

概述
传统的QA自动化测试通常是基于GUI的,比如使用Selenium,模拟用户在界面上操作。但GUI测试的开发、维护成本和运行的稳定性一直是测试界的老大难问题。投入大量的人力物力开发、维护、运行,却得不到相应的回报,令许多同行头痛不已。不过端对端(end to end)测试确实是QA/测试团队的重点工作之一,是绕不过的坎,怎么破?今天就分享一下基于API(HTTP层面)的自动化测试,姑且叫它“半端对端 (semi end to end)”吧。其实我认为它已经接近95%端对端了,为什么这样说?
假设有一个测试用例:
第1步:输入数据1
第2步:输入数据2
第3步:输入数据3
第4步:校验前面输入的数据
第5步:输入数据5
...
第n步:保存
第n+1步:输入查询条件
第n+2步:查询刚才保存的记录
第n+3步:校验查询结果
GUI的自动化测试通常会完全模拟上面所有步骤,每一步都要识别相应要操作的界面元素,进行输入点击等操作,或者从界面上抠出数据,进行校验。运行过程中任何一步的某个元素定位不到,或者任何原因的操作失败都会导致整个测试中断。
那么在API层面怎么做上面的测试呢?
第1步:发送上面第n步的“保存”操作的HTTP,得到response,并记录里面返回的ID等有用信息。可以直接跳过前面所有步骤是因为,保存时所发送的HTTP请求里面已经包含了所有前面输入的并且经过校验的有效数据。
第2步:发送上面第n+2步的查询操作的HTTP请求,得到response,并校验里面的结果。
对,就这么简单。理论上跟GUI上的测试效果是接近的,除了一些纯界面上的逻辑(这些通常并不是我们的回归测试重点,起码在我所经历的项目中)。最大的好处是完全不碰界面,极大的消除了操作GUI所带来的开发、维护成本和运行的不稳定性。也许你有很多疑问,没关系,接着看完也许就有了解答。
实践当中可以进行HTTP测试的库选择很多,大多数编程语言都有现成的HTTP库可以使用,比如python、java等。这里使用现在流行的node.js进行讲解。原因很简单,大家知道HTTP是无状态的,多个HTTP请求之间通常没有互相依赖,大多数情况下没有必要让测试一个个的跑完一个再跑另一个,所以自然就想到让多个HTTP请求并行测试,可以极大的提高效率减少测试时间。node.js的最强项就是非阻塞的异步I/O,是理想的测试HTTP的平台。这里使用了一个第三方的HTTP客户端superagent,大家可以从npm下载,到它的github页面查看API文档。
原理
这种API测试的核心原理是,首先保存一个离线的期望结果,然后调用HTTP请求,把实时返回的response与期望结果进行对比,可进行文本对比,或者JSON对比,大多数REST服务返回的都是JSON格式数据。
听起来似乎很多工具比如SoapUI也可以做到啊,为什么要自己开发呢,原因就是对于企业系统或者任何较大规模的系统来讲需要批量测试成百上千甚至几千个web service,不同的service需要灵活定制对结果的处理并校验,生成、发送测试报告,定期运行,甚至与运维工具进行集成等等,第三方工具没有这么大的灵活性。
从某种程度上讲API测试也很像性能测试,不过我们比性能测试更加关心对返回结果的校验。
下面是主要工作流程的详细解释:
录制HTTP:
首先,上面提到的期望结果从哪里来?你可以自己动手写出来保存到一个文件里面,但是对于回归测试来讲这样太原始,在一些企业级应用里面HTTP不管request还是response数据都大的惊人(很多需要进行压缩),数据结构也很复杂,几乎不可能纯手工进行定制。回归测试通常需要进行大量API测试,一个个手写期望结果也不科学。所以最好的办法就是使用工具进行HTTP录制。可以用的工具很多,但其中最强大的非Fiddler莫属。Fiddler的设置这里不详述,大家可以自行谷歌。
Fiddler设置好了以后(主要是把浏览器的代理指向它,并且打开Decode选项,如下图),就可以在界面上把测试用例手动操作一遍,Fiddler就会完整无缺的把所有的HTTP的request和reponse录制下来,当然可以设置一些过滤条件,把那些下载js, css脚本的,下载图片的http滤掉,只保留纯粹的与服务器进行数据交换的服务,这才是我们要测试的东西。把录到的所有http的request和response保存为文本文件。
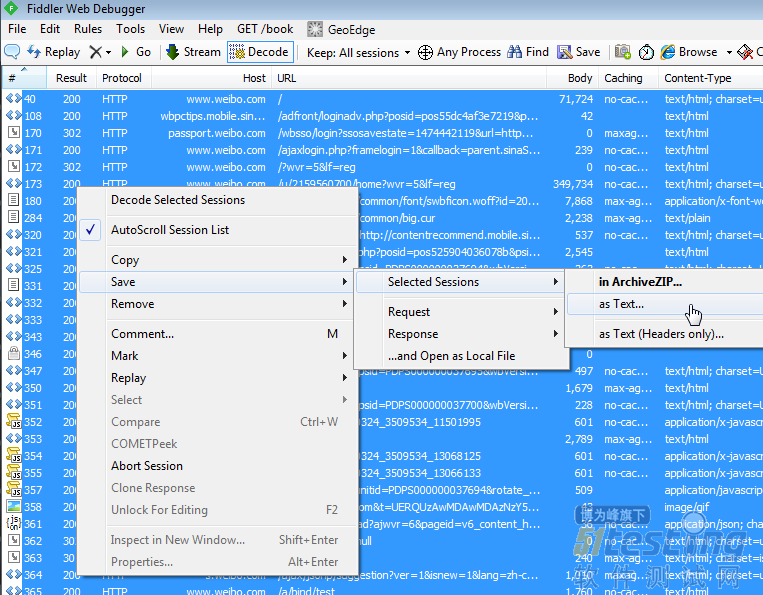
保存好的http文本是标准的http协议的格式包括header, body等部分。
解析HTTP文本:
测试过程的第一步是把所有录制下来要测试的HTTP一个个解析出来放到javascript对象里面,以备下一步回放时候调用及校验结果。这里是解析出来的样子:
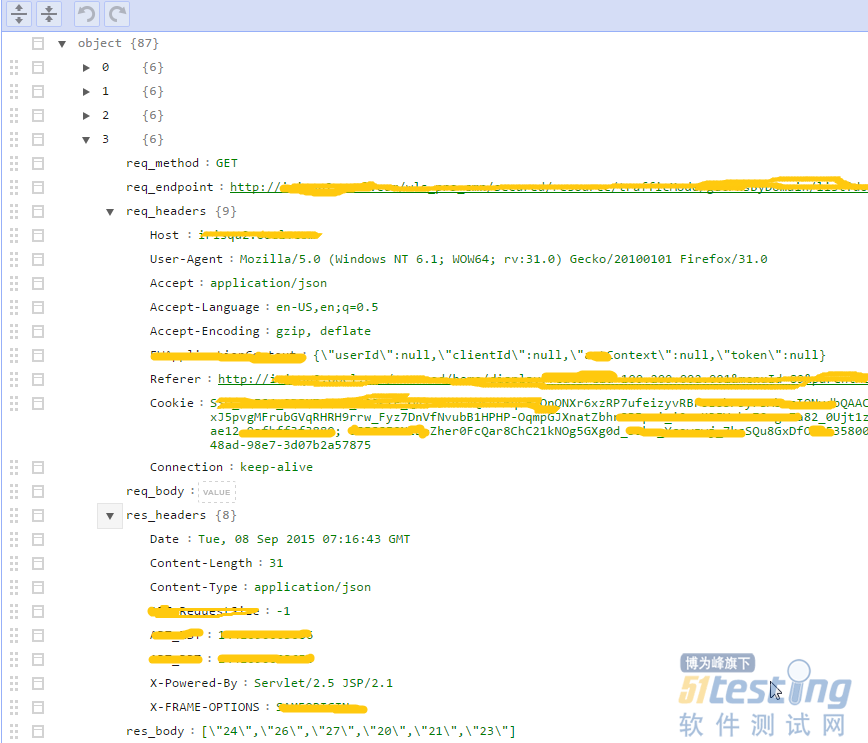
解析的过程使用了node.js的原生API 'readline',逐行读取文本文件,把相应信息写入Javascript对象:
{
req_method: '',
req_endpoint: '',
req_headers: {},
req_body: '',
res_headers: {},
res_body: ''
}
执行准备工作(set up):
首先取得登录信息:
在正式测试之前通常需要先登录你要测试的系统,取得登录cookie,然后把这个cookie替换掉之前录制的http头部的cookie信息,才能顺利回放所有的http。登录的过程每个系统都不同,需要自己加以研究。我所测试的系统需要按顺序调用5个web service才能最终拿到包含登录信息的cookie。研究时,需要在浏览器里面进行实际的登录操作,然后每一步都研究一下http request和reponse,基本上每一步的response(或者在header里面或者在body里面)都包含下一步request里面需要包含的信息,要花点心思研究出来。有一点要注意的是,用浏览器登录的过程中可能会有几次自动重定向,你在用脚本模拟的时候要把它取消,因为每一步http都要你显式的发送、接收。suerperagent这样取消自动重定向:
superagent.get(‘www.baidu.com’).redirects(0)
如果要测试的系统都是HTTPS,需要取得信任证书,并导出来(浏览器登录https的时候会要求接受证书,这个过程中可以导出来),以备模拟登录时使用。superagent使用证书简单示例,假设已准备好的证书文件为abc.pem:
process.env.NODE_TLS_REJECT_UNAUTHORIZED = '0';
var cert = fs.readFileSync(__dirname + '/abc.pem');
superagent.get('https://abc.com')
.ca(cert)
.end(function(err, res) {...});
注意node.js里面一定要设置 process.env.NODE_TLS_REJECT_UNAUTHORIZED = '0'; 才能成功。
其他准备工作:
除了获取系统登录信息,有可能还需要取得一些其他准备信息,比如替换掉其中某些http的一些请求信息。举个例子,如果所测试的http中需要用到其他单证号码,可以先准备好,测试时进行替换。通常有两种做法,第一是离线准备很多单证号码保存在文件里面或者数据库,测试的时候直接拿来使用就可以了,如果不能重复使用则需要把用过的进行标记。第二种方法是现场实时创建新的单证(也是调用HTTP来创建),然后使用它。
一般推荐使用第一种方法,这样避免把你要测试的用例和创建单证耦合在一起(虽然实际你的系统中它们确实在同一个业务流程里面),即使创建单证的功能有问题,也不影响你当前要做的测试,测试报告也更加准确。而且这样做可以减少这个测试框架的复杂度。
准备好了之后,一次性把刚才解析出来的http对象相关的信息替换掉,头部里面的cookie,有些需要替换URL中的信息,有些需要替换request body里面的信息,根据需要进行。
执行测试:
准备就绪后就是进行批量调用所有的HTTP请求。
刚才提到过大部分HTTP之间没有相互依赖,所以主要是要以并行测试为主,也就是说每一个HTTP调用后不需要等它返回就直接调用下一个,像机关枪一样瞬间把所有请求都发出去,每个HTTP的测试都是并行的,这样可以节省大量的时间,效率非常高,100个HTTP十几秒就跑完了,跟selenium在GUI上跑相比,那更是一个天上一个地下了。
superagent发送接收HTTP简单示例:
function request(httpReq, testData) { //httpReq代表一个http; testData主要是设置对http response进行校验的黑白名单等等
return new Promise(function(resolve) {
var assert = require('./assertion.js').assert, //引入自己开发的assertion模块对http reponse进行校验
endpoint = httpReq.req_endpoint,
req_method = httpReq.req_method.toLowerCase(),
req_headers = httpReq.req_headers,
req_body = httpReq.req_body;
superagent[req_method](endpoint)
.set(req_headers)
.send(req_body)
.timeout(10000)
.end(function(err, res) {
var result = assert(httpReq, res, testData);
resolve(result);
});
});
}
刚才讲大部分都是并行,那就是说有些是需要串行的,有些比较复杂的应用确实需要按顺序执行,HTTP的调用是有先后的,否则,不能保证成功(因为异步操作不能够保证谁先做完)。这种通常发生在创建比较复杂的单证上面,它进行分步校验或保存,有一定的先后顺序。
这个还是比较考验node.js异步编程能力的,并行不难,反而怎样保证几十个上百个异步操作串行,就有点难度了,需要用到Promise或者Generator的异步控制技术。以下是Promise示例代码。
var superagent = require('superagent');
function execute(httj, testData) { //httj是所有解析出来的http对象集合; testData是为需要的http设置的黑白名单等校验条件
var failureCount = 0,
logs = [];
if (testData.serial) { //串行
var p = Promise.resolve();
for (var key in httj) {
void function(k) {
p = p.then(function(result) {
log(result);
return request(httj[k], testData); //request函数简单包装了superagent执行HTTP的方法,见上一段示例代码
});
}(key);
}
p.then(function(result) {
log(result);
});
} else { //并行
var allWS = [];
for (key in httj) {
allWS.push(request(httj[key], testData));
}
p = Promise
.all(allWS)
.then(function(arr) {
for (var result of arr) {
log(result);
}
});
}
return p.then(function() {
var isPassed, report;
failureCount === 0 ? isPassed = true : isPassed = false;
report = logs.sort().join('');
return { //生成最终测试结果
isPassed,
report
};
});
function log(result) {
if (result !== undefined) {
if (result.status === 'failed') {
++failureCount;
}
logs.push(result.info);
}
}
}
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












