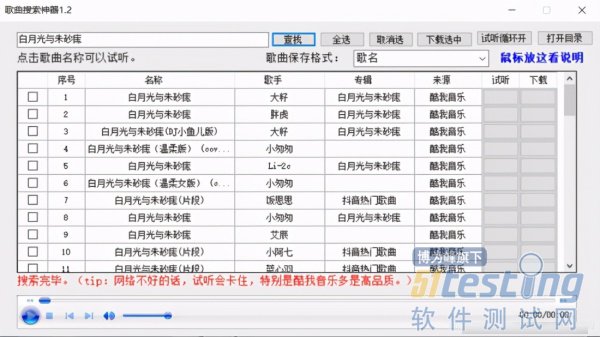
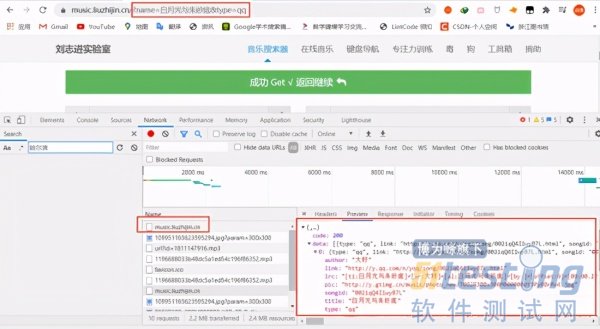
# 导入模块 from tkinter import * import requests import jsonpath import os from urllib.request import urlretrieve # 2.功能实现 """ 1.url 2.模拟浏览器请求 3.解析网页源代码 4.保存数据 """ def song_download(url,title,author): # 创建文件夹 os.makedirs("music",exist_ok=True) path = 'music\{}.mp3'.format(title) text.insert(END,'歌曲:{0}-{1},正在下载...'.format(title,author)) # 文本框滑动 text.see(END) # 更新 text.update() # 下载 urlretrieve(url,path) text.insert(END,'下载完毕,{0}-{1},请试听'.format(title,author)) # 文本框滑动 text.see(END) # 更新 text.update() def get_music_name(): """ 搜索歌曲名称 :return: """ name = entry.get() platfrom = var.get() # name = '白月光与朱砂痣' url = 'https://music.liuzhijin.cn/' headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36", # 判断请求是异步还是同步 "x-requested-with":"XMLHttpRequest", } param = { "input":name, "filter":"name", "type":platfrom, "page": 1, } res = requests.post(url=url,data=param,headers=headers) json_text = res.json() title = jsonpath.jsonpath(json_text,'$..title') author = jsonpath.jsonpath(json_text,'$..author') url = jsonpath.jsonpath(json_text, '$..url') print(title,author,url) song_download(url[0],title[0],author[0]) # 1.用户界面 # 创建画板 root = Tk() # 设置窗口标题 root.title('全网音乐下载器') # 设置窗口大小以及出现的位置 root.geometry('560x450+400+200') # 标签组件 label = Label(root,text="请输入下载的歌曲:",font=('楷体',20)) # 定位与布局 label.grid(row=0) # 输入框组件 entry = Entry(root,font=('宋体',20)) entry.grid(row=0,column=1) # 单选按钮 var = StringVar() r1 = Radiobutton(root,text='网易云',variable=var,value='netease') r1.grid(row=1,column=0) r2 = Radiobutton(root,text='QQ',variable=var,value='qq') r2.grid(row=1,column=1) # 列表框 text = Listbox(root,font=('楷体',16),width=50,height=15) text.grid(row=2,columnspan=2) # 下载按钮 button1 = Button(root,text='开始下载',font=('楷体',15),command=get_music_name) button1.grid(row=3,column=0) button2 = Button(root,text='退出程序',font=('楷体',15),command=root.quit) button2.grid(row=3,column=1) # 显示界面 root.mainloop() # 如何将.py代码打包成.exe文件 |