

Lambda Architecture 概念
Mathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介绍了Lambda Architecture的概念,用于在大数据架构中,如何让real-time与batch job更好地结合起来,以达成对大数据的实时处理。
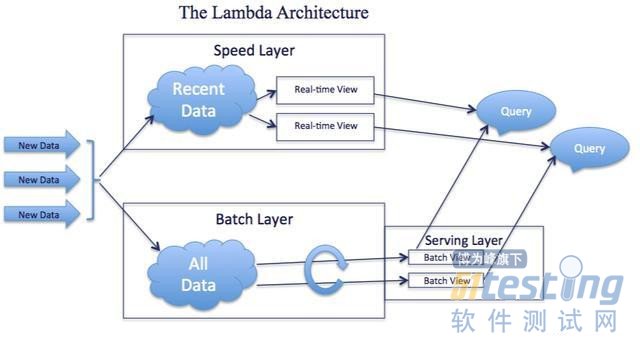
大数据平台中包括批量计算的Batch Layer和实时计算的Speed Layer,通过在一套平台中将批计算和流计算整合在一起。
例如使用Hadoop MapReduce、Spark进行批量数据的处理,使用Apache Storm、Spark Streaming 进行实时数据的处理。
这种架构在一定程度上解决了不同计算类型的问题,但是带来的问题是框架太多,会导致平台复杂度过高、运维成功高等。
Lambda架构的主要思想就是将大数据系统构建为多个层次,如下图所示:
我们来梳理一下他们是如何分工协助的:
首先new data作为整个数据系统的数据源头,Batch Layer作为数据的批处理层次对原始数据进行加工与处理,并且将处理的数据结果的Batch View输入到Serving Layer。(这里对应的是全量数据)
Speed Layer对于实时增加的数据进行处理,生成对增量数据计算结果的Real-time View。(这里对应的是增量数据)
最终用户查询是通过Batch View与Real-time View相结合的形式将最终结果呈现出来。
基于Lambda架构,一旦数据通过Batch layer进入到Serving layer,在Real-time view中的相应结果就不再需要了。
小 结
Lambda架构结合了实时处理与批处理的结果,很好的反馈了查询需求,并且在速度和可靠性之间求取了平衡,具有足够的扩展性。理想状态下,所有的查询都可以定位成一个函数:
| Query = Function(Data) |
但是,若数据达到相当大的一个级别(例如PB),且还需要支持实时查询时,就需要耗费非常庞大的资源。
而Lambda架构将数据和计算系统进行细分:
| Query = Batch(Old_Data) + RealTime(New_Data) |
但是这种架构同样存在一些问题:需要运维两套不同的计算系统,并且合并查询结果,这一定程序上带来了复杂性的增加。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












