

ЁЁЁЁ3 HiveЗжЮіЪЕМљ
ЁЁЁЁ3.1 SchemaЩшМЦ
ЁЁЁЁУЛгаЭЈгУЕФschemaЃЌжЛгаКЯЪЪЕФschemaЁЃдкЩшМЦHiveЕФschemaЕФЪБКђЃЌашвЊПМТЧЕНДцДЂЁЂвЕЮёЩЯЕФИпЦЕВщбЏдьГЩЕФПЊЯњЕШЕШЃЌЩшМЦЪЪКЯздМКЕФЪ§ОнФЃаЭЁЃ
ЁЁЁЁЩшжУЗжЧјБэ
ЁЁЁЁЖдгкHiveРДЫЕЃЌРћгУЗжЧјРДЩшМЦБэзмЪЧБивЊЕФЃЌЗжЧјЬсЙЉСЫвЛжжИєРыЪ§ОнКЭгХЛЏВщбЏЕФБуРћЕФЗНЪНЁЃЩшжУЗжЧјЪБЃЌашвЊПМТЧБЛЩшжУГЩЗжЧјЕФзжЖЮЃЌАДееЪБМфЗжЧјвЛАуЖјбдОЭЪЧвЛИіКУЕФЗНАИЃЌЦфКУДІдкгкЦфЪЧАДееВЛЭЌЪБМфСЃЖШРДШЗЖЈКЯЪЪДѓаЁЕФЪ§ОнЛ§РлСПЃЌЫцзХЪБМфЕФЭЦвЦЃЌЗжЧјЪ§СПЕФдіГЄЪЧОљдШЕФЃЌЗжЧјЕФДѓаЁвВЪЧОљдШЕФЁЃ
ЁЁЁЁБмУтаЁЮФМў
ЁЁЁЁЫфШЛЗжЧјгаРћгкИєРыЪ§ОнКЭВщбЏЃЌЩшжУЙ§ЖрЙ§ЯИЕФЗжЧјвВЛсДјРДЦПОБЃЌжївЊЪЧвђЮЊЙ§ЖрЕФЗжЧјвтЮЖзХЮФМўЕФЪ§ФПОЭдНЖрЃЌЙ§ЖрдіГЄЕФаЁЮФМўЛсИјnamecodeДјРДОоДѓЕФадФмбЙСІЁЃЭЌЪБаЁЮФМўЙ§ЖрЛсгАЯьJOBЕФжДааЃЌhadoopЛсНЋвЛИіjobзЊЛЛГЩЖрИіtaskЃЌМДЪЙЖдгкУПИіаЁЮФМўвВашвЊвЛИіtaskШЅЕЅЖРДІРэЃЌДјРДадФмПЊЯњЁЃвђДЫЃЌhiveБэЩшМЦЕФЗжЧјВЛгІИУЙ§ЖрЙ§ЯИЃЌУПИіФПТМЯТЕФЮФМўзуЙЛДѓЃЌгІИУЪЧЮФМўЯЕЭГжаПщДѓаЁЕФШєИЩБЖЁЃ
ЁЁЁЁбЁдёЮФМўИёЪН
ЁЁЁЁHiveЬсЙЉЕФФЌШЯЮФМўДцДЂИёЪНгаtextfileЁЂsequencefileЁЂrcfileЕШЁЃгУЛЇвВПЩвдЭЈЙ§ЪЕЯжНгПкРДздЖЈвхЪфШыЪфЕФЮФМўИёЪНЁЃ
ЁЁЁЁдкЪЕМЪгІгУжаЃЌtextfileгЩгкЮобЙЫѕЃЌДХХЬМАНтЮіЕФПЊЯњЖМКмДѓЃЌвЛАуКмЩйЪЙгУЁЃSequencefileвдМќжЕЖдЕФаЮЪНДцДЂЕФЖўНјжЦЕФИёЪНЃЌЦфжЇГжеыЖдМЧТММЖБ№КЭПщМЖБ№ЕФбЙЫѕЁЃrcfileЪЧвЛжжааСаНсКЯЕФДцДЂЗНЪНЃЈtext fileКЭsequencefileЖМЪЧааБэ[row table]ЃЉЃЌЦфБЃжЄЭЌвЛЬѕМЧТМдкЭЌвЛИіhdfsПщжаЃЌПщвдСаЪНДцДЂЁЃrcfileЕФОлКЯдЫЫуВЛвЛЖЈзмЪЧДцдкЃЌЕЋЪЧrcfileЕФИпбЙЫѕТЪШЗЪЕМѕЩйЮФМўДѓаЁЃЌвђДЫЪЕМЪгІгУжаЃЌrcfileзмЪЧГЩЮЊВЛЖўЕФбЁдёЃЌДяЙлЪ§ОнЦНЬЈдкбЁдёЮФМўДцДЂИёЪНЪБвВДѓСПбЁдёСЫrcfileЗНАИЁЃ
ЁЁЁЁ3.2 ЭГМЦЗжЮі
ЁЁЁЁБОНкНЋДгХХађКЭДАПкКЏЪ§СНИіЗНУцЕФНщЩмHiveЕФЭГМЦЗжЮіЙІФмЁЃ
ЁЁЁЁХХУћШШУХХХУћдкЪЕМЪЕФвЕЮёГЁОАжаОГЃгіМћЁЃР§ШчзюЪмЛЖгЕФЪщМЎЁЂЯњСПTOP100ЕФЩЬЦЗЕШЕШЁЃдйЪЕМЪЧщПіЯТЃЌЮвУЧВЛНіашвЊПМТЧИїСПЛЏжИБъЃЌЛЙашвЊПМТЧжУаХЖШЮЪЬтЁЃ
ЁЁЁЁзюМђЕЅЕФХХУћЃКORDER BY value LIMIT n
ЁЁЁЁЩЯЪіВщбЏНіНіПМТЧСЫСПЛЏжИБъЃЌХХУћВЛЙЛЦНЛЌЃЌВЈЖЏНЯДѓЁЃ
ЁЁЁЁИїжжХХУћЗНЗЈжкЖрЃЌДяЙлЪ§ОнЗжЮіЦНЬЈдкНјааitem ХХУћЖрВЩгУЛљгкгУЛЇЭЖЦБЕФХХУћЫуЗЈЁЃШчЛљгкЭўЖћбЗЧјМфЕФХХУћЫуЗЈЃЌИУЫуЗЈПЩвдНЯКУЕФНтОіаЁбљБОЕФВЛзМШЗЮЪЬтЁЃ
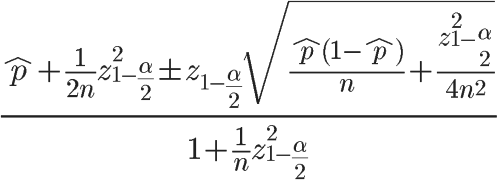
ЁЁЁЁЭМЃКЭўЖћбЗЧјМф
ЁЁЁЁДАПкЗжЮіКЏЪ§
ЁЁЁЁHiveЬсЙЉСЫЗсИЛСЫЪ§бЇЭГМЦКЏЪ§ЃЌЭЌЪБвВЬсЙЉСЫгУЛЇздЖЈвхКЏЪ§ЕФНгПкЃЌгУЛЇПЩвдздЖЈвхUDFЁЂUDAFЁЂUDTF Hive 0.11АцБОПЊЪМЬсЙЉДАПкКЭЗжЮіКЏЪ§ЃЈWindowing and Analytics FunctionsЃЉЃЌАќРЈLEADЁЂLAGЁЂFIRST_VALUEЁЂLAST_VALUEЁЂRANKЁЂROW_NUMBERЁЂPERCENT_RANKЁЂCUBEЁЂROLLUPЕШЁЃДАПкКЏЪ§гыОлКЯКЏЪ§вЛбљЃЌЖМЪЧЖдБэзгМЏЕФВйзїЃЌДгНсЙћЩЯПДЃЌЧјБ№дкгкДАПкКЏЪ§ЕФНсЙћВЛЛсОлКЯЃЌдгаЕФУПааМЧТМвРШЛЛсДцдкЁЃДАПкКЏЪ§ЕФЕфаЭЗжЮігІгУАќРЈЃКАДЗжЧјОлКЯЃЈХХађЃЌtop nЮЪЬтЃЉЁЂааМфМЦЫуЃЈЪБМфађСаЗжЮіЃЉЁЂЙиСЊМЦЫуЃЈЙКЮяРКЗжЮіЃЉЁЃ
ЁЁЁЁЮвУЧвдвЛИіМђЕЅЕФааМфМЦЫуЕФР§згЫЕУїДАПкКЏЪ§ЕФгІгУЃЈЙигкЦфЫћКЏЪ§ЕФОпЬхЫЕУїЃЌЧыВЮПМhiveЮФЕЕЃЉЁЃгУЛЇдФЖСааЮЊЕФЭГМЦЗжЮіашвЊДгЕуЛїЪщМЎааЮЊжаЙщФЩЭГМЦГіРДЁЃгУЛЇфЏРРШежОНсЙЙШчЯТБэЫљЪОЃЌУПЬѕМЧТМЮЊгУЛЇЕФЕЅДЮЕуЛїааЮЊЁЃ

ЁЁЁЁЭЈЙ§ЖдСЌајЕФгУЛЇЕуЛїШежОЗжЮіЃЌЭЈЙ§HiveЬсЙЉЕФДАПкЗжЮіКЏЪ§ПЩвдМЦЫуГігУЛЇИїеТНкЕФдФЖСЪБМфЁЃ
ЁЁЁЁSELECT userid, bookid, chapterid, end_time ЈC start_time as read_time ЁЁЁЁFROM ЁЁЁЁ( ЁЁЁЁ SELECT userid, bookid, chapterid, log_time as start_time, ЁЁЁЁ lead(log_time,1,null) over(partition by userid, bookid order by log_time) as end_time ЁЁЁЁ FROM user_read_log where pt=ЁЏ2015-12-01ЁЏ ЁЁЁЁ) t; |
ЁЁЁЁЭЈЙ§ЩЯЪіВщбЏМШПЩвдевГі2015-12-01ШеЫљгагУЛЇЖдУПвЛеТНкЕФдФЖСЪБМфЁЃжЛФмЭЈЙ§ПЊЗЂmrДњТыЛђепЪЕЯжudafРДЪЕЯжЩЯЪіЙІФмЁЃ
ЁЁЁЁДАПкЗжЮіКЏЪ§ЙиМќдкгкЖЈвхЕФДАПкЪ§ОнМЏМАЦфЖдДАПкЕФВйзїЃЌЭЈЙ§overЃЈДАПкЖЈвхгяОфЃЉРДЖЈвхДАПкЁЃШеГЃЗжЮіКЭЪЕМЪгІгУжаЃЌОГЃЛсгаДАПкЗжЮігІгУЕФГЁОАЃЌР§ШчЛљгкЗжЧјЕФХХађЁЂМЏКЯЁЂЭГМЦЕШИДдгВйзїЁЃР§ШчЮвУЧашвЊЭГМЦУПИігУЛЇдФЖСЪБМфзюЖрЕФ3БОЪщ:
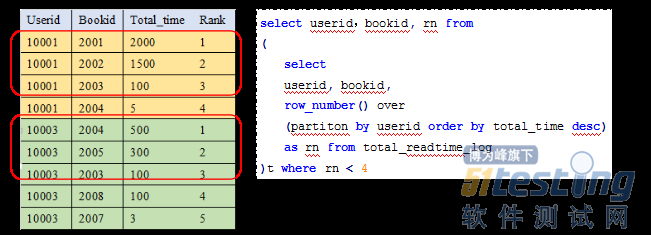
ЁЁЁЁЭМЃКааМфМЦЫуЪОвтЭММАДњТы
ЁЁЁЁДАПкКЏЪ§ЪЙЕУHiveЕФОпБИСЫЭъећЕФЪ§ОнЗжЮіЙІФмЃЌдкЪЕМЪЕФгІгУЛЗОГжаЃЌДяЙлЪ§ОнЗжЮіЭХЖгДѓСПЪЙгУhiveДАПкЗжЮіКЏЪ§РДЪЕЯжНЯЮЊИДдгЕФТпМЃЌЬсИпПЊЗЂКЭЕќДњаЇТЪЁЃ
ЁЁЁЁ3.3 гУЛЇЛЯё
ЁЁЁЁгУЛЇЛЯёМДЛљгкецЪЕЪ§ОнЕФгУЛЇФЃаЭЁЃМђЕЅРДЫЕЃЌгУЛЇЛЯёЬсШЁСЫгУЛЇЕФЪєадаХЯЂЁЂааЮЊаХЯЂЃЌДгЖјЙщФЩЭГМЦГіЦфШЫПкбЇЬиеїЁЂЦЋКУЬиеїЕШЁЃНЈСЂгУЛЇФЃаЭЕФЪзвЊШЮЮёОЭЪЧЬсШЁЬиеїЃЌМШАќРЈгУЛЇЛљБОЬиеїЃЌвВАќРЈааЮЊЬиеїКЭЭГМЦЬиеїЁЃ
ЁЁЁЁгУЛЇФЃаЭБОжЪЩЯОЭЪЧПЬЛгУЛЇаЫШЄЕФФЃаЭЃЌЖјгУЛЇЕФаЫШЄФЃаЭЪЧЖрЮЌЖШЁЂЖрГпЖШЕФЁЃПЬЛгУЛЇФЃаЭЛЙашвЊДгЪБМфЩЯНјааЖШСПЃЌЩѕжСЪЧНјааЖрГпЖШЕФзщКЯЃЌИљОнгУЛЇааЮЊЭГМЦЪБМфЕФГЄЖЬЃЌПЩвдНЋгУЛЇЕФЦЋКУЗжЮЊЖЬЦкЦЋКУКЭГЄЦкЦЋКУЁЃЦЋКУЕФШЈжиМДЮЊгУЛЇЕФЦЋКУГЬЖШЕФЖШСПЁЃ
ЁЁЁЁЖдгУЛЇЦЋКУЕФУшЪіЃЌЛЙашвЊПМТЧжУаХЖШЕФЮЪЬтЃЌР§ШчЖдгквЛИідФЖСааЮЊМЋЦфЯЁЪшЕФгУЛЇРДЫЕЃЌПЬЛЦфдФЖСРрБ№ЦЋКУЪЧКСЮовтвхЕФЁЃ
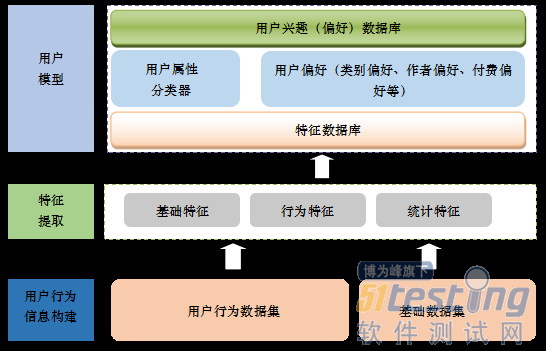
ЁЁЁЁЭМЃКгУЛЇЛЯёПЬЛ
ЁЁЁЁ3.4 ЗДзїБзЗжЮі
ЁЁЁЁжкЫљжмжЊЃЌДцдкХХУћОЭПЩФмДцдкзїБзЁЃЫбЫїЙуИцЁЂЫїЛЅСЊЭјЫЂЕЅЁЂЫЂАёЯжЯѓВуГіВЛЧюЁЃвЛАуРДЫЕЃЌзїБзЕФФПЕФЖМЪЧЮЊСЫЬсИпздМКЕФХХУћЃЌЛђепЪЧНЕЕЭЖдЪжЕФХХУћЁЃРћгУHiveЖдЪ§ОнНјааЗжЮіПЩвдЙ§ТЫЕєНЯУїЯдЕФзїБзЪ§ОнЃЌДяЕНЪ§ОнЧхЯДЕФФПЕФЁЃ
ЁЁЁЁР§ШчЖдгквЛИіЫЂАёзїБзааЮЊЃЌашвЊзїБззХВЛЖЯЫЂШежОааЮЊРДЬсИпЦфХХУћЃЌЮвУЧПЩвджИЖЈШєИЩЙцдђРДЙ§ТЫзїБзЪ§ОнЁЃШчЭЌIPЭЌЮяЦЗЭЌааЮЊЪ§ФПвьГЃЁЂЭЌгУЛЇIDааЮЊЦЕДЮвьГЃЁЂЭЌЮяЦЗIDааЮЊЦЕДЮвьГЃЕШЕШЁЃШчЯТЭМЃЌШчЙћЯрБШгкЫљгаitemЕФЦНОљдіГЄЧїЪЦЃЌШчЙћФГitemЕФдіГЄЧїЪЦЯрЖдЦНОљЫЎЦНЙ§ДѓЃЌФЧУДЦфзїБзЕФИХТЪОЭБШНЯИпЁЃ
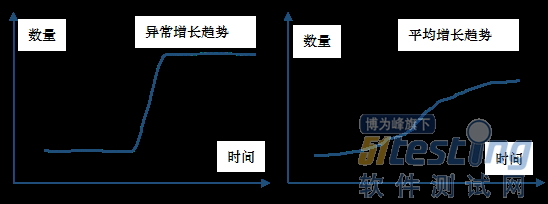
ЁЁЁЁЭМЃКзїБзЪ§ОнЧїЪЦгыЦНОљЧїЪЦЪ§ОнЖдБШ
ЁЁЁЁзїБзЗжЮіЛЙашвЊНсКЯвЕЮёашЧѓКЭЬиЕуЃЌВЩгУКЯЪЪЕФЛњЦїбЇЯАЫуЗЈРДНјааИќНјвЛВНЕФХаЖЯКЭЙ§ТЫЃЌДяЕНЗДзїБзЕФФПБъЁЃ
ЁЁЁЁ4 HiveгХЛЏ
ЁЁЁЁДяЙлЕФЪ§ОнВжПтЛљгкHiveДюНЈЃЌУПШеашвЊДІРэДѓСПЕФМЦЫуСїГЬЃЌHiveЕФЮШЖЈадКЭадФмжСЙиживЊЁЃжкЖрЕФШЮЮёашвЊЮвУЧКЯРэЕФЕїНкЗжХфМЏШКзЪдДЃЌКЯРэЕФХфжУИїВЮЪ§ЃЌКЯРэЕФгХЛЏВщбЏЁЃHiveгХЛЏАќКЌИїИіЗНУцЃЌШчjobИіЪ§гХЛЏЁЂjobЕФmap/reducerИіЪ§гХЛЏЁЂВЂаажДаагХЛЏЕШЕШЃЌБОНкНЋжївЊЬжТлHQLжаЕФЮоЪБВЛдкЕФJOINЕФгХЛЏОбщЁЃ
ЁЁЁЁ4.1 JoinгяОф
ЁЁЁЁЖдгкЩЯЪіЕФjoinгяОфЃЌЦфжаbook_infoБэЪ§СПЮЊЧЇЙцФЃЃЌ
ЁЁЁЁINSERT OVERWRITE TABLE read_log_tmp
ЁЁЁЁSELECT a.userid,a.bookid,b.author
ЁЁЁЁFROM user_read_log a JOIN book_info b ON a.bookid = b.bookid;
ЁЁЁЁИУгяОфЕФжДааМЦЛЎЮЊЃК
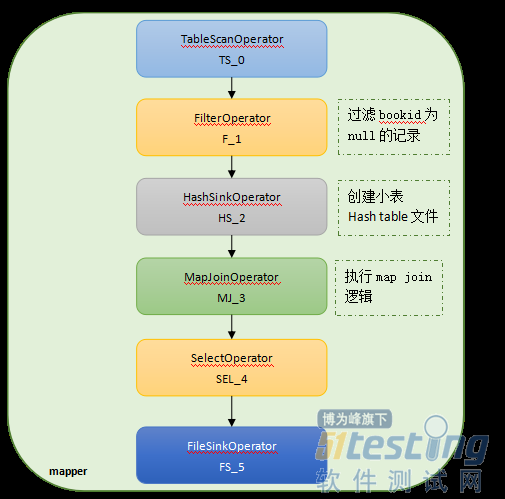
ЁЁЁЁЭМЃКmap joinЕФШЮЮёжДааСїГЬ
ЁЁЁЁЖдгкаЁЪ§ОнСПЃЌhiveЛсздЖЏВЩШЁmap joinЕФЗНЪНРДгХЛЏjoinЃЌДгmapreduceЕФБрГЬФЃаЭРДПДЃЌЪЕЯжjoinЕФЗНЪНжївЊгаmapЖЫjoinЁЂreduceЖЫjoinЁЃMapЖЫjoinРћгУhadoop ЗжВМЪНЛКДцММЪѕЭЈЙ§НЋаЁБэБфЛЛГЩhashtableЮФМўЗжЗЂЕНИїИіtaskЃЌmapДѓБэЪБПЩвджБНгХаЖЯhashtableРДЭъГЩjoinЃЌзЂвтаЁБэЕФhashtableЪЧЗХдкФкДцжаЕФЃЌдкФкДцжазїЦЅХфЃЌвђДЫmap joinЪЧвЛжжЗЧГЃПьЕФjoinЗНЪНЃЌвВЪЧвЛжжГЃМћЕФгХЛЏЗНЪНЁЃШчЙћаЁБэЙЛаЁЃЌФЧУДОЭПЩвдвдmap joinЕФЗНЪНРДЭъГЩjoinЭъГЩЁЃHiveЭЈЙ§ЩшжУhive.auto.convert.join=true(ФЌШЯжЕ)РДздЖЏЭъГЩmap joinЕФгХЛЏЃЌЖјЮоашЯдЪОжИЪОmap joinЁЃШБЪЁЧщПіЯТmap joinЕФгХЛЏЪЧДђПЊЕФЁЃ
ЁЁЁЁReduceЖЫjoinашвЊreducerРДЭъГЩjoinЙ§ГЬЃЌЖдгкЩЯЪіjoinДњТыЃЌreduce ЖЫjoinЕФmrСїГЬШчЯТЃЌ
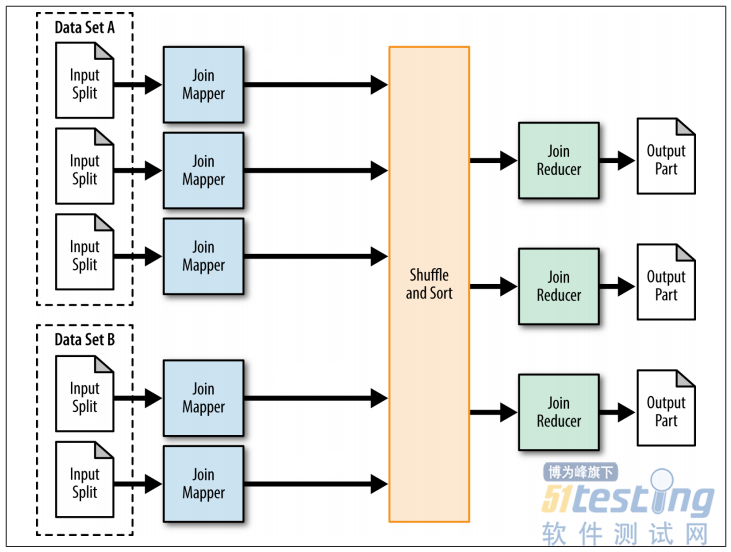
ЁЁЁЁЭМЃКreduceЖЫjoinЕФmapreduceЙ§ГЬ
ЁЁЁЁЯрБШгкmap join, reduce ЖЫjoinЮоЗЈдйmapЙ§ГЬжаЙ§ТЫШЮКЮМЧТМЃЌжЛФмНЋjoinЕФСНеХБэЕФЫљгаЪ§ОнАДееjoin keyНјааshuffle/sortЃЌВЂАДееjoin keyЕФhashжЕНЋ<key,value>ЖдЗжЗЂЕНЬиЖЈЕФreducerЁЃReducerЖдгкЫљгаЕФМќжЕЖджДааjoinВйзїЃЌР§Шч0КХЃЈbookidЕФhashжЕЮЊ0ЃЉreducerЪеЕНЕФМќжЕЖдШчЯТЃЌЦфжаT1ЁЂT2БэЪОМЧТМЕФРДдДБэЃЌЦ№ЕНБъЪЖзїгУЃК

ЁЁЁЁЭМЃКreduceЖЫjoinЕФreducer join
ЁЁЁЁReducerЖЫjoinЮоЗЈБмУтЕФreduceНиЖЯвдМАДЋЪфЕФДѓСПЪ§ОнЖМЛсИјМЏШКЭјТчДјРДбЙСІЃЌДгЩЯЭМПЩвдПДГіЫљгаhash(bookid) % reducer_numberЕШгк0ЕФkey-valueЖдЖМЛсЭЈЙ§shuffleБЛЗжЗЂЕН0КХreducerЃЌШчЙћЗжЕН0КХreducerЕФМЧТМЪ§ФПдЖДѓгкЦфЫћreducerЕФМЧТМЪ§ФПЃЌЯдШЛ0КХЕФreducerЕФЪ§ОнДІРэСПНЋЛсдЖДѓгкЦфЫћreducerЃЌвђДЫДІРэЪБМфвВЛсдЖДѓгкЦфЫћreducerЃЌЩѕжСЛсДјРДФкДцЕШЦфЫћЮЪЬтЃЌетОЭЪЧЪ§ОнЧуаБЮЪЬтЁЃЖдгкjoinдьГЩЕФЪ§ОнЧуаБЮЪЬтЮвУЧПЩвдЭЈЙ§ЩшжУВЮЪ§set Hive.optimize.skewjoin=trueЃЌШУhiveздМКГЂЪдНтОіjoinЙ§ГЬжаВњЩњЕФЧуаБЮЪЬтЁЃ
ЁЁЁЁ4.2 Group by
ЁЁЁЁгяОфЮвУЧЖдuser_read_logБэАДuserid goup byгяОфРДМЬајЬНЬжЪ§ОнЧуаБЮЪЬтЃЌЪзЯШЮвУЧexplain group byгяОфЃК
ЁЁЁЁexplain select userid,count(*) from user_read_log group by userid
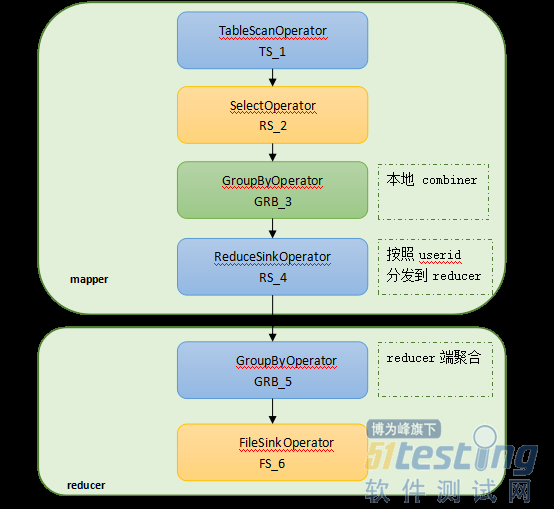
ЁЁЁЁЭМЃКgoup byЕФжДааМЦЛЎ
ЁЁЁЁGroup byЕФжДааМЦЛЎАДееuseridЕФhashжЕЗжЗЂЪ§ОнЃЌЭЌЪБдкmapЖЫвВзіСЫБОЕиreduceЃЌgroup byЕФshuffleЙ§ГЬЪЧАДееhash(userid)РДЗжЗЂЕФЃЌЪЕМЪгІгУжаШежОжаКмЖргУЛЇЖМЪЧЮДзЂВсгУЛЇЛђепЮДЕЧТМЃЌuseridзжЖЮЮЊПеЕФМЧТМЪ§дЖДѓгкuseridВЛЮЊПеЕФМЧТМЪ§ЃЌЕБЫљгаЕФПеuseridМЧТМЖМЗжЗЂЕНЬиЖЈФГвЛИіreducerКѓЃЌвВЛсДјРДбЯжиЕФЪ§ОнЧуаБЮЪЬтЁЃдьГЩЪ§ОнЧуаБЕФжївЊдвђдкгкЗжЗЂЕНФГИіЛђФГМИИіreducerЕФЪ§ОнСПдЖДѓгкЦфЫћreducerЕФЪ§ОнСПЁЃ
ЁЁЁЁЖдгкgroup byдьГЩЕФЪ§ОнЧуаБЮЪЬтЃЌЮвУЧПЩвдЭЈЙ§ЩшжУВЮЪ§
ЁЁЁЁset hive.map.aggr=true (ПЊЦєmapЖЫcombiner);
ЁЁЁЁset hive.groupby.skewindata=trueЃЛ
ЁЁЁЁетИіВЮЪ§ЕФзїгУЪЧзіreduceВйзїЕФЪБКђЃЌФУЕНЕФkeyВЂВЛЪЧЫљгаЯрЭЌжЕИјЭЌвЛИіReduceЃЌЖјЪЧЫцЛњЗжЗЂЃЌШЛКѓreduceзіОлКЯЃЌзіЭъжЎКѓдйзівЛТжMRЃЌФУЧАУцОлКЯЙ§ЕФЪ§ОндйЫуНсЙћЁЃЫфШЛЖрСЫвЛТжMRШЮЮёЃЌЕЋЪЧПЩвдгааЇЕФМѕЩйЪ§ОнЧуаБЮЪЬтПЩФмДјРДЕФЮЃЯеЁЃ
ЁЁЁЁHiveНтОіЪ§ОнЧуаБ
ЁЁЁЁе§ШЗЕФЩшжУHiveВЮЪ§ПЩвддкФГжжГЬЖШЩЯБмУтЕФЪ§ОнЧуаБЮЪЬтЃЌКЯЪЪЕФВщбЏгяОфвВПЩвдБмУтЪ§ОнЧуаБЮЪЬтЁЃвЊОЁдчЕФЙ§ТЫЪ§ОнКЭВУМєЪ§ОнЃЌМѕЩйКѓајДІРэЕФЪ§ОнСПЃЌЪЙЕУjoin keyЕФЪ§ОнЗжВМНЯЮЊОљдШЃЌНЋПезжЖЮЫцЛњИГгшжЕЃЌетбљМШПЩвдОљдШЗжЗЂЧуаБЕФЪ§ОнЃК
ЁЁЁЁselect userid,name from user_info a ЁЁЁЁjoin ( ЁЁЁЁ select case when userid is null then cast(rand(47)*100000 as int) ЁЁЁЁ else userid ЁЁЁЁ from user_read_log ЁЁЁЁ) b on a.userid = b.userid |
ЁЁЁЁШчЙћгУЛЇдкЖЈвхschemaЕФЪБКђОЭвбОдЄСЯЕНБэЪ§ОнПЩФмЛсДцдкбЯжиЕФЪ§ОнЧуаБЮЪЬтЃЌHiveзд0.10.0в§ШыСЫskew tableЕФИХФюЃЌШчНЈБэгяОф
ЁЁЁЁCREATE TABLE user_read_log (userid int,bookid, Ё)
ЁЁЁЁSKEWED BY (userid) ON (null) [STORED AS DIRECTORIES];
ЁЁЁЁашвЊзЂвтЕФЪЧЃЌskew tableжЛЪЧНЋЧуаБЬиБ№бЯжиЕФСаЕФЗжПЊДцДЂЮЊВЛЭЌЕФЮФМўЃЌУПИіжЦЖЈЕФЧуаБжЕжЦЖЈЮЊвЛИіЮФМўЛђепФПТМЃЌвђДЫдкВщбЏЕФЪБКђПЩвдЭЈЙ§Й§ТЫЧуаБжЕРДБмУтЪ§ОнЧуаБЮЪЬтЃК
ЁЁЁЁselect userid,name from user_info a
ЁЁЁЁjoin (
ЁЁЁЁselect userid from user_read_log where pt=ЁЏ2015ЁЏ and userid is not null
ЁЁЁЁ) b on a.userid = b.userid
ЁЁЁЁПЩвдПДГіЃЌШчЙћВЛМгЙ§ТЫЬѕМўЃЌЧуаБЮЪЬтЛЙЪЧЛсДцдкЃЌЭЈЙ§Ждskew tableМгЙ§ТЫЬѕМўЕФКУДІЪЧБмУтСЫmapperЕФБэЩЈУшЙ§ТЫВйзїЁЃ
ЁЁЁЁ4.3 JoinЕФЮяРэгХЛЏ
ЁЁЁЁHiveФкВПЪЕЯжСЫMapJoinResolverЃЈДІРэMapJoinЃЉЁЂSkewJoinResolverЃЈДІРэЧуаБjoinЃЉЁЂCommonJoinResolverЃЈДІРэЦеЭЈJoinЃЉЕШРрРДЪЕЯжjoinЕФВщбЏЮяРэгХЛЏЃЈ/org/apache/hadoop/hive/ql/optimizer/physicalЃЉЁЃ
ЁЁЁЁCommonJoinResolverРрИКд№НЋЦеЭЈJoinзЊЛЛГЩMapJoinЃЌHiveЭЈЙ§етИіРрРДЪЕЯжmapjoinЕФздЖЏгХЛЏЁЃЖдгкБэAКЭБэBЕФjoinВщбЏЃЌЛсВњЩњ3ИіЗжжЇЃК
ЁЁЁЁ1) вдБэAзїЮЊДѓБэНјааMapjoinЃЛ
ЁЁЁЁ2) вдБэAзїЮЊДѓБэНјааMapjoinЃЛ
ЁЁЁЁ3) Map-reduce join
ЁЁЁЁгЩгкВЛжЊЕРЪфШыЪ§ОнЙцФЃЃЌвђДЫБрвыЪБВЂВЛЛсОіЖЈзпФЧИіЗжжЇЃЌЖјЪЧдкдЫааЪБХаЖЯзпФЧИіЗжжЇЁЃашвЊзЂвтЕФЪЧвЊЯёЭъГЩЩЯЪіздЖЏзЊЛЛЃЌашвЊНЋhive.auto.convert.join.noconditionaltaskЩшжУЮЊtrueЃЈФЌШЯжЕЃЉЃЌЭЌЪБПЩвдЪжЙЄПижЦзЊдиНјФкДцЕФаЁБэЕФДѓаЁЃЈhive.auto.convert.join.noconditionaltask.sizeЃЉЁЃ
ЁЁЁЁMapJoinResolver РрИКд№ЕќДњИїИіmrШЮЮёЃЌМьВщУПИіШЮЮёЪЧЗёДцдкmap joinВйзїЃЌШчЙћгаЃЌЛсНЋlocal map workзЊЛЛГЩlocal map join workЁЃ
ЁЁЁЁSkewJoinResolverРрИКд№ЕќДњгаjoinВйзїЕФreducerШЮЮёЃЌвЛЕЉЕЅИіreducerВњЩњСЫЧуаБЃЌФЧУДОЭЛсНЋЧуаБжЕЕУЪ§ОнаДШыhdfsЃЌШЛКѓгУвЛИіаТЕФmap joinЕФШЮЮёРДДІРэЧуаБжЕЕФМЦЫуЁЃЫфШЛЖрСЫвЛТжmrШЮЮёЃЌЕЋЪЧгЩгкВЩгУЕФmap joinЃЌаЇТЪвВЪЧКмИпЕФЁЃСМКУЕФmrФЃЪНКЭжДааСїГЬзмЪЧжСЙиживЊЕФЁЃ
ЁЁЁЁ5 змНс
ЁЁЁЁБОЮФЯъЯИНщЩмСЫДяЙлДѓЪ§ОнЗжЮіЦНЬЈЕФЛљБОМмЙЙКЭдРэЃЌЛљгкhadoop/hiveЕФДѓЪ§ОнЗжЮіЦНЬЈЪЙКЃСПЪ§ОнЕФДцДЂЁЂЗжЮіЁЂЭкОђж№ВНГЩЮЊЯжЪЕЃЌВЂДјРДвтЯыВЛЕНЕФвцДІЁЃзїЮЊЪ§ОнЗжЮіЦНЬЈжїСІОќЕФHiveШдШЛДІдкВЛЖЯЕФЗЂеЙжЎжаЃЌНЋHQLРэНтГЩMapreduceГЬађЁЂРэНтHadoopЕФКЫаФФмСІЪЧИќКУЕФЪЙгУКЭгХЛЏHiveЕФИљБОЁЃДяЙлЪ§ОнЭХЖгвВНЋНєИњММЪѕЗЂеЙГБСїЃЌНсКЯздЩэЕФвЕЮёашЧѓЃЌВЩШЁКЯРэЕФПђМмМмЙЙЃЌЬсЩ§Ъ§ОнЦНЬЈЕФДІРэФмСІЁЃ












