

第7章 大数据工具实践
大数据类项目测试验证功能点繁琐,不仅需要关注数据ETL过程流转的正确性,还需要关注ETL过程中数据的质量问题。ETL过程依赖任务调度工具,ETL过程中产生的数据依赖数据质量监控工具,ETL测试依赖集成的大数据测试工具。由此可见,为提高测试效率及保证数据的准确性,从数据生产到业务应用的整个过程都离不开工具平台的支撑。本章将结合我们的项目实践经验,对大数据ETL测试相关的3个工具平台做概要分析。
7.1 大数据测试工具
数据对于任何一个企业来说都是非常重要的,为了保证数据ETL过程的质量及效率,很多公司引入了ETL工具。目前业界ETL工具有很多,几乎所有的巨头软件供应商都推出了自己的ETL工具,另外也有一些开源的ETL工具。常见的ETL工具,主要有以下几款:
1) Datastage:一套专门针对多种源数据处理的集成工具。通过自动化过程将源数据抽取、转换后,输入到数据仓库。
2) Informatica:用于访问和集成几乎任何业务系统、任何格式的数据。数据交付高效,具有高性能、高可扩展性、高可用性的特点。
4) Talend Data Integration:一个软件集成平台,为数据集成、数据质量保障、数据管理和数据准备提供解决方案。它只有ETL 的作用,所有插件都可以轻松地与大数据生态系统集成。但是它的使用门槛相对较高,对使用的人员的相关技能要求很高。
除此之外,还有Datameer、Clover ETL、Cognos Data Manager、Data Integrator、Data Integration Studio,不再一一详细介绍。
ETL工具虽多,但是针对ETL测试的测试工具在业界却比较少见。为解决公司日常大数据测试中遇到的痛点问题,我们结合实际业务背景需求,开发了一款大数据测试工具 easy_data_test。
7.1.1 大数据测试的痛点
在日常ETL测试过程中会遇到很多问题,主要是Hive SQL类测试的问题,如下:
1) 测试以手动测试为主,缺少自动化工具。
2) 缺少数据质量相关的分析工具。
3) 测试中需要重复编写查询类SQL语句,效率较低。
4) SQL查询耗时太长,严重拖慢测试进度。
5) Shell窗口查询结果不易保存、HUE的查询结果易过期且需要手动操作保存。
6) 数据同步场景及ETL场景下,需要对比源表目标表一致性,缺少对比工具。
7) 实时数据处理场景对数据时效性要求高,测试时场景难以模拟,问题复现困难。
8) 常用测试场景用例编写重复,比如对拉链表测试,MR脚本测试缺少通用的测试覆盖用例。
9) 缺少Hive&HBase一致性对比工具[ HBase与Hive一致性对比背景:在金融风控业务中会存在离线和在线场景。通常,离线数据存储在Hive中,在线数据或特征存储在HBase中,在线和离线共用一套特征计算代码。为了保证模型在线上效果不衰减,与离线训练效果一致,在线离线需要保证数据的一致性。这样相同样本关联得到相同的在线离线数据,再使用一套共用的特征计算代码才能计算生成一致的特征。特征输入进相同的模型,才会得到相同的决策结果。]。
总的来说,大数据测试存在门槛高,测试效率较低,测试覆盖不全,测试场景不易复现,测试问题难以定位等问题。
7.1.2 大数据测试工具设计
1.模块设计
easy_data_test模块设计图如图7-1所示:
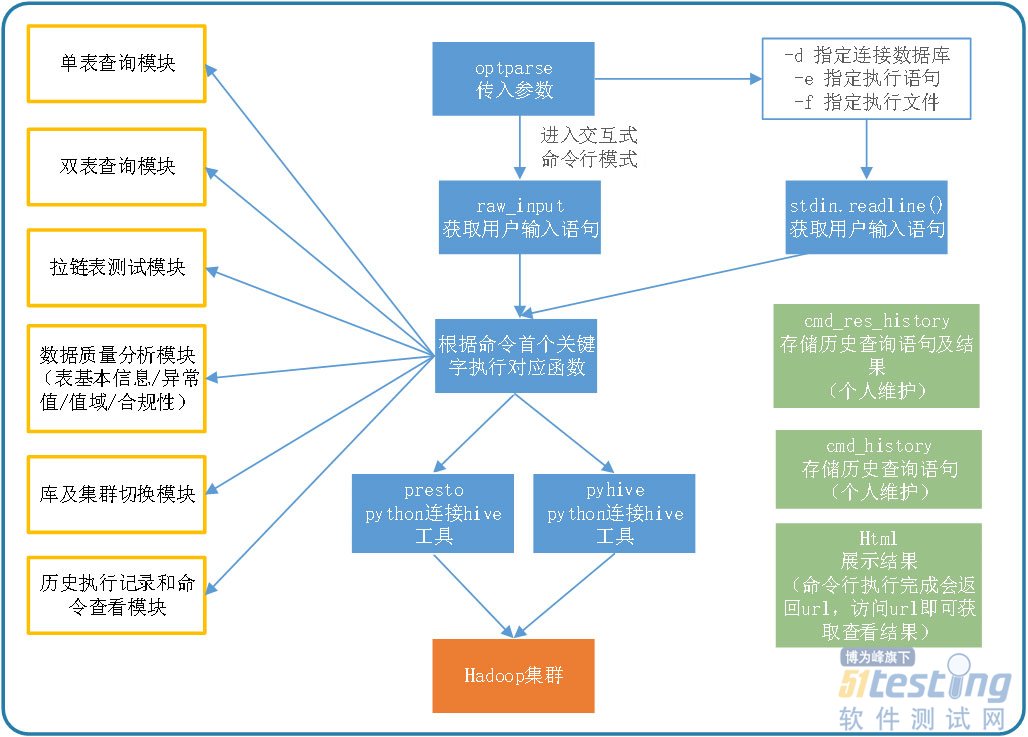
图7-1 easy_data_test模块设计图
用户运行easy_data_test工具后,可以通过“./easy_data_test --help”查看所有非交互式命令,使用stdin.readline()来获取用户输入的语句。如果没有指定-f或者-e就会进入交互式命令行模式。进入交互式模式后,程序通过raw_input函数获取用户输入的命令,并根据命令的首个关键字执行对应的函数。函数中封装了一个或多个SQL语句,通过Presto或者pyHive连接Hive执行。部分执行结果展示在终端页面并存储在查询历史命令及结果文件中。部分命令执行完毕后会生成url,通过浏览器可以查看相应命令的执行结果。由图7-1可以看出,不同的首个关键字对应不同的功能模块,通常每个功能模块包含多个执行函数。
版权声明:51Testing软件测试网获得人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。












