
-
LoadRunner结果分析向导2
2008-02-29 16:17:09

Retries per Second
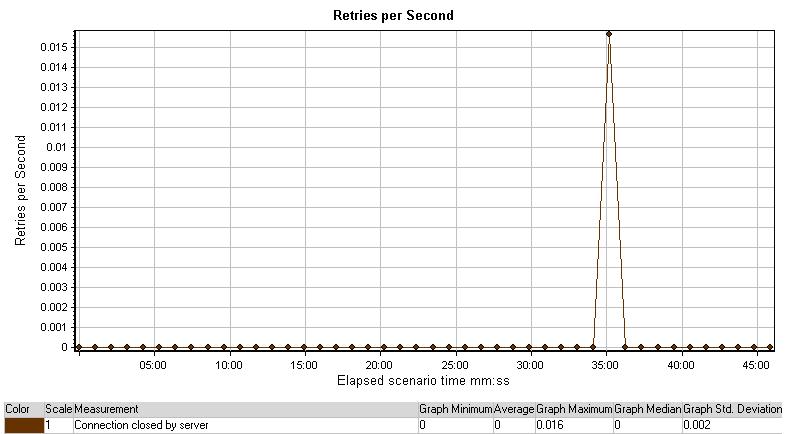
每秒重试图表显示了测试中某一时刻服务器联接重试的数量。图中重试数数大多时刻为0,除了运行到35分钟时,每秒重试数达到0.016每秒.从上图中很难做出结论,因为这个重试的峰值很像一个与其它结果不相关的独立的事件
Connections
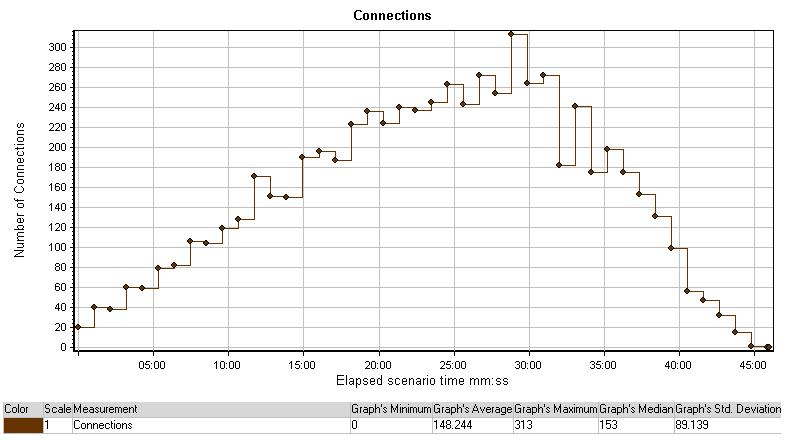
连接图表展示了场景中超时开放TCP/IP联接的数量。一个有超链接的HTML页面可能促使浏览器开放多个连接以打开不同的网页地址。每个网站服务器都会开放2个连接。理论上,打开连接的数量可以反映虚拟用户的运行数。
这张图有助于发现何时需要额外的连接。例如,如果连接的数量攀升到了一个稳定期,而且事务响应时间急剧增长,增加连接可能在执行过程中导致一个戏剧性的增长(事务响应时间的减小)
图中开放连接的数量在到达时间表中的ramp-down之前是不断地增长的。这表明连接的数量即使到达250个用户的压力承受度是足够的。所以,在运行25分钟左右时出现的问题一定是有其它原因。
Connections per Second

每秒连接图表显示每秒新建连接的开放与连接的关闭。通常,新建的连接会反应关闭的连接数,如图中所示。注意图中的峰值,出现在20-35分钟,与此对应的是测试中虚拟用户到达峰值的数量也持续在这段期间。而且,连接的数量在这些结果中看起来没有什么问题
Error Statistics

错误统计表显示了测试期间错误发生的数量,以错误代码分类。连接服务器和本地页面出错是最常出现的。这里的错误代码出现次数最高的是26366和26609.在下面的图表中我们会得到这些错误的详细说明。
Error Statistics (by Descrīption)

错误统计(按类型分类)图表显示了场景或按步执行期间错误增长的数量,这里的错误按类型分类。图中有错误的描述。错误与失败的事务是不同的概念,后者不在此图中统计,因为通常情况下一个独立的错误是不会导致事务失败的。有时由于一个独立事务的失败会出现复合错误.例如,LR运行中会在每一页查找特定字符来核实这些页面是正确的显示,但如果页面没有正确显示,则找不到这个字符,这时会记录一个错误。导致页面显示失败的原因并是文本的检查出现的,而是一些其它也会被LR记录的错误
图中绿色占了大部分,它是与“search”这个文字检查的失败相对应的。第2大的米色部分与HTTP503的状态或是“service temporarily unavailale”(服务暂时不可用)相对应。想要确定错误的原因,需要检查脚本“search”检查字的出现并分析此时虚拟用户需要哪些资源。在每个网站服务器的日志文件中查找服务器响应的503类型,如果是可用的,对确定响应的原因是可能助的。
Errors per Second
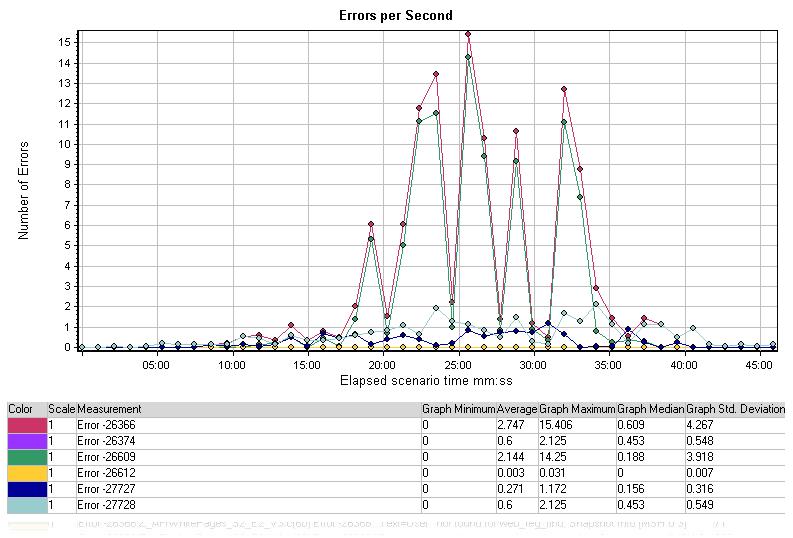
每秒错误图表显示了测试场景中每秒出现错误的平均值,按错误类型分类。在测试结果的分析中,这张表在确定应用程序施压时的具体情况有很大帮助。
图中有20-35分时出现了预期中的峰值,这与其它图相对应。尽管这里没有给出错误的详细描述,但错误出现的主体是在一个确定的时段,使我们可以诊断出异常的行为。下一步可以检查应用程序及数据库组在20-30这一时段产生的各种日志文件。
Errors per Second (by Descrīption)
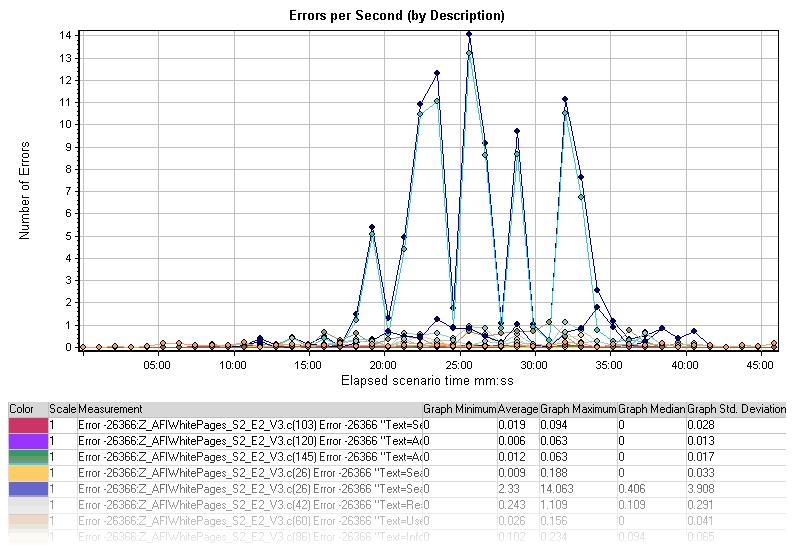
每秒错误(按性质分类)图展示了场景或会话按步运行中,每秒错误的平均数,以错误的性质分类。错误的性质在词汇汇总中有描述。
深蓝色的错误与相同的“Search”这个词的文本检查相对应,而浅蓝色的错误与同样的HTTP状态代码503相对应。相同的查询可以用在诊断这些错误出现的原因上。
Errors per Second – Running Vusers
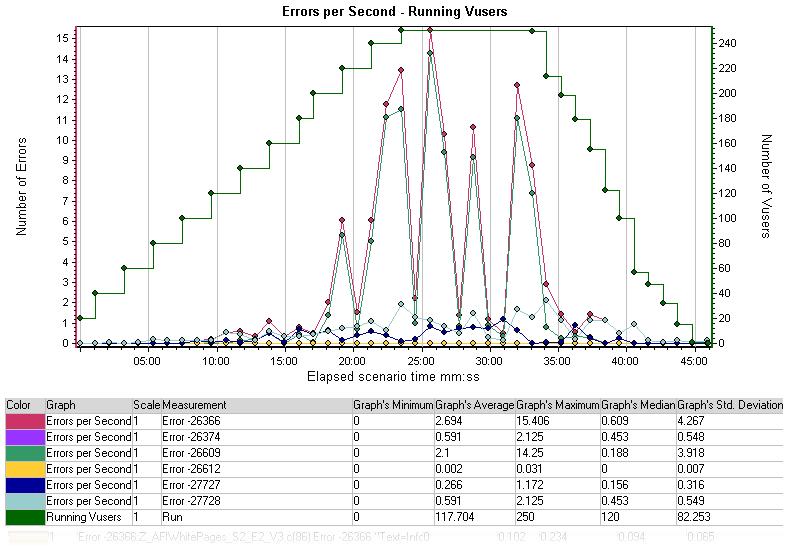
每秒错误数—运行的虚拟用户图表显示的是每秒的覆盖和错误以及在图表Y轴对面显示运行的虚拟用户。
你可以用这张图看到在虚拟用户和每秒错误的数量中是否存在某种关系。
明显在,在运行到20-35分钟时是存在一些关系的。大概从200个虚拟用户开始,错误的峰值达到最大每秒出现15个,并持续到该压力期间的结束,直到35分钟运行到ramp-down为止。
从这些结果中判断问题的下一步就是要在检查在发生错误的时间段内所有有用的日志文件,并且,如果需要的话,可以改变或更新硬件的物理配置以改善性能,并需要返测以证实这些变化是否与期望一样。
-
LR测试积累[原创]
2008-02-29 16:01:33
正在积累中……
一、hits per second/throughput的由来
1、每秒点击率是客户端向服务器发送的请求数,也就是说如果客户端进入了软件系统的界面,那么该界面上的所有图片和控件都会分别作为一次点击数。
2、吞吐量是服务器发送给客户端的数据量,而不包括客户端发送给服务器的请求等。
二、迭代方式
1、 Iteration Number
Iteration Number用当前的迭代数目替换参数。
2、 Random Number
Random Number用一个随机数替换参数。通过指定最大值和最小值来设置随机数的范围。
3、 Unique Number
Unique Number用一个唯一的数字来替换参数。你可以指定一个起始数字和一个块的大小。三、迭代中使用关联参数化方法
注:一定要在参数的文本文档中有回车符
1、 建立一个参数A后,欲使另一参数B与之关联,在参数表中的select next row设置为the same line as A
2、 如图设置
图1
四、标准偏差值STD
标准偏差(Std Dev,Standard Deviation) - 统计学名词。
一种量度数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。标准偏差的大小可通过标准偏差与平均值的倍率关系来衡量。
标准偏差公式:S = Sqr(∑(xn-x拨)^2 /(n-1))
公式中∑代表总和,x拨代表x的算术平均值,^2代表二次方,Sqr代表平方根。
例:有一组数字分别是200、50、100、200,求它们的标准偏差。
x拨 = (200+50+100+200)/4 = 550/4 = 137.5
S^2 = [(200-137.5)^2+(50-137.5)^2+(100-137.5)^2+(200-137.5)^2]/(4-1) =[62.5^2+(-87.5)^2+(-37.5)^2+62.5^2]/3 =[3906.25+7656.25+1406.25+3906.25]/3 = 16875/3 = 5625
标准偏差 S = Sqr(5625) = 75该值用于衡量LR的曲线图中所选取的若干点的值之间的偏差大小,如果超过一定标准,则说明软件过于不稳定。
五、SAP/SDP
SAP (Session Announcement Protocol )::会话通告协议。RFC2974,主要的作用就是告诉接收者,要多播一些什么内容。没有定义描述的格式
SDP:(Session Descrīption Protocol):会话描述协议。 规定了格式,就是对会话的必要信息如何编码,不过不包括传输机制和协商参数。 SDP语法,采用文字,而不是ASN.1。一个SDP会话描述以会话级信息 和 媒体级信息开始,如果出现一个,另外一个接着后面出现。
六、合并图和关联图
将两个图联系起来,就会看到一个图的数据会对另一个图的数据产生影响。这称为将两
个图关联。例如,您可以将正在运行的 Vuser 图和平均事务响应时间图相关联,来了解
大量的 Vuser 对事务的平均响应时间产生的影响。
1 在图树中单击“正在运行的 Vuser”,查看正在运行的 Vuser 图。
2 右键单击正在运行的 Vuser 图并选择“合并图”。
3 在“选择要合并的图”列表中,选择“平均事务响应时间”。
4 在“选择合并类型”区域中,选择“关联”,然后单击“确定”
七、录制脚本方法
1、Sniffer方法:利用以太网的广播特性。嗅探器。但要求客户机与服务器在同一网段。
2、Proxy方法(代理):客户端发送到Vugen,再由Vugen发送给服务器。在客户端与服务器之间增加了LR。
八、客户端永远是发送请求,而服务器处理
LR录制的record log里面与工具charles以及实际网页文件的大小都是一致的。
九、录制模式HTTP/URL
Html-based scrīpt(browser/context sensitive)把隶属于一个页面的数据放在一个模块中。
URL(http/analog)真实记录C/S之间全部过程。
2种方式的使用:WEB或B/S结构控件过多的flash等,应使用HTML方式。可以浓缩。可读性好。实质上是一样的。
HTML记录的是web_submit_form
URL是web_submit_data,且支持控件。
十、常见错误
1、录制的脚本为空/录制出错/无法打开首页等:
空:协议选择错误/非B/S操作/打开页面时页面从缓存取出的,也是无法录制下来的/
使用代理/IE使用选项/有恶意代码(检测使用工具:AD-AWARD)/bofu防火墙或防病毒软件
录制出错:出错时使用CODE VIEW,即使出错也能把代码记录下来,而使用TREE VIEW则会停止记录
打开空网页:VUGEN有问题/LR安装路径BIN下Registe_vugen.bat(重新注册一次可能修复)
2、脚本出错
十一、协议选择
LR8中单协议HTTP,在IE中设置一个7777localhost端口,C与B之间都由7777连接,采集所有信息;多协议中单选HTTP协议,指定端口的影射
判断协议工具:PROCESSSPY(正在使用的.DLL分析使用的协议)
十二、关联
是服务器到客户端的数据,函数web_reg_save_param(“param name”,<list of attributes>*,last)
“param name”是参数名,list of attributes分为三部分:“LB=”“RB=”“ORD=”,分别指左边界、右边界和符合条件的第一个,最后一个可以写ORD=ALL,意为全部取出来。而LAST没有,写LB/RB时,写入引号需要转义符。
十三、思考时间
没有:压力会大一些
有:压力会小一些但会比较符合实际等待时间
十四、.net内存分析
1、堆栈——放的是局部变量、方法参数、返回值和其他临时值
2、托管堆——0级、1级、2级,用于分配托管对象的区域,也是垃圾回收器区域
3、非托管堆——用于运行时数据结构、方法表、microsoft中间语言(MSIL)、JITed代码
垃圾回收器只是回收了托管堆的内存,堆栈是自动释放的,非托管堆由非托管堆内代码自动控制,而托管堆也有可能内存泄露
.net常用性能测试指标:
1、Process/Private bytes一个进程所独占的内存是多少,无法跟其他进程共享
2、.net CLR Memory/#Bytes in All Heaps托管堆内总使用内存数
3、.net CLR LocksAnd Threads/# of current logical Threads,在.net运行过程中所使用的线程,注意:线程里面所使用的内存是在堆栈里面分出来的
举例:
a)1不让其增长,2没变,可能是非托管堆性能有问题,因为整个内存增加,而托管堆内存的没有变的
b)3增长,1增长,线程泄露,导致内存泄露
c)
堆栈内存泄露(StackOverflowException)
可能引起堆栈内存泄露的原因:
1、栈资源并且从不返回的方法调用
2、线程泄露
每分配一次堆栈后没有回收回来,就是线程泄露,严重会出现StackOverflowException异常
最新的桌面机与服务器版的WINDOWS堆栈大小为1MB
3、托管堆的内存泄露
大对像的内存碎片——如果在栈中申请有9千个字节,它不会放在堆栈中,而是在堆中。.net不会做压缩处理,不断地申请回收,可能会出现内存碎片问题导致泄露
不必要的根引用
中年危机
使用工具CLEprofiler.exe,不断申请回收大字节进行监控
十五、LR解密
Lr_decrypt,把加密函数进行解密
Action()
{
Char *str=”abc”
Char *str1;
lr_load_dll(“encode1.dll”)// 加载动态连接库,encode1.dll是.dll文件名
str1=(char *)crypt_encrypt(str)//调用接口将字符变量str放到.dll文件中去,crypt_encrypt //Dll文件发布了一个接口
lr_output_message(“encrypted=%s”,str1);
lr_out_message(“%s world”,lr_decrypt(str1); //解密
加密的话需要用外部的加密方法,使用LR自带工具或自己编写.DLL文件。
十六、写入错误的用户名和密码不出错
加检查点
要insert的地方右键addstep/ web_reg_find/增加search test/
文件。
-
LR结果分析1
2007-12-07 14:11:42
有些地方写得不够清楚,待改进~
这只是1,晚些时候还有2
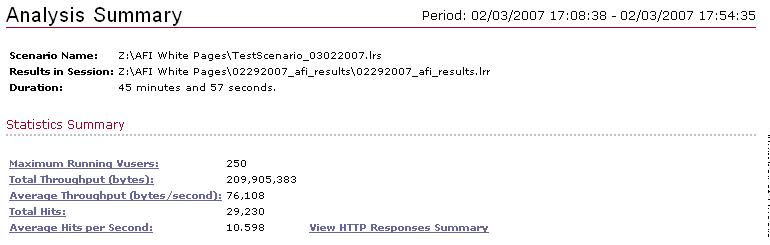
分析总结页面划分了三个主要的段,统计总结、事务总结以及HTTP响应总结。统计总结列出了在场景中统计的全部影响。
你可以在运行Vusers的顶点和场景运行的整个期间(这个阶段是17:08:38 – 17:54:35, 有 46分钟),对比吞吐量和统计点击率。
用户的数量和整个运行时间,就是衡量服务器/应用程序可承受吞吐量和点击率的性能了么?你必须对服务器/数据库性能和配置有更多的了解才可以确定。
下一个分析总结部分是事务总结,包括了每个单独的事务的统计,他们的回应时间(最小,平均,最大和标准偏差)
图中的“90 Percent”统计指出事务在当前行90%的最大响应时间。在这个统计数值之上,你可以知道90%的“A_MainPage_AFI…”这件事务最大的响应时间是94.845秒
成功和失败事务都列在这个部分里。前缀为“Z_”的事务包含了脚本中使用的所有事务统计的总和
所有的成功事务在“Z_”事务中至多等于最少通过的单独事务,这里不包括Vuser_init/end这两个事务,这是因为“Z_”事务记录了整个脚本流的统计数字,而不只是一个单独事务。如果脚本中一个用户成功执行所有的步骤,从开始到结束,只有这个时候,“Z_”事务的成功值会上升。无论如何,如果失败发生在脚本中的某一点,则事务失败的数量在发生失败的地方将会增加,并且“Z_”的失败事务数值也会随之增加。
在这个统计数字的基础上,“Z_”事务中成功事务的总数为776,符合最少成功的单独事务“E_ResultsDisplay…”,而在另一方面,“Z_“的总的失败数是所有事务之和
最后部分的分析总结是HTTP响应总结,这包括了在测试过程中所有HTTP响应的总数和每秒统计的记录。最常出现的信号就是HTTP200,表明成功。这个HTTP所有响应的列表和它们的含意可以在术语表中查看附加的文档
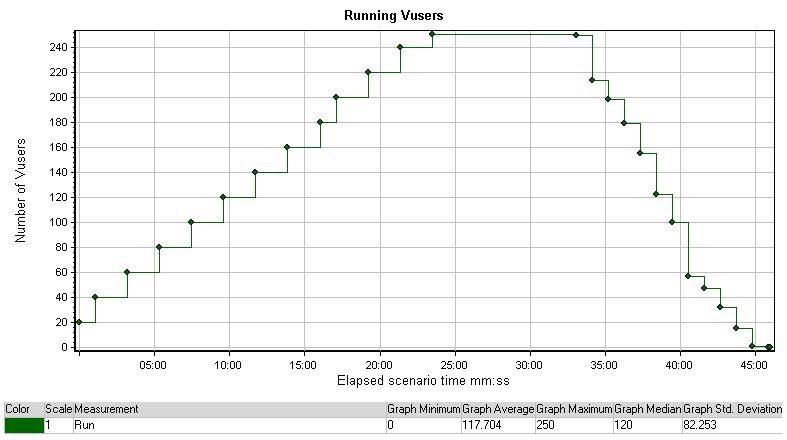
Running Vusers
运行的用户图表显示了虚拟用户在场景中当前执行脚本的情况。一个虚拟用户按照测试脚本执行一次任务直到全部结束,这个用户已经执行了所需脚本的所有重复(iterations)除非手工停止controller中的用户
虚拟用户会在渐增的场景中被增加,不像上图中所有用户同时被加载,在虚拟用户的数量在压力测试计划中到达一个高度之后,会保持这些用户运行一段时间,再使用户数递减,递减的速度要比递增的快,因为从移除用户对服务器几乎没有任何不利影响。
无论什么时候,在测试中出现问题,你都应该知道当前场景中的用户数量。压力测试的目的是诊断程序在虚拟压力下出现的问题,所以,当虚拟用户的数量达到某个值时,会看到数据都在减少,这可以说明程序的不稳定。突发的数据向相反方向(正或负)的延伸都意味着运行的虚拟用户在增加中
这张图表遵循着标准的测试时间表,每分钟增加10个用户,到达最大用户数250时运行10分钟,之后每分钟减少25个用户
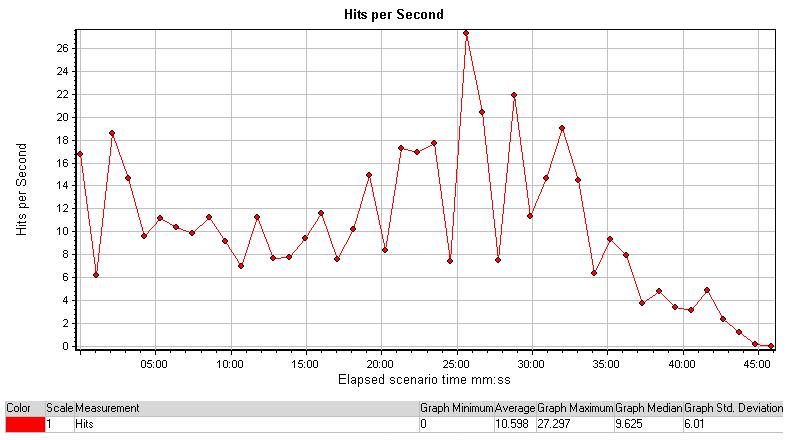
Hits per Second
每秒点击率显示在网站服务器上随着时间推移的点击数量。这个图表可以显示整个场景或者最后60、180、600或3600秒的情况。你可以将它与事务响应时间图表对比来查看点击是如何影响事务的执行的。
每秒点击率的增涨表明服务器负荷的增加,所以将每秒点击率与事务响应时间和吞吐量对比,可以让你对服务器在压力下的执行有更多理解。当一个网站服务器正在活动中,每秒点击率将会时常镜像成功的HTTP响应信号的总数。在上图中运行的第25分钟左右到达了尖锋。这可以在诸如运行的用户数、吞吐量和事务响应时间中这些图表中找到答案。
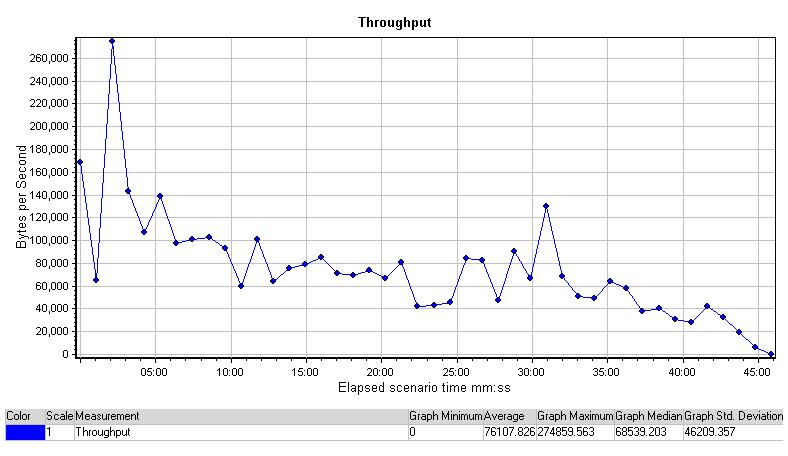
Throughput
Throughput(吞吐量)展示了数据的总量,它基于字节,由网页服务器每秒向传送scenario的运行情况. Throughput 是基于字节/秒来传输的,它描述通过网络服务器传输的数据在网络上任意事件发生时的传输量。完美的吞吐量应该是随着每秒点击率的增加而增加,这种增加是建立在带宽足够处理用户提出的所有请求的基础上的。
在比较吞吐量和每秒的点击率中你可以获得服务器在执行过程中的信息。如果服务器如预期的一样在执行,那么吞吐量会随着它每秒的点击量的增加而增加。这是期望实现的情况,因为点击增加一次就会需要服务器发送更多的返回信息给用户。无论如何,如果点击的次数增加而吞吐量恒定或减少,就说明服务器无法执行增加的请求(每秒点击率),结果就是事务反应时间的增加。
这个图表在展示了一个吞吐量在整个测试中普遍下降的情况,在前25分钟,这种减少的数量是少量却明显的,刚好对应了Hits per Sencond的图表的尖锋时刻,比较这些统计的数字,最好的方法就是把这些图表结合起来。
这张图表展示了整个测试过程中吞吐量的一个正常减少,在25分钟前面这里,减少的数量不大却也清晰,与上一张图表Hit per Second正好对应,单纯的这些统计数字还是不如整体对比的看所有图表来得准确详细
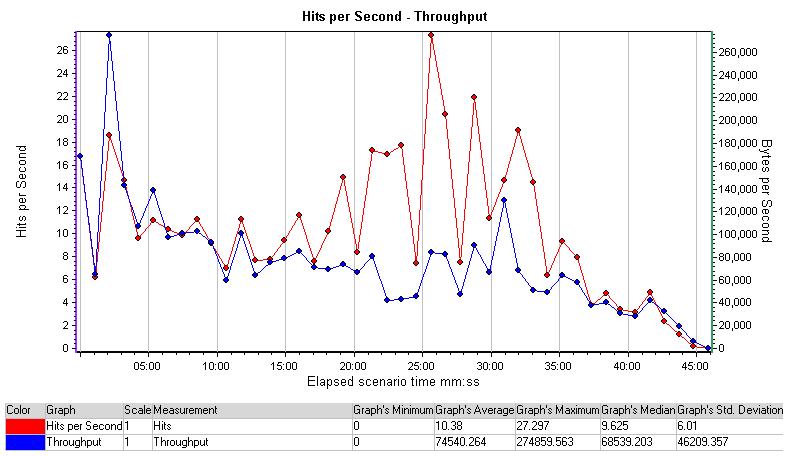
Hits per Second - Throughput
这张图表是把hits per second和 throughput两图结合起来的结果,我们可以看到在25分钟前后,每秒的点击的爆增和吞吐量的减少是相应的。如果一台服务器的业务量低于最大负载量,则每秒点击率通常
会映射吞吐量。上述图表中的结果最有可能的情况是由于用户负载的增加,因为更多用户将会引起每秒点击率的增长,并且当服务器不再处理大量的请求的时候,吞吐量将会减少。
说到后面的RunningVusers图表,我们知道在前25分钟,加载250个用户会使其到达峰值,由此,预期的每秒点击率的增长和吞吐量的减少说明了服务器的负载已经达到了它的最大值。我们可以预计事务的处理时间和每秒可能发生的错误也会在25分钟前后达到峰值。
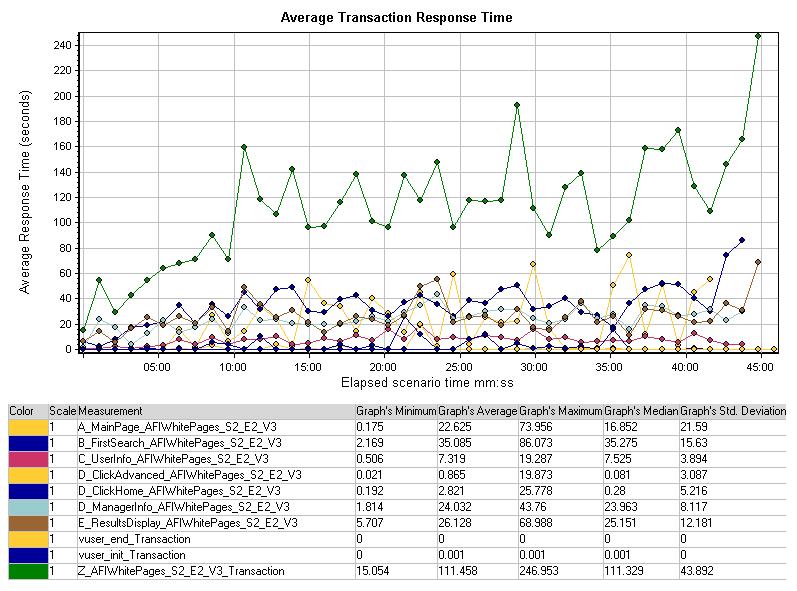
Average Transaction Response Time
平均事务处理时间图表显示了平均每个事务的结束的反应时间。反应时间是从客户端请求到服务器响应的全部时间。通常的响应时间会与当前在测试场景中运行的Vusers的数量一致。
响应时间增加的最通常的原因是运行的用户增加,因为随着用户进入测试场景的增加,服务器的工作量也会增加。服务器会花时间去响应一个增加的负载,于是平均响应时间就会增长。
上述图中我们预期到响应的增长时间,这与其它图表中在25分钟前后的数据变化一致。看一下响应时间中的“Z_AFIWhitePages_s2_e3_v3_Transaction”事务,这是最早能分析常规行为的方法,并且进入场景后的10分钟里,总的响应时间增长到110秒左右。在10分钟的时候Vusers运行的人数达到120,所以与前面对比,服务器开始了很大的工作量。
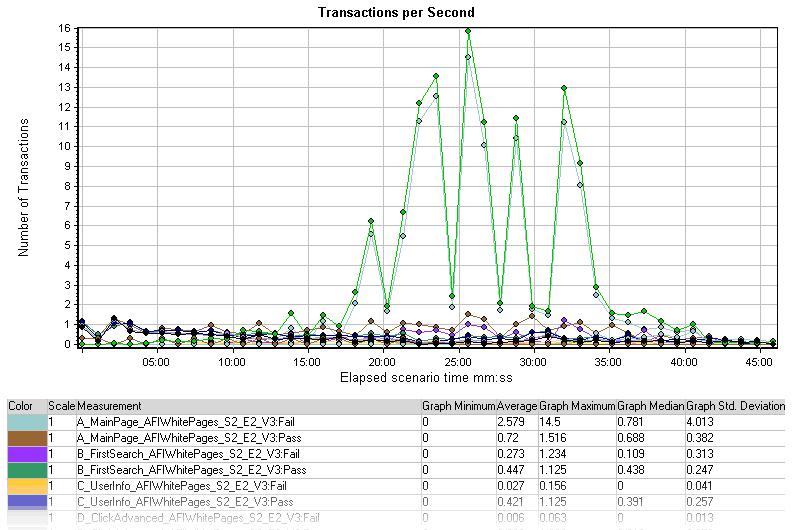
Transactions per Second (Passed/Failed)
每秒事务图表显示了随着时间推移,事务成功和失败的数量。一个事务表示单独的一个步骤或一个虚拟用户在一组用户中的执行。例如,这个过程是在一个事务中并发测试在网站上进入并确认登录信息
在规定时间内测试场景中的每秒事务数与运行的虚拟用户数相一致,并且随着虚拟用户的增加,每秒事务数也会增加。如果随着虚拟用户的减少,每秒事务数也会减少,这时场景中很可能出现了问题。你应该先对比运行的虚拟用户数量与每秒事务图,以核实一次虚拟用户的增加是否导致每秒点击率、事务响应时间和吞吐量的增加,将这些统计数据放到一起会帮助你找出问题发生的主要原因
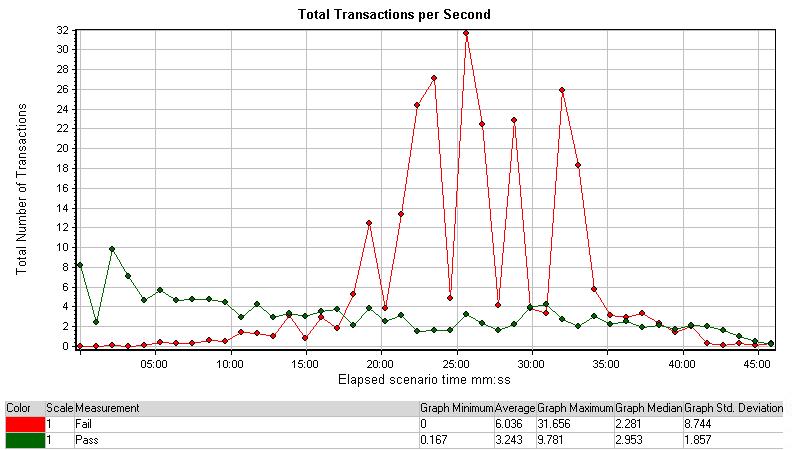
Total Transactions per Second
每秒总事务图显示的是在测试场景的运行中,所有事务通过与失败的总和。我们可以清晰地看到所有事务的运行情况,像上一张图表一样,有更多特定的每秒事务,这张图表中红线代表失败的总数,说明正在运行的服务器由于一个用户已经超出它可以承载的最大能力
图中的红线说明事务失败的总数,在25分钟左右的时候出现了预期的峰值,表明服务器已经超出了可以承受用户的最大值。注意在35分钟前锐减的错误,这与测试中虚拟用户的减少相对应
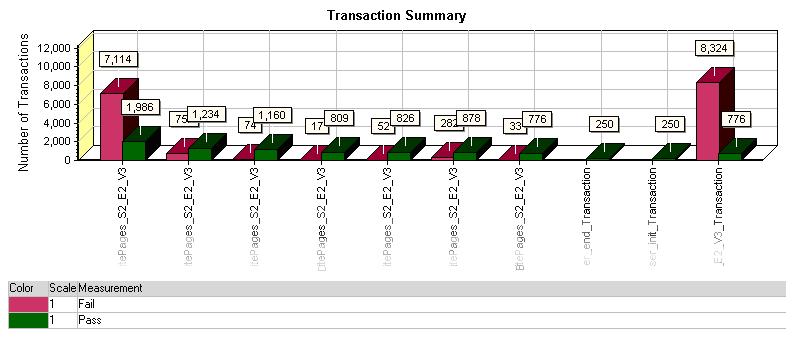
交易总数图表显示测试场景中所有成功、失败和停止事务的的记录。成功的事务是完全成功的,失败的事务是由于未预期事件的出现(一个页面的加载失败,登录失败等)导致的,停止的事务是指没有满足成功或失败条件
分析这张图表你可以发现事务成功/失败的比率,并确定哪个事务看起来需要更多注意。单一事务的大量失败表明在测试场景中有某类型的问题在一个时刻出现了,出现这种问题的原因可能是某个服务器或页面的问题。此外,分析其它结果会有助于确定事务失败的特殊原因。
例如,最右侧的事务失败率达到91.47%,明显地这已经超出了预期值。通过分析其它图表,你会发现它们精确地说明这个事务的失败情况。单独的事务同时出现通过与失败,暗示着场景中在某一点出现了问题。所以对比运行虚拟用户的数量、响应时间和吞吐量是有必要的。
注意这里的“Z_”事务,以且所有出现失败事务的总和,这个值总是大于任意一个单独事务失败的事务
Transaction Performance Summary
事务每秒执行总结图表除了在测试场景中规定了最小值、平均值、最大值响应时间之外与事务总结图表相似,
最右侧的事务是“Z_”事务,它在图中有最大值,因为它是所有事务之和。没有哪个事务单独表现出比其他事务高很多的响应时间,但是左边数第二个事务有30.2秒的平均响应时间值。如果可以得到此事务所需资源的更多信息(包括完成数据库的操作,服务器是否正常接收数据),你就会发现高出平均响应时间的原因。
在这个例子中,0响应时间的事务是当虚拟用户被加载和退出测试场景时的初始化和终止,可以忽略不计。如果测试计划需要,初始化和终止行为中可以包含多个动作,例如场景在总共的三个部分中都需要事务,可以在进入程序时一次(初始化),执行动作时根据设置的次数运行,然后退出程序(终止)
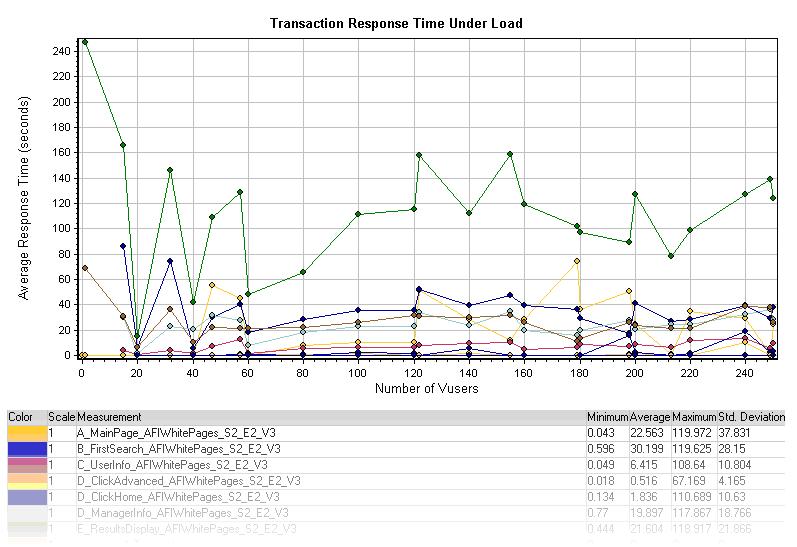
Transaction Response Time (Under Load)
事务响应时间(压力下)图表是运行的虚拟用户和平均事务响应时间表的一个结合。它显示了在测试场景的某一时刻事务响应时间与虚拟用户运行的数量是有关系的。这张图表有助于观察虚拟用户加载和分析平缓加载的场景对响应时间产生的影响
平缓的加载使你可以侦测到当虚拟用户数量达到多少时,事务响应时间会出现不好的变化。通过对比测试时间表与这张图表的统计数字,你可以确定响应时间的一个峰值与虚拟用户的增长是否相对应,否则你只能在其它地方找到问题出现的原因。
图中的加载0-20位用户时的平均响应时间是可以被忽略的,因为测试是从20个用户开始的。非常高的响应时间是因为LR测试软件本身的资源使用,且从0-20用户在测试中没有任何的影响。用户初始化后,运行40用户时,平均响应时间锐减。最可能的原因是这40个用户在不同的网页/服务器之间重新被分配,之后到达60用户
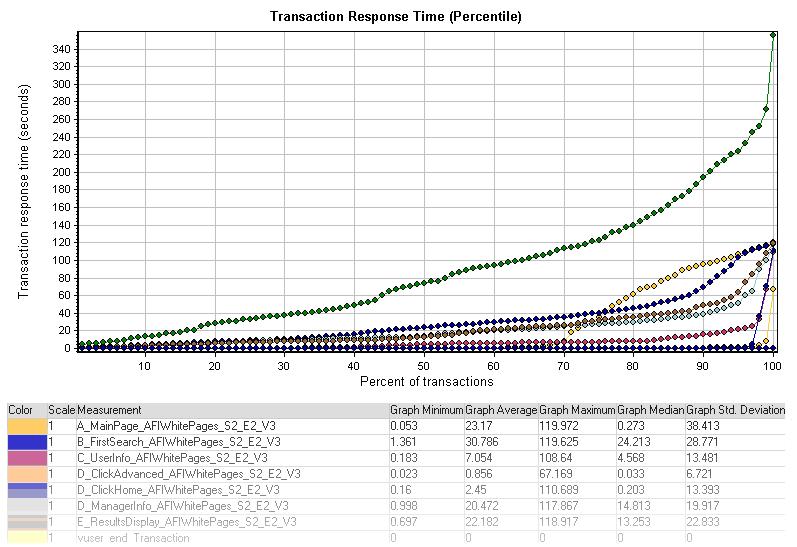
Transaction Response Time (Percentile)
事务响应时间显示了事务在一定时间内的响应百分比。图中事务的平均响应时间(绿线)到达90%时,响应时间已经超过了200秒。基于这点还很难作出结论,不同于普通的观察。例如,事务在到达90%时的响应时间比在10%时要多。也很难直接地用其它图表而不用这张图表,因为在X轴上衡量事务百分率这部分数据,想要在这些统计数据的基础上做出对比的结论实在困难。
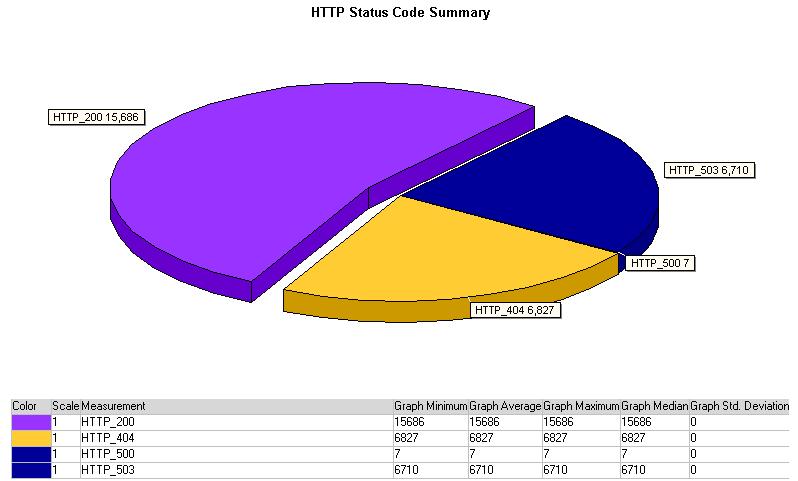
HTTP Status Code Summary
HTTP状态标准总结包含了饼图显示了HTTP响应数量的集合,它按照状态分类。在多数测试中主要的响应标准是200,成功。图中50%的部份是200,25%是500(失败),另25%是请求页面404(未找到)。HTTP响应的详细标准和含义在附加的词汇表中说明
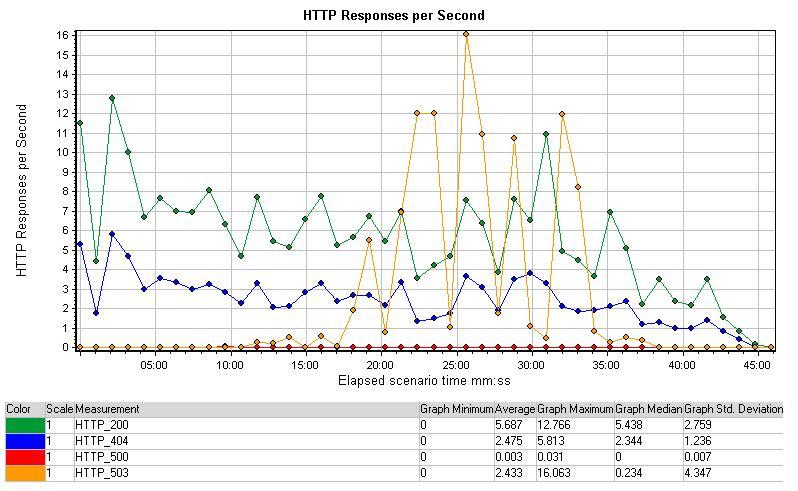
HTTP Responses per Second
HTTP每秒响应图统计的是HTTP响应的状态标准,最常用的标准有200(成功),302(重定向),404(未找到)和500(内部服务器问题)。增加的HTTP响应意味着服务器正在处理更多的请求,并成功发送一个HTTP的响应给用户。
图中测试的整个过程中,“成功”响应标准与“页面未找到”标准的数量相对稳定,在响应503标准在18分钟时开始出现了一个峰值,这说明服务器无法获得请求,在25分钟的时候503标准的每秒响应相当的大,达到每秒16次,说明这时服务器已经超出它可承受的最大值,此结论被其它结果支持。



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}