

ЎЎЎЎ2.3 ЛДёцЦШТЄµДDOMКфРФ
ЎЎЎЎnodeNameКфРФЈє№ж¶ЁЅЪµгµДГыіЖЎЈ
ЎЎЎЎnodeNameКЗЦ»¶БµД
ЎЎЎЎФЄЛШЅЪµгµДnodeNameУл±кЗ©ГыПаН¬
ЎЎЎЎКфРФЅЪµгµДnodeNameУлКфРФГыПаН¬
ЎЎЎЎОД±ѕЅЪµгµДnodeNameКјЦХКЗ#text
ЎЎЎЎОДµµЅЪµгµДnodeNameКјЦХКЗ#document
ЎЎЎЎnodeValueКфРФЈє№ж¶ЁЅЪµгµДЦµЎЈ
ЎЎЎЎФЄЛШЅЪµгµДnodeValueКЗundefined»тnull
ЎЎЎЎОД±ѕЅЪµгµДnodeValueКЗОД±ѕ±ѕЙн
ЎЎЎЎКфРФЅЪµгµДnodeValueКЗКфРФЦµ
ЎЎЎЎnodeTypeКфРФЈє·µ»ШЅЪµгµДАаРНЎЈ
ЎЎЎЎnodeTypeКЗЦ»¶БµДЎЈ
ЎЎЎЎinnerHTMLКфРФЈє»сИЎФЄЛШДЪИЭЈ¬ИзЈє

ЎЎЎЎјґtextµДЦµОЄHelloWorldЈЎ
ЎЎЎЎinnerHTMLїЙТФ±»ёіЦµЈ¬ТІїЙ¶БЈ¬ТтґЛКЗ±»ТэУГґОКэЧо¶аµД¶ФПуКфРФЈ¬Н¬К±ТІКЗЧоИЭТЧІъЙъ°ІИ«ОКМвµД¶ФПуКфРФЎЈ
ЎЎЎЎ2.4 КдИлТ»°гФЪДДАп
ЎЎЎЎLocation¶ФПуКфРФ
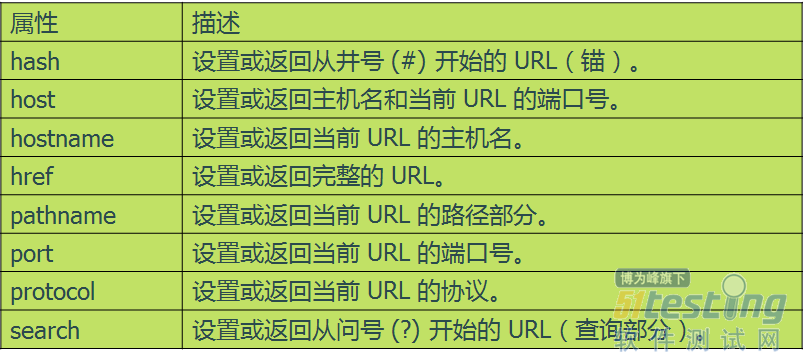
ЎЎЎЎJSНЁіЈ»бНЁ№эµчУГDOMДЪЦГ¶ФПуlocationАґ»сµГУГ»§КдИлЈ¬ИзТэУГІОКэЗР·ЦїЙК№УГlocation.searchЈ¬ТэУГНкХыURLїЙК№УГlocation.hrefµИЎЈ

ЎЎЎЎИэ.DOMbaseXSS
ЎЎЎЎ3.1БЅёцµдРНµДDOM№эіМ
ЎЎЎЎ1Ј©·ґЙдРНDOMbaseXSS
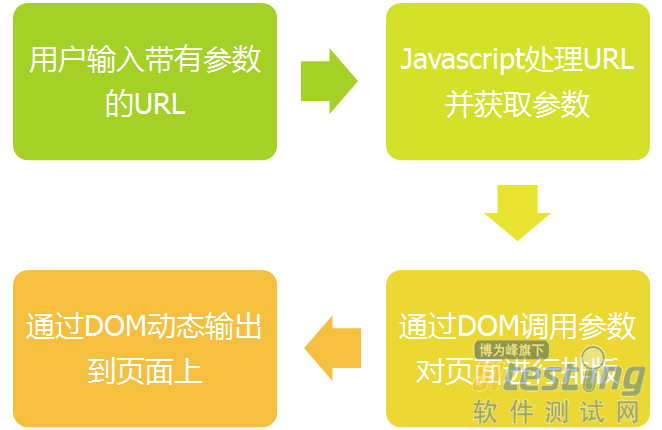
ЎЎЎЎ2Ј©ґжґўРНDOMbaseXSS

ЎЎЎЎ3.2 РиТЄБЛЅвµДЦЄК¶µг
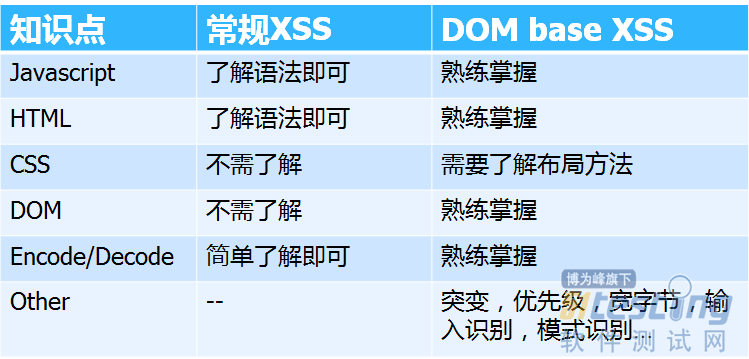
ЎЎЎЎ±ИЖріЈ№жXSSЈ¬DOMbaseXSSµДВ©¶ґ·ўПЦ№эіМёьПсКЗґъВлЙујЖ..
ЎЎЎЎ3.3 µдРНDOMbaseXSSКµАэ

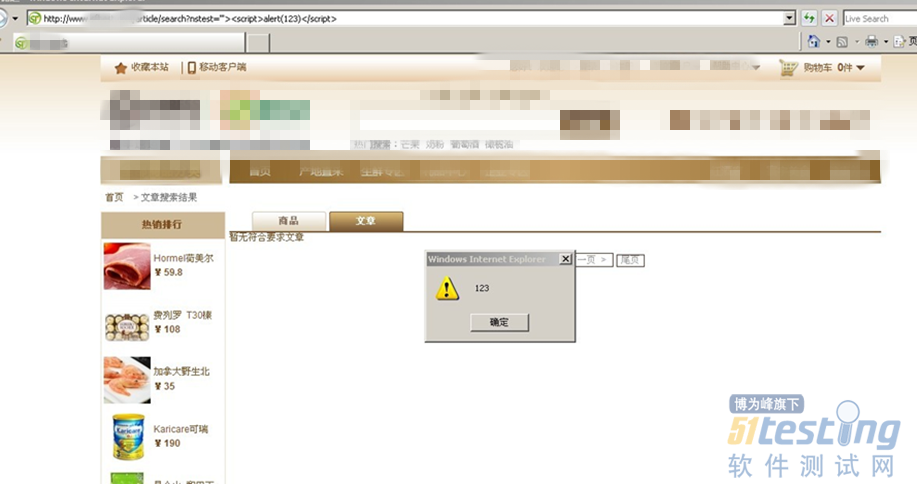
ЎЎЎЎ3.4 mxss
ЎЎЎЎИз№ыУГ»§КдИлЎ°іцИлЎ±DOMБЅґОТФЙПЈ¬ФтУРїЙДЬґҐ·ўёьёЯј¶±рµДDOMbaseXSSЈєmXSS
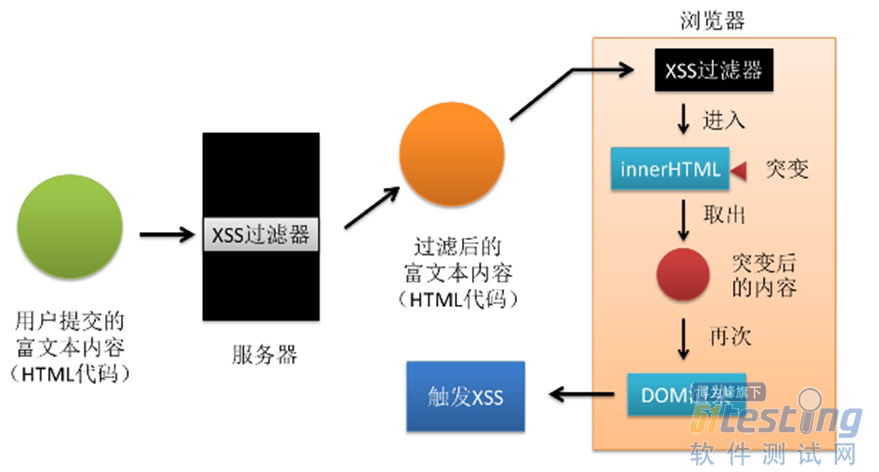
ЎЎЎЎ3.5 ИЭТЧіцПЦmXSSµДіЎѕ°

ЎЎЎЎУЙУЪinnerHTML»бЅ«HTMLКµМеЈ¬CSSЧЄТеЧЦ·ыЈ¬ANSI±аВлµИЅшРР·ґЧЄТеЈ¬ТтґЛФАґ±»ЧЄТеЦ®єуИПОЄ°ІИ«µДУГ»§КдИлєЬУРїЙДЬФЪИЖ№э№эВЛЖчЦ®єу±»·ґЧЄ»ШИҐЎЈ

ЎЎЎЎЛД.№эВЛЖчИЖ№э
ЎЎЎЎ4.1 ПИАґјёёцАхЧУ
ЎЎЎЎіЈ№жXSSµД№эВЛЖчИЖ№э

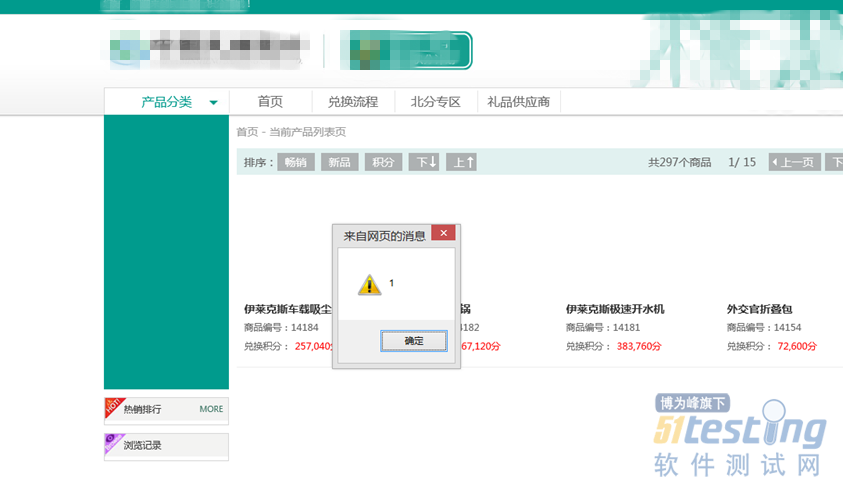
ЎЎЎЎ4.2 №эВЛЖчИЖ№э·Ѕ·Ё
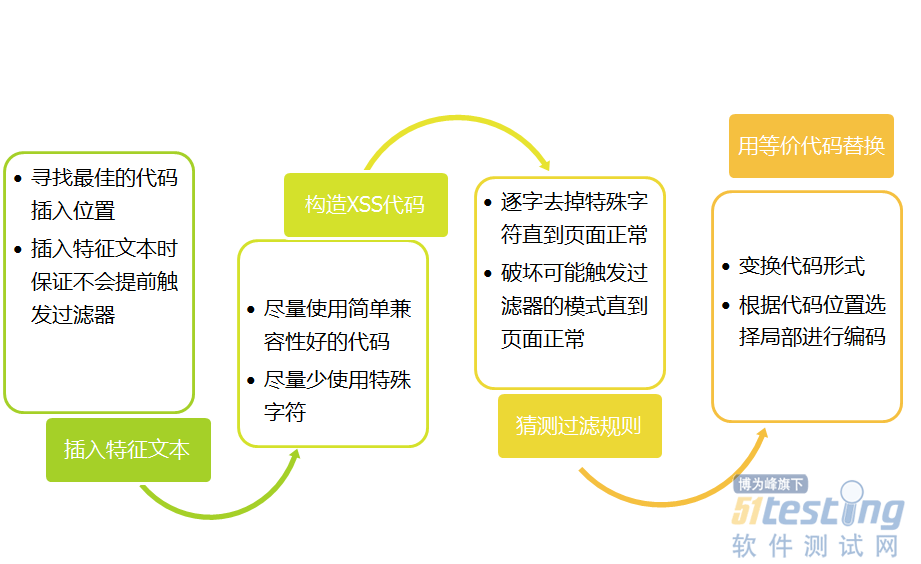
ЎЎЎЎТ»°гТвТеЙП¶шСФЈ¬DOMbaseXSSµДКЧПИТЄНЁ№э·юОс¶ЛµД№эВЛЖчЗеПґТ»·¬Ј¬И»єу»№ТЄНЁ№эТіГжјУФШµДёчёцJSЅЕ±ѕЈ¬ИЖ№эДС¶ИПа¶ФЅПґуЎ
ЎЎЎЎ±аВлИЖ№эЈє
ЎЎЎЎОТГЗТЄІеИлµДґъВлЈє<imgsrc=Ў°Ў±onerror=alert(123)>

ЎЎЎЎHTML5МШРФЈє

ЎЎЎЎ4.3XSSРЮёґЅЁТй
ЎЎЎЎІ»є¬УРё»ОД±ѕ±ајЖчЈЁЧФ¶ЁТеСщКЅЈ©ЗТГ»УРК№УГDOMµДХѕµгЈє
ЎЎЎЎКдИлЈє№эВЛЛ«ТэєЕЈ¬µҐТэєЕЈ¬ЧуУТјвАЁєЕЈ¬·ЦєЕЎЈ
ЎЎЎЎКдіцЈє¶ФЙПКцЧЦ·ыЅшРРHTMLКµМе±аВлјґїЙЎЈ
ЎЎЎЎІ»є¬УРё»ОД±ѕ±ајЖчЈЁЧФ¶ЁТеСщКЅЈ©µ«К№УГDOMµДХѕµгЈє
ЎЎЎЎКдИлЈєФЪDOMЦРЧЄТеЛ«ТэєЕЈ¬µҐТэєЕЈ¬ЧуУТјвАЁєЕЈ¬·ЦєЕЎЈ
ЎЎЎЎКдіцЈєФЪКдіцЦ®З°ЅшРР±аВлЈ¬ИзЈєinnerHTML=encodeHTML(output)
ЎЎЎЎє¬УРё»ОД±ѕ±ајЖчЈЁЧФ¶ЁТеСщКЅЈ©µ«Г»УРК№УГDOMµДХѕµгЈє
ЎЎЎЎКдИлЈє№эВЛЛ«ТэєЕЈ¬µҐТэєЕЈ¬·ЦєЕЎЈ
ЎЎЎЎКдіцЈє¶ФЙПКцЧЦ·ыЅшРРHTMLКµМе±аВлјґїЙЎЈ
ЎЎЎЎє¬УРё»ОД±ѕ±ајЖчЈЁЧФ¶ЁТеСщКЅЈ©ЗТК№УГDOMµДХѕµгЈє
ЎЎЎЎГ»°м·ЁЎЦёДД¶щРЮДД¶щЎ












