

ЁЁЁЁЕМгяЃКSpark вбОГЩЮЊЙуИцЁЂБЈБэвдМАЭЦМіЯЕЭГЕШДѓЪ§ОнМЦЫуГЁОАжаЪзбЁЯЕЭГЃЌвђаЇТЪИпЃЌвзгУвдМАЭЈгУаддНРДдНЕУЕНДѓМвЕФЧрэљЃЌЮвздМКзюНќАыФъдкНгДЅsparkвдМАspark streamingжЎКѓЃЌЖдsparkММЪѕЕФЪЙгУгавЛаЉздМКЕФОбщЛ§РлвдМАаФЕУЬхЛсЃЌдкДЫЗжЯэИјДѓМвЁЃБОЮФвРДЮДгsparkЩњЬЌЃЌдРэЃЌЛљБОИХФюЃЌspark streamingдРэМАЪЕМљЃЌЛЙгаsparkЕїгХвдМАЛЗОГДюНЈЕШЗНУцНјааНщЩмЃЌЯЃЭћЖдДѓМвгаЫљАяжњЁЃ
ЁЁЁЁspark ЩњЬЌМАдЫаадРэ

ЁЁЁЁSpark ЬиЕу
ЁЁЁЁдЫааЫйЖШПь => SparkгЕгаDAGжДаав§ЧцЃЌжЇГждкФкДцжаЖдЪ§ОнНјааЕќДњМЦЫуЁЃЙйЗНЬсЙЉЕФЪ§ОнБэУїЃЌШчЙћЪ§ОнгЩДХХЬЖСШЁЃЌЫйЖШЪЧHadoop MapReduceЕФ10БЖвдЩЯЃЌШчЙћЪ§ОнДгФкДцжаЖСШЁЃЌЫйЖШПЩвдИпДя100ЖрБЖЁЃ
ЁЁЁЁЪЪгУГЁОАЙуЗК => ДѓЪ§ОнЗжЮіЭГМЦЃЌЪЕЪБЪ§ОнДІРэЃЌЭММЦЫуМАЛњЦїбЇЯА
ЁЁЁЁвзгУад => БраДМђЕЅЃЌжЇГж80жжвдЩЯЕФИпМЖЫузгЃЌжЇГжЖржжгябдЃЌЪ§ОндДЗсИЛЃЌПЩВПЪ№дкЖржжМЏШКжа
ЁЁЁЁШнДэадИпЁЃSparkв§НјСЫЕЏадЗжВМЪНЪ§ОнМЏRDD (Resilient Distributed Dataset) ЕФГщЯѓЃЌЫќЪЧЗжВМдквЛзщНкЕужаЕФжЛЖСЖдЯѓМЏКЯЃЌетаЉМЏКЯЪЧЕЏадЕФЃЌШчЙћЪ§ОнМЏвЛВПЗжЖЊЪЇЃЌдђПЩвдИљОнЁАбЊЭГЁБ(МДГфаэЛљгкЪ§ОнбмЩњЙ§ГЬ)ЖдЫќУЧНјаажиНЈЁЃСэЭтдкRDDМЦЫуЪБПЩвдЭЈЙ§CheckPointРДЪЕЯжШнДэЃЌЖјCheckPointгаСНжжЗНЪНЃКCheckPoint DataЃЌКЭLogging The UpdatesЃЌгУЛЇПЩвдПижЦВЩгУФФжжЗНЪНРДЪЕЯжШнДэЁЃ
ЁЁЁЁSparkЕФЪЪгУГЁОА
ЁЁЁЁФПЧАДѓЪ§ОнДІРэГЁОАгавдЯТМИИіРраЭЃК
ЁЁЁЁИДдгЕФХњСПДІРэ(Batch Data Processing)ЃЌЦЋжиЕудкгкДІРэКЃСПЪ§ОнЕФФмСІЃЌжСгкДІРэЫйЖШПЩШЬЪмЃЌЭЈГЃЕФЪБМфПЩФмЪЧдкЪ§ЪЎЗжжгЕНЪ§аЁЪБ;
ЁЁЁЁЛљгкРњЪЗЪ§ОнЕФНЛЛЅЪНВщбЏ(Interactive Query)ЃЌЭЈГЃЕФЪБМфдкЪ§ЪЎУыЕНЪ§ЪЎЗжжгжЎМф
ЁЁЁЁЛљгкЪЕЪБЪ§ОнСїЕФЪ§ОнДІРэ(Streaming Data Processing)ЃЌЭЈГЃдкЪ§АйКСУыЕНЪ§УыжЎМф
ЁЁЁЁSparkГЩЙІАИР§ ФПЧАДѓЪ§ОндкЛЅСЊЭјЙЋЫОжївЊгІгУдкЙуИцЁЂБЈБэЁЂЭЦМіЯЕЭГЕШвЕЮёЩЯЁЃдкЙуИцвЕЮёЗНУцашвЊДѓЪ§ОнзігІгУЗжЮіЁЂаЇЙћЗжЮіЁЂЖЈЯђгХЛЏЕШЃЌдкЭЦМіЯЕЭГЗНУцдђашвЊДѓЪ§ОнгХЛЏЯрЙиХХУћЁЂИіадЛЏЭЦМівдМАШШЕуЕуЛїЗжЮіЕШЁЃетаЉгІгУГЁОАЕФЦеБщЬиЕуЪЧМЦЫуСПДѓЁЂаЇТЪвЊЧѓИпЁЃЬкбЖ / yahoo / ЬдБІ / гХПсЭСЖЙ
ЁЁЁЁsparkдЫааМмЙЙ
ЁЁЁЁsparkЛљДЁдЫааМмЙЙШчЯТЫљЪОЃК
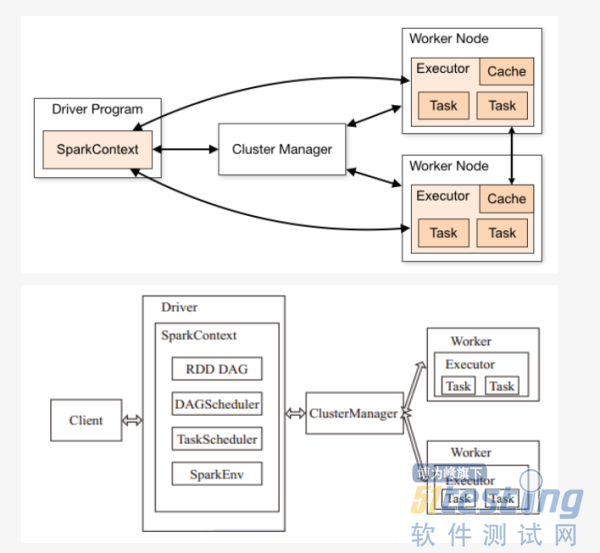
ЁЁЁЁsparkНсКЯyarnМЏШКБГКѓЕФдЫааСїГЬШчЯТЫљЪОЃК

ЁЁЁЁspark дЫааСїГЬЃК
ЁЁЁЁSparkМмЙЙВЩгУСЫЗжВМЪНМЦЫужаЕФMaster-SlaveФЃаЭЁЃMasterЪЧЖдгІМЏШКжаЕФКЌгаMasterНјГЬЕФНкЕуЃЌSlaveЪЧМЏШКжаКЌгаWorkerНјГЬЕФНкЕуЁЃMasterзїЮЊећИіМЏШКЕФПижЦЦїЃЌИКд№ећИіМЏШКЕФе§ГЃдЫаа;WorkerЯрЕБгкМЦЫуНкЕуЃЌНгЪежїНкЕуУќСюгыНјаазДЬЌЛуБЈ;ExecutorИКд№ШЮЮёЕФжДаа;ClientзїЮЊгУЛЇЕФПЭЛЇЖЫИКд№ЬсНЛгІгУЃЌDriverИКд№ПижЦвЛИігІгУЕФжДааЁЃ
ЁЁЁЁSparkМЏШКВПЪ№КѓЃЌашвЊдкжїНкЕуКЭДгНкЕуЗжБ№ЦєЖЏMasterНјГЬКЭWorkerНјГЬЃЌЖдећИіМЏШКНјааПижЦЁЃдквЛИіSparkгІгУЕФжДааЙ§ГЬжаЃЌDriverКЭWorkerЪЧСНИіживЊНЧЩЋЁЃDriver ГЬађЪЧгІгУТпМжДааЕФЦ№ЕуЃЌИКд№зївЕЕФЕїЖШЃЌМДTaskШЮЮёЕФЗжЗЂЃЌЖјЖрИіWorkerгУРДЙмРэМЦЫуНкЕуКЭДДНЈExecutorВЂааДІРэШЮЮёЁЃдкжДааНзЖЮЃЌDriverЛсНЋTaskКЭTaskЫљвРРЕЕФfileКЭjarађСаЛЏКѓДЋЕнИјЖдгІЕФWorkerЛњЦїЃЌЭЌЪБExecutorЖдЯргІЪ§ОнЗжЧјЕФШЮЮёНјааДІРэЁЃ
ЁЁЁЁExcecutor /Task УПИіГЬађздгаЃЌВЛЭЌГЬађЛЅЯрИєРыЃЌtaskЖрЯпГЬВЂааЃЌ
ЁЁЁЁМЏШКЖдSparkЭИУїЃЌSparkжЛвЊФмЛёШЁЯрЙиНкЕуКЭНјГЬ
ЁЁЁЁDriver гыExecutorБЃГжЭЈаХЃЌазїДІРэ
ЁЁЁЁШ§жжМЏШКФЃЪНЃК
ЁЁЁЁ1.Standalone ЖРСЂМЏШК
ЁЁЁЁ2.Mesos, apache mesos
ЁЁЁЁ3.Yarn, hadoop yarn
ЁЁЁЁЛљБОИХФюЃК
ЁЁЁЁApplication =>SparkЕФгІгУГЬађЃЌАќКЌвЛИіDriver programКЭШєИЩExecutor
ЁЁЁЁSparkContext => SparkгІгУГЬађЕФШыПкЃЌИКд№ЕїЖШИїИідЫЫузЪдДЃЌаЕїИїИіWorker NodeЩЯЕФExecutor
ЁЁЁЁDriver Program => дЫааApplicationЕФmain()КЏЪ§ВЂЧвДДНЈSparkContext
ЁЁЁЁExecutor => ЪЧЮЊApplicationдЫаадкWorker nodeЩЯЕФвЛИіНјГЬЃЌИУНјГЬИКд№дЫааTaskЃЌВЂЧвИКд№НЋЪ§ОнДцдкФкДцЛђепДХХЬЩЯЁЃУПИіApplicationЖМЛсЩъЧыИїздЕФExecutorРДДІРэШЮЮё
ЁЁЁЁCluster Manager =>дкМЏШКЩЯЛёШЁзЪдДЕФЭтВПЗўЮё (Р§ШчЃКStandaloneЁЂMesosЁЂYarn)
ЁЁЁЁWorker Node => МЏШКжаШЮКЮПЩвддЫааApplicationДњТыЕФНкЕуЃЌдЫаавЛИіЛђЖрИіExecutorНјГЬ
ЁЁЁЁTask => дЫаадкExecutorЩЯЕФЙЄзїЕЅдЊ
ЁЁЁЁJob => SparkContextЬсНЛЕФОпЬхActionВйзїЃЌГЃКЭActionЖдгІ
ЁЁЁЁStage => УПИіJobЛсБЛВ№ЗжКмЖрзщtaskЃЌУПзщШЮЮёБЛГЦЮЊStageЃЌвВГЦTaskSet
ЁЁЁЁRDD => ЪЧResilient distributed datasetsЕФМђГЦЃЌжаЮФЮЊЕЏадЗжВМЪНЪ§ОнМЏ;ЪЧSparkзюКЫаФЕФФЃПщКЭРр
ЁЁЁЁDAGScheduler => ИљОнJobЙЙНЈЛљгкStageЕФDAGЃЌВЂЬсНЛStageИјTaskScheduler
ЁЁЁЁTaskScheduler => НЋTasksetЬсНЛИјWorker nodeМЏШКдЫааВЂЗЕЛиНсЙћ
ЁЁЁЁTransformations => ЪЧSpark APIЕФвЛжжРраЭЃЌTransformationЗЕЛижЕЛЙЪЧвЛИіRDDЃЌЫљгаЕФTransformationВЩгУЕФЖМЪЧРСВпТдЃЌШчЙћжЛЪЧНЋTransformationЬсНЛЪЧВЛЛсжДааМЦЫуЕФ
ЁЁЁЁAction => ЪЧSpark APIЕФвЛжжРраЭЃЌActionЗЕЛижЕВЛЪЧвЛИіRDDЃЌЖјЪЧвЛИіscalaМЏКЯ;МЦЫужЛгадкActionБЛЬсНЛЕФЪБКђМЦЫуВХБЛДЅЗЂЁЃ
ЁЁЁЁSparkКЫаФИХФюжЎRDD

ЁЁЁЁSparkКЫаФИХФюжЎTransformations / Actions
ЁЁЁЁTransformationЗЕЛижЕЛЙЪЧвЛИіRDDЁЃЫќЪЙгУСЫСДЪНЕїгУЕФЩшМЦФЃЪНЃЌЖдвЛИіRDDНјааМЦЫуКѓЃЌБфЛЛГЩСэЭтвЛИіRDDЃЌШЛКѓетИіRDDгжПЩвдНјааСэЭтвЛДЮзЊЛЛЁЃетИіЙ§ГЬЪЧЗжВМЪНЕФЁЃ ActionЗЕЛижЕВЛЪЧвЛИіRDDЁЃЫќвЊУДЪЧвЛИіScalaЕФЦеЭЈМЏКЯЃЌвЊУДЪЧвЛИіжЕЃЌвЊУДЪЧПеЃЌзюжеЛђЗЕЛиЕНDriverГЬађЃЌЛђАбRDDаДШыЕНЮФМўЯЕЭГжаЁЃ
ЁЁЁЁActionЪЧЗЕЛижЕЗЕЛиИјdriverЛђепДцДЂЕНЮФМўЃЌЪЧRDDЕНresultЕФБфЛЛЃЌTransformationЪЧRDDЕНRDDЕФБфЛЛЁЃ
ЁЁЁЁжЛгаactionжДааЪБЃЌrddВХЛсБЛМЦЫуЩњГЩЃЌетЪЧrddРСЖшжДааЕФИљБОЫљдкЁЃ
ЁЁЁЁSparkКЫаФИХФюжЎJobs / Stage
ЁЁЁЁJob => АќКЌЖрИіtaskЕФВЂааМЦЫуЃЌвЛИіactionДЅЗЂвЛИіjob
ЁЁЁЁstage => вЛИіjobЛсБЛВ№ЮЊЖрзщtaskЃЌУПзщШЮЮёГЦЮЊвЛИіstageЃЌвдshuffleНјааЛЎЗж
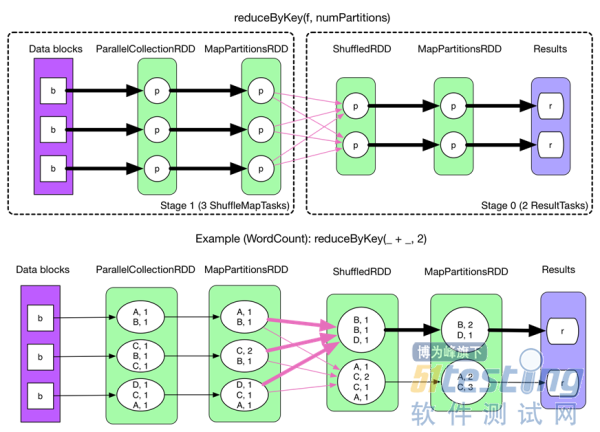
ЁЁЁЁSparkКЫаФИХФюжЎShuffle
ЁЁЁЁвдreduceByKeyЮЊР§НтЪЭshuffleЙ§ГЬЁЃ
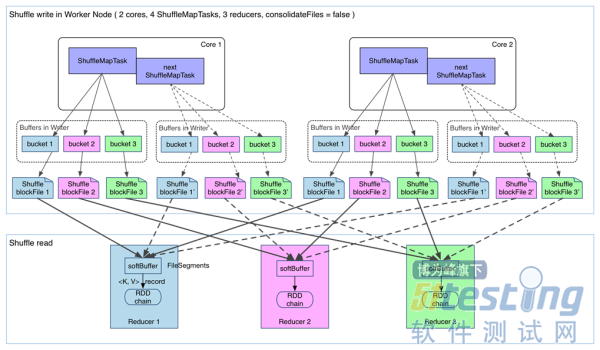
ЁЁЁЁдкУЛгаtaskЕФЮФМўЗжЦЌКЯВЂЯТЕФshuffleЙ§ГЬШчЯТЃК(spark.shuffle.consolidateFiles=false)

ЁЁЁЁfetch РДЕФЪ§ОнДцЗХЕНФФРя?
ЁЁЁЁИе fetch РДЕФ FileSegment ДцЗХдк softBuffer ЛКГхЧјЃЌОЙ§ДІРэКѓЕФЪ§ОнЗХдкФкДц + ДХХЬЩЯЁЃетРяЮвУЧжївЊЬжТлДІРэКѓЕФЪ§ОнЃЌПЩвдСщЛюЩшжУетаЉЪ§ОнЪЧЁАжЛгУФкДцЁБЛЙЪЧЁАФкДц+ДХХЬЁБЁЃШчЙћspark.shuffle.spill = falseОЭжЛгУФкДцЁЃгЩгкВЛвЊЧѓЪ§ОнгаађЃЌshuffle write ЕФШЮЮёКмМђЕЅЃКНЋЪ§Он partition КУЃЌВЂГжОУЛЏЁЃжЎЫљвдвЊГжОУЛЏЃЌвЛЗНУцЪЧвЊМѕЩйФкДцДцДЂПеМфбЙСІЃЌСэвЛЗНУцвВЪЧЮЊСЫ fault-toleranceЁЃ
ЁЁЁЁshuffleжЎЫљвдашвЊАбжаМфНсЙћЗХЕНДХХЬЮФМўжаЃЌЪЧвђЮЊЫфШЛЩЯвЛХњtaskНсЪјСЫЃЌЯТвЛХњtaskЛЙашвЊЪЙгУФкДцЁЃШчЙћШЋВПЗХдкФкДцжаЃЌФкДцЛсВЛЙЛЁЃСэЭтвЛЗНУцЮЊСЫШнДэЃЌЗРжЙШЮЮёЙвЕєЁЃ
ЁЁЁЁДцдкЮЪЬтШчЯТЃК
ЁЁЁЁВњЩњЕФ FileSegment Й§ЖрЁЃУПИі ShuffleMapTask ВњЩњ R(reducer ИіЪ§)Иі FileSegmentЃЌM Иі ShuffleMapTask ОЭЛсВњЩњ M * R ИіЮФМўЁЃвЛАу Spark job ЕФ M КЭ R ЖМКмДѓЃЌвђДЫДХХЬЩЯЛсДцдкДѓСПЕФЪ§ОнЮФМўЁЃ
ЁЁЁЁЛКГхЧјеМгУФкДцПеМфДѓЁЃУПИі ShuffleMapTask ашвЊПЊ R Иі bucketЃЌM Иі ShuffleMapTask ОЭЛсВњЩњ MR Иі bucketЁЃЫфШЛвЛИі ShuffleMapTask НсЪјКѓЃЌЖдгІЕФЛКГхЧјПЩвдБЛЛиЪеЃЌЕЋвЛИі worker node ЩЯЭЌЪБДцдкЕФ bucket ИіЪ§ПЩвдДяЕН cores R Иі(вЛАу worker ЭЌЪБПЩвддЫаа cores Иі ShuffleMapTask)ЃЌеМгУЕФФкДцПеМфвВОЭДяЕНСЫcores R 32 KBЁЃЖдгк 8 КЫ 1000 Иі reducer РДЫЕЃЌеМгУФкДцОЭЪЧ 256MBЁЃ
ЁЁЁЁЮЊСЫНтОіЩЯЪіЮЪЬтЃЌЮвУЧПЩвдЪЙгУЮФМўКЯВЂЕФЙІФмЁЃ
ЁЁЁЁдкНјааtaskЕФЮФМўЗжЦЌКЯВЂЯТЕФshuffleЙ§ГЬШчЯТЃК(spark.shuffle.consolidateFiles=true)
ЁЁЁЁПЩвдУїЯдПДГіЃЌдквЛИі core ЩЯСЌајжДааЕФ ShuffleMapTasks ПЩвдЙВгУвЛИіЪфГіЮФМў ShuffleFileЁЃЯШжДааЭъЕФ ShuffleMapTask аЮГЩ ShuffleBlock iЃЌКѓжДааЕФ ShuffleMapTask ПЩвдНЋЪфГіЪ§ОнжБНгзЗМгЕН ShuffleBlock i КѓУцЃЌаЮГЩ ShuffleBlock i'ЃЌУПИі ShuffleBlock БЛГЦЮЊ FileSegmentЁЃЯТвЛИі stage ЕФ reducer жЛашвЊ fetch ећИі ShuffleFile ОЭааСЫЁЃетбљЃЌУПИі worker ГжгаЕФЮФМўЪ§НЕЮЊ cores * RЁЃFileConsolidation ЙІФмПЩвдЭЈЙ§spark.shuffle.consolidateFiles=trueРДПЊЦєЁЃ
ЁЁЁЁSparkКЫаФИХФюжЎCache
ЁЁЁЁval rdd1 = ... // ЖСШЁhdfsЪ§ОнЃЌМгдиГЩRDD ЁЁЁЁrdd1.cache ЁЁЁЁval rdd2 = rdd1.map(...) ЁЁЁЁval rdd3 = rdd1.filter(...) ЁЁЁЁrdd2.take(10).foreach(println) ЁЁЁЁrdd3.take(10).foreach(println) ЁЁЁЁrdd1.unpersist |
ЁЁЁЁcacheКЭunpersisitСНИіВйзїБШНЯЬиЪтЃЌЫћУЧМШВЛЪЧactionвВВЛЪЧtransformationЁЃcacheЛсНЋБъМЧашвЊЛКДцЕФrddЃЌеце§ЛКДцЪЧдкЕквЛДЮБЛЯрЙиactionЕїгУКѓВХЛКДц;unpersisitЪЧФЈЕєИУБъМЧЃЌВЂЧвСЂПЬЪЭЗХФкДцЁЃжЛгаactionжДааЪБЃЌrdd1ВХЛсПЊЪМДДНЈВЂНјааКѓајЕФrddБфЛЛМЦЫуЁЃ
ЁЁЁЁcacheЦфЪЕвВЪЧЕїгУЕФpersistГжОУЛЏКЏЪ§ЃЌжЛЪЧбЁдёЕФГжОУЛЏМЖБ№ЮЊMEMORY_ONLYЁЃ
ЩЯЮФФкШнВЛгУгкЩЬвЕФПЕФЃЌШчЩцМАжЊЪЖВњШЈЮЪЬтЃЌЧыШЈРћШЫСЊЯЕВЉЮЊЗхаЁБр(021-64471599-8017)ЃЌЮвУЧНЋСЂМДДІРэЁЃ












