# 定于预测目标变量名
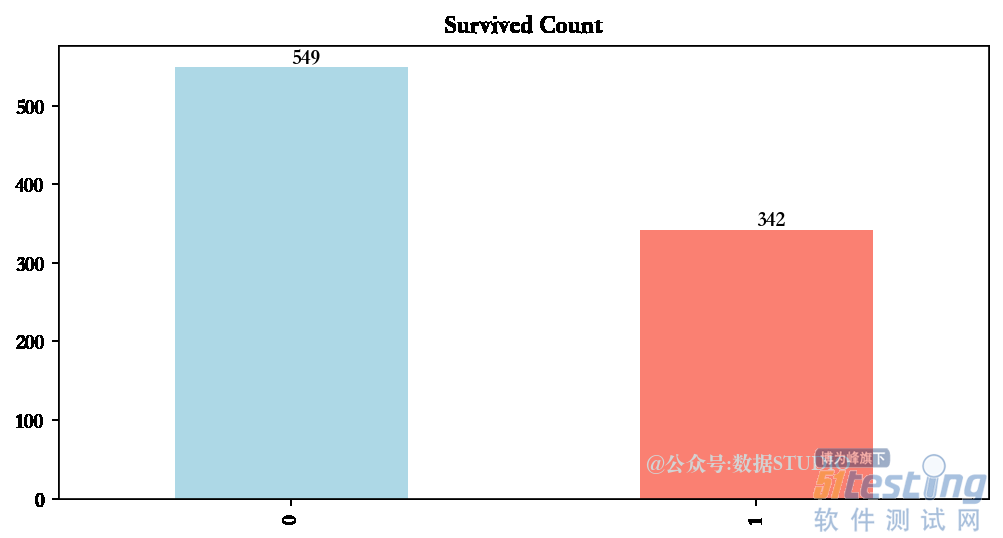
Target = ["Survived"]
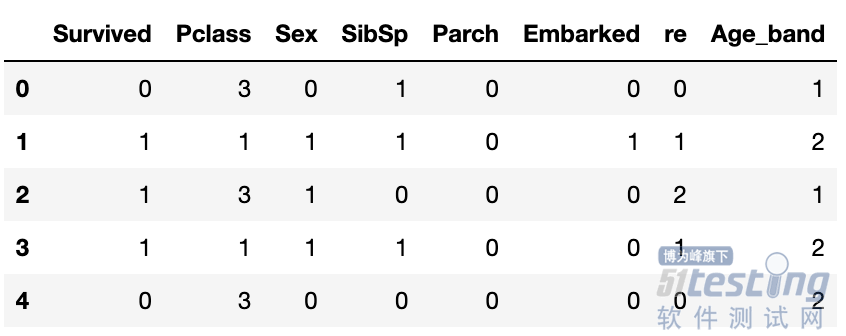
## 定义模型的自变量名
train_x = ["Pclass", "Sex", "SibSp", "Parch",
"Embarked", "Age_band","re"]
##将训练集切分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(
data[train_x], data[Target],
test_size = 0.25,random_state = 1)
## 先使用默认的参数建立一个决策树模型
dtc1 = DecisionTreeClassifier(random_state=1)
## 使用训练数据进行训练
dtc1 = dtc1.fit(X_train, y_train)
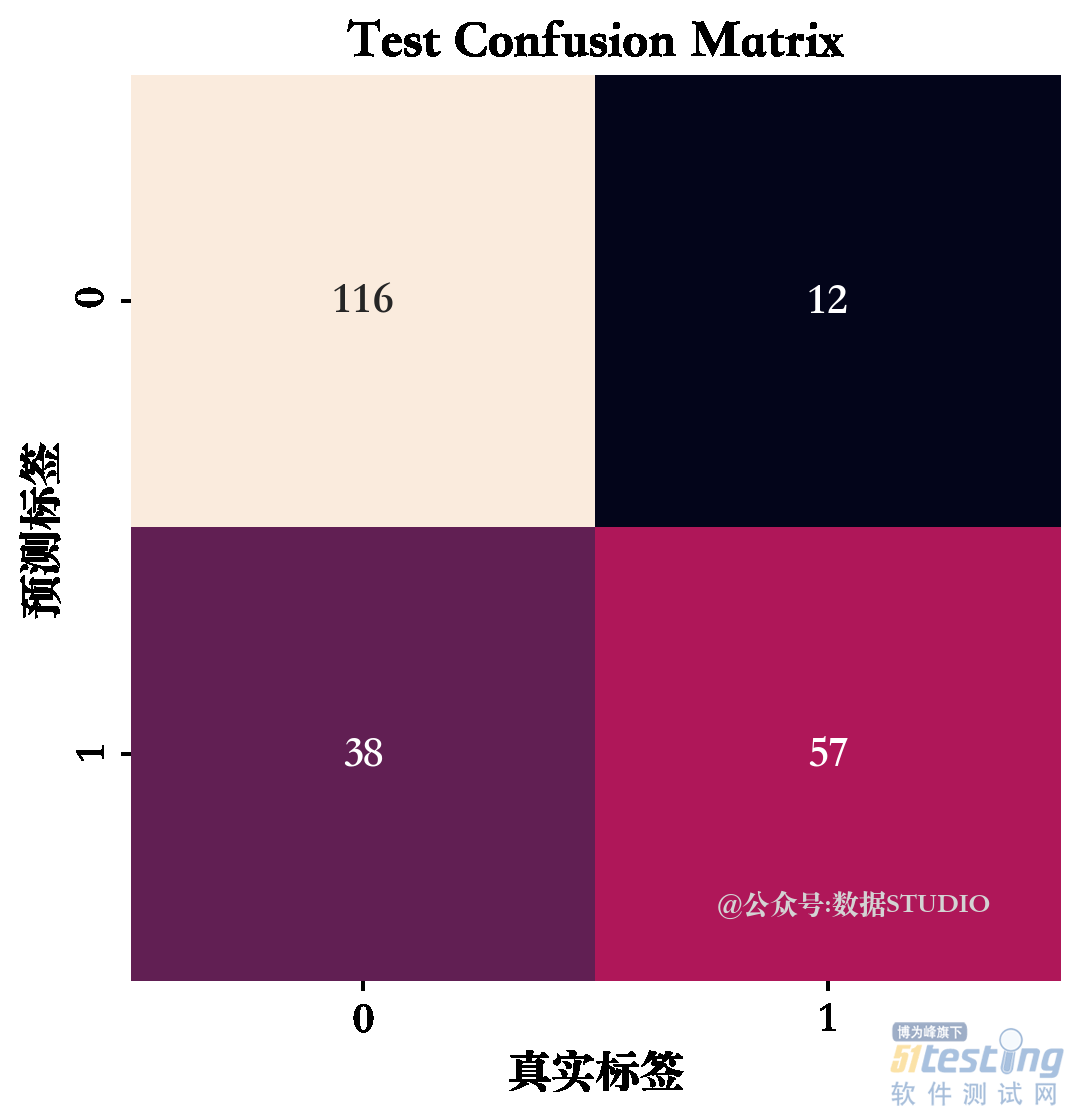
## 输出其在训练数据和验证数据集上的预测精度
dtc1_lab = dtc1.predict(X_train)
dtc1_pre = dtc1.predict(X_val)
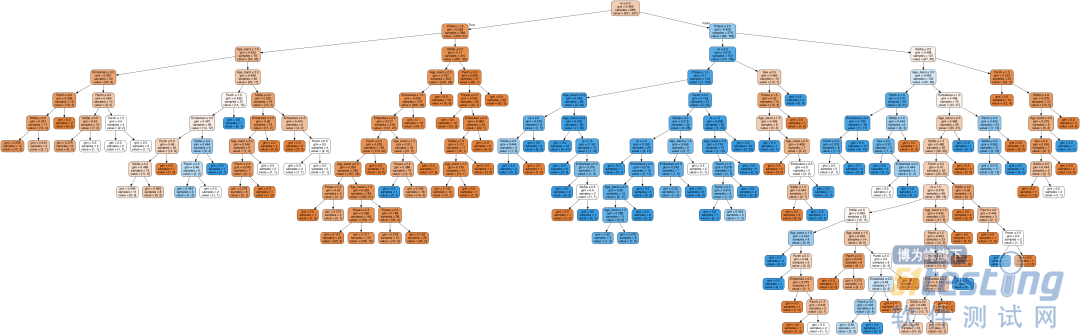
## 将获得的决策树结构可视化
dot_data = StringIO()
export_graphviz(dtc1, out_file=dot_data,
feature_names=X_train.columns,
filled=True, rounded=True,special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())