

4.8 正则表达式处理
正则表达式的主要作用是进行文本的检索、替换或者是从一个字符串中提取出符合我们指定条件的子串,它描述了一种字符串匹配的模式。目前正则表达式已经被集成到了各种文本编辑器和文本处理工具中。
4.8.1 常用字符功能
正则表达式中几种常见的字符类型,包括特殊字符类、数量限定符、位置符、特殊含义字符等,如表4-21、表4-22、表4-23和表4-24所示。
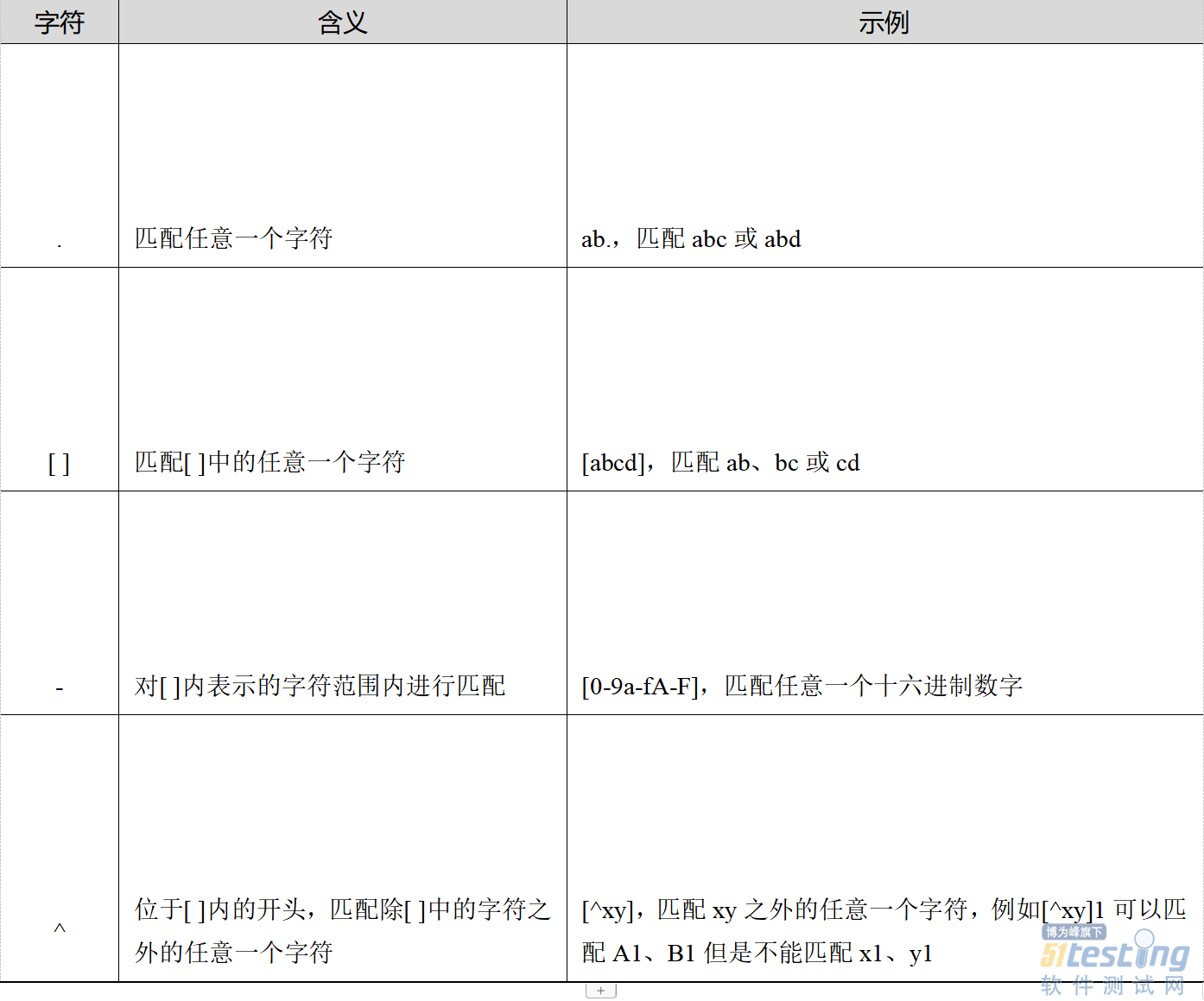
表4-21 特殊字符类及其含义
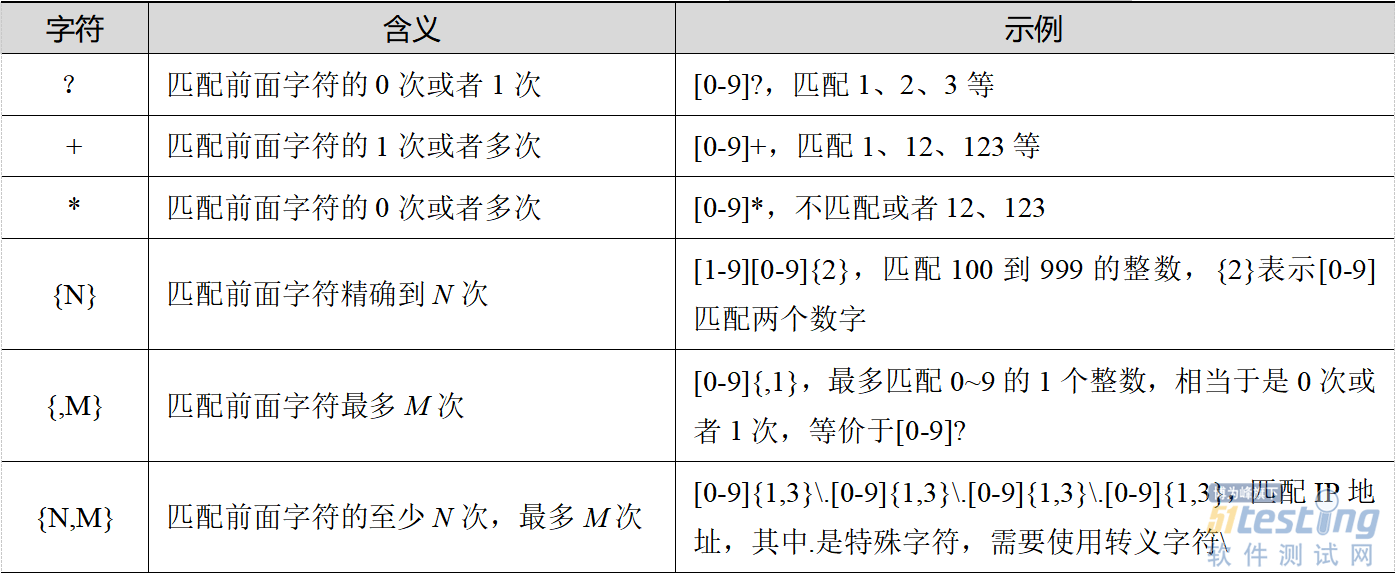
表4-22 数量限定符及其含义

表4-23 位置符及其含义
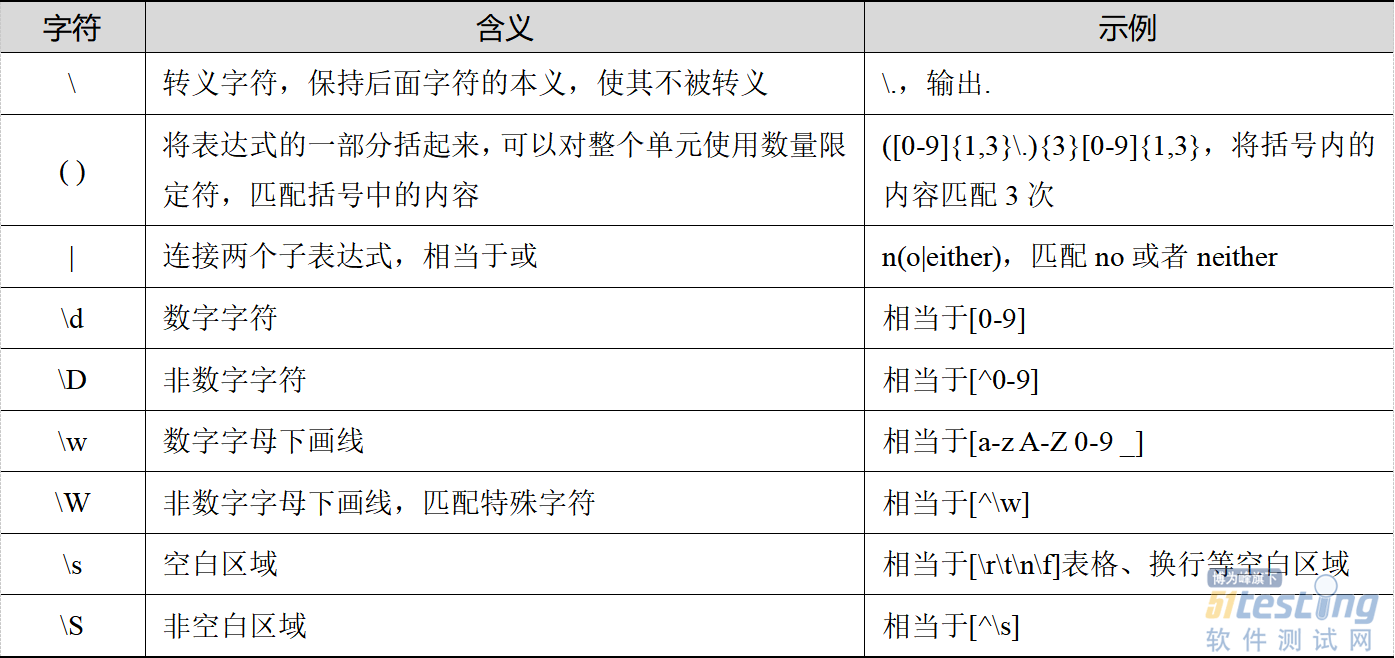
表4-24 特殊含义符及其含义
4.8.2 re模块简介
我们利用re模块处理正则表达式,主要涉及5个常用的方法re.match()、re.search()、re.findall()、re.sub()和re.split()。下面逐一介绍5个方法的使用。
1.re.match()
re.match()方法从指定字符串的开始位置进行匹配,开始位置匹配成功则继续匹配,否则输出None。该方法返回一个正则匹配对象,我们可以通过如下两个方法获取相关内容:
通过group()方法获取内容;
通过span()方法来获取范围,匹配到字符的开始和结束的索引位置。
示例如下:
content = "Hello 1234567 World_This is a Regex Demo"
result = re.match("^Hello\s\d+\s\w{10}.*?Demo$",content)
print(result) # 字符串对象
print(result.group()) # 匹配到内容
print(result.span()) # 匹配到字符的开始和结束的索引位置
输出结果如下:
<re.Match object;span=(0,40),match='Hello 1234567 World_This is a Regex Demo'>
Hello 1234567 World_This is a Regex Demo
(0,40)
需要注意的是,group()方法获取内容的时候,索引符号从1开始,即group()返回的是全部内容,group(1)返回第一个()中的内容。
2.re.search()
re.search()方法扫描整个字符串,返回的是第一个成功匹配的字符串,否则返回None。示例如下:
str = "手机号:12345678901,银行卡号:123456"
res = re.search("号:(.*?),",str)
print(res) # 返回正则对象
print(res.group(0)) # 返回匹配到的全部内容
print(res.group(1)) # group中参数最大不能超过正则表达式中括号的个数
输出结果如下:
<re.Match object; span=(4,17),match'号:12345678901'>
号:12345678901
12345678901
注意,group(N)中的参数N不能超过正则表达式中括号的个数,若超过则报错。
3.re.findall()
re.findall()方法扫描整个字符串,通过列表形式返回所有匹配的字符串。示例如下:
str = "https://www.ptpress.com.cn,https://www.epubit.com,"
res = re.findall("https://(.*?),", str)
print(res)
输出结果如下:
['www.ptpress.com.cn', 'www.epubit.com']
如果存在多个.*?,则返回的内容使用列表中嵌套元组的形式。
4.re.sub()
re.sub()方法用来替换字符串中的某些内容。示例如下:
str = "https://www.ptpress.com.cn,https://www.epubit.com,"
res = re.sub(r"http", "https",str)
print(res)
输出结果如下:
https://www.ptpress.com.cn,https://www.epubit.com,
5.re.split()
re.split()主要用于分割字符串,示例如下。
re.split(pattern, string, maxsplit=0, flags=0)
用pattern分开字符串,如果在pattern中捕获到括号,那么所有的组里的文字将包含在列表里;如果maxsplit非零,最多进行maxsplit次分隔,剩下的字符全部返回到列表的最后一个元素。示例如下:
re.split(r'\W+', 'Books,books,books.') # \W表示非数字字符下画线
输出结果如下:
['Books', 'books', 'books', '']
贪婪模式与非贪婪模式
贪婪模式与非贪婪模式影响的是被量词修饰的子表达式的匹配行为。贪婪模式是在整个表达式匹配成功的前提下,尽可能多地匹配;而非贪婪模式是在整个表达式匹配成功的前提下,尽可能少地匹配。
在正则表达式中,我们经常会使用3个符号:
点.表示匹配的是除去换行符之外的任意字符;
问号?表示匹配0个或者1个;
星号*表示匹配0个或者任意个字符。
.*?表示非贪婪模式,.*表示贪婪模式。例如,比较re模块中两种匹配方式的不同。
输入:
str = "aaaacbabadceb"
res1 = re.findall("a.*?b", str) #非贪婪模式.*?尽可能少
输出结果如下:
['aaaacb', 'ab', 'adceb']
输入:
res2 = re.findall("a.*b", str) #贪婪模式.*?尽可能多
输出结果如下:
['aaaacbabadceb']
在上面的非贪婪模式中,我们使用了问号?,匹配到aaaacb已经达到要求,则停止第一次匹配。接下来再匹配ab和adceb,多个匹配结果存在于贪婪模式中,程序会找到最长的符合要求的字符串。
版权声明:51Testing软件测试网获得作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责












