个batch put请求,会被组装成一个Entry,写入到WAL中:

Write into WAL
将Entry写到文件中时是支持压缩的,但该特性默认未开启。
WAL进阶内容
WAL Roll and Archive
当正在写的WAL文件达到一定大小以后,会创建一个新的WAL文件,上一个WAL文件依然需要被保留,因为这个WAL文件中所关联的Region中的数据,尚未被持久化存储,因此,该WAL可能会被用来回放数据。
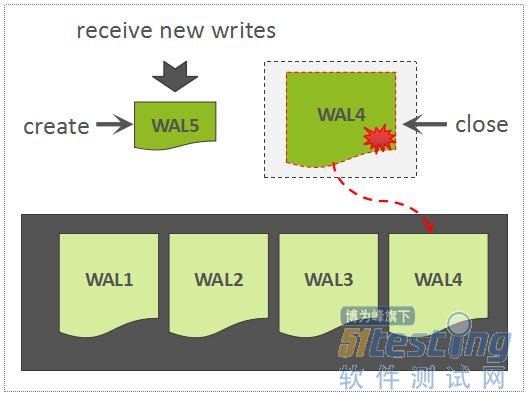
Roll WAL
如果一个WAL中所关联的所有的Region中的数据,都已经被持久化存储了,那么,这个WAL文件会被暂时归档到另外一个目录中:
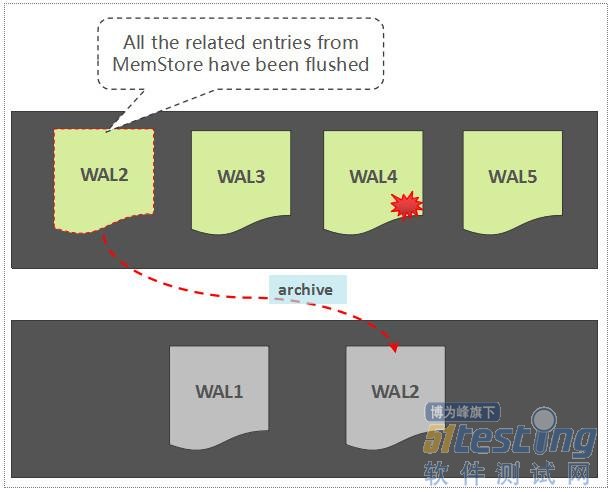
WAL Archive
注意,这里不是直接将WAL文件删除掉,这是一种稳妥且合理的做法,原因如下:
避免因为逻辑实现上的问题导致WAL被误删,暂时归档到另外一个目录,为错误发现预留了一定的时间窗口
按时间维度组织的WAL数据文件还可以被用于其它用途,如增量备份,跨集群容灾等等,因此,这些WAL文件通常不允许直接被删除,至于何时可以被清理,还需要额外的控制逻辑
另外,如果对写入HBase中的数据的可靠性要求不高,那么,HBase允许通过配置跳过写WAL操作。
思考:put与batch put的性能为何差别巨大?
在网络分发上,batch put已经具备一定的优势,因为batch put是打包分发的。
而从写WAL这块,看的出来,batch put写入的一小批次Put对象,可以通过一次sync就持久化到WAL文件中了,有效减少了IOPS。
但前面也提到了,batch size并不是越大越好,因为每一个batch在RegionServer端是被串行处理的。
利用Disruptor提升写并发性能
在高并发随机写入场景下,会带来大量的WAL Sync操作,HBase中采用了Disruptor的RingBuffer来减少竞争,思路是这样:如果将瞬间并发写入WAL中的数据,合并执行Sync操作,可以有效降低Sync操作的次数,来提升写吞吐量。
Multi-WAL
默认情形下,一个RegionServer只有一个被写入的WAL Writer,尽管WAL Writer依靠顺序写提升写吞吐量,在基于普通机械硬盘的配置下,此时只能有单块盘发挥作用,其它盘的IOPS能力并没有被充分利用起来,这是Multi-WAL设计的初衷。Multi-WAL可以在一个RegionServer中同时启动几个WAL Writer,可按照一定的策略,将一个Region与其中某一个WAL Writer绑定,这样可以充分发挥多块盘的性能优势。
关于WAL的未来
WAL是基于机械硬盘的IO模型设计的,而对于新兴的非易失性介质,如3D XPoint,WAL未来可能会失去存在的意义,关于这部分内容,请参考文章《从HBase中移除WAL?3D XPoint技术带来的变革》。
Region内部处理:写MemStore
每一个Column Family,在Region内部被抽象为了一个HStore对象,而每一个HStore拥有自身的MemStore,用来缓存一批最近被随机写入的数据,这是LSM-Tree核心设计的一部分。
MemStore中用来存放所有的KeyValue的数据结构,称之为CellSet,而CellSet的核心是一个ConcurrentSkipListMap,我们知道,ConcurrentSkipListMap是Java的跳表实现,数据按照Key值有序存放,而且在高并发写入时,性能远高于ConcurrentHashMap。
因此,写MemStore的过程,事实上是将batch put提交过来的所有的KeyValue列表,写入到MemStore的以ConcurrentSkipListMap为组成核心的CellSet中:

Write Into MemStore
MemStore因为涉及到大量的随机写入操作,会带来大量Java小对象的创建与消亡,会导致大量的内存碎片,给GC带来比较重的压力,HBase为了优化这里的机制,借鉴了操作系统的内存分页的技术,增加了一个名为MSLab的特性,通过分配一些固定大小的Chunk,来存储MemStore中的数据,这样可以有效减少内存碎片问题,降低GC的压力。当然,ConcurrentSkipListMap本身也会创建大量的对象,这里也有很大的优化空间,去年阿里的一篇文章透露了阿里如何通过优化ConcurrentSkipListMap的结构来有效减少GC时间。
进阶内容2:先写WAL还是先写MemStore?
在0.94版本之前,Region中的写入顺序是先写WAL再写MemStore,这与WAL的定义也相符。
但在0.94版本中,将这两者的顺序颠倒了,当时颠倒的初衷,是为了使得行锁能够在WAL sync之前先释放,从而可以提升针对单行数据的更新性能。详细问题单,请参考HBASE-4528。
在2.0版本中,这一行为又被改回去了,原因在于修改了行锁机制以后(下面章节将讲到),发现了一些性能下降,而HBASE-4528中的优化却无法再发挥作用,详情请参考HBASE-15158。改动之后的逻辑也更简洁了。
进阶内容3:关于行级别的ACID
在之前的版本中,行级别的任何并发写入/更新都是互斥的,由一个行锁控制。但在2.0版本中,这一点行为发生了变化,多个线程可以同时更新一行数据,这里的考虑点为:
如果多个线程写入同一行的不同列族,是不需要互斥的
多个线程写同一行的相同列族,也不需要互斥,即使是写相同的列,也完全可以通过HBase的MVCC机制来控制数据的一致性
当然,CAS操作(如checkAndPut)或increment操作,依然需要独占的行锁
更多详细信息,可以参考HBASE-12751。
至此,这条数据已经被同时成功写到了WAL以及MemStore中:

Data Written In HBase
总结
本文主要内容总结如下:
介绍HBase写数据可选接口以及接口定义。
通过一个样例,介绍了RowKey定义以及列定义的一些方法,以及如何组装Put对象
数据路由,数据分发、打包,以及Client通过RPC发送写数据请求至RegionServer
RegionServer接收数据以后,将数据写到每一个Region中。写数据流程先写WAL再写MemStore,这里展开了一些技术细节
简单介绍了HBase权限控制模型
需要说明的一点,本文所讲到的MemStore其实是一种"简化"后的模型,在2.0版本中,这里已经变的更加复杂。












