

字节跳动数据链路介绍
为了明确问题的讨论范围,我们首先介绍一下字节的数据链路。

字节的数据的来源分为两种:
·端数据:APP 和 Web 端通过埋点 SDK 发送的,经过 LogService,最终落入 MQ;
· 业务数据:APP,Web 和第三方服务所进行的业务操作,通过各种应用的服务,最终落入 RDS,RDS 中的数据,经过 Binlog 的方式,汇入 MQ;
MQ 中的数据,在 MQ 之间有分流的过程,做转换格式,流量拆分等。
离线数仓的核心是 Hive,数据通过各种手段最终汇入其中,使用主流的 HiveSQL 或 SparkJob 做业务处理,流入下游 Clickhouse 等其他存储。
实时数仓的核心是 MQ,使用主流的 FlinkSQL 或通用 FlinkJob 做处理,期间与各种存储做 SideJoin 丰富数据,最终写入各种存储。
典型的数据出口有三类:
· 指标系统:业务属性强烈的一组数据,比如“抖音日活”
· 报表系统:以可视化的形式,各种维度展示加工前或加工后的数据
· 数据服务:以 API 调用的形式进一步加工和获取数据
在字节,数据血缘的系统边界是:从 RDS 和 MQ 开始,一路途径各种计算和存储,最终汇入指标、报表和数据服务系统。
血缘的应用场景
在讨论技术细节之前,需要先讲清楚血缘的应用场景与业务价值,进一步明确数据血缘需要解决的问题。不同的应用场景,对于血缘数据的消费方式,血缘的覆盖范围,血缘的质量诉求,都会有所差别。


数据血缘系统的整体设计
01 - 概览
通过对字节血缘链路和应用场景的讨论,可以总结出血缘整体设计时需要考虑的两个关键点:
可扩展性:在字节,业务复杂而庞大,整条数据链路中,使用到的各种存储有几十种,细分的任务类型也是几十种,血缘系统需要可以灵活的支持各种存储和任务类型。
开放的集成方式:消费血缘时,有实时查询的场景,也有离线消费的场景,还有可能下游系统会基于当前数据做扩展。
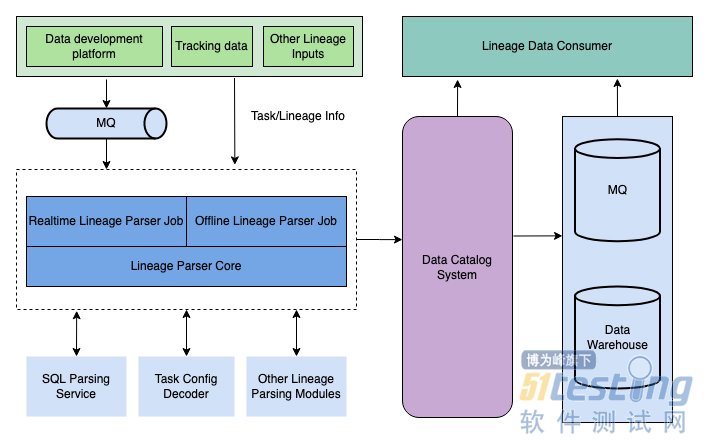
字节数据血缘系统的整体架构可以分为三部分:
· 任务接入:以某种方式,从任务管理系统中获取任务信息。
· 血缘解析:通过解析任务中的信息,获取到血缘数据。
· 数据导出:负责将血缘数据存储到 Data Catalog 系统中,并供下游系统消费。
02 - 任务接入
有两个关键的设计考虑:
提供两种可选的链路,以应对不同下游系统对于数据实时性的不同要求:
· 近实时链路:任务管理系统将任务的修改的消息写入 MQ,供血缘模块消费。
· 离线链路:血缘模块周期性的调用任务管理系统的 API 接口,拉取全量(或增量)任务信息,进行处理。
定义统一的 Task 模型,并通过 TaskType 来区分不同类型任务,确保后续处理的可扩展性:
· 不同任务管理系统,可能管理相同类型的任务,比如都支持 FlinkSQL 类型的任务;同一任务管理系统,有时会支持不同类型的任务,比如同时支持编写 FlinkSQL 和 HiveSQL。
· 新增任务管理系统或者任务类型,可以添加 TaskType。
03 - 血缘解析
有两个关键的设计考虑:
定义统一的血缘数据模型 LineageInfo
针对不同的 TaskType,灵活定制不同的解析实现,也支持不同 TaskType 可服用的兜底解析策略。比如:
· SQL 类任务:比如 HiveSQL 与 FlinkSQL,会调用 SQL 类的解析服务。
· Data Transfer Service(DTS)类:解析任务中的配置,建立源与目标之间的血缘关系。
· 其他类任务:比如一些通用任务会登记依赖和产出,报表类系统的控制面会提供报表来源的库表信息等。
04 - 数据导出
血缘解析所产出的 LineageInfo,会首先送入 DataCatalog 系统,支持三种集成方式:
· 对于 Data Catalog 中血缘相关 API 调用,实时拉取需要的血缘数据。
· 消费 MQ 中的血缘修改增量消息,以近实时能力构造其他周边系统。
· 消费数仓中的离线血缘导出数据,做分析梳理等业务。
血缘的数据模型
血缘数据模型的定义,是确保系统可扩展性和方便下游消费集成的关键设计之一。
-概览
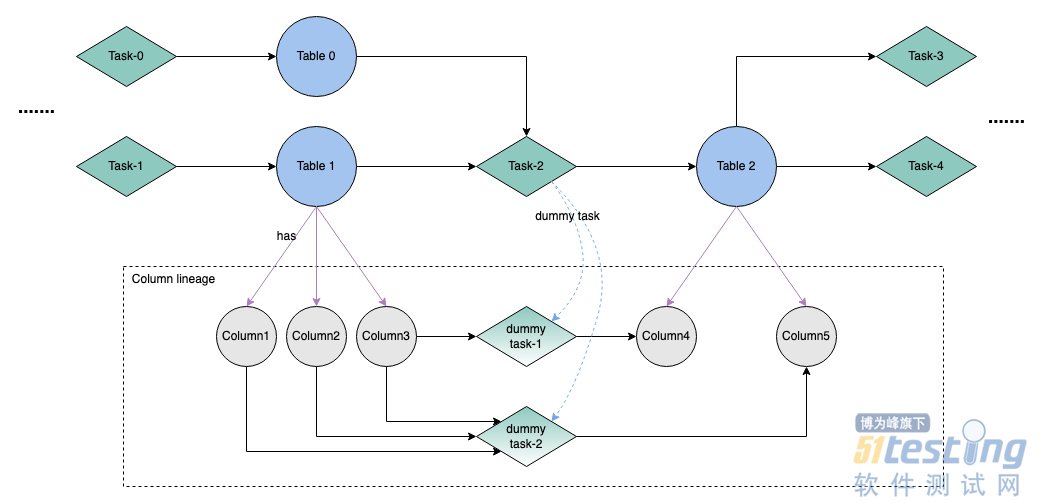
我们以图的数据模型来建模整套血缘系统。图中包含两类节点和两类边:
· 数据节点:对于存储数据的介质的抽象,比如一张 Hive 表,或者是 Hive 表的一列。
· 任务节点:对于任务(或链路)的抽象,比如一个 HiveSQL 脚本。
· 从数据节点指向任务节点的边:代表一种消费关系,任务读取了这个数据节点的数据。
· 从任务节点指向数据节点的边:代表一种生产关系,任务生产了这个数据节点的数据。
将任务节点和数据节点统一到一张图上的 2 点优势:
· 将血缘的生命周期与任务的生命周期统一,通过更新任务关联的边来更新血缘关系。
· 可以灵活的支持从任务切入和从数据节点切入的不同场景。比如数据资产领域从数据节点切入的居多,而数据开发领域从任务切入的场景居多,不同的应用场景可以在一张大图上灵活遍历。
字段(Column)级血缘
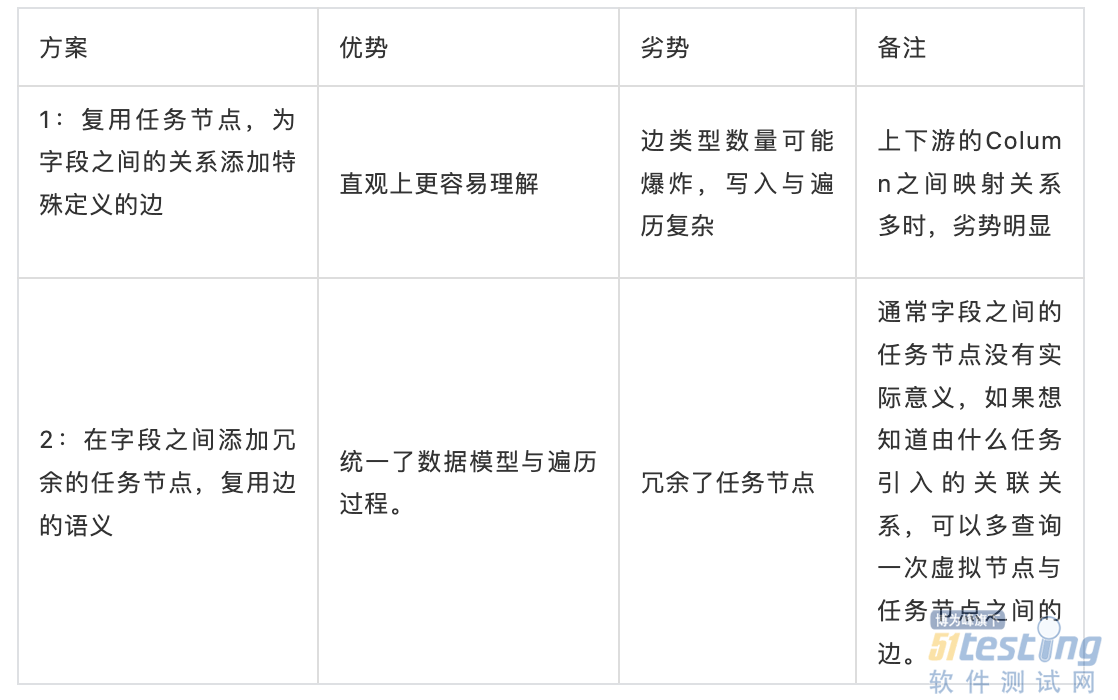
字段血缘是血缘模型中的边界情况,单独拿出来简单讨论。在实现时,有两种可供选择的思路:
我们最终采用了第 2 种方案。
血缘衡量指标
实际推广血缘时,最常被用户问到的问题就是,血缘质量怎么样,他们的场景能不能用。面对这种灵魂拷问,每个用户都单独评估一遍的开销过大,所以我们花了很多精力讨论探索出了最常用的三个技术指标,以佐证血缘质量。用户可以根据这些指标,判断自己的场景是否适用。
01 - 准确率
定义:假设一个任务实际的输入和产出与血缘中该任务的上游和下游相符,既不缺失也不多余,则认为这个任务的血缘是准确的,血缘准确的任务占全量任务的比例即为血缘准确率。
准确率是用户最关注的指标,像数据开发的影响分析场景,血缘的缺失有可能会造成重要任务没有被通知,造成线上事故。
不同类型的任务,血缘解析的逻辑不同,计算准确率的逻辑也有区别:
SQL 类任务:比如 HiveSQL 和 FlinkSQL 任务,血缘来源于 SQL 的解析,当 SQL 解析服务给出的质量保证是,成功解析的 SQL 任务,产生的血缘关系就一定是准确的,那么这类任务的血缘准确率,就可以转化成 SQL 解析的成功率。
数据集成(DTS)类任务:比如 MySQL->Hive 这类通道任务,血缘来源于对用户登记上下游映射关系的配置,这类血缘的准确率,可以转化成对于任务配置解析的成功率。
脚本类任务:比如 shell,python 任务等,这些血缘来源于用户登记的任务产出,这类血缘的准确率,可以转化成登记产出中正确的比例。
注意一个问题,上面所讲的准确率计算,转化的时候都有一个前提假设,是程序按照我们假定的方式运行,实际情况并不一定总是这样。其实这件事情没必要特别纠结,血缘就像我们在运行的其他程序一样,都可能因程序 bug,环境配置,边界输入等,产生不符合预期的结果。
作为准确率的补充,我们在实践中通过三种途径,尽早发现有问题的血缘:
人工校验:通过构造测试用例来验证其他系统一样,血缘的准确性问题也可以通过构造用例来验证。实际操作时,我们会从线上运行的任务中采样出一部分,人工校验解析结果是否正确,有必要的时候,会 mock 掉输出,持续运行校验。
埋点数据验证:字节中的部分存储会产生访问埋点数据,通过清洗这些埋点数据,可以分析出部分场景的血缘链路,以此来校验程序中血缘产出的正确性。比如,HDFS 的埋点数据可以用来校验很多 Hive 相关链路的血缘产出。
用户反馈:全量血缘集合的准确性验证是个浩瀚的过程,但是具体到某个用户的某个业务场景,问题就简化多了。实际操作中,我们会与一些业务方深入的合作,一起校验血缘准确性,并修复问题。
02 - 覆盖率
定义:当至少有一条血缘链路与资产相关时,称为资产被血缘覆盖到了。被血缘覆盖到的资产占关注资产的比例即为血缘覆盖率。
血缘覆盖率是比较粗粒度的指标。作为准确率的补充,用户通过覆盖率可以知道当前已经支持的资产类型和任务类型,以及每种覆盖的范围。
在内部,我们定义覆盖率指标的目的有两个,一是圈定出我们比较关注的资产集合,二是寻找系统中缺失的整块的任务类型。
以 Hive 表为例,字节生产环境的 Hive 表已经达到了几十万级别,其中有很大一部分,是不会被长期使用与关注的。计算血缘覆盖率时,我们会根据规则圈选出其中的部分,比如,过去 7 天有数据写入的,作为分母,在这之上,看血缘覆盖率是多少。
当血缘覆盖率低时,通常说明我们漏掉了某种任务类型或者圈选的资产范围不合理。举个例子,在初期时,我们发现 MQ 的血缘覆盖率只有个位数,分析后发现,我们漏掉了以另外一种格式定义的流式数据集成任务。
03 - 时效性
定义:从任务发生修改,到最终反应到血缘存储系统的端到端延时。
对于一些用户场景来说,血缘的时效性并没有特别重要,属于加分项,但是有一些场景是强依赖。不同任务类型的时效性会有差异。
数据开发领域的影响分析场景,是对血缘实时性要求很高的场景之一。用户在圈定修改的影响范围时,如果只能拉取到昨天为止的状态,是会产生严重业务事故的。
提升时效性的瓶颈,通常不在血缘服务方,而是任务管理系统是否可以近实时的将任务相关的修改,以通知形式发送出来。
未来
文中阐述的部分数据血缘技术已经通过火山引擎大数据研发治理套件 DataLeap 对外开放。
接下来,字节跳动数据平台在数据血缘方面的工作,会主要集中在三个方向:
首先,是持续提升血缘的准确性。当前我们的血缘准确性已经提升到了可用的状态,但是依然需要人工的校验与修复。如何持续稳定的提升准确性,是探索的重要方向。
其次,是血缘的标准化建设。除了数据血缘之外,应用级别的血缘其实也很重要,在解决方案上,我们希望做到通用与标准。当前业务方会基于数据血缘拼接一些自己业务领域的链路,完成标准化后,这部分用例可以复用整套基础设施,定制产品层面的展现就好了。
最后,是加强对外部生态的支持。细分下来有两个方向,一是探索通用的 SQL 类血缘解析引擎,当前,新接入一种 SQL 类的引擎血缘,成本是比较高的;二是支持开源或公有云上产品的端到端血缘。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












