
《权力的游戏》谁是你最喜爱的演员?这里有一份Python教程
上一篇 / 下一篇 2019-04-22 09:55:29 / 个人分类:软件测试
《权力的游戏》最终季已于近日开播,对于全世界翘首以待的粉丝们来说,其最大的魅力就在于“无法预知的人物命运”。那些在魔幻时代的洪流中不断沉浮的人们,将会迎来怎样的结局?近日,来自 Medium 上的一位名叫 Rocky Kev 的小哥哥利用 Python 通过《权力的游戏》粉丝网站收集最喜爱演员的照片。结果是怎样的是其次的,关键是过程,用他的话来讲,“非常 enjoy!”
文中,他主要分享了一些关于 Python 库的使用,包括:通过 Selenium 库实现 Web 自动化,并通过 BeautifulSoup 库进行 Web 抓取,生成 CSV 模块的报告,类似于采用 Python 工具模拟整个 Pandas/Data Science 方面的功能。
他还指出,读者不需要任何的 Python 经验,他已经详细解释了这些代码。而他自己也不是一名 Python专家,仅仅学习了几周的 Python 知识,就写出了这些代码。在他看来,“Python 是一种通用的编程语言,它具有严格的类型、解释,并且因其易读性和优异的设计原则而出名。”
如简单对比下 JavaScrip 与 Python 语法区别:
Python使用缩进和大括号。

Python 使用基于类的继承,因此它更像 C 语言,而 JavaScript. 可以模拟类。
Python 也是一种强类型,没有类型混合。例如,如果同时添加一个字符串和一个 Int类型的数据,它就会报错。
同样,他也为大家提前奉献了自己常用的 Python 免费资源,比如 Automata the Boring Stuff、Python for Beginners,以及 Dataquest.io data science等,都可以在网上搜集到。
本篇将主要分为三部分:
一、Web自动化
使用 Python 最酷的事情之一就是实现 Web 自动化。例如,你可以使用如下思路来编写一个 Python 脚本:
2、自动访问特定网站
3、登录该站点
4、转到该网站的另一页面
5、查找最新的博文
6、打开那篇博文
7、提交评论 “写得好,鼓掌”
8、最后退出网站
这个过程看似不难,花 20 秒就可以搞定,但如果让一遍一遍这样做,谁都会被逼疯。例如,如果你的网站还在开发中,里面有 100 篇博客,你想给每篇博客发表评论来测试该功能。那就会需要花 100 篇博文 * 20 秒 = 大约 33 分钟。如果有多个测试阶段,那是不是要多次测试该功能?
不过,Web 自动化同样也可以应用在:
自动化创建网站账户。
在线课程中,从头到尾自动化监控。
仅使用单个脚本就能在网站上推送 100 个评论的功能。
我们将做什么?
对于这一部分,我们将自动化登录美剧《权力的游戏》的粉丝网站。如果我们单独去登录如 westeros.org、winteriscoming.net 等粉丝网站,非常浪费时间。使用如下所示的模板,你可以自动登录各类粉丝网站。
代码
安装 Python3、Selenium 和 Firefox Web 等程序才可以开始使用。
教程:如何使用 Python 自动化表单提交:
https://rockykev.com/how-to-automate-form-submissions-logins/
## Game of Thrones easy login script ## ##?Description:?This?code?logs?into?all?of?your?fan?sites?automatically from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException import time driver = webdriver.Firefox() driver.implicitly_wait(5) ## implicity_wait makes the bot wait 5 seconds before every action ## so the site content can load up # Define the functions def?login_to_westeros?(username,userpass): ## Open the login page driver.get('https://asoiaf.westeros.org/index.php?/login/') ## Log the details print(username + " is logging into westeros.") ## Find the fields and log into the account. textfield_username = driver.find_element_by_id('auth') textfield_username.clear() textfield_username.send_keys(username) textfield_email = driver.find_element_by_id('password') textfield_email.clear() textfield_email.send_keys(userpass) submit_button = driver.find_element_by_id('elSignIn_submit') submit_button.click() ## Log the details ????print(username?+?"?is?logged?in!?->?westeros") def?login_to_reddit_freefolk?(username,?userpass): ## Open the login page ????driver.get('https://www.reddit.com/login/?dest=https%3A%2F%2Fwww.reddit.com%2Fr%2Ffreefolk') ## Log the details print(username + " is logging into /r/freefolk.") ## Find the fields and log into the account. textfield_username = driver.find_element_by_id('loginUsername') textfield_username.clear() textfield_username.send_keys(username) |
textfield_email = driver.find_element_by_id('loginPassword') textfield_email.clear() textfield_email.send_keys(userpass) submit_button = driver.find_element_by_class_name('AnimatedForm__submitButton') submit_button.click() ## Log the details ????print(username?+?"?is?logged?in!?->?/r/freefolk.") ## Define the user and email combo. login_to_westeros("gameofthronesfan86", PASSWORDHERE) time.sleep(2) driver.execute_script("window.open('');") Window_List = driver.window_handles driver.switch_to_window(Window_List[-1]) login_to_reddit_freefolk("MyManMance", PASSWORDHERE) time.sleep(2) driver.execute_script("window.open('');") Window_List = driver.window_handles driver.switch_to_window(Window_List[-1]) ## wait for 2 seconds time.sleep(2) print("task complete") |
代码分解
首先,我们需要导入 Selenium 库来解决复杂的问题。还可以导入时间库,在每次操作后,将等待数秒。添加允许页面加载的等待时间。
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException import time |
什么是Selenium?
Selenium 是我们用于 Web 自动化的 Python 库。Selenium 开发了一个 API,可以让第三方开发 Web 驱动程序与浏览器通信。这样,Selenium 团队可以专注于代码库维护更新,而另一个团队可以专注于中间件。
例如:
Chromiun 团队为 Selenium 创建了自主的网络驱动程序 chromedriver
Firefox 团队为 Selenium 创建了自主的网络驱动程序 geckodriver
Opera 团队为 Selenium 创建了自主的网络驱动程序 operadriver
| driver = webdriver.Firefox() |
| driver.get(' |
https://www.hbo.com/game-of-thrones
| ') |
driver.close()
以上代码表达的意思是:将 Firefox 设置为首选浏览器,将此链接传递给 Firefox,关闭 Firefox。
登录网站
为了便于阅读,作者写了一个单独的函数来登录每个站点。
deflogin_to_westeros?(username,?userpass): ## Log in driver.get('https://asoiaf.westeros.org/index.php?/login/') ## Log the details print(username + " is logging into westeros.") ## 2) |
Look for the login box on the page
textfield_username = driver.find_element_by_id('auth') textfield_username.clear() textfield_username.send_keys(username) |
textfield_email = driver.find_element_by_id('password') textfield_email.clear() textfield_email.send_keys(userpass) submit_button = driver.find_element_by_id('elSignIn_submit') submit_button.click() ## Log the details print(username?+?"?is?logged?in!?->?westeros") |
如果更进一步分析代码,每个函数都有以下功能:
1、访问指定页面
| driver.get('https://asoiaf.westeros.org/index.php?/login/') |
2、查找登录框
*如果有请清除文本
*提交变量
textfield_username = driver.find_element_by_id('auth') textfield_username.clear() textfield_username.send_keys(username) |
3、查找密码框
*如果有请清除文本
*提交变量
textfield_email = driver.find_element_by_id('password') textfield_email.clear() textfield_email.send_keys(userpass) |
4、查找提交按钮,然后单击
submit_button = driver.find_element_by_id('elSignIn_submit')
submit_button.click()
注释:每个网站都有不同的方法来查找用户名/密码和提交按钮。需要读者做一些搜索工作。
如何找到任何网站的登录框和密码框?
Selenium 库有一堆方便的方法来查找网页上的元素。可以提供一些函数:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_class_name
有关整个的函数列表,请访问 Selenium Python 文档去查找。
以 asoiaf.westeros.com 为例:

运行代码
以下运行代码时的一小段 demo(截图)
二、Web Scrapping
接下来,将探讨 Web Scrapping,它可以帮助你自动的获取 Web 内容。
整个过程是这样的:首先使用 Python 访问网页;接着使用 BeautifulSoup 解析该网页;然后设置代码获取特定数据。我们将获取网页上的图像。
Web Scrapping 也可以应用于:
获取网页上的所有链接;
获取论坛中所有帖子的标题;
下载网站中的所有网站。
挑战
我们的目标是抓取网页中的图片,虽然网页链接、正文和标题的抓取非常简单,但是对于图像内容的抓取要复杂得多。
作为 Web 开发人员,在单个网页上显示原图像会降低网页访问速度。一般是仅使用缩略图,而仅在单机缩略图时才加载完整图像。
举个例子:如果我们的网页有20张1M的图像。访问者登录后,必须下载20M的图像。更常用的方法是制作20张10kb的缩略图,这样有效负载就仅为200kb,也就是1/100。
那么这与网络抓取图像有什么关系呢?
上述例子意味着写一个适用于每个网站的通用代码非常困难。每个网站实现将缩略图转换为全尺寸图像的方法不同,这就导致很难创建一个通用的模型。
过程案例
本教程的目标是收集我们最喜爱演员的照片。为了收集这些照片,先利用 Python 进行网页内容抓取,然后通过 BeautifulSoup 库访问网页并从中获取图像的 tag。
注释:在许多网站条款和条件中,禁止任意形式的数据抓取。此外,请注意你正在占用其网站资源,你应该一次一个请求,而不是并行打开大量连接请求,逼停网站。
# Import the libraries needed import requests import time from bs4 import BeautifulSoup # The URL to scrape url='https://www.popsugar.com/celebrity/Kit-Harington-Rose-Leslie-Cutest-Pictures-42389549?stream_view=1#photo-42389576' #url='https://www.bing.com/images/searchq=jon+snow&FORM=HDRSC2' # Connecting response = requests.get(url) # Grab the HTML and using Beautiful soup = BeautifulSoup (response.text, 'html.parser') #A loop code to run through each link, and download it foriinrange(len(soup.findAll('img'))): tag = soup.findAll('img')[i] link = tag['src'] #skip it if it doesn't start with http if"http"?in?full_link: print("grabbed?url:"+link) filename = str(i) + '.jpg' print("Download:"+filename) r = requests.get(link) open(filename, 'wb').write(r.content) else: print("grabbed?url:"+link) print("skip") time.sleep(1) Breaking down the code |
使用 Python 访问网页
首先导入所需的库,然后将网页链接存到变量中。
Requesets 库用于执行各种 HTTP 请求。
Time 库用于在每个请求后等待一秒钟。
BeautifulSoup 库用于更轻松地搜索 DOM 树。
使用 BeautifulSoup 解析网页
接下来,将 URL 地址推送给 BeautifulSoup。
寻找内容
最后,使用 FOR 循环来获取内容。
以 FOR 循环开始,BeautifulSoup 能快速过滤,并找到所有的 img 标签,然后存储在临时数组中。使用 len 函数查询数组的长度。
#A loop code to run through each link, and download it for i in range(len(soup.findAll('img'))): |
代码中会有51个内容。
For i in range(50):
接下来,我们将返回 soup 对象,然后开始内容过滤。
tag = soup.findAll('img')[i] link = tag['src'] |
需要记住的是,For循环中,[i]代表一个数字。
因此,我们可以通过索引号来寻找到每一个存储下来的 img 内容。采用soup.findALL('img')[i] 的使用方法将其传递给 tag 变量。
| <img src="smiley.gif" alt="Smiley face" height="42" width="42"> |
下一步是 src 变量。
下载内容
到循环的最后一步,下载内容。这里面的代码设计解释一下:
1、IF语句实际上是用于测试站点,有时候抓取的图像是根网站的一部分,且是不想要的内容。所以如果使用IF语句可以忽略。
2、只抓取 .jpg 格式的图片。
3、添加打印命令,如果你想获取网页所有的链接或特定内容,也是可以的。
其中采用的是 requests.get(link)和open(filename,'wb').write(r.content) 代码。
r = requests.get(link) open(filename, 'wb').write(r.content) |
原理:
1、Requests 获取链接。
2、Open 是 Python 的一个内置函数,可以打开或者创建文件,并给它写的权限,并将链接的内容写入文件。
| #skip it if it doesn't start with http |
| if "http" in full_link: |
print("grabbed url: " + link) |
| filename = str(i) + '.jpg' |
print("Download: " + filename) |
| r = requests.get(link) |
| open(filename, 'wb').write(r.content) |
| else: |
print("grabbed?url: " + link) |
| print("skip") |
| time.sleep(1) |
Web Scraping 有很多有用的函数。以上的代码在抓取网站的图像时,需要修改后才能使用。
三、生成报告和数据
收集数据很容易,但解释数据很困难。这就是为什么现在对数据科学家的需求急剧增加。数据科学家通常使用 R 和 Python 等语言进行解释。
接下来,我们将使用 CSV 模块。如果我们面对的是一个巨大的数据集,比如50,000 行或更多,那就需要使用 Pandas 库。
我们需要做的是下载 CSV 库,让 Python 解释数据,根据问题查询,然后打印出答案。

对比 Python 与表格函数
你可能会有疑问:“当我可以轻松使用像= SUM或= COUNT这样的表格函数,或者过滤掉我不需要手动操作的行时,为什么要使用 Python 呢?”
与第1部分和第2部分中的所有其他自动化技巧一样,你绝对可以手动执行此操作。但想象一下,如果你每天必须生成一份新的报告。
过程案例
每年,《权力的游戏》的新闻网站 Winteriscoming.net 都会举办疯狂三月的活动。访问者将投票选出他们最喜欢的角色,获胜者将向上移动并与另一个人竞争。经过 6 轮投票,宣布获胜者。

由于 2019 年投票仍在进行中,我们抓取了 2018 年 6 轮的数据并将其编译成 CSV 文件。此外,还添加了一些额外的背景数据(比如它们来自哪里),使报告内容更有趣。
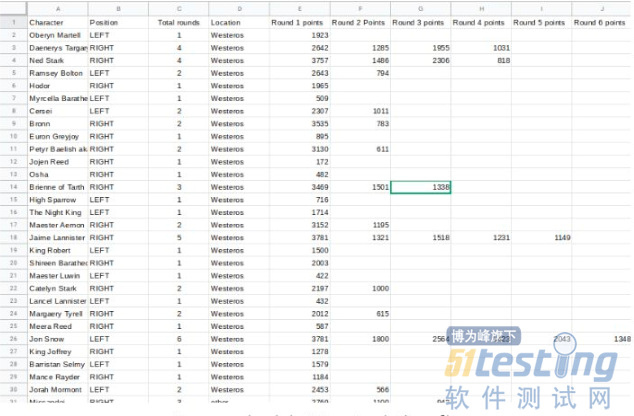
不过,基于这个报告,有些问题需要考虑:
微软雅黑
TAG: