

MySQL本身也做了一些努力,那就是基于Paxos协议的MGR。但它没有Sharding的解决方案,需要借助其他中间件。
这样的DB已经有很多,其中,以Aurora为代表的云数据库进入视野。根据其流行度,仅对PorlarDB和TiDB进行了调研。
其他产品,包括但不限于:
Greenplum Druid Aurora Taurus Spanner NuoDB Oracle Exadata Oracle RAC |
如果你时间有限,直接看初步结论即可。下面的内容可以忽略。
初步结论
它们都支持MySQL协议,现有业务迁移起来会比较平滑,但对硬件的要求都较高。部分一致性都有Raft协议的参与,可靠性都有保证。
TiDB是开源的,某些组件强制要求SSD,且需配备DBA,造成了整体成本的上升。但是使用案例较多,经历过较大规模的应用。
PolarDB。阿里新的明星产品,价格相对合理,但使用案例有限,也无法窥视其源码,只有零星宣传文档。鉴于阿里喜好夸大的尿性,需试用后进行深入评价。但云端优势太明显,已被优先考虑。
通过咨询已有经验的实践者,普遍吐槽会遇到很多奇怪的问题,并不像宣传中的那么美好。
以下。
TiDB
一、简介
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。
特性
TiDB 具备如下特性:
高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
分布式事务
TiDB 100% 支持标准的 ACID 事务。
真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
一站式 HTAP 解决方案
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
云原生 SQL 数据库
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
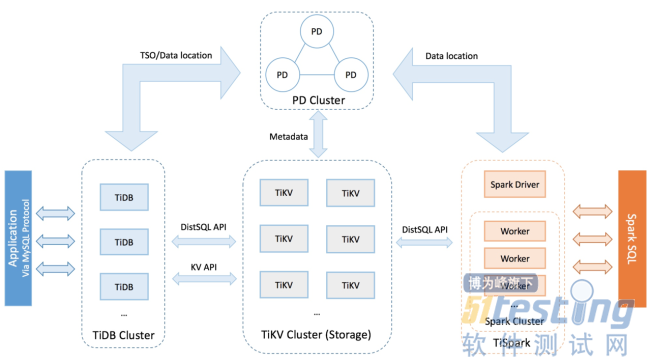
二、整体架构图
三、兼容性(不支持特性列表)
四、FAQ
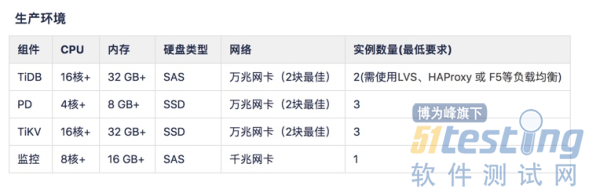
五、硬件需求
TiDB:解析,处理sql逻辑,通过PD获取数据地址,访问TiKV捞数据,返回结果(需负载均衡,高耗u,高内存,高网络)
PD:集群管理,存储元数据信息,tikv负载均衡,分配全局事务id
TiKV:分布式且提供事务的 Key-Value 存储引擎。(高耗u,高内存,高网络,高硬盘)
PD节点=3794*3 = 11382 TiKV节点=30049*3 = 59547 (500G SSD) 监控节点=7446 合计:107873 |
六、其他问题
1、 对硬盘要求高,启动会检测硬盘是否为SSD,若否无法启动
2、 不支持分区,删除数据是个大坑。(3.0支持)
解决方案:
| set @@session.tidb_batch_delete=1; |
3、 批量插数据问题
解决方案:
| set @@session.tidb_batch_insert=1; |
4、 删除表数据时不支持别名
delete from 表名 表别名 where 表别名.col = '1' 会报错
5、 内存使用问题,GO语言导致不知道回收机制什么时候运作。内存使用过多会导致TIDB当机(这点完全不像MYSQL)测试情况是,32G内存,在10分钟后才回收一半。
6、 数据写入的时候,tidb压力很大, tikv的CPU也占用很高
7、 不支持GBK
8、 不支持存储过程
9、 列数支持太少,只支持100列
polardb
一、简介、成本
POLARDB是阿里巴巴自主研发的下一代关系型分布式云原生数据库,目前兼容三种数据库引擎:MySQL、Oracle、PostgreSQL。计算能力最高可扩展至1000核以上,存储容量最高可达 100T。POLARDB采用存储和计算分离的架构,所有计算节点共享一份数据,提供分钟级的配置升降级、秒级的故障恢复、全局数据一致性和免费的数据备份容灾服务。POLARDB既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、自我迭代的优势,例如POLARDB for MySQL性能最高可以提升至MySQL的6倍,而成本只有商用数据库的1/10
二、集群架构,计算与存储分离
POLARDB采用多节点集群的架构,集群中有一个Writer节点(主节点)和多个Reader节点(读节点),各节点通过分布式文件系统(PolarFileSystem)共享底层的存储(PolarStore)。
三、读写分离
应用程序使用集群地址时,POLARDB for MySQL通过内部的代理层(Proxy)对外提供服务,应用程序的请求都先经过代理,然后才访问到数据库节点。代理层不仅可以做安全认证和保护,还可以解析SQL,把写操作(比如事务、UPDATE、INSERT、DELETE、DDL等)发送到主节点,把读操作(比如SELECT)均衡地分发到多个只读节点,实现自动的读写分离。对于应用程序来说,就像使用一个单点的MySQL数据库一样简单。内部的代理层(Proxy)后续将支持POLARDB for PostgreSQL/Oracle。
四、产品优势
容量大
最高100TB,您不再需要因为单机容量的天花板而去购买多个实例做分片,由此简化应用开发,降低运维负担。
高性价比
POLARDB的计算与存储分离,每增加一个只读节点只收取计算资源的费用,而传统的只读节点同时包含计算和存储资源,每增加一个只读节点需要支付相应的存储费用。
分钟级弹性
存储与计算分离的架构,配合共享存储,使得快速升级成为现实。
读一致性
集群地址利用LSN(Log Sequence Number)确保读取数据时的全局一致性,避免因为主备延迟引起的不一致。
毫秒级延迟(物理复制)
利用基于Redo的物理复制代替基于Binlog的逻辑复制,提升主备复制的效率和稳定性。即使对大表进行加索引、加字段等DDL操作,也不会造成数据库的延迟。
无锁备份
利用存储层的快照,可以在60秒内完成对2TB数据量大小的数据库的备份,而且备份过程不会对数据库加锁,对应用程序几乎无影响,全天24小时均可进行备份。
复杂SQL查询加速
内置并行查询引擎,对执行时长超过1分钟的复杂分析类SQL加速效果明显。本功能需要使用额外的连接地址。
五、架构
云数据库POLARDB基于Cloud Native设计理念,其架构示意图及特点如下:
一写多读
POLARDB采用分布式集群架构,一个集群包含一个主节点和最多15个只读节点(至少一个,用于保障高可用)。主节点处理读写请求,只读节点仅处理读请求。主节点和只读节点之间采用Active-Active的Failover方式,提供数据库的高可用服务。
计算与存储分离
POLARDB采用计算与存储分离的设计理念,满足公共云计算环境下用户业务弹性扩展的刚性需求。数据库的计算节点(DB Server)仅存储元数据,而将数据文件、Redo Log等存储于远端的存储节点(Chunk Server)。各计算节点之间仅需同步Redo Log相关的元数据信息,极大降低了主节点和只读节点间的延迟,而且在主节点故障时,只读节点可以快速切换为主节点。
读写分离
读写分离是POLARDB for MySQL集群默认免费提供的一个透明、高可用、自适应的负载均衡能力。通过集群地址,SQL请求自动转发到POLARDB集群的各个节点,提供聚合、高吞吐的并发SQL处理能力。具体请参见读写分离。
高速链路互联
数据库的计算节点和存储节点之间采用高速网络互联,并通过RDMA协议进行数据传输,使I/O性能不再成为瓶颈。
RDMA是一种远端内存直接访问技术,相当于传统的socket协议软硬件架构相比较,高速,超低延时,极低的CPU使用率的RDMA主导了RDMA的高速发展。
共享分布式存储
多个计算节点共享一份数据,而不是每个计算节点都存储一份数据,极大降低了用户的存储成本。基于全新打造的分布式块设备和文件系统,存储容量可以在线平滑扩展,不会受到单机服务器配置的影响,可应对上百TB级别的数据规模。
数据多副本、Parallel-Raft协议
数据库存储节点的数据采用多副本形式,确保数据的可靠性,并通过Parallel-Raft协议保证数据的一致性。
六、18年进化
此前,POLARDB核心卖点是100%向下兼容MySQL 5.6,100TB存储容量,性能是官方MySQL的6倍,跑分超越AWS Aurora。
在写性能方面,再度提升近2倍,去年13万QPS,今年达到了25万QPS;POLARDB还支持多达16个节点,其聚合读性能超过1000万QPS;在相同测试流程下,POLARDB写性能比AWS Aurora快了近两倍;
在读写分离方面,提供了会话一致性的读写分离支持。虽然读写分写是常用技术,但通常读节点会有一定程度的延迟问题,对此,POLARDB新增了智能网关技术,用户可以在主节点上完成写,再从分节点实现读,满足了用户的读写一致性的需求。
SQL加速能力,通过使用MPP技术,能够让一条SQL同时在16个节点上执行,从而把一条复杂SQL的查询时间缩短了8-20倍。
在数据库稳定性上,POLARDB是目前全球唯一一家在生产环节大规模使用Optane技术的云服务商,3D XPoint技术能像写内存一样,从物理上消除QOS抖动,数据库跑起来写请求会更平稳。
End
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












