

python中有许多内置函数,不像print那么广为人知,但它们却异常的强大,用好了可以大大提高代码效率。
这次来梳理下8个好用的python内置函数。
1、set()
当需要对一个列表进行去重操作的时候,set()函数就派上用场了。
obj = ['a','b','c','b','a'] print(set(obj)) # 输出:{'b', 'c', 'a'} |
set([iterable])用于创建一个集合,集合里的元素是无序且不重复的。
集合对象创建后,还能使用并集、交集、差集功能。
A = set('hello') B = set('world') A.union(B) # 并集,输出:{'d', 'e', 'h', 'l', 'o', 'r', 'w'} A.intersection(B) # 交集,输出:{'l', 'o'} A.difference(B) # 差集,输出:{'d', 'r', 'w'} |
2、eval()
之前有人问如何用python写一个四则运算器,输入字符串公式,直接产生结果。
用eval()来做就很简单:
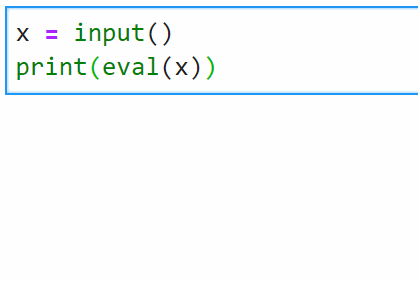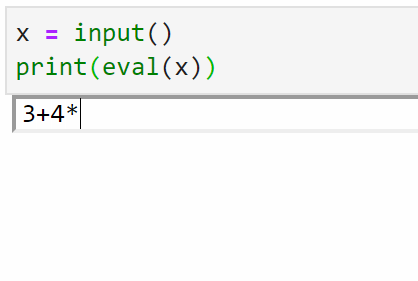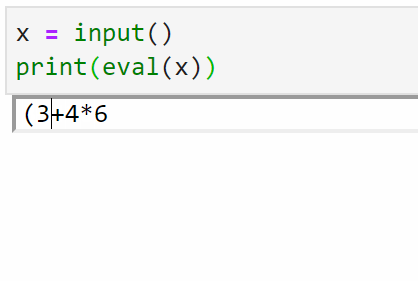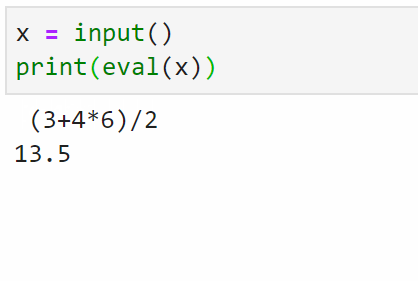
eval(str_expression)作用是将字符串转换成表达式,并且执行。
a = eval('[1,2,3]') print(type(a)) # 输出:<class 'list'> b = eval('max([2,4,5])') print(b) # 输出: 5 |
3、sorted()
在处理数据过程中,我们经常会用到排序操作,比如将列表、字典、元组里面的元素正/倒排序。
这时候就需要用到sorted() ,它可以对任何可迭代对象进行排序,并返回列表。
对列表升序操作:
a = sorted([2,4,3,7,1,9]) print(a) # 输出:[1, 2, 3, 4, 7, 9] |
对元组倒序操作:
sorted((4,1,9,6),reverse=True) print(a) # 输出:[9, 6, 4, 1] |
使用参数:key,根据自定义规则,按字符串长度来排序:
chars = ['apple','watermelon','pear','banana'] a = sorted(chars,key=lambda x:len(x)) print(a) # 输出:['pear', 'apple', 'banana', 'watermelon'] |
根据自定义规则,对元组构成的列表进行排序:
tuple_list = [('A', 1,5), ('B', 3,2), ('C', 2,6)] # key=lambda x: x[1]中可以任意选定x中可选的位置进行排序 a = sorted(tuple_list, key=lambda x: x[1]) print(a) # 输出:[('A', 1, 5), ('C', 2, 6), ('B', 3, 2)] |
4、reversed()
如果需要对序列的元素进行反转操作,reversed()函数能帮到你。
reversed()接受一个序列,将序列里的元素反转,并最终返回迭代器。
a = reversed('abcde') print(list(a)) # 输出:['e', 'd', 'c', 'b', 'a'] b = reversed([2,3,4,5]) print(list(b)) # 输出:[5, 4, 3, 2] |
5、map()
做文本处理的时候,假如要对序列里的每个单词进行大写转化操作。
这个时候就可以使用map()函数。
chars = ['apple','watermelon','pear','banana'] a = map(lambda x:x.upper(),chars) print(list(a)) # 输出:['APPLE', 'WATERMELON', 'PEAR', 'BANANA'] |
map()会根据提供的函数,对指定的序列做映射,最终返回迭代器。
也就是说map()函数会把序列里的每一个元素用指定的方法加工一遍,最终返回给你加工好的序列。
举个例子,对列表里的每个数字作平方处理:
nums = [1,2,3,4] a = map(lambda x:x*x,nums) print(list(a)) # 输出:[1, 4, 9, 16] |
6、reduce()
前面说到对列表里的每个数字作平方处理,用map()函数。
那我想将列表里的每个元素相乘,该怎么做呢?
这时候用到reduce()函数。
from functools import reduce nums = [1,2,3,4] a = reduce(lambda x,y:x*y,nums) print(a) # 输出:24 |
reduce()会对参数序列中元素进行累积。
第一、第二个元素先进行函数操作,生成的结果再和第三个元素进行函数操作,以此类推,最终生成所有元素累积运算的结果。
再举个例子,将字母连接成字符串。
from functools import reduce chars = ['a','p','p','l','e'] a = reduce(lambda x,y:x+y,chars) print(a) # 输出:apple |
你可能已经注意到,reduce()函数在python3里已经不再是内置函数,而是迁移到了functools模块中。
这里把reduce()函数拎出来讲,是因为它太重要了。
7、filter()
一些数字组成的列表,要把其中偶数去掉,该怎么做呢?
nums = [1,2,3,4,5,6] a = filter(lambda x:x%2!=0,nums) print(list(a)) # 输出:[1,3,5] |
filter()函数轻松完成了任务,它用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象。
filter()函数和map()、reduce()函数类似,都是将序列里的每个元素映射到函数,最终返回结果。
我们再试试,如何从许多单词里挑出包含字母w的单词。
chars = chars = ['apple','watermelon','pear','banana'] a = filter(lambda x:'w' in x,chars) print(list(a)) # 输出:['watermelon'] |
8、enumerate()
这样一个场景,同时打印出序列里每一个元素和它对应的顺序号,我们用enumerate()函数做做看。
chars = ['apple','watermelon','pear','banana'] for i,j in enumerate(chars): print(i,j) ''' 输出: 0 apple 1 watermelon 2 pear 3 banana ''' |
enumerate翻译过来是枚举、列举的意思,所以说enumerate()函数用于对序列里的元素进行顺序标注,返回(元素、索引)组成的迭代器。
再举个例子说明,对字符串进行标注,返回每个字母和其索引。
a = enumerate('abcd') print(list(a)) # 输出:[(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd')] |
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












