在后台的Python:众多程序员无法攻克的难题
上一篇 /
下一篇 2021-01-25 11:51:11
本文就将解答“运行
python代码时会发生什么?”,重点介绍很流行的Python工具CPython。如果你不知道正在使用何种Python工具,那么你90%使用的是CPython。
先看两个超级简单的代码。
for i inrange(10**7): x = i %5 |
代码1:简单代码
defmain(): for i inrange(10**7): x = i %5 main() |
代码2:定义了一个主函数来运行相同的简单代码。
两个代码都执行一个虚拟任务。取0到1000万之间的数字(通过for循环),并计算其模(余数)为5,到目前为止操作非常简单。那么,测量代码的运行时间是多少呢?
import time start_time = time.time() for i inrange(10**7): x = i %5 finish_time = time.time() print("Duration:{} msec".format((finish_time-start_time)*1000)) |
在代码1中添加一个简单的计时器
import time defmain(): for i inrange(10**7): x = i %5 start_time = time.time() main() finish_time = time.time() print("Duration:{} msec".format((finish_time-start_time)*1000)) |
在代码2中添加一个简单的计时器
在两个代码中添加一个简单的计时器来测量各自的运行时间。由于两个代码执行相同的简单任务,预计运行时间也相同。当然,如果运行时间真的相同,本文就没有存在的必要了。事实上,代码1和代码2的运行时间分别为739毫秒和434毫秒,惊讶吧!
很多Python程序员并不知道这个难题,因为这需要深入理解Python的运行原理。本文就将解答“运行python代码时会发生什么?”,重点介绍很流行的Python工具CPython。如果你不知道正在使用何种Python工具,那么你90%使用的是CPython。
以下是运行源代码时的情况:
首先,源代码通过“词法分析”程序被分解成标记,例如, x=1将被分解成x, =,和1。然后,通过“句法分析”的过程,这些标记被组织成抽象语法树(AST),之后“编译器”将所有内容转换成为一个叫做“字节码”的抽象代码。
在Python中,不像C、C++、Java等语言,编译器不会获取“源代码”并将其转换为“机器代码”,理解这一点很重要。与之相反,编译器可接受“源代码”并且将其转换为“字节码”。解释器的任务是获取字节码并以机器能够理解的方式运行。
在Python运行代码的四个步骤中,解释器负责最繁重的工作。而其他三个步骤不会处理太多的任务。因此,任何时候想要研究Python程序的性能时,应该查看解释步骤并寻找一些线索。
解释器读取字节码并运行其指令。如果字节码类似于菜谱,那么指令便是菜谱中的不同步骤。如果字节码可读取,就可能找到关于上述谜题的一些线索。使用 dis包来查看字节码指令。dis是一个Python包,用于分析和解码字节码,并以人们可以理解的方式显示出来。dis.dis() 的输出结构如下:
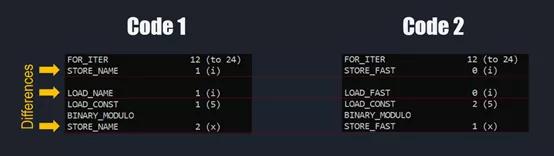
本文不详细介绍dis包的细节,只关注Operation Named的一列。Operation name指示Python解释器的行为。如果你非常好奇,那么名为ceval.c的文件可以回答。以上两个代码都运行了dis.dis(),为了简化操作,本文突出显示重要部分,即循环部分。下图显示了这两个代码的字节码:
如图所示,两个代码在给定的指令方面非常相似。但是,仔细观察,会发现字节码中有一些细微的(但是很重要的)差异。在代码1中,可以看到STORE_NAME和LOAD_NAME,但是在代码2中,可以看到STORE_FAST和LOAD_FAST。运行时间的差异似乎是由于这两种指令类型的不同造成的。可以查看ceval.c文件来了解其中的差异。
简而言之,在代码1中,解释器处理变量i和x的方式与代码2不同(注意_NAME和_FAST后缀)。代码1中,i和x都是全局变量,而CPython将这些变量存储在字典数据结构中,这使得加载过程比存储在固定大小数组中的局部变量耗时更久。与字典相比,从固定大小的数组中检索变量要快得多。
为什么Python这么做?很简单,因为在主代码中,不知道有多少变量会出现,但是在一个函数中变量的数量是固定的。
如果这是原因所在,来做个
测试:把解释器打乱,在代码2(快速代码)中将x和i变量定义为全局变量,并再次测量运行时间。这是改变后的代码2:
defmain(): global i, x for i inrange(10**7): x = i %5 main() |
代码3与代码2相同,只是定义了变量i和x,以查看全局变量是否是导致难题代码性能变慢的原因。
运行代码3,用时805毫秒(代码2用时434 毫秒)。代码3的用时非常接近于代码1(即739毫秒)。这正如预计的,处理全局变量比处理局部变量(固定大小的数组与字典)花费更多的时间。
如你所见,只需要了解一点关于Python解释器的工作原理,以及从dis库中得到帮助,这个难题即可迎刃而解。
参与调查问卷,赢取测试好礼!
点击下方链接
成功提交后免费获得资料和课程
更有抽奖好礼等着你
收藏
举报
TAG: