

Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
当我们在浏览器中输入一个url后回车,后台会发生什么?
简单来说这段过程发生了以下四个步骤:

Python大佬精心梳理的爬虫系统入门知识点,希望对大家有用!
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。
抓取
这一步,你要明确要得到的内容是什么?是HTML源码,还是Json格式的字符串等。
1. 最基本的抓取
抓取大多数情况属于get请求,Python中自带urllib及urllib2这两个模块,基本上能满足一般的页面抓取。另外,requests也是非常有用的包,与此类似的,还有httplib2等等。

此外,对于带有查询字段的url,get请求一般会将来请求的数据附在url之后,以?分割url和传输数据,多个参数用&连接。
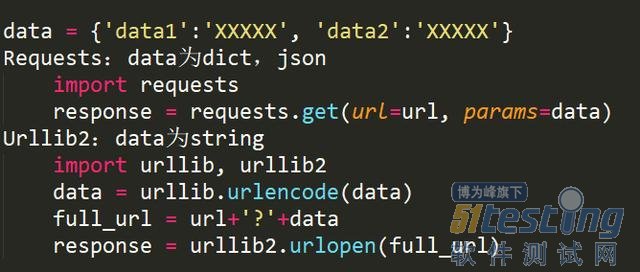
对于登陆情况的处理
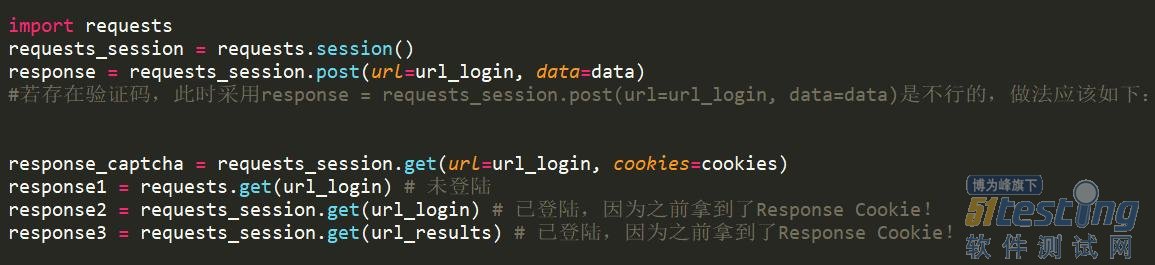
使用表单登陆
这种情况属于post请求,即先向服务器发送表单数据,服务器再将返回的cookie存入本地。

使用cookie登陆
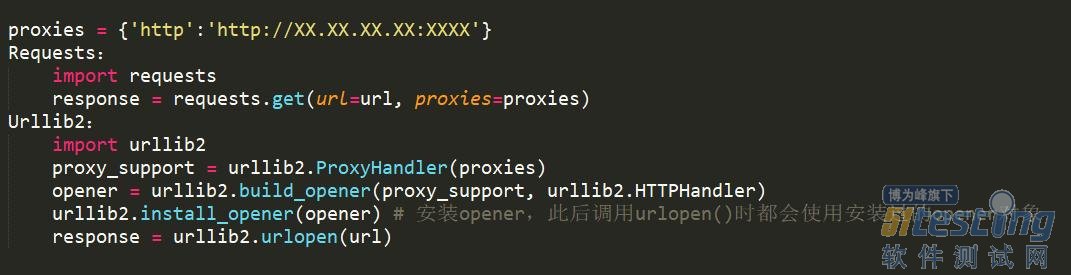
对于反爬虫机制的处理
使用代理
适用情况:限制IP地址情况,也可解决由于“频繁点击”而需要输入验证码登陆的情况。
时间设置
适用情况:限制频率情况。
Requests,Urllib2都可以使用time库的sleep()函数:
import time
time.sleep(1)
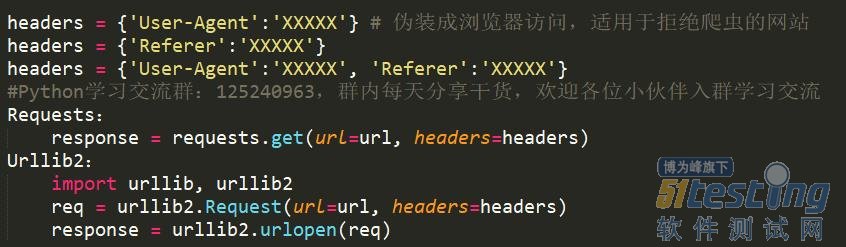
伪装成浏览器,或者反“反盗链”
对于断线重连
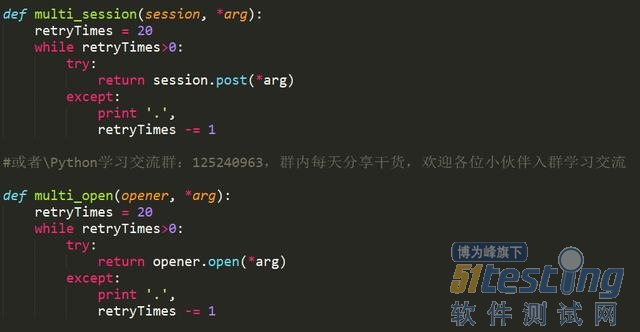
对于Ajax请求的处理
对于“加载更多”情况,使用Ajax来传输很多数据。
它的工作原理是:从网页的url加载网页的源代码之后,会在浏览器里执行JavaScript程序。

验证码识别
对于网站有验证码的情况,我们有三种办法:
使用代理,更新IP。
使用cookie登陆。
验证码识别。
爬取有两个需要注意的问题:
如何监控一系列网站的更新情况,也就是说,如何进行增量式爬取?
对于海量数据,如何实现分布式爬取?
分析
抓取之后就是对抓取的内容进行分析,你需要什么内容,就从中提炼出相关的内容来。
常见的分析工具有正则表达式,BeautifulSoup,lxml等等。
存储
分析出我们需要的内容之后,接下来就是存储了。
我们可以选择存入文本文件,也可以选择存入MySQL或MongoDB数据库等。
存储有两个需要注意的问题:
如何进行网页去重?
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。
内容以什么形式存储?












