
基于AI的移动端自动化测试框架的设计与实践
上一篇 / 下一篇 2019-01-02 10:09:33 / 个人分类:软件测试
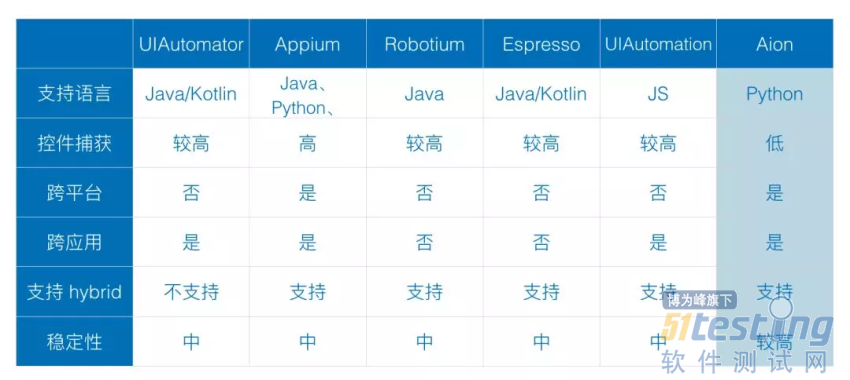
我们在衡量一个自动化测试框架的好坏时候,通常一些指标来作为参考标准。比如会要求这个框架的测试代码易于开发和维护,稳定性高,满足要求的执行效率,同时在这些基本需求等到满足后,我们会要求它具备跨平台、快应用能力和对 Hybrid 的支持。传统的测试框架在这些指标上的表现各有优劣。

上图可以看出,大多数平台提供的测试框架本身不具备跨平台能力,虽然 Appium 支持跨平台,但是他本身是对不同平台的封装,而且由于它基于协议的方式,让测试代码的维护性变得比其他框架要差。总结下来,传统框架相对来说主要存在以下一些不足:
跨平台能力差
跨应用能力差
稳定性对ID依赖较大
控件捕获成本高
dump 系统视图树几率性的失败
在这个背景下,测试人员其实渴望存在一种支持可见即可得的自动化测试框架,这样让测试代码的风格更加接近用户平时的使用习惯。其实之前业内也有一些人在这方面做过一些常识,Sikuli 和网易的 AirTest 都是基于图片截图进行匹配的方式,完成的点击和验证。
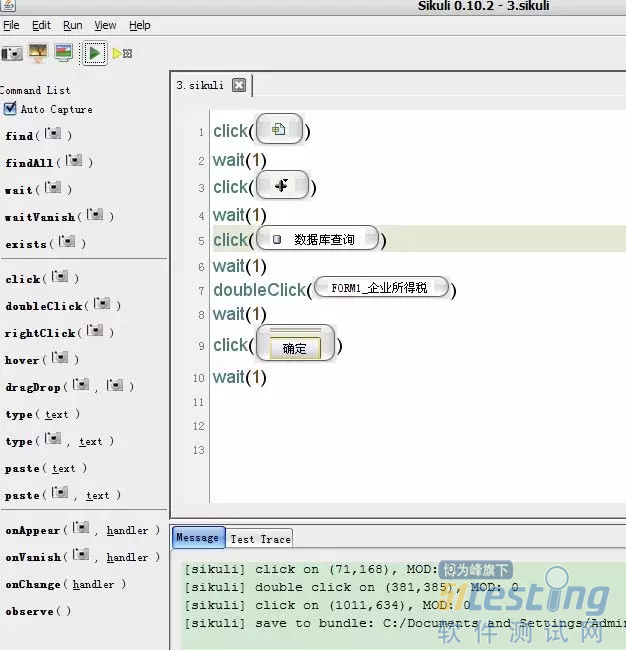

Sikuli 是早期 PC 时代的一个测试框架,AirTest 是网易近期推出的,可以说这个框架还是非常不错,不过基于截图匹配的方式还是会存在一些不足,比如匹配的准确度不够,没有层次结构,以及由于色差或者背景颜色变化带来的测试代码不稳定性,都会降低代码可维护性。
其实我们在编写测试代码的时候更希望能够实现将 “点击'tab'里面的'会员'”翻译成 find('tab').find('会员').click() 这样类似的操作,在进行一些总结之后,我们认为需要完成这样的转换,至少需要以下的一些基本能力:
图像切割
图像分类识别
OCR 文字识别
图像相似度匹配
像素点操作
深度学习发展带来的机会

这是 ImageNet 的 ILSVRC 挑战赛的结果,可以发现在 2012 年之前,深度学习还没有被引入到图像分类中,其结果的准确率一直在 75% 以下难以突破,但是在深度学习被引入以后,图像分类的准确率每年都在攀升,都近期已经达到 98% 甚至 99% 以上的结果。这样的结果意味着深度学习的图像分类能力已经远远超出人类肉眼的分辨能力。
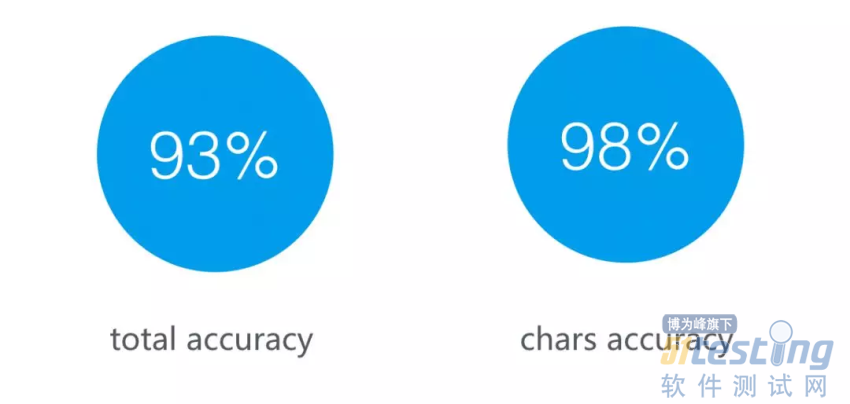
此外还有一项关键技术就是 OCR 的能力,在我们做过一些简单的尝试以后得到的结果是,文本整句识别的准确率可以达到 93%,单个文字的识别准确率已经可以提升到 98%。虽然召回率并没有达到足够的准确率,但是由于我们是先切图在完成 OCR ,所以准确率对我们来说更为关键。
在基础能力满足条件的基础上,于是我们开始尝试搭建一套支持可见即可得的测试框架,前期方案调研的时候,行业上 UI2Code 这样一个事情和我们在技术上有很多想通的地方,因为都会将一张图片逆向生成出一套视图树。
PixelToApp
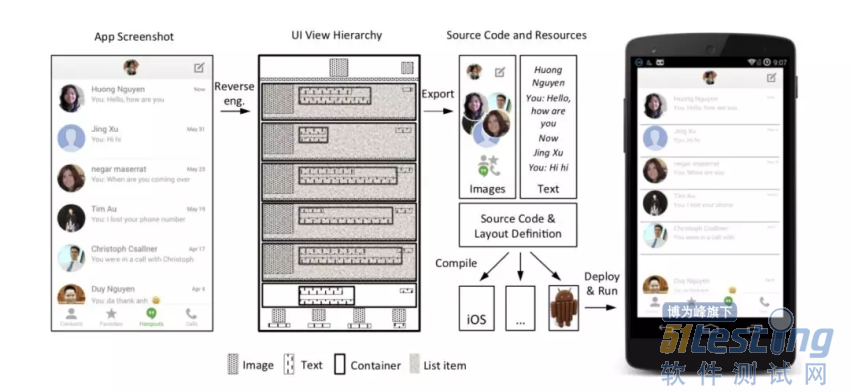
第一个接触到的是一个基于传统图像处理技术的 PixelToApp 的项目,这个项目会将一张截图通过图像处理技术逆向生成一个布局,并结合切割下来的资源生成一套应用代码,其中生成布局的过程是我们关注的重点。
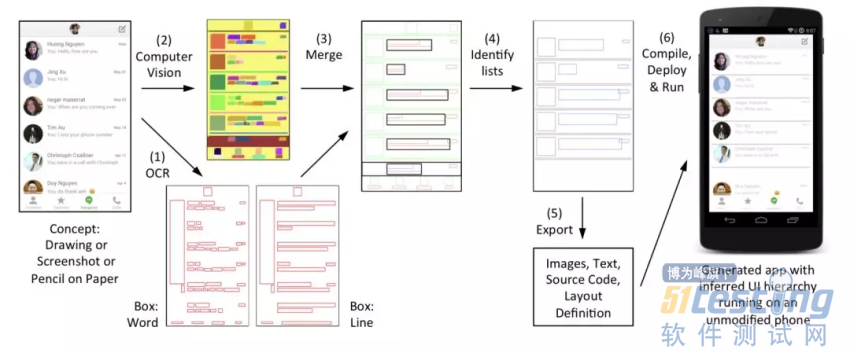
这个过程首先利用 OCR 识别出图片中文本区域并标记出来,其次通过图像处理技术提出出图片中各个元素的位置信息,再次把这两个位置信息进行一个合并,得到一个更加准确的布局信息,最后通过一些算法计算是否存在列表和 Grid 等信息,从而生成得到的布局信息。
这个方案存在的问题比较明显,1.复杂图片处理能力不够2.算法的泛化能力不足,而且在算法的瓶颈很难突破。
Pix2Code
另外一个方案是完全基于深度学习的端到端的技术方案。Pix2Code 在 Github 上有一定的知名度,也是利用深度学习进行 UI2Code 一个具有代表性的方案。
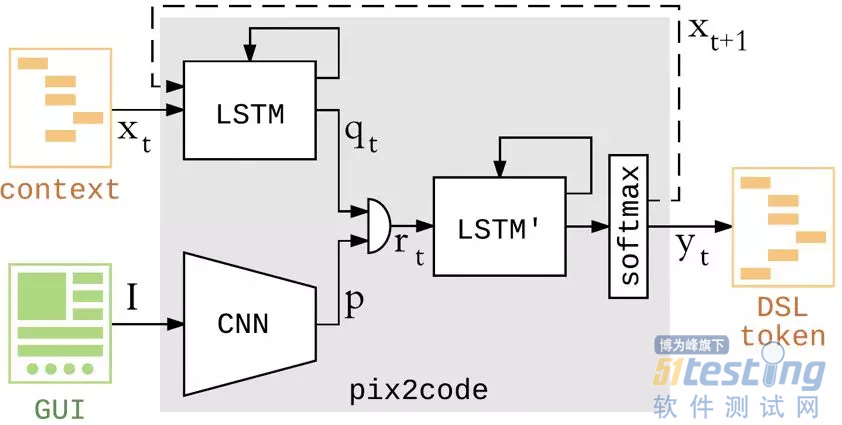
这个方案里,构建了一个如上图所示的模型,训练过程中会先将图片经过 CNN 生成一个特征向量 p,然后将该图片对应的布局描述文件拆分成一个序列,每个序列先通过一个 LSTM 模块生成一个特征向量 q,然后将 p 和 q 进行级联,在通过一个 LSTM 模块,最后通过一个 SoftMax 模块输出结果,并作为下一个序列的一个输入。
先不说这个模型设计的好坏,单从准确度上来讲肯定是满足不了需求的,这个项目的准确率只有 60-70%,而且是在一些简单的界面。当然在这个之后也存在一些其他端到端的方案尝试,效果比这个要好,但是总体准确率依然不高。
这种完全基于深度学习端到端的技术方案存在一个明显的问题就是过程不可干预,当结果不理想时往往需要重新设计或优化模型,这个周期相对来说还是比较长的,而且训练素材的样本标注成本也会比较高。
Aion 的方案
在对比了传统图像处理和纯深度学习的方案以后,我们采用了将两种技术进行融合的方案。在我们的方案里,会先利用图像处理技术进行分块切割,然后利用图像分类进行分块的类别识别,再进行子元素的提取,最后利用 OCR 和图像分类技术识别对应的属性填充到子元素的属性中,生成一个二级的视图树。有了这个二级视图树以后,就可以完成团队想要的点击和验证操作了。

整个测试用例的执行流程如图所示,其中场景判断、分类识别和子元素属性填充都会应用到 AI 技术。同时在我们的框架上,还无缝兼容了传统框架的使用,以满足从传统case切换的问题,和纯图像处理没法处理的场景。
Aion 的深度学习优化
我们选用的 MobileNetV2 模型,这个模型的好处是在满足一定准确率的情况下,执行效率特别高。在进行训练的过程中我们碰到的第一个问题就是训练素材分布不均匀的情况,这个时候我们采用脚本生成和采集更多行业 App 信息的方式,扩充了爱奇艺的数据源,从而通过筛选实现一个相对均衡的训练素材。

在提升准确率上,我们从迁移训练的Top-Layer的方式切换到 Fine-tune的方式,这个过程中依然碰到了训练素材不足的情况。除此之外团队还采用多原图多模型并用的方式提升整体的准确率。

Aion 的优势与不足
Aion 作为一款基于全新技术方案的测试框架,和传统框架相比,优势是比较明显的。
总结下来,大致如下:
可见即可得,易于理解和开发
对系统框架依赖弱,跨平台
稳定性强,不用担心 ID 混淆的问题
分类少,层次浅,视图捕获简单
无缝支持传统框架
当然也有美中不足,首先准确率需要进一步提升,其次就是一些特征特别少的元素,如输入框有时候只有一条线或一个光标作为特征值,识别出来难度较大。在一些前背景元素融合度比较高的场景下,提取出子元素相对比价难。
写在最后:
利用 AI 技术的确解决了团队之前不能解决的问题,Aion 框架的表现整体也是优于现有的其他测试框架的。其实在移动端以及移动端测试还存在更多的场景,能够利用 AI 解决更多问题,如页面异常检测、用户行为预测,页面预加载等。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8052),我们将立即处理。

了解更多课程内容及课程安排,可咨询QQ 2852509883 或致电客服 400-821-0951(工作日9:00-17:30)
【看这里】
TAG: