

第10章 模型算法评估测试
在前面几章,我们已经介绍了机器学习项目的生命周期,并讲述了大数据和特征的测试手段及方法。在机器学习项目中,数据和特征准备妥当以后,接下来便是使用机器学习算法来拟合历史数据、生成预测模型,最后通过工程技术手段部署并投入使用。机器学习模型算法的好坏会直接影响最终模型服务的质量,因此针对机器学习模型算法的评估测试在机器学习项目中是不可或缺的,本章将对机器学习模型算法的评估测试进行详细介绍。
10.1 模型算法评测基础
10.1.1 模型算法评测概述
机器学习模型算法的本质是找一个能够尽量模拟真实状况的函数,并使用训练好的函数进行预测。为了保障机器学习项目的质量,我们需要对机器学习模型算法进行评估测试,评价模型算法的好坏,发现模型算法存在的缺陷。在进行模型算法评估的时候,我们既要考虑算法的学术正确性,还要考虑其在业务应用中的表现。
在大多数的机器学习应用中,很多公司都会采用离线与在线两套数据、环境来进行离线开发训练和在线提供服务,如图10-1中所示的是机器学习项目的工作流概况,图中只给出了一些比较重要的模块及服务。我们会在离线环境使用离线数据训练、调优、选择模型算法,在离线的评测通过后才会部署到在线。模型部署到在线以后,我们需要验证服务部署的正确性,同时还需要使用在线真实流量对多个不同模型实施A/B test,以此来比较这些模型表现的优劣。
这样,我们便需要关注模型离线与模型在线两部分:利用学术性方法进行离线评测(offline evaluation in academic world)和在业务环境中进行在线评测(online evaluation in business world)。因此很多时候我们都会首先在离线对模型算法进行学术性的评估,采用合适的评估指标来评价比较模型算法的优劣,使用测试方法(诸如蜕变测试、鲁棒性测试等)发现模型算法中可能存在的缺陷。由于离线的数据是在更新变化的,因此在评测的时候还会关注离线的不同时间点的前后一致性问题。正常的话,预测结果和指标效果在不同时间点的前后应该是一致的。模型算法在离线确认无误以后就会部署到在线,因此我们还需要关注模型算法的在线离线一致性。在进行离线评估时,我们通过使用训练样本和测试样本来训练与评估机器学习模型算法,以求模型算法的偏差与方差都尽可能小。在进行在线评估时,除了验证在线部署的正确性,更多的是要从业务的角度来评估模型服务。此外,还要关注在线模型算法服务的指标监控,保障在线服务的稳定。

图10-1 机器学习模型算法的离线评测与在线评测
10.1.2 样本数据划分策略
我们在对模型进行评估时,需要使用样本数据来计算出描述模型预测效果的评估指标。样本数据的不同选取方法和划分策略,最终会导致模型算法评估指标结果的不同。此时我们需要选择合适的划分策略来正确合理地反映模型的效果。此小节我们将介绍一些常用的样本数据划分策略[12]。
1.重新替代验证
首先将所有样本数据都用于训练模型,然后再使用这些样本数据通过模型进行预测,通过预测结果与实际值的比较来评估错误率,该错误称为重新替换错误,这种验证方法称为重新替代验证(Resubstitution)。
显然,用于评估的样本与训练模型的样本是同一份样本数据,这种评估出来的结果有一定的片面性,并不能说明模型算法的泛化能力,评估结论很难让我们信服。
2.留出法验证
为了避免重新替代验证可能存在的缺陷,我们可以使用留出法验证(Hold-out)将数据分为两个不同的数据集,分别标记为训练数据集和测试数据集,训练集与测试集划分的比例可以是6:4、7:3或8:2等。在这种分配方式下,在训练集和测试集中有可能会出现不同类别样本的分布不一致。为了解决这个问题,在划分训练集和测试集时,可以将不同类别的数据平均分配,使训练集和测试集的数据分布与原数据样本集相近,此过程称为分层抽样。
3.K折交叉验证
在K折交叉验证(K-Fold Cross-Validation)中,假设全部数据集可分为K折,选用K-1折用于训练,剩下的1折用于测试,如此迭代K次,然后计算评价指标的平均值。因此,这种划分方法也可以称为重复保留方法,如图10-2所示对K折交叉验证的表述:

图10-2 K折交叉验证(4折)
其优点是整个验证过程中全体数据集都曾用于训练和测试,获得的模型算法的评价指标是每次迭代错误率的平均值,更接近于真实的指标数值。
4.留一法交叉验证
在留一法交叉验证(Leave-One-Out Cross-Validation,LOOCV)中,除1条记录外,所有数据均用于训练,然后使用1条记录用于测试。如果有N条记录,则此过程重复N次。优点是全体数据集都曾用于训练和测试,同样模型算法的评价指标是每次迭代结果的平均值;缺点是整体验证过程重复次数较高,时间、资源消耗较大。如图10-3所表述的是留一法交叉验证。

图10-3 留一法交叉验证
5.随机二次抽样验证
在随机二次抽样(Random Subsampling)中,从数据集中随机选择多组数据,并将其组合成测试数据集,其余数据构成训练数据集,其中模型算法的错误率是每次迭代的错误率的平均值,如图10-4随机二次抽样验证技术所示的表述。
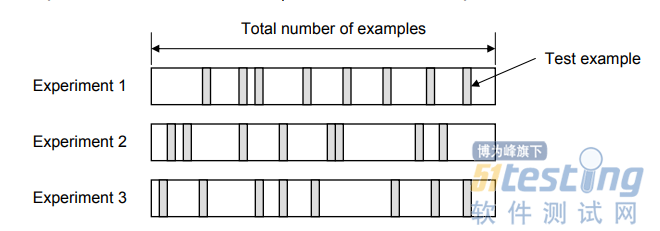
图10-4 随机二次抽样验证
6.自助采样验证
在这种自助采样验证(Bootstrapping)中,训练数据集是通过替换随机选择的,未被选择进入训练集的数据用于测试。与K折交叉验证不同,评估指标计算的结果可能会随折数的不同而变化。模型算法的指标是每次迭代指标的平均值,图10-5表述了自助采样的实现过程。

图10-5 自助采样验证
版权声明:51Testing软件测试网获得人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。












