

19.3.7、实现基本的数据库操作
在动态Web应用中,数据库技术永远是核心技术中的核心技术。Django模型是与数据库相关的,与数据库相关的代码一般保存在文件models.py中。Django框架支持SQLite3、MySQL和PostgreSQL 等数据库工具,开发者只需要在文件 settings.py 中进行配置即可,不用修改文件models.py中的代码。下面的实例代码演示了在Django框架中创建SQLite3数据库信息的过程。
实例19-12 创建SQLite3数据库信息
源码路径 daima\19\19-12
(1)新建一个名为"learn_models"的项目,然后进入"learn_models"文件夹中,并新建一个名为"people"的app。
django-admin startproject learn_models # 新建一个项目 cd learn_models # 进入到该项目的文件夹 django-admin startapp people # 新建一个 people 应用(app) |
(2)将新建的应用(people)添加到文件 settings.py中的INSTALLED_APPS中,也就是告诉Django有这么一个应用。
INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'people', ) |
(3)打开文件people/models.py,新建一个继承自类models.Model的子类Person,此类中有name和age这两个字段。具体实现代码如下所示。
from django.db import models class Person(models.Model): name = models.CharField(max_length=30) age = models.IntegerField() def __str__(self): return self.name |
在上述代码中,name和age这两个字段中不能有双下划线"__",这是双下划线因为在Django QuerySet API中有特殊含义(用于关系,包含,不区分大小写,以什么开头或结尾,日期的大于、小于,正则表达式等)。另外,也不能有Python中的关键字。所以说name是合法的,student_name也是合法的,但是student__name不合法,try、class和continue也不合法,因为它们是Python的关键字。
(4)开始同步数据库操作,在此使用默认数据库SQLite3,无须进行额外配置。具体命令如下所示。
| # 进入 manage.py 所在的那个文件夹并输入这个命令 python manage.py makemigrations python manage.py migrate |
通过上述命令可以创建一个数据库表,当在前面的文件models.py中新增类Person时,运行上述命令后就可以自动在数据库中创建对应数据库表,不用开发者手动创建。在CMD控制台中运行后,会发现Django生成了一系列的表,也生成了上面刚刚新建的表 people_person。CMD 运行界面如图 19-20所示。
(5)在CMD控制台中,输入命令进行测试。整个测试过程如下所示。
$ python manage.py shell >>>from people.models import Person >>>Person.objects.create(name="haoren", age=24) <Person: haoren> >>>Person.objects.get(name="haoren") <Person: haoren> |
19.3.8、使用Django后台系统开发博客系统
在动态Web应用中,后台管理系统十分重要,网站管理员通过后台实现对整个网站的管理。Django框架的功能十分强大,为开发者提供了现成的admin后台管理系统,程序员只需要编写很少的代码就可以实现功能强大的后台管理系统。下面的实例代码演示了使用Django框架开发博客系统的过程。
实例19-13 开发个人博客系统
源码路径 daima\19\19-13
(1)新建一个名为"zqxt_admin"的项目,然后进入"zqxt_admin"文件夹中,并新建一个名为"blog"的app。
| django-admin startproject zqxt_admin cd zqxt_admin # 创建 blog 这个 app python manage.py startapp blog |
(2)修改"blog"文件夹中的文件models.py。具体实现代码如下所示。
from __future__ import unicode_literals from django.db import models from django.utils.encoding import python_2_unicode_compatible @python_2_unicode_compatible class Article(models.Model): title = models.CharField('标题', max_length=256) content = models.TextField('内容') pub_date = models.DateTimeField('发表时间', auto_now_add=True, editable=True) update_time = models.DateTimeField('更新时间', auto_now=True, null=True) def __str__(self): return self.title class Person(models.Model): first_name = models.CharField(max_ length=50) last_name = models.CharField(max_ length=50) def my_property(self): return self.first_name + ' ' + self. last_name my_property.short_description = "Full name of the person" full_name = property(my_property) |
(3)将"blog"加入到settings.py文件中的INSTALLED_APPS中。具体实现代码如下所示。
INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog', ) |
(4)通过如下所示的命令同步所有的数据库表。
| # 进入包含有 manage.py 的文件夹 python manage.py makemigrations python manage.py migrate |
(5)进入文件夹"blog"中,修改里面的文件admin.py(如果没有新建一个)。具体实现代码如下所示。
from django.contrib import admin from .models import Article, Person class ArticleAdmin(admin.ModelAdmin): list_display = ('title', 'pub_date', 'update_time',) class PersonAdmin(admin.ModelAdmin): list_display = ('full_name',) admin.site.register(Article, ArticleAdmin) admin.site.register(Person, PersonAdmin) |
输入下面的命令启动服务器。
| python manage.py runserver |
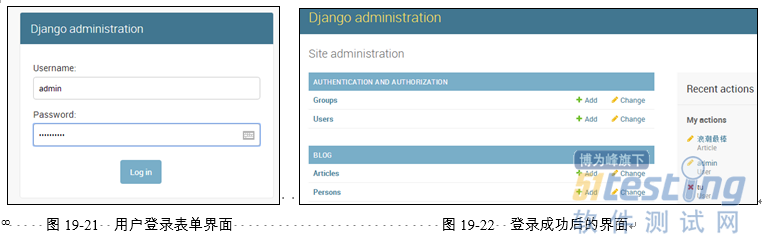
然后,在浏览器中输入"http://localhost:8000/admin"会显示一个用户登录表单界面,如图19-21所示。
可以创建一个超级管理员用户,在CMD控制台中,使用命令进入包含manage.py的文件夹"zqxt_admin"中。接下来,输入如下命令创建一个超级账号,根据提示分别输入账号、邮箱地址和密码。
| python manage.py createsuperuser |
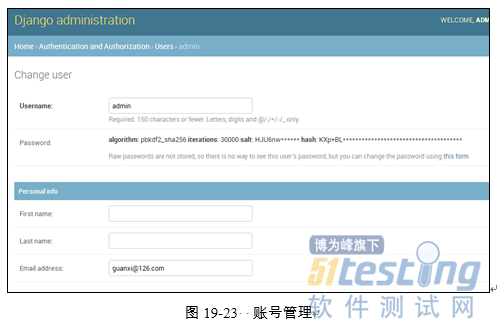
此时可以使用超级账号登录后台管理系统。登录成功后的界面如图19-22所示。
管理员可以修改、删除或添加账号信息,如图19-23所示。
也可以对系统内已经发布的博客信息进行管理和维护,如图19-24所示。

也可以直接修改用户账号信息的密码,如图19-25所示。

19.4、使用Flask框架
Flask是一个免费的Web框架,也是一个年轻充满活力的微框架,有着众多的拥护者,文档齐全,社区活跃度高。Flask的设计目标是实现一个WSGI的微框架,其核心代码保持简单性和可扩展性,很容易学习。本节将详细讲解使用Flask框架开发Python Web程序的知识。
19.4.1、开始使用Flask框架
因为Flask框架并不是Python语言的标准库,所以在使用之前必须先进行安装。可以使用pip命令实现快速安装,因为它会自动帮你安装其依赖的第三方库。在CMD控制台的命令提示符下使用如下命令进行安装。
| pip install flask |
成功安装时的界面如图19-26所示。
在安装Flask框架后,可以在交互式环境下使用import flask语句进行验证。如果没有错误提示,则说明成功安装Flask框架。另外,也可以通过手动下载的方式进行手动安装,必须先下载安装Flask依赖的两个外部库,即Werkzeug和Jinja2,分别解压后进入对应的目录,在命令提示符下使用python setup.py install来安装它们。Flask依赖外部库的下载地址可到网上搜索。
然后,在下面的下载地址下载Flask。下载后再使用python setup.py install命令来安装它。
http://pypi.python.org/packages/source/F/Flask/Flask-0.10.1.tar.gz
下面的实例代码演示了使用Flask框架开发一个简单Web程序的过程。
实例19-14 使用Flask框架开发一个简单Web程序
源码路径 daima\19\19-14
实例文件flask1.py的具体实现代码如下所示。
import flask #导入flask模块 app = flask.Flask(__name__) #实例化类Flask @app.route('/') #装饰器操作,实现URL地址 def helo(): #定义业务处理函数helo() return '你好,这是第一个Flask程序!' if __name__ == '__main__': app.run() #运行程序 |
在上述实例代码中首先导入了Flask框架,然后实例化主类并自定义只返回一串字符的函数helo()。接着使用@app.route('/')装饰器将URL和函数helo()联系起来,使得服务器在收到对应的URL请求时,调用这个函数,返回这个函数生产的数据。
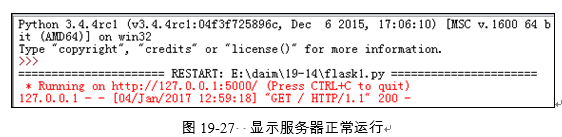
执行后会显示一行提醒语句,如图19-27所示。这表示Web服务器已经正常启动和运行了,它的默认服务器端口为5000,IP地址为127.0.0.1。
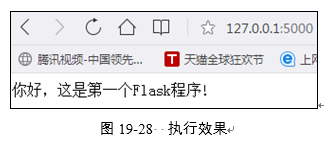
在浏览器中输入网址"http://127.0.0.1:5000/"后,便可以测试上述Web程序,执行效果如图19-28所示。通过按下键盘中的Ctrl+C组合键可以退出当前的服务器。
当服务器收到浏览器发出的访问请求后,服务器还会显示出相关信息,如图19-29所示。其中显示了访问该服务器的客户端地址、访问的时间、请求的方法以及表示访问结果的状态码。

在上述实例代码中,方法run()的功能是启动一个服务器,在调用时可以通过参数来设置服务器。常用的主要参数如下所示。
" host:服务的IP地址,默认为None。
" port:服务的端口,默认为None。
" debug:是否开启调试模式,默认为None。
19.4.2、传递URL参数
在Flask框架中,通过使用方法route()可以将一个普通函数与特定的URL关联起来。当服务器收到这个URL请求时,会调用方法route()返回对应的内容。Flask框架中的一个函数可以由多个URL装饰器来装饰,实现多个URL请求由一个函数产生的内容响应。下面的实例演示了将不同的URL映射到同一个函数的过程。
实例19-15 将不同的URL映射到同一个函数
源码路径 daima\19\19-15
实例文件flask2.py的具体实现代码如下所示。
import flask #导入flask模块 app = flask.Flask(__name__) #实例化类 @app.route('/') #装饰器操作,实现URL地址映射 @app.route('/aaa') #装饰器操作,实现第2个URL地址映射 def helo(): return '你好,这是一个Flask程序!' if __name__ == '__main__': app.run() #运行程序 |
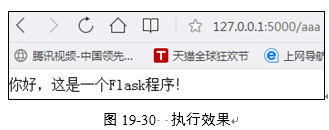
执行本实例后,无论是在浏览器中输入"http:// 127.0.0.1:5000/",还是输入"http://127. 0.0.1:5000/aaa",在服务器端都将这两个URL请求映射到同一个函数helo(),所以输入两个URL地址后的效果一样。执行效果如图19-30所示。
在现实应用中,实现HTTP请求传递最常用的两种方法是"GET"和"POST"。在Flask框架中,URL装饰器的默认方法为"GET",通过使用Flask中URL装饰器的参数"方法类型",可以让同一个URL的两种请求方法都映射在同一个函数。
在默认情况下,当通过浏览器传递参数相关数据或参数时,都是通过GET或POST请求中包含参数来实现的。其实通过URL也可以传递参数,此时直接将数据放入到URL中,然后在服务器端获取传递的数据。
在Flask框架中,获取的URL参数需要在URL装饰器和业务函数中分别进行定义或处理。有如下两种形式的URL变量规则(URL装饰器中的URL字符串写法)。
/hello/<name> #例如获取URL"/hello/wang"中的参数"wang"并赋予name变量
/hello/<int: id> #例如获取URL"/hello/5"中的参数"5",并自动转换为整数5给id变量
要想获取和处理URL中传递来的参数,需要在对应业务函数的参数列表中列出变量名。具体语法格式如下所示。
@app.route("/hello/<name>") def get_url_param (name): pass |
这样在列表中列出变量名后,就可以在业务函数get_url_param()中引用这个变量值,并可以进一步使用从URL中传递过来的参数。
下面的实例演示了使用get请求获取URL参数的过程。
实例19-16 使用get请求获取URL参数
源码路径 daima\19\19-16
实例文件flask3.py的具体实现代码如下所示。
import flask #导入flask模块 html_txt = """ #初始化变量html_txt,作为GET请求的页面 <!DOCTYPE html> <html> <body> <h2>如果收到了GET请求</h2> <form method='post'> #设置请求方法是"post" <input type='submit' value='按下我发送 POST请求' /> </form> </body> </html> """ app = flask.Flask(__name__) #实例化类Flask #URL映射,不管是'GET'方法还是'POST'方法,都 #映射到helo()函数 @app.route('/aaa',methods=['GET','POST']) def helo(): #定义业务处理函数helo() if flask.request.method == 'GET': #如果接收到的请求是GET return html_txt #返回html_txt的页面内容 else: #否则,接收到的请求是POST return '我司已经收到POST请求!' if __name__ == '__main__': app.run() #运行程序 |
本实例演示了使用参数"方法类型"的URL装饰器实例的过程。在上述实例代码中,预先定义了GET请求要返回的页面内容字符串html_txt,在函数helo()的装饰器中提供了参数methods为"GET"和"POST"字符串列表,表示对于URL为"/aaa"的请求,不管是'GET'方法还是'POST'方法,都映射到helo()函数。在函数helo()内部使用flask.request.method来判断收到的请求方法是"GET"还是"POST",然后分别返回不同的内容。
执行本实例,在浏览器中输入"http://127.0.0.1:5000/aaa"后的效果如图19-31所示。单击"按下我发送POST请求"按钮后的效果如图19-32所示。

19.4.3、使用session和cookie
通过本书前面内容的学习可知,通过使用cookie和session可以存储客户端和服务器端的交互状态。其中cookie能够运行在客户端并存储交互状态,而session能够在服务器端存储交互状态。在Flask框架中提供了上述两种常用交互状态的存储方式,其中session存储方式与其他Web框架有一些不同。Flask框架中的session使用了密钥签名的方式进行了加密。也就是说,虽然用户可以查看你的cookie,但是如果没有密钥就无法修改它,并且只保存在客户端。
在Flask框架中,可以通过如下代码获取cookie。
flask. request.cookies.get('name ')
在Flask框架中,可以使用make_response对象设置cookie,例如下面的代码。
resp = make_response (content) #content返回页面内容 resp.set_cookie ('username','the username') #设置名为username的cookie |
下面的实例演示了使用cookie跟踪用户的过程。
实例19-17 使用cookie跟踪用户
源码路径 daima\19\19-17
实例文件flask4.py的具体实现代码如下所示。
import flask #导入flask模块 html_txt = """ #初始化变量html_txt,作为GET请求的页面 <!DOCTYPE html> <html> <body> <h2>可以收到GET请求</h2> <a href='/get_xinxi'>单击我获取cookie信息</a> </body> </html> """ app = flask.Flask(__name__) #实例化类Flask @app.route('/set_xinxi/<name>') #URL映射到指定 #目录中的文件 def set_cks(name): #函数set_cks()用于从URL中获 #取参数并将其存入cookie中 name = name if name else 'anonymous' resp = flask.make_response(html_txt) #构造响应对象 resp.set_cookie('name',name) #设置cookie return resp @app.route('/get_xinxi') def get_cks(): #函数get_cks()用于从cookie中读取数据并显示在页面中 name = flask.request.cookies.get('name') #获取cookie信息 return '获取的cookie信息是:' + name #显示获取到的cookie信息 if __name__ == '__main__': app.run(debug=True) |
在上述实例代码中,首先定义了两个功能函数。其中,第一个功能函数用于从URL中获取参数并将其存入cookie中;第二个功能函数用于从cookie中读取数据并显示在页面中。
当在浏览器中使用"http://127.0.0.1:5000/set_xinxi/langchao"浏览时,表示设置了名为name(langchao)的cookie信息,执行效果如图19-33所示。当单击"单击我获取cookie信息"链接后来到"/get_xinxi"时,会在新页面中显示在cookie中保存的name名称"langchao"的信息,效果如图19-34所示。

19.4.4、文件上传
在Flask框架中实现文件上传系统的方法非常简单,与传递GET或POST参数十分相似。在Flask框架实现文件上传系统的基本流程如下所示。
(1)将在客户端上传的文件保存在flask.request.files对象中。
(2)使用flask.request.files对象获取上传的文件名和文件对象。
(3)调用文件对象中的方法save()将文件保存到指定的目录中。
下面的实例演示了在Flask框架中实现文件上传系统的过程。
实例19-18 在Flask框架中实现文件上传系统
源码路径 daima\19\19-18
实例文件flask5.py的具体实现代码如下所示。
import flask #导入flask模块 app = flask.Flask(__name__) #实例化类Flask #URL映射操作,设置处理GET请求和POST请求的方式 @app.route('/upload',methods=['GET','POST']) def upload(): #定义文件上传函数upload() if flask.request.method == 'GET': #如果是GET请求 return flask.render_template('upload.html') #返回上传页面 else: #如果是POST请求 file = flask.request.files['file'] #获取文件对象 if file: #如果文件不为空 file.save(file.filename) #保存上传的文件 return '上传成功!' #显示提示信息 if __name__ == '__main__': app.run(debug=True) |
在上述实例代码中,只定义了一个实现文件上传功能的函数upload(),它能够同时处理GET请求和POST请求。其中将GET请求返回上传页面,当获得POST请求时获取上传的文件,并保存到当前的目录下。
当在浏览器中使用"http://127.0.0.1:5000/upload"运行时,显示一个文件上传表单界面,效果如图19-35所示。单击"浏览"按钮可以选择一个要上传的文件,单击"上传"按钮后会上传这个文件,并显示上传成功提示。执行效果如图19-36所示。

19.5、技术解惑
19.5.1、"客户端/服务器"开发模式
因为Web应用程序开发是现实中最常见的软件开发类型,整个开发过程涵盖的知识非常广,所以在本节首先针对常见的Web开发模式进行简要介绍,为读者进入后续章节的学习打下坚实的基础。在本书前面的网络开发章节中,曾经讲解了客户端/服务器编程模型的基本知识,客户端/服务器编程模型其实就是客户端/服务器开发模式。Web应用遵循前面反复提到的客户端/服务器架构。这里说的Web客户端是浏览器,即允许用户在万维网上查询文档的应用程序。另一边是Web服务器端,指的是运行在信息提供商的主机上的进程。这些服务器等待客户端及其文档请求,进行相应的处理,并返回相关的数据。正如大多数客户端/服务器系统中的服务器端一样,Web服务器端"永远"运行。用户运行Web客户端程序(如浏览器),连接因特网上任意位置的Web服务器来获取数据。
客户端可以向Web服务器端发出各种不同的请求,这些请求可能包括一个用于查看网页的需求,或者提交一个包含待处理数据的表单。Web服务器端首先处理请求,然后以特定的格式(HTML等)返回给客户端浏览。
Web客户端和服务器端交互需要用到特定的"语言",即Web交互需要用到的标准协议,这称为HTTP(HyperText Transfer Protocol,超文本传输)。HTTP是TCP/IP的上层协议,这意味着HTTP协议依靠TCP/IP来进行低层的交流工作。它的职责不是发送或者传递消息(TCP/IP协议处理这些),而是通过发送、接收HTTP消息来处理客户端的请求。HTTP属于无状态协议,因为其不跟踪从一个客户端到另一个客户端的请求信息,这一点很像现在使用的客户端/服务器架构。服务器持续运行,但是客户端的活动以单个事件划分,一旦完成一个客户请求,这个服务事件就停止了。客户端可以随时发送新的请求,但是会把新的请求视为独立的服务请求。由于每个请求缺乏上下文,因此你可能注意到有些URL中含有很长的变量和值,这些将作为请求的一部分,以提供一些状态信息。另一种方式是使用"cookie",即保存在客户端的客户状态信息。
19.5.2、Python Web客户端开发是大势所趋
在现实应用中,浏览器只是众多Web客户端的一种,任何一个向Web服务器端发送请求来获得数据的应用程序都可以称为"客户端"。当然,也可以创建并使用其他的客户端以在互联网中检索和浏览数据。从市场需求方面来看,创建其他客户端的主要原因如下。
" 浏览器的能力有限,浏览器主要用于浏览网页内容并同其他Web站点交互。
" 客户端程序可以完成更多的工作,不仅可以下载数据,还可以存储、操作数据,甚至可以将其传送到另外一个地方或者传给另外一个应用。
在Python程序中,可以使用urllib模块下载或者访问Web中的信息(例如使用urllib.urlopen()或者urllib.urlretrieve())。整个实现过程非常简单,开发者所要做的只是为程序提供一个有效的Web地址而已。
19.5.3、注意Python 3的变化
从Python 3开始,已经将urllib2、urlparse和robotparser并入到了urllib模块中,并且修改了urllib模块,其中包含如下5个子模块。
" urllib.error。
" urllib.parse。
" urllib.request。
" urllib.response。
" urllib.robotparser。
19.6、课后练习
(1)编写一个程序,使用Tornado实现文件上传。
(2)编写一个程序,在Django框架中使用Ajax技术。
相关阅读:
版权声明:51Testing软件测试网获人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。












