

一 简介
apache Griffin是一个开源的大数据数据质量解决方案,它支持批处理和流模式两种数据质量检测方式,可以从不同维度(比如离线任务执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)度量数据资产,从而提升数据的准确度、可信度。
官方网站的介绍:Big Data Quality Solution For Batch and Streaming 官方介绍:http://griffin.apache.org/#about_page
二 架构
Apache Griffin具备的能力
引入官方文档

意思就是Apache Griffn具备提供明确的数据质量的定义域,这个通常覆盖了大多数数据质量的问题,同时能够支持用户自定义数据质量的标准,通过扩展DSL(Apache Griffn定义),用户能够自定义扩展自己的数据定义功能
Apache Griffin处理数据的方式
官方文档
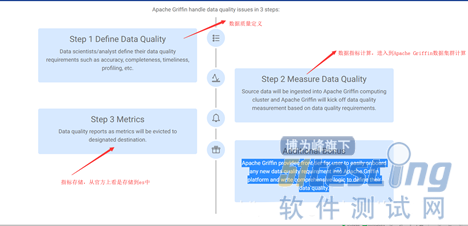
1,对于数据质量的定义,用户可以通过Apache Griffin UI功能,对于他们关注的数据进行质量定义,例如准确性,完整性,及时性等。
2,数据指标计算,Apache Griffin基于数据质量的维度定义,从流模式(kafka模型),批处理(定时功能)的方式抽取元数据进行计算。
3,数据质量结果落盘,数据质量报告作为度量将被逐出指定的目标。
4,apache Griffin提供了易于在ApacheGriffin平台上提供任何新的数据质量要求并编写综合逻辑以定义其数据质量的插件扩展。
Apache Griffin架构图
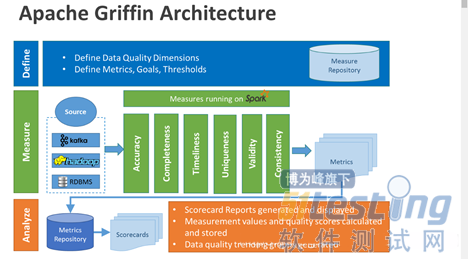
各个部分的主要职能:
· Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等
· Measure:主要负责执行统计任务,生成统计结果
· Analyze:主要负责保存与展示统计结果
Apache Griffin的元数据来源:kafka,hadoop,RDBMS(关系型数据库),
Apache Griffin的运行指标模型:基于Spark
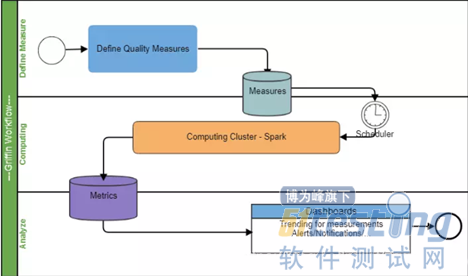
Apache Griffin的工作流
1,注册数据,把想要检测数据质量的数据源注册到griffin。
2,配置度量模型,可以从数据质量维度来定义模型,如:精确度、完整性、及时性、唯一性等。
3,配置定时任务提交spark集群,定时检查数据。
4,在门户界面上查看指标,分析数据质量校验结果。
三 环境部署
1,部署jdk版本
步骤略(jdk版本要求1.8以上)
2,部署mysql版本
步骤略
3,部署hadoop版本
(1)下载hadoop版本 :https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/ 2.7.7版本
(2)上传到/opt/hadoop,没有hadoop目录可以自己创建 mkdir /opt/hadoop(也可以自行创建其他目录)
tar hadoop-2.7.7.tar.gz
vi /etc/profile
追加Hadoop目录
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
追加hadoop的jdk环境变量‘
cd $HADOOP_HOME/etc/hadoop
vi hadoop-env.sh
在文件中追加JDK环境变量
export JAVA_HOME=/usr/local/jdk(实际自己的jdk部署目录)
编辑core-site.xml文件
cd $HADOOP_HOME/etc/hadoop/conf
vi core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
编辑hdfs-site.xml文件
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置mapred-site.xml,刚开始安装的时候文件名是mapred-site.xml.template,重命名为mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4,部署hive版本
参考 :https://www.cnblogs.com/caoxb/p/11333741.html
5,部署Spark版本
参考: https://blog.csdn.net/k393393/article/details/92440892
6,部署Livy版本
参考:添加链接描述
7,部署Elasticsearch5版本
参考:https://blog.csdn.net/fiery_heart/article/details/85265585
8,部署Zookeeper
基于kafka的时候需要。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












