

ЎЎЎЎұіҫ°
ЎЎЎЎMysqlКэҫЭҝвЧчОӘКэҫЭіЦҫГ»ҜөДҙжҙўПөНіЈ¬ФЪКөјКТөОсЦРУҰУГ№г·әЎЈФЪУҰУГТІҫӯіЈ»бТтОӘSQLУцөҪёчЦЦёчСщөДЖҝҫұЎЈЧоіЈУГөДMysqlТэЗжКЗinnodbЈ¬ЛчТэАаРНКЗB-TreeЛчТэЈ¬ФцЙҫёДІйөИІЩЧчЧоҫӯіЈУцөҪөДОКМвКЗЎ°ІйЎұЈ¬ІйСҜУЦТФЛчТэОӘЦШөгЈЁГ»ЛчТэІ»КЗІЎЈ¬ВэЖрАҙМ«ТӘГьЈ©ЎЈІИ№эO2OУЕ»ЭИҜЎўТЎТ»ТЎЦЬұЯБҪёцТөОсөДТ»Р©ҝУЈ¬өұМёөҪSQLУЕ»ҜКұЈ¬Пл·ЦПнПВinnodbПВB-TreeЛчТэөДТ»Р©АнҪвУлКөјщЎЈ
ЎЎЎЎҪУПВАҙөДДЪИЭЈ¬°ІЕЕИзПВЈә
ЎЎЎЎ1ЎўҪйЙЬЛчТэөД№ӨЧчФӯАнЈ»
ЎЎЎЎ2ЎўТэУГКөАэҫЯМеҪйЙЬЛчТэЈ»
ЎЎЎЎ3ЎўИзәОК№УГexplainЕЕІйПЯЙПОКМвЈ»
ЎЎЎЎ4ЎўКөјКЕцөҪөДОКМв»гЧЬЈ»
ЎЎЎЎЛчТэИзәО№ӨЧч
ЎЎЎЎөұІйСҜКұЈ¬MysqlөДІйСҜУЕ»ҜЖч»бК№УГНіјЖКэҫЭФӨ№АК№УГёчёцЛчТэөДҙъјЫЈЁCOSTЈ©Ј¬УлІ»К№УГЛчТэөДҙъјЫЈЁCOSTЈ©ұИҪПЎЈMysql»бСЎФсҙъјЫЧоөНөД·ҪКҪЦҙРРІйСҜЎЈMysqlИзәОК№УГЛчТэЈ¬ҝЙТФУГПВГжөДОұҙъВлАҙЛөГчЈә
min_cost = INIT_VALUE min_cost_index = NONE for(index in all_indexs): if (index match WHERE_CLAUSE): cur_cost = COST(index) if(cur_cost < min_cost): min_cost = cur_cost min_cost_index = index |
ЎЎЎЎINIT_VALUEЈәІ»К№УГЛчТэКұөДҙъјЫ
ЎЎЎЎall_indexsЈәІйСҜұнЙПЛщУРөДЛчТэCOSTЈә»щұҫКЗУЙЎ°№АјЖРиТӘЙЁГиөДРРКэЎұЈЁrowsЈ©АҙИ·¶Ё
ЎЎЎЎWHERE_CLAUSEЈәІйСҜSQLЦРөДWHEREЧУҫд
ЎЎЎЎҙуЦВөДТвЛјЈәMysql»бұйАъёГІйСҜПа№ШөДұнЈЁtableЈ©өДГҝТ»МхЛчТэЈ¬И»әуЕР¶ПёГЛчТэДЬ·сұ»ұҫҙОІйСҜК№УГЈЁpossible_keysЈ©ЎЈөұЛчТэҝЙТФК№УГКұЈ¬MysqlФӨ№АК№УГёГЛчТэҪшРРІйСҜөДcostЈ¬И»әуСЎФсФӨ№АҙъјЫЧоөНөДҙъјЫөД·ҪКҪЈЁkeyЈ©ЦҙРРІйСҜЎЈ
ЎЎЎЎЛчТэЖҘЕд(match)
ЎЎЎЎФхСщЕР¶ПЛчТэКЗ·сЖҘЕдЈЁmatchЈ©SQLІйСҜЈҝ
ЎЎЎЎ1ЎўЛчТэөДЧуЗ°Чә№жФтЈ»ЛчТэЦРөДБРУЙЧуПтУТЦрТ»ЖҘЕдЈ¬Из№ыЦРјдДіТ»БРІ»ДЬК№УГЛчТэФтәуРтБРІ»ФЪІйСҜЦРІ»ФЩұ»К№УГЎЈ
ЎЎЎЎАэИзЈ¬Из№ыУРТ»ёц3БРЛчТэ(str_col1,col2,col3)Ј¬ЖдЦРstr_col1ОӘЧЦ·ыҙ®Ј¬Фт¶Ф(str_col1)Ўў(str_col1,col2)әН(str_col1,col2,col3)ЙПөДІйСҜҪшРРБЛЛчТэЎЈ
ЎЎЎЎИз№ыБРІ»№№іЙЛчТэЧоЧуГжөДЗ°ЧәЈ¬MySQLІ»ДЬК№УГЛчТэЎЈјЩ¶ЁУРПВГжПФКҫөДSELECTУпҫдЎЈ
ЎЎЎЎSELECT * FROM tbl_name WHERE str_col1=val1;
ЎЎЎЎSELECT * FROM tbl_name WHERE str_col1=val1 AND col2=val2;
ЎЎЎЎSELECT * FROM tbl_name WHERE col2=val2;
ЎЎЎЎSELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;
ЎЎЎЎИз№ы (str_col1Ј¬col2Ј¬col3)УРТ»ёцЛчТэЈ¬Ц»УРЗ°2ёцІйСҜК№УГЛчТэЎЈөЪ3ёцәНөЪ4ёцІйСҜИ·Кө°ьАЁЛчТэөДБРЈ¬ө«(col2)әН(col2Ј¬col3)І»КЗ (col1Ј¬col2Ј¬col3)өДЧоЧуұЯөДЗ°ЧәЎЈ
ЎЎЎЎ2ЎўwhereУпҫдЦРБРөДұнҙпКҪОӘ=Ўў>Ўў>=Ўў<Ўў<=ЎўBETWEENЎўISNULL»тХЯLIKE ЎҜpatternЎҜЈЁЖдЦРЎҜpatternЎҜІ»ТФНЁЕд·ыҝӘКјЈ©
ЎЎЎЎ3ЎўГҝёцANDЧйЧчОӘұнҙпКҪЖҘЕдЛчТэЎЈ
ЎЎЎЎSELECT * FROM tbl_name WHERE (str_col1=val1 OR col4 =val4) AND col2=val2;
ЎЎЎЎТтОӘstr_col1=val1 OR col4 =val4ЧчОӘТ»ЧйЈ¬col4І»ЖҘЕдЛчТэЦРөДБРЈ¬ЛщТФІйСҜІ»ЖҘЕдЛчТэЎЈ
ЎЎЎЎ4ЎўИз№ыұнҙпКҪЦРҙжФЪАаРНЧӘ»»»тХЯБРЙПУРёҙФУәҜКэФтУлёГБРІ»ЖҘЕдЛчТэЦРөДБРЎЈ
ЎЎЎЎSELECT * FROM tbl_name WHERE str_col1=1;
ЎЎЎЎSELECT * FROM tbl_name WHERE SUBSTRING(str_col1,1,8) = Ў®titleЎҜ;
ЎЎЎЎөЪ1ёцІйСҜЈ¬ТтОӘ1КЗХыКэЎўstr_col1КЗЧЦ·ыҙ®Ј¬ЛщТФІ»ЖҘЕдЛчТэЈ»өЪ2ёцІйСҜstr_col1УРёҙФУәҜКэЈ¬Н¬СщІ»ЖҘЕдЛчТэЎЈ
ЎЎЎЎЛчТэөДCOST
ЎЎЎЎMysqlИзәОјЖЛгЛчТэөДCOSTЈҝ
ЎЎЎЎЛчТэөДcost»щұҫКЗУЙЎ°№АјЖРиТӘЙЁГиөДРРКэЎұЈЁrowsЈ©АҙИ·¶ЁЎЈКэҫЭАҙФҙУЪinformation_schemaЈ¬ФЪMysqlЖф¶ҜөДКұәт¶БИлДЪҙжЈ¬ФЛРРКұЦ»К№УГДЪҙжЦөЈ¬ҙжҙўТэЗж»б¶ҜМ¬ёьРВХвР©ЦөЎЈ
ЎЎЎЎОТГЗҝЙТФНЁ№эexplainҝҙПВЎ°№АјЖРиТӘЙЁГиөДәҜКэЎұЈ¬ҝЙТФНЁ№эoptimizer_traceІйСҜККУГГҝТ»МхSQLөДҫЯМеөДcostЦөЎЈexplainТІКЗПЯЙПЕЕІйОКМвөДАыЖчЈ¬әуГж»бЦШөгҪйЙЬЎЈ
ЎЎЎЎЛчТэКөАэ·ЦОц
ЎЎЎЎЛчТэөДЧЦ¶Оҫҝҫ№КЗФхГҙҙУwhereУпҫдЦРМбИЎЈ¬Іўұ»MysqlК№УГДШЈ¬ПВГжҪ«ТФТ»ёцКөАэ·ЦОцХвёц№эіМЎЈДЪИЭИ«ОДОӘХӘИЎәОөЗіЙөДОДХВЎ¶SQLЦРөДwhereМхјюЈ¬ФЪКэҫЭҝвЦРМбИЎУлУҰУГЗіОцЎ·Ј¬ІўЧцБЛІҝ·ЦЙҫёДЎЈ
ЎЎЎЎОТГЗҙҙҪЁТ»ХЕІвКФұнЈ¬Т»ёцЛчТэЛчТэЈ¬И»әуІеИлјёМхјЗВјЎЈ(ЧўТвЈәПВГжөДКөАэЈ¬К№УГөДұнөДҪб№№І»КЗInnoDBТэЗжЛщІЙУГөДҫЫҙШЛчТэұнЎЈНјАэҪцОӘЛөГчЈ¬ФӯАнККУГinnodb)
ЎЎЎЎcreate table t1 (a int primary key, b int, c int, d int, e varchar(20));
ЎЎЎЎcreate index idx_t1_bcd on t1(b, c, d);
ЎЎЎЎinsert into t1 values (4,3,1,1,ЎҜdЎҜ);
ЎЎЎЎinsert into t1 values (1,1,1,1,ЎҜaЎҜ);
ЎЎЎЎinsert into t1 values (8,8,8,8,ЎҜhЎҜ):
ЎЎЎЎinsert into t1 values (2,2,2,2,ЎҜbЎҜ);
ЎЎЎЎinsert into t1 values (5,2,3,5,ЎҜeЎҜ);
ЎЎЎЎinsert into t1 values (3,3,2,2,ЎҜcЎҜ);
ЎЎЎЎinsert into t1 values (7,4,5,5,ЎҜgЎҜ);
ЎЎЎЎinsert into t1 values (6,6,4,4,ЎҜfЎҜ);
ЎЎЎЎt1ұнөДҙжҙўҪб№№ИзПВНјЛщКҫ(Ц»»ӯіцБЛidx_t1_bcdЛчТэУлt1ұнҪб№№Ј¬Г»УР°ьАЁt1ұнөДЦчјьЛчТэ)Јә
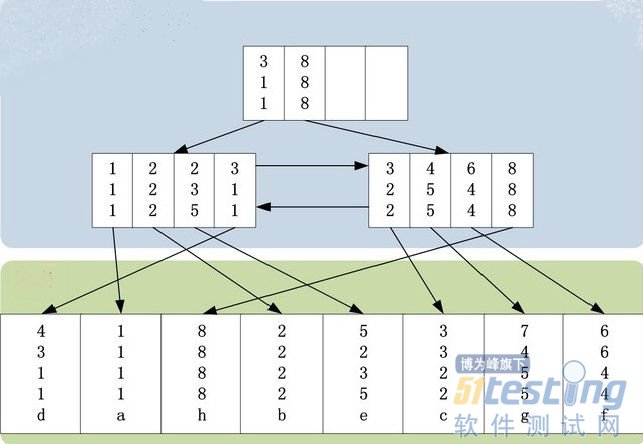
ЎЎЎЎјтөҘЛөГчЙПНјЈ¬idx_t1_bcdЛчТэЙПУР[b,c,d]ИэёцЧЦ¶ОЈ¬І»°ьАЁ[a,e]ЧЦ¶ОЎЈidx_t1_bcdЛчТэЈ¬КЧПИ°ҙХХbЧЦ¶ОЕЕРтЈ¬bЧЦ¶ОПаН¬Ј¬Фт°ҙХХcЧЦ¶ОЕЕРтЈ¬ТФҙЛАаНЖЎЈ
ЎЎЎЎҝјВЗТФПВSQLЈә
ЎЎЎЎselect * from t1 where b >= 2 and b < 8 and c > 1 and d != 4 and e != Ў®aЎҜ;
ЎЎЎЎҝЙТФ·ўПЦwhereМхјюК№УГөҪБЛ[b,c,d,e]ЛДёцЧЦ¶ОЈ¬¶шt1ұнөДidx_t1_bcdЛчТэЈ¬ЗЎәГК№УГБЛ[b,c,d]ХвИэёцЧЦ¶ОЈ¬ДЗГҙЧЯidx_t1_bcdЛчТэҪшРРМхјю№эВЛЈ¬УҰёГКЗТ»ёцІ»ҙнөДСЎФсЎЈ
ЎЎЎЎЛщУРSQLөДwhereМхјюЈ¬ҫщҝЙ№йДЙОӘ3ҙуАаЈәIndex Key (First Key & Last Key)Ј¬Index FilterЈ¬Table FilterЎЈ
ЎЎЎЎҪУПВАҙЈ¬ИГОТГЗАҙПкПё·ЦОцХЯ3ҙуАа·ЦұрКЗИзәО¶ЁТеЈ¬ТФј°ИзәОМбИЎөДЎЈ
ЎЎЎЎl Index Key
ЎЎЎЎУГУЪИ·¶ЁSQLІйСҜФЪЛчТэЦРөДБ¬Рш·¶О§(ЖрКј·¶О§+ҪбКш·¶О§)өДІйСҜМхјюЈ¬ұ»іЖЦ®ОӘIndex KeyЎЈУЙУЪТ»ёц·¶О§Ј¬ЦБЙЩ°ьә¬Т»ёцЖрКјУлТ»ёцЦХЦ№Ј¬Index KeyТІұ»Ір·ЦОӘIndex First KeyәНIndex Last KeyЈ¬·ЦұрУГУЪ¶ЁО»ЛчТэІйХТөДЖрКјЈ¬ТФј°ЛчТэІйСҜөДЦХЦ№МхјюЎЈ
ЎЎЎЎIndex First Key
ЎЎЎЎМбИЎ№жФтЈәҙУЛчТэөДөЪТ»ёцјьЦөҝӘКјЈ¬јмІйЖдФЪwhereМхјюЦРКЗ·сҙжФЪЈ¬ИфҙжФЪІўЗТМхјюКЗ=Ўў>=Ј¬ФтҪ«¶ФУҰөДМхјюјУИлIndex First KeyЦ®ЦРЈ¬јМРш¶БИЎЛчТэөДПВТ»ёцјьЦөЈ¬К№УГН¬СщөДМбИЎ№жФтЈ»ИфҙжФЪІўЗТМхјюКЗ>Ј¬ФтҪ«¶ФУҰөДМхјюјУИлIndex First KeyЦРЈ¬Н¬КұЦХЦ№Index First KeyөДМбИЎЈ»ИфІ»ҙжФЪЈ¬Н¬СщЦХЦ№Index First KeyөДМбИЎЎЈ
ЎЎЎЎХл¶ФЙПГжөДSQLЈ¬УҰУГХвёцМбИЎ№жФтЈ¬МбИЎіцАҙөДIndex First KeyОӘ(b >= 2, c > 1)ЎЈУЙУЪcөДМхјюОӘ >Ј¬МбИЎҪбКшЈ¬І»°ьАЁdЎЈ
ЎЎЎЎIndex Last Key
ЎЎЎЎМбИЎ№жФтЈәҙУЛчТэөДөЪТ»ёцјьЦөҝӘКјЈ¬јмІйЖдФЪwhereМхјюЦРКЗ·сҙжФЪЈ¬ИфҙжФЪІўЗТМхјюКЗ=Ўў<=Ј¬ФтҪ«¶ФУҰМхјюјУИлөҪIndex Last KeyЦРЈ¬јМРшМбИЎЛчТэөДПВТ»ёцјьЦөЈ¬К№УГН¬СщөДМбИЎ№жФтЈ»ИфҙжФЪІўЗТМхјюКЗ < Ј¬ФтҪ«МхјюјУИлөҪIndex Last KeyЦРЈ¬Н¬КұЦХЦ№МбИЎЈ»ИфІ»ҙжФЪЈ¬Н¬СщЦХЦ№Index Last KeyөДМбИЎЎЈ
ЎЎЎЎХл¶ФЙПГжөДSQLЈ¬УҰУГХвёцМбИЎ№жФтЈ¬МбИЎіцАҙөДIndex Last KeyОӘ(b < 8)Ј¬УЙУЪКЗ < ·ыәЕЈ¬ТтҙЛМбИЎbЦ®әуҪбКшЎЈ
ЎЎЎЎ2 Index Filter
ЎЎЎЎФЪНкіЙIndex KeyөДМбИЎЦ®әуЈ¬ОТГЗёщҫЭwhereМхјю№М¶ЁБЛЛчТэөДІйСҜ·¶О§Ј¬ө«КЗҙЛ·¶О§ЦРөДПоЈ¬ІўІ»¶јКЗВъЧгІйСҜМхјюөДПоЎЈФЪЙПГжөДSQLУГАэЦРЈ¬(3,1,1)Ј¬(6,4,4)ҫщКфУЪ·¶О§ЦРЈ¬ө«КЗУЦҫщІ»ВъЧгSQLөДІйСҜМхјюЎЈ
ЎЎЎЎIndex FilterөДМбИЎ№жФтЈәН¬СщҙУЛчТэБРөДөЪТ»БРҝӘКјЈ¬јмІйЖдФЪwhereМхјюЦРКЗ·сҙжФЪЈәИфҙжФЪІўЗТwhereМхјюҪцОӘ =Ј¬ФтМш№эөЪТ»БРјМРшјмІйЛчТэПВТ»БРЈ¬ПВТ»ЛчТэБРІЙИЎУлЛчТэөЪТ»БРН¬СщөДМбИЎ№жФтЈ»ИфwhereМхјюОӘ >=Ўў>Ўў<Ўў<= ЖдЦРөДјёЦЦЈ¬ФтМш№эЛчТэөЪТ»БРЈ¬Ҫ«ЖдУаwhereМхјюЦРЛчТэПа№ШБРИ«ІҝјУИлөҪIndex FilterЦ®ЦРЈ»ИфЛчТэөЪТ»БРөДwhereМхјю°ьә¬ =Ўў>=Ўў>Ўў<Ўў<= Ц®НвөДМхјюЈ¬ФтҪ«ҙЛМхјюТФј°ЖдУаwhereМхјюЦРЛчТэПа№ШБРИ«ІҝјУИлөҪIndex FilterЦ®ЦРЈ»ИфөЪТ»БРІ»°ьә¬ІйСҜМхјюЈ¬ФтҪ«ЛщУРЛчТэПа№ШМхјюҫщјУИлөҪIndex FilterЦ®ЦРЎЈ
ЎЎЎЎХл¶ФЙПГжөДУГАэSQLЈ¬ЛчТэөЪТ»БРЦ»°ьә¬ >=Ўў< БҪёцМхјюЈ¬ТтҙЛөЪТ»БРҝЙМш№эЈ¬Ҫ«УаПВөДcЎўdБҪБРјУИлөҪIndex FilterЦРЎЈТтҙЛ»сөГөДIndex FilterОӘ c > 1 and d != 4 ЎЈ
ЎЎЎЎ3 Table Filter
ЎЎЎЎTable FilterКЗЧојтөҘЈ¬ЧоТЧ¶®Ј¬ТІКЗМбИЎЧоОӘ·ҪұгөДЎЈМбИЎ№жФтЈәЛщУРІ»КфУЪЛчТэБРөДІйСҜМхјюЈ¬ҫщ№йОӘTable FilterЦ®ЦРЎЈ
ЎЎЎЎН¬СщЈ¬Хл¶ФЙПГжөДУГАэSQLЈ¬Table FilterҫНОӘ e != Ў®aЎҜЎЈ
ЎЎЎЎёщҫЭТФЙПКөАэЖдКөҝЙТФЧЬҪбіцТ»Р©№жВЙЈ¬WHEREУпҫдҫҝҫ№ФхСщЈЁКЗ·сЈ©ЖҘЕдЛчТэЈ¬І»УГГФРЕіцЧФЛыИЛЦ®ҝЪөД№жФтЎЈЦ»РиТӘјтөҘөД°ҙХХЛчТэЧФЧуПтУТөДГҝТ»БРЈ¬ҙУWHEREУпҫдМбИЎМхјюЈ¬ДЬ·сҙУЛчТэКчөДёщҪЪөгіц·ўЈ¬өҪҙпЛчТэКчөДТ¶ҪЪөгЈ¬іЙ№ҰЖҘЕдіцТ»ёц»тјёёц·¶О§ЗшјдЈ¬јҙДЬЧФјәЧФРРЕР¶ПКЗ·сДЬК№УГЛчТэЎЈ·ҙ№эАҙЈ¬ЧоЧуЗ°ЧәЖҘЕдЎўLikeІ»ДЬТФНЁЕд·ыҝӘКјЎўAND·ЦЧйЈ¬ТІ¶јКЗУЙB-TreeұҫЙнМШРФҫц¶ЁөДЎЈ
ЎЎЎЎЛчТэОКМвЕЕІй
ЎЎЎЎЗ°ГжОТГЗМёК№УГЛчТэөДcostөДЦөМбөҪ№эexplainЎЈПВГжҪйЙЬexplainөДЦөЈ¬ІўТФТ»ёцКөјКУцөҪөДОКМвЛөГчИзәОЕЕІйОКМвЎЈ
ЎЎЎЎExplainПкҪв
ЎЎЎЎК№УГТ»ёцКҫАэSQLАҙҪвКНexplainЈә
ЎЎЎЎselect id from r_ibeacon_biz_device_d where ftime >= 20151126 and ftime <= 20151126 and biz_id = 11602 limit 50;

ЎЎЎЎIDX_BID_FTIMEКЗұнr_ibeacon_biz_device_dөДЖдЦРТ»МхЛчТэЎЈ
ЎЎЎЎBiz_id,ftimeҫщОӘbigintАаРНЎЈ
ЎЎЎЎОТГЗЧЕЦШ№ШЧўјёёцЦШөгЧЦ¶ОөДЦШөгЦөЈә
ЎЎЎЎ- type:ЛчТэөДК№УГ·ҪКҪ
ЎЎЎЎeq_ref Ўӯ ЛчТэ,№ШБӘЖҘЕдИфёЙРР
ЎЎЎЎref Ўӯ ЛчТэ(З°Чә)ЖҘЕд
ЎЎЎЎrange Ўӯ ЛчТэ·¶О§ЙЁ(BETWEENЎўINЎў>=ЎўLIKE)өГөҪКэҫЭ
ЎЎЎЎindex Ўӯ ЛчТэИ«ЙЁГи
ЎЎЎЎall Ўӯ ұнИ«ЙЁГи
ЎЎЎЎКҫАэЦРК№УГөДЛчТэКЗК№УГИ«ЛчТэ·¶О§ЙЁГиЈ¬ЛщТФtypeОӘrange
ЎЎЎЎ- possible_keysЈәККУГІйСҜөДЛчТэБРұнЎЈКҫАэЦРУРИэМхЛчТэККУГұҫҙОІйСҜЎЈ
ЎЎЎЎ- key: ІйСҜКөјКЦҙРРК№УГөДЛчТэЎЈКҫАэК№УГөДОӘIDX_BID_FTIME
ЎЎЎЎ- key_lenЈәІйСҜК№УГЛчТэөДіӨ¶ИЎЈ
ЎЎЎЎnull 1ЧЦҪЪ
ЎЎЎЎtinyint 1ЧЦҪЪ
ЎЎЎЎint 4ЧЦҪЪ
ЎЎЎЎbigint 8ЧЦҪЪ
ЎЎЎЎdouble 8ЧЦҪЪ
ЎЎЎЎdatetime 8ЧЦҪЪ
ЎЎЎЎtimestamp 4ЧЦҪЪ
ЎЎЎЎvarchr(10)ұдіӨЧЦ¶ОЗТФКРнNULL: 10*(Character SetЈәutf8=3,gbk=2,latin1=1)+1(NULL)+2(ұдіӨЧЦ¶О)
ЎЎЎЎchar(10)№М¶ЁЧЦ¶ОЗТФКРнNULL: 10*(Character SetЈәutf8=3,gbk=2,latin1=1)+1(NULL)
ЎЎЎЎТФЙПКЗіЈУГАаРНөДіӨ¶ИЈ¬КҫАэЦРkey_lenОӘ18Ј¬јҙЈә8ЧЦҪЪ(biz_id bigint)+1ЧЦҪЪ(biz_idФКРнОӘnull)+8ЧЦҪЪ(ftimebigint)+1ЧЦҪЪ(ftimeФКРнОӘnull)ЎЈЛщТФұҫҙОІйСҜКЗК№УГБЛЛчТэөДЛщУРЧЦ¶ОјУЛЩІйСҜ
ЎЎЎЎ- rowsЈәІйСҜФӨ№АЙЁГиөДРРКэ
ЎЎЎЎExplainёъҪшОКМв
ЎЎЎЎТЎТ»ТЎЦЬұЯәуМЁөДКэҫЭНіјЖҪУҝЪ¶ы»бУРРЎјв·еЈ¬Йжј°БЛТ»МхSQLЈә
ЎЎЎЎТ»МхSQLёг¶ЁҝЁ·ҪјмСйјЖЛгselect d.id from r_ibeacon_biz_page_d d where d.ftime >= 20151126 and d.ftime <= 20151126 and d.biz_id = 11023 and d.page_id = 778495 limit 0,20Ј»
ЎЎЎЎұнr_ibeacon_biz_page_d өДЦчТӘЧЦ¶ОРЕПўИзПВЈә
ЎЎЎЎftime bigint(20)
ЎЎЎЎbiz_id bigint(20)
ЎЎЎЎpage_id varchar(200)
ЎЎЎЎЛчТэОӘЈәIDX_BID_PID_FTIME
ЎЎЎЎExplainҪб№ыИзПВ

ЎЎЎЎ№ЫІмТФЙПexplainҪб№ыҝЙТФҝҙөҪТ»ЗРХэіЈЈ¬SQLЎ°·ыәПФӨЖЪЎұөДЧЯБЛЛчТэЎЈө«КЗrowsЙФОў¶аБЛөгЈ¬ө«КЗҝҙЖрАҙТІЎ°әГПсЎұokЎЈө«КЗОКМвҫНКЗіцПЦјв·еЎЈ
ЎЎЎЎОКМвЕЕІйЈә
ЎЎЎЎКЧПИЈ¬ЧўТвөҪөДТ»өгҫНКЗexplainЦРөДtypeТміЈЈ¬КЗrefЎЈ°ҙХХЙПГжөДҪвКНЈ¬Из№ыЧЯБЛЛчТэДЗУҰёГКЗrangeАаРНІЕ¶Ф°ЎЎЈ
ЎЎЎЎЖдҙОЈ¬№ЫІмkey_lenЈ¬9Ј¬·ўПЦИ·КөУРР©І»¶ФЈ¬ФхГҙ»бХвГҙРЎЎЈ°ҙХХАаРНЛщХјЧЦҪЪЈ¬9ёХәГОӘbiz_idөДіӨ¶ИЈ¬И·¶ЁХвМхSQLЛдИ»ЧЯБЛЛчТэЈ¬ө«КЗЦ»К№УГБЛbiz_idЧЦ¶ОЎЈФӯТтДШЈҝ
ЎЎЎЎИ»әуЦҙРРЎ°desc r_ibeacon_biz_page_dЎұЈ¬ІйҝҙұнҪб№№өДЛчТэЧЦ¶ОЈ¬Н»И»·ўПЦpage_idөДАаРНФхГҙКЗvarcharЈ¬ФЩҝҙSQLЦРpage_id=11023ЎЈН»И»ТвК¶өҪБЛКІГҙЈ¬ҙЛКұёХәГОҘ·ҙЛчТэЖҘЕдөДөЪЛДМх№жФтЎЈёьёДSQLЎ°page_id=11023ЎұОӘЎ°page_id=Ў®11023ЎҜЎұСйЦӨЈ¬ИзПВ

ЎЎЎЎҝЙТФҝҙөҪtype=rangeЎўkey_len=621Ј¬·ыәПФӨЖЪЎЈҪУПВАҙТӘЧцөДҫНКЗёьёДұнЦРpage_idөДАаРНОӘbigintЎЈёфМмФЩҝҙҪУҝЪөДјв·е№ыИ»ПчЖҪЎЈ
ЎЎЎЎExplainКЗТ»ёцәЬәГөД№ӨҫЯЈ¬ҝЙТФУГАҙСйЦӨSQLКЗ·сК№УГБЛЛчТэЈ¬ёьЦШТӘөДКЗСйЦӨSQLКЗ·сИзФӨЖЪөДК№УГЛчТэЙПЎЈЕЕІйПЯЙПОКМв»№УРprofileәНoptimizer_traceЈ¬УЙУЪКөјКГ»УРМ«¶аУГөҪФЭЗТІ»ұнЎЈ
ЎЎЎЎіЈјыОКМв»гЧЬ
ЎЎЎЎ- RangeФхГҙК№УГЛчТэЈҝ
ЎЎЎЎПкјыЙПОД
ЎЎЎЎ- Order byК№УГЛчТэВрЈҝ
ЎЎЎЎёГОКМвҝЙТФУЙТФПВЧКБПҪвКНЈә
ЎЎЎЎSQL queries with an order by clause donЎҜt need to sort the result explicitly if the relevant index already delivers the rows in the required order. That means the same index that is used for the where clause must also cover the order by clause.
ЎЎЎЎЧЬЦ®Т»ҫд»°ЈәЛчТэұҫЙнІўІ»ДЬұЬГвЕЕРтЈ¬өұёщҫЭЛчТэИЎіцөДКэҫЭТСҫӯВъЧгorder byЧУҫдөДТӘЗуҫНҝЙТФұЬГвЕЕРтІЩЧчЎЈ
ЎЎЎЎ- order byМ«ВэЈҝ
ЎЎЎЎұЬГвКэҫЭЕЕРтЈ¬ІЙУГЛчТэЕЕРт(·ЦТіІйСҜОДТХРҙ·Ё)
ЎЎЎЎ- limit offsetМ«ВэЈҝ
ЎЎЎЎұЬГвҙуoffsetЈ¬К№УГwhereУпҫд№эВЛёь¶аөДРРЎЈёь¶аІОҝјөДКөјщЎ¶Efficient Pagination Using MySQLЎ·
ЎЎЎЎ- ОӘКІГҙІ»ЧЯЛчТэЈЁЛчТэТІЧЯБЛЈ¬»№КЗВэЈ©Јҝ
ЎЎЎЎАаРНКЗ·сТ»ЦВ: int vs charЈЁvarcharЈ©ЎўvarcharЈЁ32Ј©vs varchar(64)
ЎЎЎЎЧЦ·ыјҜКЗ·сТ»ЦВЈәЙжј°ұн№ШБӘКұЈ¬БҪұнЧЦ·ыјҜКЗ·сТ»ЦВЎЈ












