
Python 强大的任务调度框架 Celery!(4)
自定义任务流
有时候我们也可以将执行的多个任务,划分到一个组中。
# celery_demo/tasks/task1.py
from app import app
@app.task()
def add(x, y):
print("加法计算")
return x + y
@app.task()
def sub(x, y):
print("减法计算")
return x - y
@app.task()
def mul(x, y):
print("乘法计算")
return x * y
@app.task()
def div(x, y):
print("除法计算")
return x // y
老规矩,重启 worker,因为我们修改了任务工厂。
然后来导入它们,创建任务,并将这些任务划分到一个组中。
>>> from tasks.task1 import add, sub, mul, div
>>> from celery import group
# 调用 signature 方法,得到 signature 对象
# 此时 t1.delay() 和 add.delay(2, 3) 是等价的
>>> t1 = add.signature(args=(2, 3))
>>> t2 = sub.signature(args=(2, 3))
>>> t3 = mul.signature(args=(2, 3))
>>> t4 = div.signature(args=(4, 2))
# 但是变成 signature 对象之后,
# 我们可以将其放到一个组里面
>>> gp = group(t1, t2, t3, t4)
# 执行组任务
# 返回 celery.result.GroupResult 对象
>>> res = gp()
# 每个组也有一个唯一 id
>>> print("组id:", res.id)
组id: 65f32cc4-b8ce-4bf8-916b-f5cc359a901a
# 调用 get 方法也会阻塞,知道组里面任务全部完成
>>> print("组结果:", res.get())
组结果: [5, -1, 6, 2]
>>>
可以看到整个组也是有唯一 id 的,另外 signature 也可以写成 subtask 或者 s,在源码里面这几个是等价的。
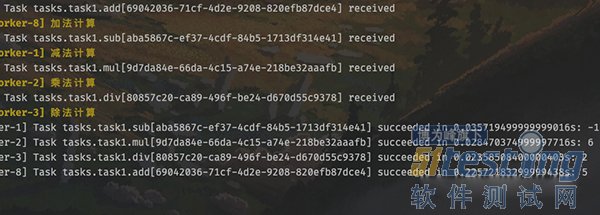
我们观察一下 worker 的输出,任务是并发执行的,所以哪个先完成不好说。但是调用组的 get 方法时,里面的返回值顺序一定和任务添加时候的顺序保持一致。
除此之外,celery 还支持将多个任务像链子一样串起来,第一个任务的输出会作为第二个任务的输入,传递给下一个任务的第一个参数。
# celery_demo/tasks/task1.py
from app import app
@app.task
def task1():
l = []
return l
@app.task
# task1 的返回值会传递给这里的 task1_return
def task2(task1_return, value):
task1_return.append(value)
return task1_return
@app.task
# task2 的返回值会传递给这里的 task2_return
def task3(task2_return, num):
return [i + num for i in task2_return]
@app.task
# task3 的返回值会传递给这里的 task3_return
def task4(task3_return):
return sum(task3_return)
然后我们看怎么将这些任务像链子一样串起来。
>>> from tasks.task1 import *
>>> from celery import chain
# 将多个 signature 对象进行与运算
# 当然内部肯定重写了 __or__ 这个魔法方法
>>> my_chain = chain(
... task1.s() | task2.s(123) | task3.s(5) | task4.s())
>>>
# 执行任务链
>>> res = my_chain()
# 获取返回值
>>> print(res.get())
128
>>>
这种链式处理的场景非常常见,比如 MapReduce。
celery 实现定时任务
既然是定时任务,那么就意味着 worker 要后台启动,否则一旦远程连接断开,就停掉了。因此 celery 是支持我们后台启动的,并且可以启动多个。
# 启动 worker
celery multi start w1 -A app -l info
# 可以同时启动多个
celery multi start w2 w3 -A app -l info
# 以上我们就启动了 3 个 worker
# 如果想停止的话
celery multi stop w1 w2 w3 -A app -l info
但是注意,这种启动方式在 Windows 上面不支持,因为 celery 会默认创建两个目录,分别是 /var/log/celery 和 /var/run/celery,显然这是类 Unix 系统的目录结构。
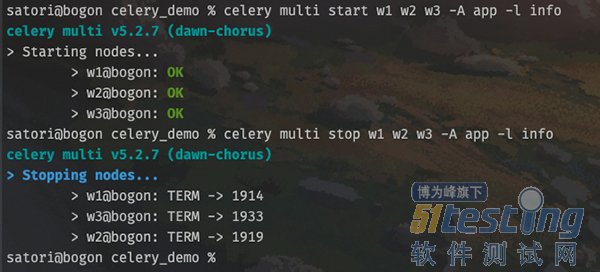
显然启动和关闭是没有问题的,不过为了更好地观察到输出,我们还是用之前的方式,选择前台启动。
然后回顾一下 celery 的架构,里面除了 producer 之外还有一个 celery beat,也就是调度器。我们调用任务工厂的 delay 方法,手动将任务发送到队列,此时就相当于 producer。如果是设置定时任务,那么会由调度器自动将任务添加到队列。
我们在 tasks 目录里面再创建一个 period_task1.py 文件。
# celery_demo/tasks/period_task1.py
from celery.schedules import crontab
from app import app
from .task1 import task1, task2, task3, task4
@app.on_after_configure.connect
def period_task(sender, **kwargs):
# 第一个参数为 schedule,可以是 float,或者 crontab
# crontab 后面会说,第二个参数是任务,第三个参数是名字
sender.add_periodic_task(10.0, task1.s(),
name="每10秒执行一次")
sender.add_periodic_task(15.0, task2.s("task2"),
name="每15秒执行一次")
sender.add_periodic_task(20.0, task3.s(),
name="每20秒执行一次")
sender.add_periodic_task(
crontab(hour=18, minute=5, day_of_week=0),
task4.s("task4"),
name="每个星期天的18:05运行一次"
)
# celery_demo/tasks/task1.py
from app import app
@app.task
def task1():
print("我是task1")
return "task1你好"
@app.task
def task2(name):
print(f"我是{name}")
return f"{name}你好"
@app.task
def task3():
print("我是task3")
return "task3你好"
@app.task
def task4(name):
print(f"我是{name}")
return f"{name}你好"
既然使用了定时任务,那么一定要设置时区。
# celery_demo/config.py
broker_url = "redis://:maverick@82.157.146.194:6379/1"
result_backend = "redis://:maverick@82.157.146.194:6379/2"
# 之前说过,celery 默认使用 utc 时间
# 其实我们是可以手动禁用的,然后手动指定时区
enable_utc = False
timezone = "Asia/Shanghai"
最后是修改 app.py,将定时任务加进去。
from celery import Celery
import config
app = Celery(
__name__,
include=["tasks.task1", "tasks.period_task1"])
app.config_from_object(config)
下面就来启动任务,先来启动 worker,生产上应该后台启动,这里为了看到信息,选择前台启动。
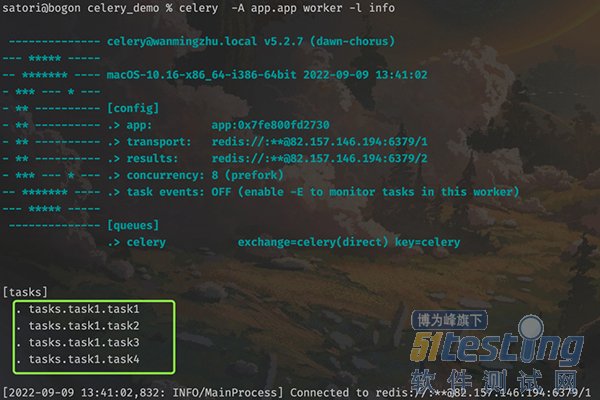
tasks.task1 里面的 4 个任务工厂都被添加进来了,然后再来启动调度器。

调度器启动之后会自动检测定时任务,如果到时间了,就发送到队列。而启动调度器的命令如下:

根据调度器的输出内容,我们知道定时任务执行完了,但很明显定时任务本质上也是任务,只不过有定时功能,但也要发到队列里面。然后 worker 从队列里面取出任务,并执行,那么 worker 必然会有信息输出。
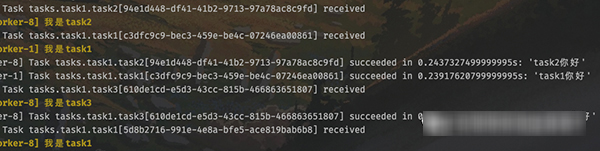
调度器启动到现在已经有一段时间了,worker 在终端中输出了非常多的信息。
此时我们就成功实现了定时任务,并且是通过定义函数、打上装饰器的方式实现的。除此之外,我们还可以通过配置的方式实现。
# celery_demo/tasks/period_task1.py
from celery.schedules import crontab
from app import app
# 此时也不需显式导入任务工厂了
# 直接以字符串的方式指定即可
app.conf.beat_schedule = {
# 参数通过 args 和 kwargs 指定
"每10秒执行一次": {"task": "tasks.task1.task1",
"schedule": 10.0},
"每15秒执行一次": {"task": "tasks.task1.task2",
"schedule": 15.0,
"args": ("task2",)},
"每20秒执行一次": {"task": "tasks.task1.task3",
"schedule": 20.0},
"每个星期天的18:05运行一次": {"task": "tasks.task1.task4",
"schedule": crontab(hour=18,
minute=5,
day_of_week=0),
"args": ("task4",)}
}
需要注意:虽然我们不用显式导入任务工厂,但其实是 celery 自动帮我们导入。由于这些任务工厂都位于 celery_demo/tasks/task1.py 里面,而 worker 也是在 celery_demo 目录下启动的,所以需要指定为 tasks.task1.task{1234}。
这种启动方式也是可以成功的,貌似还更方便一些,但是会多出一个文件,用来存储配置信息。
crontab 参数
定时任务除了指定一个浮点数之外(表示每隔多少秒执行一次),还可以指定 crontab。关于 crontab 应该都知道是什么,我们在 Linux 上想启动定时任务的话,直接 crontab -e 然后添加即可。
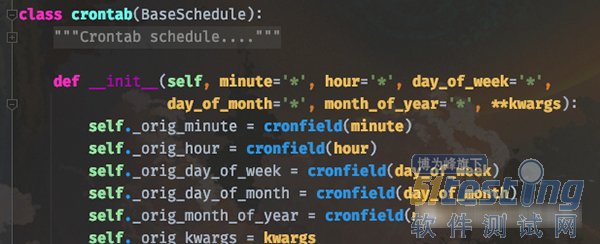
而 celery 的 crontab 和 Linux 高度相似,我们看一下函数原型就知道了。
简单解释一下:
minute:0-59,表示第几分钟触发,* 表示每分钟触发一次;
hour:0-23,表示第几个小时触发,* 表示每小时都会触发。比如 minute=2, hour=*,表示每小时的第二分钟触发一次;
day_of_week:0-6,表示一周的第几天触发,0 是星期天,1-6 分别是星期一到星期六,不习惯的话也可以用字符串 mon,tue,wed,thu,fri,sat,sun 表示;
month_of_year:当前年份的第几个月;
以上就是这些参数的含义,并且参数接收的值还可以是一些特殊的通配符:
*:所有,比如 minute=*,表示每分钟触发;
*/a:所有可被 a 整除的时候触发;
a-b:a 到 b范围内触发;
a-b/c:范围 a-b 且能够被 c 整除的时候触发;
2,10,40:比如 minute=2,10,40 表示第 2、10、40 分钟的时候触发;
通配符之间是可以自由组合的,比如 */3,8-17 就表示能被 3 整除,或范围处于 8-17 的时候触发。
除此之外,还可以根据天色来设置定时任务(有点离谱)。
from celery.schedules import solar
app.conf.beat_schedule = {
"日落": {"task": "task1",
"schedule": solar("sunset",
-37.81753,
144.96715)
},
}
solar 里面接收三个参数,分别是 event、lat、lon,后两个比较简单,表示观测者所在的纬度和经度。值大于 0,则对应东经/北纬,小于 0,则对应西经/南纬。
我们重点看第一个参数 event,可选值如下:
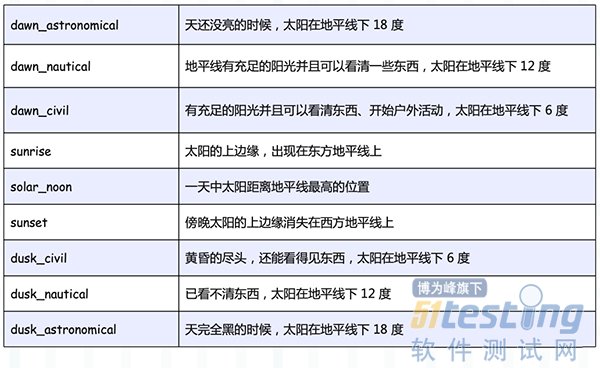
比如代码中的 "sunset", -37.81753, 144.96715 就表示,当站在南纬 37.81753、东经 144.96715 的地方观察,发现傍晚太阳的上边缘消失在西方地平线上的时候,触发任务执行。
个人觉得这个功能有点强悍,但估计绝大部分人应该都用不到,可能气象领域相关的会用的比较多。
小结
以上就是 celery 的使用,另外这里的 broker 和 backend 用的都是 Redis,其实还可以使用 RabbitMQ 和数据库。
broker_url = "amqp://admin:123456@82.157.146.194:5672//"
result_backend = "mysql+pymysql://root:123456@82.157.146.194:3306/store"
可以自己测试一下,但不管用的是哪种存储介质,对于我们使用 celery 而言,都是没有区别的。
celery 在工作中用的还是比较多的,而且有一个调度工具 Apache airflow,它的核心调度功能也是基于 celery 实现的。
软件测试行业调查报告是什么,点击下方链接了解详情。带你发现更多的测试类型和工具,更有免费课程等你拿~
相关阅读:
- 别再听中介忽悠了,用Python租到最合适的房子! (liqianqian1116, 2022-9-16)
- Python 的四舍五入的两个方法,你学会了吗? (liqianqian1116, 2022-9-19)
- Python 强大的任务调度框架 Celery!(1) (liqianqian1116, 2022-9-19)
- Python 强大的任务调度框架 Celery!(2) (liqianqian1116, 2022-9-19)
- Python 强大的任务调度框架 Celery!(3) (liqianqian1116, 2022-9-19)
标题搜索
我的存档
数据统计
- 访问量: 248446
- 日志数: 948
- 建立时间: 2020-08-11
- 更新时间: 2024-04-18
