

前言
目的
掘金里大佬太多了,分享各种牛批技术、代码、经验,看的美滋滋,但是在身为一只菜鸡的我也在思考,大家看了那么多文章,了解了那么多前沿技术,真正落地使用的又有多少?还是需要实战一下才能知道,什么时候需要用到什么技术手段,怎么合适的运用各种技术来解决问题。因此本篇文章并不是分享哪些技术多666,而是跟各位老哥一起根据一个具体需求,完成分析、设计编码、上线的全流程,形成一个真正可用的产品,以此来形成一种为了解决问题而选取相应技术的思维(牛批要先吹好)。
需求
Screenlapse也算是个比较有意思的产品了,它主要的功能就是帮助用户定期对指定网页进行截图,可以设置每天、每周、每月某一个特定时间点去做截图,截图随时预览,有了这么个服务你就可以给你的网站形成一个历史档案库,或者默默的视奸竞争对手网站网页的变化。
然而!!它是个PC站没有移动端,而且他好像被墙了,百度也不索引它
那么机会来了,我们自己做一个本土化的移动版的Screenlase,顺便把他做到公众号里
先放个成品



分析
冷静睿智机敏的分析一下问题
初步分析
用户功能:
微信用户登陆
用户添加爬取任务
用户删除爬取任务
用户修改爬取任务
用户查看所有任务
用户查看某一个任务的截图
后端功能:
定时把需要爬取的链接抓取个截图存下来
这么一看功能简单的一批,不就是增删改查么,辣鸡!
但是定眼一看,发现事情并不简单。
详细分析
1. 关于微信用户登陆
相比于小程序,公众号的微信用户登陆更麻烦一些,需要通过链接的跳转来获取到openid,然而坑并不在这!!!,因为我的公众号是个弱鸡的个人订阅号!连获取openid的权限都没有!!如果是原来,基本上就全剧终了,然而由于前端事件开通了个PayJs的个人微信支付接口,而里面刚好有个获取openid的接口(不知道用了什么黑科技),因此直接用这个接口来替代官方的接口获取openid
2. 用户登陆与验证
有了openid,后端直接根据openid在用户表里生成一条用户记录即可,关于如何生成,路子有很多,各位大佬都是明白人,根据具体情况选择合适的方法插一条就行
然后验证的话当然用烂大街的JWT方式,后台在用户登陆后验证完用户信息,返回个token给前端,前端存着token,每次调用的时候都带着,老套路了
3. 关于后台爬取
由于我的后端使用php写的,因此引申出了一些问题,
爬取页面截图
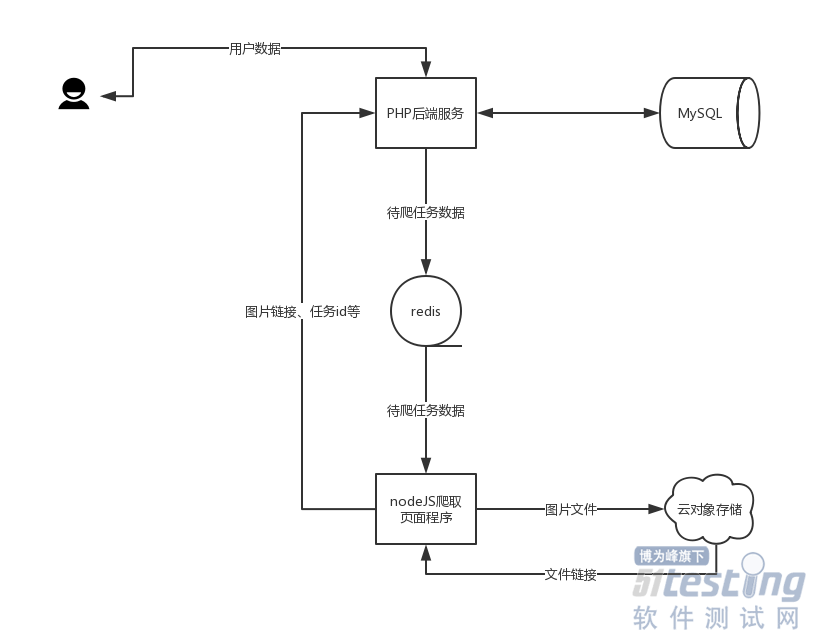
这种事情php虽然有办法但还是弱鸡一些没有nodejs使用puppeteer来的方便,既然nodejs能很方便的解决,那么自然就选择nodejs来爬取页面截图,然而这就会涉及到php的后端和nodejs爬取程序交互的问题,这里也有很多方式可以解决,可以通过接口,也可以通过其他方式,但是考虑到爬取任务的特点,在这里我选择了用redis做中间层(其他中间件做任务队列也都OJBK),利用redis的发布订阅模式,php将待爬取的任务放到redis里,nodejs的程序也作为订阅者,获取到任务,爬取完图片后通过接口将相关信息返回给php的后台。
图片存放位置
考虑到手上是个乞丐版的服务器,如果把图片放到服务器上,占用空间不说,每次客户端访问从服务器加载图片会占用大量带宽,影响网站性能,因此肯定要找个图床啦,我的服务器是腾讯云的给提供免费50G的对象存储,有了这个就好说了,puppeteer爬取完图片后把图片先暂存到服务器上,然后把图片上传到图床,获得图片链接,然后把服务器上的图片删掉,给php的后端返回的时候也只是返回一下图片链接就行啦
定时任务
系统需要一个定时任务,定时从数据库中取出需要进行爬取的数据,然后放入redis,然而php在这方面也是比较鸡肋,虽然有Swoole这种牛批的框架,但是为了解决一个小问题,不值当引入这么大的框架,因此选个这种方案,做个接口,然后利用BT面板配置个linux的定时任务,每隔几分钟就访问一下这个接口,然后接口就去搞一些列操作就完事啦
流程图
流程还是比较简单的
设计
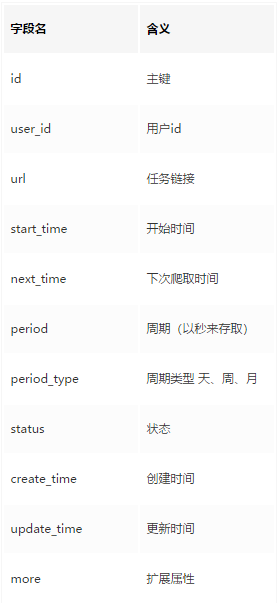
数据字段设计
根据上面的分析大概也知道了,核心功能区就是把用户需要爬取的链接存下来,定期取出来爬一下,然后把爬取到的图片链接存一下和用户的任务关联上即可,因此设计两张表就OJBK,简单的一批
1.任务表
2.任务图片表

接口设计
数据表设计完了,现在来识别一下,看看需要哪些接口
用户方面:
获取任务列表的接口(task/getByPage)
增加任务的接口(task/add)
删除任务的接口(task/delete)
修改任务的接口(task/update)
获取任务详细的接口(task/get)
查看任务已爬取图片的接口(task/getScreenshotByPage)
用户登陆接口
验证用户登录状态的接口
后台管理方面:
各位看官根据情况自行发挥啦
其他接口:
定时任务调用的接口(用来取处任务放入redis)
接收爬取图片信息的接口(供nodejs程序调用)
核心的接口就这些,足以撑起整个业务功能的闭环了
实现
实现分三部分分别实现,移动端、后台、nodeJS爬取程序
采取的一些工具如下:
后端:PHP/Thinkphp5.1 Nodejs
数据库:MySQL Redis
移动端:Vue+Vant
其他:服务器、BT面板(懒人专用、谁用谁知道)、公众号、对象存储
后端:
都是普通的增删改查,需要注意的是再添加任务的时候,需要在添加完成后立即生成一个爬取任务,爬一张图作为初始图片
public function add(Request $request){ //验证输入 (new TaskAddValidate())->goCheck(); //根据token获取用户id $userId=TokenService::getCurrentVars(TokenService::currentToken(),'id'); $startTime=$request->param('start_time'); $period=$request->param('period'); $periodType=$request->param('period_type',0); $url=$request->param('url'); //转换一下时间戳,php里是10位时间戳,js里是精确到毫秒的13位 if (strlen($startTime)>10){ $startTime=substr($startTime,0,10); } $nextTime=$startTime+$period; $more=[]; if($request->has('more')){ $more=json_decode(htmlspecialchars_decode($request->param('more')),true); } $task=TaskModel::create([ 'start_time'=>$startTime, 'next_time'=>$nextTime, 'period'=>$period, 'period_type'=>$periodType, 'url'=>$url, 'user_id'=>$userId, 'more'=>$more ]); //直接生成一个爬取任务,发布到redis RedisService::pushTask('tasks',$task); return ResultService::success('',$task); } |
爬取图片服务(使用puppeteer):
爬取并上传到腾讯云的对象存储
const puppeteer = require('puppeteer'); const redis=require('redis'); const redisConfig=require('./redis.config'); var COS = require('cos-nodejs-sdk-v5'); const axios=require('axios') const fs=require('fs'); const config=require('./config'); //订阅redis,接收任务 const redisClient=redis.createClient(redisConfig.port,redisConfig.host); redisClient.auth(redisConfig.password); redisClient.subscribe('tasks'); redisClient.on('message',(channel,msg)=>{ if(channel=='tasks'){ let task=JSON.parse(msg); getScreenshot(task); } }); //爬取截图 async function getScreenshot(task){ const browser = await puppeteer.launch({ headless: true,args: ['--no-sandbox', '--disable-setuid-sandbox'] }) const page = await browser.newPage() page.setViewport({ width: 1280, height: 960, }); await page.goto(task.url, { waitUntil: 'networkidle2' //等待页面不动了,说明加载完毕了 }) let basePath=config.basePath; let filenName=`${task.id}-${Date.now()}.png`; let filePath=basePath+filenName; await page.screenshot({ path: filePath ,fullPage:true}) //上传图片到云对象存储 let imgRes=await uploadScreenshot(filePath,filenName); //将图片链接回传给php服务端 let res=await axios.post(config.apiUrl,{ id:task.id, url:'http://'+imgRes.Location, plan_time:task.next_time }); //删除图片 fs.unlink(filePath,(err)=>{ if(err){ console.log(`删除文件不成功,原因${err}`); } }); } // 使用永久密钥创建实例 var cos = new COS({ SecretId: '***', SecretKey: '***' }); //上传图片到云对象存储 function uploadScreenshot(filePath,filenName){ return new Promise((resolve,reject)=>{ cos.sliceUploadFile({ Bucket: '***', Region: '***', Key: filenName, FilePath: filePath },(err,data)=>{ if(!err){ resolve(data); } else{ reject(err); } }); }) } |
移动端:
用的是vue+vant进行移动端开发,由于本菜鸡没什么审美,基本上也就是直接对vant组件进行使用拼拼凑凑就完事了,
项目目录如下
想分享的一点是,看了许多文章,对于在vue项目中进行网络接口调用的方式,一部分人偏爱于将所有的接口调用都以action的形式放到vuex里,所有的数据基本上都集中在了vuex中,然而以我得理解,vuex是为了全局数据共享而存在的,将所有数据都集中在vuex中可能会使vuex变得庞大,有违初衷,因此,我还是将所有的接口按业务区分都放在了api文件夹中,在需要的时候直接调用即可
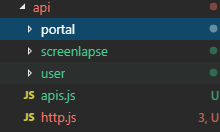
其中http.js是对axios进行的一个小封装,添加了一些拦截器,
每个业务文件夹中的接口均做成promise形式的方便并导出
import http from './../http' let register=(params=null)=>http.post('/api/front/user/register',params); let login=(params=null)=>http.post('/api/front/user/login',params); let checkLogin=()=>http.get('/api/front/user/checkLogin'); let logout=()=>http.post('/api/front/user/logout'); let getUser=()=>http.get('api/front/user/get'); export default { register, login, logout, checkLogin, getUser } |
apis则是用来将不同业务的接口进行集中,在使用的时候直接引用apis就可以了
import user from './user' import portal from './portal' import screenlapse from './screenlapse' let exportApi={ getSetting }; Object.assign(exportApi,user,portal,screenlapse) export default exportApi |
上线:
本地测试没问题,开始上线工作,结合上面的分析,我们需要对三个部分进行上线
系统是Centos7,使用的是BT面板一键搭建lnmp环境,进行日常运维与站点管理
后端服务上线(php)
使用bt面板直接建一个站点即可,使用面板自带的伪静态配置下隐藏index.php
移动端
本地打包完成后,上传到服务器,利用bt面板新建一个站点,该站点的目录指向移动端的文件,然后需要配置一下反向代理来解决一下跨域,基本上就是把某一个标识开头的请求转发一下
location ^~ /apis/ { proxy_pass https://api.yizhisamoye.cn/; } location ^~ /upload/ { proxy_pass https://api.yizhisamoye.cn; } |
爬取服务
注意两点
爬取服务由于只是一个简单的小程序,并没有使用node的http server相关的东西,因此没法使用pm2来启动和管理,不过也没关系,只要让程序跑起来在后台一直运行即可,使用命令来启动即可,定位到爬虫文件夹,使用命令nohup node spider.js即可,
安装完相关依赖启动后,爬虫报找不到chrome的错误,这时候需要对centos系统安装一下插件和依赖来保障puppeteer的运行
| yum install pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXtst.x86_64 cups-libs.x86_64 libXScrnSaver.x86_64 libXrandr.x86_64 GConf2.x86_64 alsa-lib.x86_64 atk.x86_64 gtk3.x86_64 ipa-gothic-fonts xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-utils xorg-x11-fonts-cyrillic xorg-x11-fonts-Type1 xorg-x11-fonts-misc -y |
最后
上线完后测试没什么问题,至此,完成了一个项目从需求到上线的全部过程,虽然没有用什么牛批技术,项目管理也基本没有,但是毕竟是菜鸡啊哈哈哈,主要还是给一些个人开发者提供一个思路,以解决问题的目标去应用技术,而不是为了应用技术而应用技术。
文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












